一种web网页的正文内容提取方法、装置、设备及介质与流程
本发明涉及web网页领域,特别涉及一种web网页的正文内容提取方法、装置、设备及计算机可读存储介质。
背景技术:
随着互联网技术的快速发展与普及,web网页逐渐成为人们获取信息的主要来源之一。但是,与此同时,web网页中的正文内容中往往夹杂着许多无用信息或者垃圾信息,如广告展示、垃圾链接、推荐产品信息、导航条信息和版权说明信息等,这些信息将直接影响用户获取到web网页中的有效的正文内容。
现有技术中,通过根据目标web网页的网页内容设置对应的dom树,再根据文本密度规则、目标web网页的页面布局等规则,提取出目标web网页中的有效的正文内容。但是,由于web网页的页面结构设置越来越复杂,现有技术的方法在提取web网页中正文内容时,将存在提取不准确的情况。
因此,如何提高提取web网页中的正文内容的准确度,是本领域技术人员目前需要解决的技术问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种web网页的正文内容提取方法,能够提高提取web网页中的正文内容的准确度;本发明的另一目的是提供一种web网页的正文内容提取装置、设备及计算机可读存储介质,均具有上述有益效果。
为解决上述技术问题,本发明提供一种web网页的正文内容提取方法,包括:
根据目标web网页的源代码确定出与所述目标web网页对应的dom树;其中,所述dom树的叶子节点表示所述目标web网页中的网页内容;
按照预设规则对各所述网页内容进行监听埋点,并统计用户对各所述网页内容的操作信息;
利用预先训练出的决策树根据文本密度规则、所述目标web网页的页面布局、各所述网页内容对应的操作信息分别判断各所述网页内容是否为正文内容,提取出所述目标web网页的正文内容。
优选地,在所述根据目标web网页的源代码确定出与所述目标web网页对应的dom树之后,进一步包括:
判断所述网页内容中是否存在敏感词汇;
若是,则发出对应的提示信息。
优选地,所述统计用户对各所述网页内容的操作信息具体包括:
统计所述用户浏览各所述网页内容的时间长度和/或所述用户对各所述网页内容的点选操作的次数和/或所述用户在各所述网页内容上进行的输入操作的次数。
优选地,在所述根据目标web网页的源代码确定出与所述目标web网页对应的dom树之后,进一步包括:
对所述dom树中的网页内容进行数据清洗操作。
优选地,在所述按照预设规则对各所述网页内容进行监听埋点,并统计用户对各所述网页内容的操作信息之后,进一步包括:
确定出所述用户浏览时间最长和/或输入操作次数最多的目标网页内容;
将所述目标网页内容进行突出显示。
优选地,进一步包括:
记录存在所述敏感词汇的所述目标web网页的网址。
优选地,进一步包括:
根据所述文本密度规则、所述页面布局、所述网页内容和对应的操作信息确定出所述目标web网页的网页类型。
为解决上述技术问题,本发明还提供一种web网页的正文内容提取装置,包括:
设置模块,用于根据目标web网页的源代码确定出与所述目标web网页对应的dom树;其中,所述dom树的叶子节点表示所述目标web网页中的网页内容;
统计模块,用于按照预设规则对各所述网页内容进行监听埋点,并统计用户对各所述网页内容的操作信息;
提取模块,用于利用预先训练出的决策树根据文本密度规则、所述目标web网页的页面布局、各所述网页内容对应的操作信息分别判断各所述网页内容是否为正文内容,提取出所述目标web网页的正文内容。
为解决上述技术问题,本发明还提供一种web网页的正文内容提取设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现上述任一种web网页的正文内容提取方法的步骤。
为解决上述技术问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一种web网页的正文内容提取方法的步骤。
