一种匹配文字信息的视频检索方法与流程
本发明涉及视频检索技术领域,特别是涉及一种匹配文字信息的视频检索方法。
背景技术:
随着互联网技术的飞速发展、各种视频拍摄,剪辑和采集设备不断的更新换代,网络视频的数量呈爆炸式增长。人们能够更加便利的查看视频的同时,也要求更加高效更加精准的视频检索。传统的基于文本的视频检索方法需要先人工对视频信息进行注解,再使用基于文本的数据库管理系统进行视频检索,因此,在视频检索过程需要大量的时间和存储索引空间。随着视频数据数量上的飞速增长,基于文本的视频检索已无法满足人们的检索需求,难以通过少量简要的文字信息检索出视频,同时在处理基于视频内容的检索时效率很低甚至无效。
综上可知,解决视频检索问题的关键在于文字信息如何扩充来降低检索复杂度以及如何实现基于视频内容的检索。随着人工智能技术的发展,深度学习技术为解决这些问题提供了新的思路。神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术,其中的知识图谱技术可以将复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制显示出来,并加以处理和使用,可以对文字信息进行扩充。视频描述(videocaptioning)技术能将视频生成文字描述,即视频图像领域到文本领域的转化。循环神经网络(recurrentneuralnetwork,rnn)可以用于实现视频检索系统整体的功能。基于此,设计一种匹配文字信息的视频检索方法。
技术实现要素:
本发明公开了一种匹配文字信息的视频检索方法,主要应用知识图谱和videocaptioning技术处理文字信息和视频,实现基于视频内容的视频检索,提升视频检索的效率,降低了数据存储量。
根据本发明应用背景,提供一种匹配文字信息的视频检索方法,本方法包括以下步骤:
步骤1、使用知识图谱对文字信息进行信息扩充并建立文字特征向量矩阵,并参考文字特征向量矩阵训练全卷积神经网络fcn模型,建立视频与文字信息的关系,使用单向lstm神经网络对视频生成特征描述并建立视频特征向量矩阵,记录对文字信息进行信息扩充并生成文字特征向量矩阵和用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法及参数:
1)使用知识图谱对输入用于检索的文字信息进行信息扩充,拆分输入的文字信息为一组词,利用word2vec模型和知识图谱嵌入模型得到词和知识库实体的向量表示,将这些向量通过非线性变换映射到同一个向量空间,并使用这些向量架构一个kcnn神经网络,给定词汇数据库,进一步得到词汇检索关于输入的文字信息的向量表达,再使用一个dnn神经网络模型预测文字与拓展信息的关联概率,建立文字特征向量矩阵,取关联度最高的特征信息向量加入矩阵,对输入的文字进行信息扩充,记录对文字信息进行信息扩充并生成文字特征向量矩阵的方法和参数;
2)参照文字特征矩阵里的信息词汇,建立相对应的特征词汇库,用videocaptioning技术对待检测视频生成描述,建立词汇全卷积神经网络lexical-fcn模型,将视频的每一帧通过fcn神经网络生成数据,通过模型训练建立数据与从文字特征向量矩阵中汇聚的词库的弱映射联系,在fcn神经网络输出的最后一层,使用目标检测方法中的anchor方法来粗略的划分出16个区域,确认区域序列的种类,选择部分序列使用单向lstm神经网络生成基于文字特征向量矩阵的描述,再利用word2vec模型建立视频特征向量矩阵,记录使用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法和参数。
