一种网络舆情信息传播中关键节点选择方法与流程
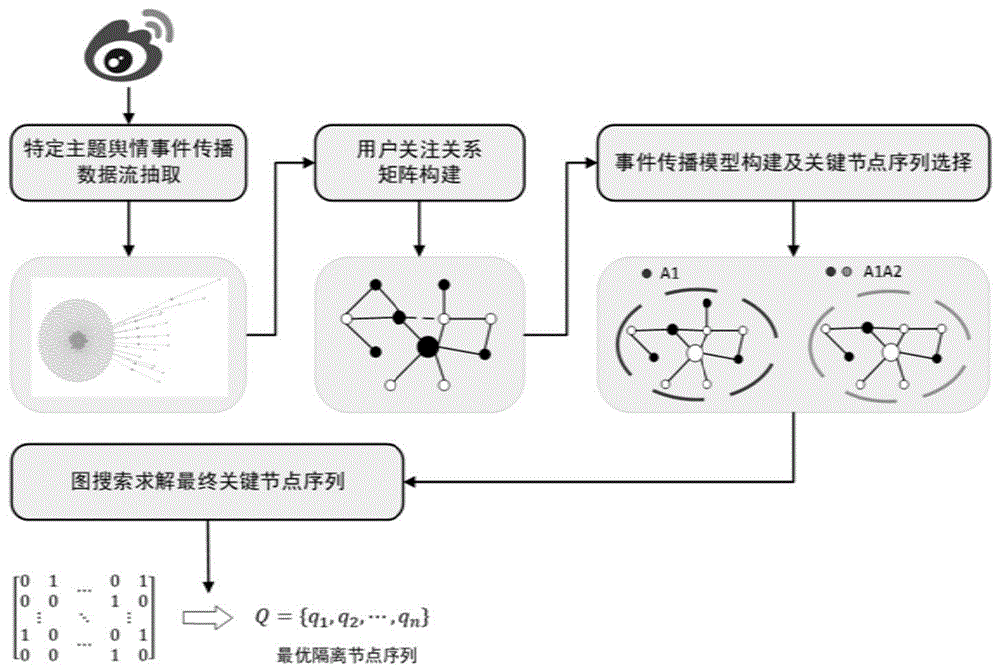
本发明涉及社交网络应用技术领域,特别涉及一种网络舆情信息传播中关键节点选择方法。
背景技术:
web2.0时代,在线社交网络发展迅速,用户从单纯的信息受众演变成为有独立影响能力的信息传播主体,社交网络为舆情事件的发展提供了广阔的平台,舆情信息在社交网络的传播呈现出传播速度越来越快,影响越来越大的特点。如何对快速发现有害舆情事件,并且准确评估其发展态势,采用智能化的引导方式疏解舆情代替暴力删帖、五毛党灌水等低效手段,是社会发展中一个关键的研究问题。社交网络中用户数量众多,每个用户对事件的发展演化能够造成不同的影响。与社交网络中意见领袖的发现不同,我们的研究问题是找到一批相对于易于引导的节点,通过改变用户行为以期望取得比较好的整体效果。目前社交网络关键节点选择算法主要可以分为以下几类:
1)基于节点属性与网络拓扑结构的节点重要性评估:这类方法利用网络的结构信息,然后基于这些已知的结构信息对节点的重要性进行排序,重要度高的节点被视为关键节点。常用的评估指标有:节点度、介数(通过节点最短路径的几率,反映了节点对其他节点之间联络的控制作用)、聚类系数以及一些中心性指标用于描述节点在社交网络中所处位置的中心程度。
2)基于贪心算法的节点影响力最大化评估:影响力最大化问题,已经有大量研究将其形式化定义出来。由于种子节点数目众多,并且组合多样性,已经被证明是一个np-hard问题,基于贪心策略的算法通常在准确性方面都有良好的表现,因此被广泛采用。传播模型上,在传播模型上主要还是使用kempe等提出的独立级联模型和线性阈值模型。其研究思路为通过模拟信息传播过程,寻找一批能够大量增加参与节点让这些种子节点在预定的传播模型下进行影响力传播,使得传播过程终止时被影响的节点数量达到最大。
现在已经存在了许多在社交网络中发现关键节点的工作。
现有技术1提出了一种基于节点覆盖范围的社交网络影响力最大化方法,其主要方法包括:首先根据网络拓扑结构计算每个节点的覆盖范围增益,然后根据增益排序选择种子节点,最后从种子节点集合中选择该社交网络影响力最大化节点集合。
现有技术2提出了一种基于k壳分解的识别传播关键节点的方法,其方法主要包括:首先,通过采集社交平台的消息转发建立传播网络,把参与转发消息的用户加入节点集合,并且获取节点集合中用户的好友集合,建立节点拓扑图;然后根据节点度计算各个节点的k壳索引作为个体影响力;最后采用floyd算法计算所述传播网络中每对节点间的最短距离,综合k壳索引以及最短路径排名得到传播网络中的传播关键节点。
现有技术3提出了一种基于影响力最大化的社交网络关键节点识别方法,其主要方法包括:首先根据节点度对节点影响力进行初步排序;然后在节点影响力全局稳定之前迭代更新节点影响力;最后根据影响力最大化原则,选取影响力排名靠前的节点作为关键节点。
上述社交网络关键节点发现方法的专利技术方案在关键节点选择过程中都只考虑了网络的静态特征,如节点度,k-shell特性等,忽略了社交网络信息传播过程中的节点相互影响的动态过程;其次,采用综合排名的方式导致关键节点的选取多集中在度较大的节点,在发现影响信息传播的中间关键节点方面存在不足。
技术实现要素:
本发明的目的在于提供一种网络舆情信息传播中关键节点选择方法,以解决上述问题。
为实现上述目的,本发明采用以下技术方案:
一种网络舆情信息传播中关键节点选择方法,其特征在于,包括以下步骤:
步骤1,社交网络特定主题舆情事件传播数据流抽取及参与用户关注关系矩阵构建:对某社交网络的主站点以及它的wap站点进行网络请求抓包,分析某社交网络登录过程的网络请求序列,实现爬虫程序自动登录站点;对于获取到的特定主题下的社交网络消息,爬取每条社交网络下的转发内容,转发时间以及转发用户信息,并且获取参与转发用户的用户关注列表以及粉丝列表,根据用户之间发送消息的时序关系以及用户关注关系构建用户关注关系矩阵a=(v,e),其中v表示参与用户,e表示用户之间的关注关系,是用户的出度边;