本发明提供的一种web网页的正文内容提取方法,首先根据目标web网页的源代码确定出与目标web网页对应的dom树;其中,dom树的叶子节点表示目标web网页中的网页内容;然后按照预设规则对各网页内容进行监听埋点,并统计用户对各网页内容的操作信息;再利用预先训练出的决策树根据文本密度规则、目标web网页的页面布局、各网页内容对应的操作信息分别判断各网页内容是否为正文内容,提取出目标web网页的正文内容。
可见,本方法通过进一步按照预设规则对各网页内容进行监听埋点,并统计出用户对各网页内容的操作信息;再在现有技术根据文本密度规则和页面布局确定目标web网页的正文内的基础上,进一步利用各网页内容和对应的操作信息判断各网页内容是否为正文内容,从而提取出目标web网页的正文内容,从而能够提高提取web网页中的正文内容的准确度。
为解决上述技术问题,本发明还提供了一种web网页的正文内容提取装置、设备及计算机可读存储介质,均具有上述有益效果。
附图说明
为了更清楚地说明本发明实施例或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
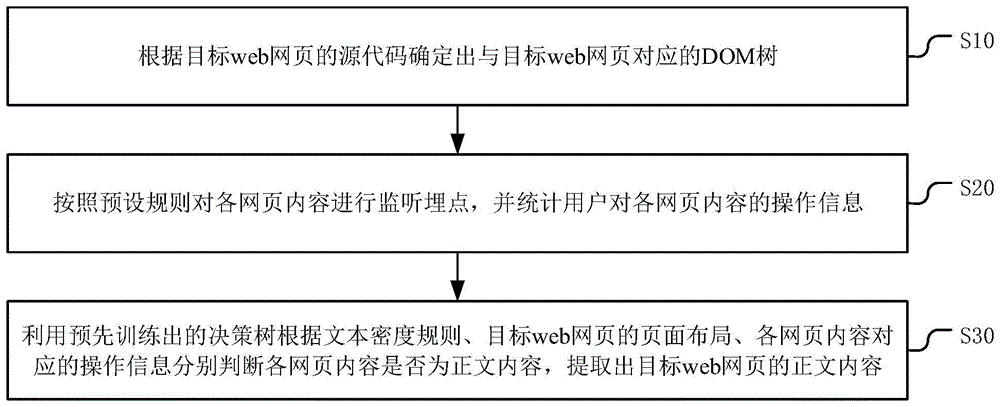
图1为本发明实施例提供的一种web网页的正文内容提取方法的流程图;
图2为本发明实施例提供的一种web网页的正文内容提取装置的结构图;
图3为本发明实施例提供的一种web网页的正文内容提取设备的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例的核心是提供一种web网页的正文内容提取方法,能够提高提取web网页中的正文内容的准确度;本发明的另一核心是提供一种web网页的正文内容提取装置、设备及计算机可读存储介质,均具有上述有益效果。
为了使本领域技术人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。
图1为本发明实施例提供的一种web网页的正文内容提取方法的流程图。如图1所示,一种web网页的正文内容提取方法包括:
s10:根据目标web网页的源代码确定出与目标web网页对应的dom树;
其中,dom树的叶子节点表示目标web网页中的网页内容。
具体的,首先获取目标web网页的html源代码,再通过dom(documentobjectmodel,文档对象化模型)将html源代码进行解析,生成的htmltree树状结构和对应访问方法,即,得出dom树;其中,dom树的叶子节点表示目标web网页中的网页内容,且网页内容包括目标web页面中的纯文本、点选按钮以及输入框等内容。
s20:按照预设规则对各网页内容进行监听埋点,并统计用户对各网页内容的操作信息。
具体的,在得出与目标web页面对应的dom树之后,按照预设规则对各网页内容进行监听埋点,以便于对设置了监听埋点的网页内容进行信息统计。其中,预设规则指的是预先设置的具体进行监听埋点的网页内容的类型,通过监听埋点,以获取各不同的用户分别对各网页内容进行的操作情况。可以理解的是,对网页内容进行埋点是网站分析的一种常用的数据采集方法,因此本实施例对监听埋点的具体实现方式不做赘述。另外,在本实施例中,具体是统计用户对各网页内容的操作信息,例如可以是用户浏览网页内容的时间长度等,本实施例对此不做限定。
s30:利用预先训练出的决策树根据文本密度规则、目标web网页的页面布局、各网页内容对应的操作信息分别判断各网页内容是否为正文内容,提取出目标web网页的正文内容。
具体的,在本实施例中,预先训练出决策树,该决策树的每个叶子节点表示一个判断类别,该叶子节点的两个分支表示两种判断结果(是/否)。在本实施例中,判断类别是根据文本密度规则、目标web网页的页面布局、各网页内容对应的操作信息设置的,因此,决策树的根节点到叶子节点是一条分类的路径规划,利用决策树对每个网页内容进行决策判断,确定出该网页内容是否为正文内容。利用决策树进行决策判断,结构简单,处理效率高。
本发明实施例提供的一种web网页的正文内容提取方法,首先根据目标web网页的源代码确定出与目标web网页对应的dom树;其中,dom树的叶子节点表示目标web网页中的网页内容;然后按照预设规则对各网页内容进行监听埋点,并统计用户对各网页内容的操作信息;再利用预先训练出的决策树根据文本密度规则、目标web网页的页面布局、各网页内容对应的操作信息分别判断各网页内容是否为正文内容,提取出目标web网页的正文内容。