步骤2、将文字特征向量矩阵和视频特征向量矩阵导入rnn循环神经网络模型进行训练,再将用知识图谱对文字信息进行信息扩充并生成文字特征向量的方法作为处理输入的文字信息的接口,将用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法作为处理视频的接口,将整个模型载入视频检索引擎,处理并判断模型可用性是否达成目标:
1)对导入rnn循环神经网络模型的文字特征向量矩阵和视频特征向量矩阵进行匹配和建立联系,多次输入生成不同类型不同内容的激活函数,以此来提升筛选和匹配的精度,不断调整和传递参数,生成多层网络,迭代此训练过程不断调整参数直至完成训练,将保存的生成文字特征向量矩阵和视频特征向量矩阵的方法作为模型的输入接口,最后把模型载入视频检索引擎;
2)输入描述视频显著性特征的文字信息,连接到视频资源库,经过视频搜索引擎,文字信息扩充,作为输入进入到引擎内部,参与筛选和匹配过程,同时视频库的视频进入引擎,提取相应特征后,进行此时引擎的自处理式的匹配和筛选,最后引擎将经处理的最优结果作为检索结果返回。
与现有技术相比,本方法的优点在于:
1、使用的数据来自于输入的文字信息和视频本身的特征描述,实现了基于视频内容的视频检索。
2、优化了检索流程,提供了使用文字信息检索视频的方法,提高了识别率和视频检索率。
3、使用文字信息与视频的特征匹配,减少了人工建立视频索引方法中由经验给出的各项对视频特征的存储,减轻关键数据存储量,减轻检索数据操作执行量。
4、使用了深度学习的算法,将建立的文字特征向量矩阵和视频特征向量矩阵作为训练样本进行训练,获得每个维度特征对应的联系,克服了现有的索引式方法中由经验给出的各项特征联系的人为主观性,使视频本身的信息元素对检索结果影响中的权重达到更优,进而视频搜索引擎筛选效果更优,搜索结果更符合用户需求,改善用户体验,提升视频检索的效率。
附图说明
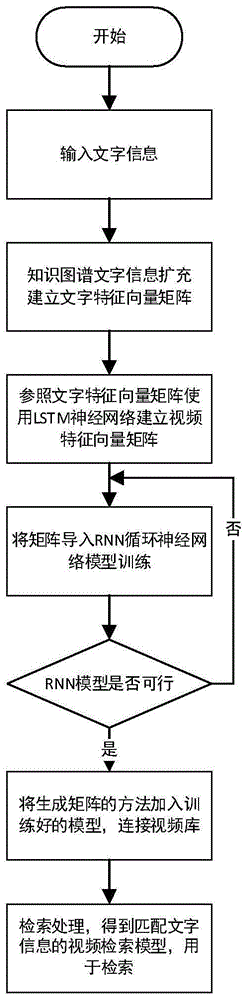
图1是本发明的流程图;
图2是本发明的文字信息扩充示意图;
图3是本发明的文字特征向量矩阵示意图;
图4是本发明的视频特征生成示意图;
图5是本发明的视频特征向量矩阵示意图;
图6是本发明的rnn模型训练示意图
具体实施方式
如图1所示,本发明技术方案的具体步骤为:
步骤1、使用知识图谱对文字信息进行信息扩充并建立文字特征向量矩阵,并参考文字特征向量矩阵训练全卷积神经网络fcn模型,建立视频与文字信息的关系,使用单向lstm神经网络对视频生成特征描述并建立视频特征向量矩阵,记录对文字信息进行信息扩充并生成文字特征向量矩阵和用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法及参数:
1)如图2所示,使用知识图谱对输入用于检索的文字信息进行信息扩充,拆分输入的文字信息为一组词,利用word2vec模型和知识图谱嵌入模型得到词和知识库实体的向量表示,将这些向量通过非线性变换映射到同一个向量空间,并使用这些向量架构一个kcnn神经网络,给定词汇数据库,进一步得到词汇检索关于输入的文字信息的向量表达,再使用另一个dnn神经网络模型预测文字与拓展信息的关联概率,建立如图3所示的文字特征向量矩阵,取关联度最高的特征信息向量加入矩阵,对输入的文字进行信息扩充,记录对文字信息进行信息扩充并生成文字特征向量矩阵的方法和参数:
将输入的文字拆成一组词,并将其与知识库的实体进行链接,再接着找出距离链接实体一跳之内的所有邻接实体,利用word2vec模型可以得到词的向量表示,利用知识图谱嵌入模型可以得到知识库实体的向量表示;