步骤2,事件传播模型构建:使用传染病模型作为基础信息传播模型去建模每条社交网络消息的传播过程,对每条消息i进行影响力βi估计,所有消息的传播过程结合在一起即为事件整体的传播过程;
步骤3,事件传播过程中关键节点选择:依据步骤1得到的数据构造用户邻接矩阵a,利用a的结构特征进行启发式搜索,筛选出一批种子节点q;依据步骤3得到的事件传播模型仿真模拟隔离节点v∈q之后的信息传播结果,利用贪心算法获得每次迭代结果的最优解,最终得到一组节点序列,将多组节点序列构造成一个有向图,利用深度优先算法遍历得到的有向图,得到最终的关键节点序列。
2.根据权利要求1所述的一种网络舆情信息传播中关键节点选择方法,其特征在于,社交网络中的特定主题事件传播流数据包括:社交网络发帖人信息、社交网络内容和社交网络发送时间;社交网络发帖人信息包括用户粉丝数、关注数、粉丝列表、关注列表和用户简介。
3.根据权利要求1所述的一种网络舆情信息传播中关键节点选择方法,其特征在于,步骤1社交网络特定主题舆情事件传播数据流抽取及参与用户关注关系矩阵构建,其构建步骤为:
第1步:对社交网络的主站点以及社交网络wap站点进行网络请求抓包,分析社交网络登录过程的网络请求序列,模拟登录请求,获取用户cookie实现爬虫程序自动登录社交网络站点;
第2步:模拟登录后,从社交网络搜索入口输入事件关键词,解析搜索结果页html得到特定主题下的社交网络消息,内容包括发帖内容、发帖时间、发帖人信息以及转发情况;根据每条社交网络消息的转发,获取转发该条社交网络的用户信息,包含用户粉丝数、关注数、粉丝列表、关注列表和用户简介;
第3步:根据每个事件参与用户的粉丝以及关注列表和转发关系,把用户之间的关系强度建模为强关联关系、中等关联关系和弱关联关系三种关联关系,得到一个n*n维的用户关系矩阵a,其中n为参与用户数。
4.根据权利要求3所述的一种网络舆情信息传播中关键节点选择方法,其特征在于,
1)强关联关系:根据用户转发消息的时间进行构建;如果用户u转发了用户v的消息,认为用户u关注了用户v,则有一条从v指向u的边;
2)中等关联关系:用户之间存在关注关系,但是没直接有转发关系;假定用户u关注了用户v,用户v发送事件相关消息的时间比用户u早,即tv<tu;
3)弱关联关系:用户之间存在关注关系,但是双方在发贴时序上没有关系;假定用户u关注了用户v,但是用户v发送事件相关消息的时间比用户u晚,即tu<tv;用t*表示用户转发消息的时间。
5.根据权利要求1所述的一种网络舆情信息传播中关键节点选择方法,其特征在于,步骤2事件传播模型构建,采用基本传染病si模型描述每条微博信息的传播,以1min为周期度量传播,利用真实数据集在固定时刻的参与用户数量作为基准去估计一条社交网络消息的影响力bi,从而构成一个n*1维的用户影响力矩阵<。
6.根据权利要求1所述的一种网络舆情信息传播中关键节点选择方法,其特征在于,步骤3事件传播过程中关键节点选择中,采用了基于隔离效率的贪心算法,其方法步骤为:
首先设置初始关键节点集合q={};从种子节点集合qtemp中选取一个节点v,根据其出度计算引导该节点的成本
重复执行以上过程,直到关键节点集中节点数目与预设的引导节点数目相等;
接下来进行图搜索算法,执行过程为:
1)执行关键节点选择算法,得到一组节点qlist;
2)遍历qlist中的元素,构建一条节点选择顺序路径;
3)重复执行前两步得到多条节点路径;
4)根据多条路径构造最优节点集的关系矩阵;
5)用深度优先算法求解矩阵中的最长路径,并且要包含最多公共节点;路径上的节点为最终关键节点集合q={q1,q2,…,qqnum}。