可见,本方法通过进一步按照预设规则对各网页内容进行监听埋点,并统计出用户对各网页内容的操作信息;再在现有技术根据文本密度规则和页面布局确定目标web网页的正文内的基础上,进一步利用各网页内容和对应的操作信息判断各网页内容是否为正文内容,从而提取出目标web网页的正文内容,从而能够提高提取web网页中的正文内容的准确度。
在上述实施例的基础上,本实施例对技术方案作了进一步的说明和优化,具体的,本实施例在根据目标web网页的源代码确定出与目标web网页对应的dom树之后,进一步包括:
判断网页内容中是否存在敏感词汇;
若是,则发出对应的提示信息。
具体的,在本实施例中,可以预先利用正则表达式设置敏感词汇,然后在根据目标web网页的源代码确定出与目标web网页对应的dom树之后,根据预先设置的敏感词汇对各网页内容进行识别,判断网页内容中是否存在敏感词汇。若检测到网页内容中存在敏感词汇,则进一步发出提示信息。
需要说明的是,本实施例对发出提示信息的具体方式不做限定,即,对提示信息的类型不做限定,例如,可以是通过蜂鸣器和/或指示灯和/或显示器等提示装置发出对应的提示信息以达到提示的目的。
可见,本实施例通过进一步判断网页内容中是否存在敏感词汇,并在确定出网页内容中存在敏感词汇的情况下发出对应的提示信息,使得用户可以及时根据提示信息退出该目标web网页,进一步提升用户的使用体验。
作为优选的实施方式,进一步包括:
记录存在敏感词汇的目标web网页的网址。
需要说明的是,在本实施例中,是在判断出目标web网页的网页内容中存在敏感词汇时,进一步记录该目标web网页的网址。本实施例对记录该目标web网页的网址的具体方式不做限定,例如可以将该目标web网页的网址存储于预设的文本型文件中,也可以将该目标web网页的网址存储于数据库表中等。
可以理解的是,本实施例通过进一步记录该存在敏感词汇的目标web网页的网址,能够便于统计存在异常的web网页。
在上述实施例的基础上,本实施例对技术方案作了进一步的说明和优化,具体的,本实施例在根据目标web网页的源代码确定出与目标web网页对应的dom树之后,进一步包括:
对dom树中的网页内容进行数据清洗操作。
需要说明的是,在本实施例中,数据清洗操作包括去除网页内容中的空格、标签、换行符等特殊字符;还可以去除掉网页内容中明显的广告内容或者导航条信息或者版权说明信息等。
通过预先对dom树中的网页内容进行数据清洗操作,能够进一步提高后续提取目标web网页的正文内容的准确度。
在上述实施例的基础上,本实施例对技术方案作了进一步的说明和优化,具体的,本实施例中,统计用户对各网页内容的操作信息具体包括:
统计用户浏览各网页内容的时间长度和/或用户对各网页内容的点选操作的次数和/或用户在各网页内容上进行的输入操作的次数。
可以理解的是,在实际操作中,用户在浏览目标web网页时,一般会进行查看操作,如查看目标web网页中的文字信息;点选操作,如关闭广告内容的窗口;或者输入操作,如在输入框中输入信息等。本实施例中,通过统计用户浏览各网页内容的时间长度和/或用户在各网页内容上进行的输入操作的次数,得出各网页内容的统计信息,用于目标web网页的正文内容提取操作,能够准确有效地对各网页内容进行判断。
作为优选的实施方式,在按照预设规则对各网页内容进行监听埋点,并统计用户对各网页内容的操作信息之后,进一步包括:
确定出用户浏览时间最长和/或输入操作次数最多的目标网页内容;
将目标网页内容进行突出显示。
在实际操作中,用户在浏览目标web网页时,若网页内容为有用的信息,则用户一般会花费更多的时间去阅读理解,也就是说,用户浏览该网页内容的时间长度会普遍较长;或者,若网页内容为输入框,用户普遍需要在该输入框处输入信息,因此,用户在该输入框处进行的输入操作的次数会更多。