把输入的文字、链接实体、上下文实体的向量表示通过一个非线性变换映射到同一个向量空间
g(e1:n)=[g(e1)g(e2)…g(en)]
然后类似于图像中rgb的三通道,将词、链接实体、上下文实体的向量表示作为cnn神经网络多通道的输入,架构一个kcnn神经网络,这样kcnn神经网络模型的输入就可以表示为:
给定词汇数据库,通过kcnn神经网络得到文字信息的向量表示:采用dnn神经网络模型作为注意力网络和一个归一化函数softmax计算归一化影响力权重:
得到数据库关于输入文字的向量表示:
2)如图4所示,参照文字特征矩阵里的信息词汇,建立相对应的特征词汇库,使用videocaptioning技术对待检测视频生成描述,建立全卷积神经网络lexical-fcn模型,将视频的每一帧通过fcn网络生成数据,通过模型训练建立数据与从文字特征向量矩阵中汇聚的词库的弱映射联系,在fcn神经网络输出的最后一层,使用目标检测方法中的anchor方法来粗略的划分出16个区域,确认区域序列的种类,选择部分序列使用单向lstm神经网络生成基于文字特征向量矩阵的描述,再利用word2vec模型建立如图5所示的视频特征向量矩阵,记录用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法和参数:
建立lexical-fcn模型,将视频的每一帧通过fcn网络生成数据,通过模型训练建立数据与从文字特征向量矩阵中汇聚的词库的弱映射联系,在fcn输出的最后一层,使用目标检测方法中的anchor方法来粗略的划分出16个区域,为区域序列生成服务;
区域序列生成使用submodularmaximization数学方法,提取视频为30帧,确认区域序列的种类,选择部分序列生成描述,选择标准为
逐步贪心得出区域序列,在每个时间加入区域r的收益为
于是在每步选择使其增量最大的r,对于参数权重w有:
使用加了类型信息c的单向lstm神经网络:s*=argmaxsp(c|v),针对不同类型的序列生成描述词汇并通过word2vec模型建立结构对称的特征向量矩阵,记录用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法和参数。
步骤2、将文字特征向量矩阵和视频特征向量矩阵导入rnn循环神经网络模型进行训练,再将用知识图谱对文字信息进行信息扩充并生成文字特征向量矩阵的方法作为处理输入的文字信息的接口,将用videocaptioning技术对待检测视频生成描述并通过word2vec模型建立视频特征向量矩阵的方法作为处理视频的接口,将整个模型载入视频检索引擎,处理并判断模型可用性是否达成目标:
1)如图6所示,对导入rnn循环神经网络模型的文字特征向量矩阵和视频特征向量矩阵进行匹配和建立联系,多次输入生成不同类型不同内容的激活函数,以此来提升筛选和匹配的精度,不断调整和传递参数,生成多层网络,迭代此训练过程不断调整参数直至完成训练,将保存的生成文字特征向量矩阵和视频特征向量矩阵的方法作为模型的输入接口,将模型载入视频检索引擎:
这个网络在t时刻接受到输入的两个特征向量xt和yt之后,隐藏层的值是st,输出是ot,关键的一点st的值不仅仅取决于xt,还取决于st-1,我们可以用以下的公式:
st=f(u·xt+t·yt+w·st-1)
2)输入描述视频显著性特征的文字信息,连接到视频资源库,经过视频搜索引擎,文字信息扩充,作为输入进入到引擎内部,参与筛选和匹配过程,同时视频库的视频进入引擎,提取相应特征后,进行此时引擎的自处理式的匹配和筛选,最后引擎将经处理的最优结果作为检索结果返回。
- 还没有人留言评论。精彩留言会获得点赞!