本实施例通过确定出用户浏览时间最长和/或输入操作次数最多的目标网页内容,表示目标网页内容是用户很可能需要着重注意或者需要进行输入操作的内容,因此将确定出的目标网页内容进行突出显示。具体的,突出显示的方式可以将对应的目标网页内容的字体加粗,或者利用特殊颜色显示目标网页内容等,本实施例对此不做限定,通过对目标网页内容进行突出显示,能够进一步起到提示用户注意的查看的效果,避免用户遗漏信息。
在上述实施例的基础上,本实施例对技术方案作了进一步的说明和优化,具体的,本实施例进一步包括:
根据文本密度规则、页面布局、网页内容和对应的操作信息确定出目标web网页的网页类型。
可以理解的是,不同的web网页中的文本密度规则或者页面布局或者网页内容可能是不同的,在本实施例中,预先确定各不同的文本密度规则、页面布局、网页内容和对应的操作信息的组合所对应的网页类型,然后在获取当前目标web网页的文本密度规则、页面布局、网页内容和对应的操作信息之后,确定出与目标web网页对应的网页类型。
可见,本实施例通过进一步根据文本密度规则、页面布局、网页内容和对应的操作信息确定出目标web网页的网页类型,便于用户获取目标web网页的正文内容,进一步提升用户的使用体验。
上文对于本发明提供的一种web网页的正文内容提取方法的实施例进行了详细的描述,本发明还提供了一种与该方法对应的web网页的正文内容提取装置、设备及计算机可读存储介质,由于装置、设备及计算机可读存储介质部分的实施例与方法部分的实施例相互照应,因此装置、设备及计算机可读存储介质部分的实施例请参见方法部分的实施例的描述,这里暂不赘述。
图2为本发明实施例提供的一种web网页的正文内容提取装置的结构图,如图2所示,一种web网页的正文内容提取装置包括:
设置模块21,用于根据目标web网页的源代码确定出与目标web网页对应的dom树;其中,dom树的叶子节点表示目标web网页中的网页内容;
统计模块22,用于按照预设规则对各网页内容进行监听埋点,并统计用户对各网页内容的操作信息;
提取模块23,用于利用预先训练出的决策树根据文本密度规则、目标web网页的页面布局、各网页内容对应的操作信息分别判断各网页内容是否为正文内容,提取出目标web网页的正文内容。
本发明实施例提供的web网页的正文内容提取装置,具有上述web网页的正文内容提取方法的有益效果。
作为优选的实施方式,进一步包括:
判断模块,用于判断网页内容中是否存在敏感词汇;若是,则调用提示模块;
提示模块,用于发出对应的提示信息。
作为优选的实施方式,统计模块22具体包括:
统计子模块,用于统计用户浏览各网页内容的时间长度和/或用户对各网页内容的点选操作的次数和/或用户在各网页内容上进行的输入操作的次数。
作为优选的实施方式,进一步包括:
清洗模块,用于对dom树中的网页内容进行数据清洗操作。
作为优选的实施方式,进一步包括:
统计确定模块,用于确定出用户浏览时间最长和/或输入操作次数最多的目标网页内容;
显示模块,用于将目标网页内容进行突出显示。
作为优选的实施方式,进一步包括:
记录模块,用于记录存在敏感词汇的目标web网页的网址。
作为优选的实施方式,进一步包括:
类型确定模块,用于根据文本密度规则、页面布局、网页内容和对应的操作信息确定出目标web网页的网页类型。
图3为本发明实施例提供的一种web网页的正文内容提取设备的结构图,如图3所示,一种web网页的正文内容提取设备包括:
存储器31,用于存储计算机程序;
处理器32,用于执行计算机程序时实现如上述web网页的正文内容提取方法的步骤。
本发明实施例提供的web网页的正文内容提取设备,具有上述web网页的正文内容提取方法的有益效果。
为解决上述技术问题,本发明还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现如上述web网页的正文内容提取方法的步骤。
本发明实施例提供的计算机可读存储介质,具有上述web网页的正文内容提取方法的有益效果。
以上对本发明所提供的web网页的正文内容提取方法、装置、设备及计算机可读存储介质进行了详细介绍。本文中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!