与现有技术相比,本发明有以下技术效果:在新浪微博特定主题事件传播流原始数据集基础上,考虑了本发明利用了用户之间本身存在的关注关系以及相关发帖的时序关系构造了用户关系强度矩阵,单条微博消息的传播与真实数据集的拟合度平均达到了95%,对消息传播的整体趋势拟合准确率达到了95.2%;在关键节点的选择结果上,由于考虑了成本收益比,本发明得到的关键节点集合中节点度的平均值很小,模拟隔离集合中所有节点所得到的参与用户数目的减少量高于隔离与关键节点集合中节点度之和相近的节点所带来的参与用户数目的减少量,隔离的成本收益比有所提高。
本发明考虑了消息传播的动态性,利用了si模型去模拟社交网络信息传播过程中的节点相互影响的动态过程。
本发明考虑了用户参与事件的时序特征,通过准确的信息仿真能够确定节点的影响范围。
本发明考虑了成本收益比,得到的关键节点集合中节点度的平均值很小,更适合与现实场景中的舆情引导。
附图说明
图1是本发明一种网络舆情信息传播中关键节点选择方法框图。
图2是新浪微博数据集采集流程图。
图3是用户关注关系矩阵构建流程图。
图4是事件传播模型构建流程图。
图5是关键节点序列选择流程图。
具体实施方式
以下结合附图及实施例对本发明的实施方式进行详细说明:
请参阅图1至图5,一种网络舆情信息传播中关键节点选择方法,包括以下步骤:
步骤1,社交网络特定主题舆情事件传播数据流抽取及参与用户关注关系矩阵构建:对某社交网络的主站点以及它的wap站点进行网络请求抓包,分析某社交网络登录过程的网络请求序列,实现爬虫程序自动登录站点;对于获取到的特定主题下的社交网络消息,爬取每条社交网络下的转发内容,转发时间以及转发用户信息,并且获取参与转发用户的用户关注列表以及粉丝列表,根据用户之间发送消息的时序关系以及用户关注关系构建用户关注关系矩阵a=(v,e),其中v表示参与用户,e表示用户之间的关注关系,是用户的出度边;
步骤2,事件传播模型构建:使用传染病模型作为基础信息传播模型去建模每条社交网络消息的传播过程,对每条消息i进行影响力βi估计,所有消息的传播过程结合在一起即为事件整体的传播过程;
步骤3,事件传播过程中关键节点选择:依据步骤1得到的数据构造用户邻接矩阵a,利用a的结构特征进行启发式搜索,筛选出一批种子节点q;依据步骤3得到的事件传播模型仿真模拟隔离节点v∈q之后的信息传播结果,利用贪心算法获得每次迭代结果的最优解,最终得到一组节点序列,将多组节点序列构造成一个有向图,利用深度优先算法遍历得到的有向图,得到最终的关键节点序列。
社交网络中的特定主题事件传播流数据包括:社交网络发帖人信息、社交网络内容和社交网络发送时间;社交网络发帖人信息包括用户粉丝数、关注数、粉丝列表、关注列表和用户简介。
步骤1社交网络特定主题舆情事件传播数据流抽取及参与用户关注关系矩阵构建,其构建步骤为:
第1步:对社交网络的主站点以及社交网络wap站点进行网络请求抓包,分析社交网络登录过程的网络请求序列,模拟登录请求,获取用户cookie实现爬虫程序自动登录社交网络站点;
第2步:模拟登录后,从社交网络搜索入口输入事件关键词,解析搜索结果页html得到特定主题下的社交网络消息,内容包括发帖内容、发帖时间、发帖人信息以及转发情况;根据每条社交网络消息的转发,获取转发该条社交网络的用户信息,包含用户粉丝数、关注数、粉丝列表、关注列表和用户简介;
第3步:根据每个事件参与用户的粉丝以及关注列表和转发关系,把用户之间的关系强度建模为强关联关系、中等关联关系和弱关联关系三种关联关系,得到一个n*n维的用户关系矩阵a,其中n为参与用户数。
1)强关联关系:根据用户转发消息的时间进行构建;如果用户u转发了用户v的消息,认为用户u关注了用户v,则有一条从v指向u的边;
2)中等关联关系:用户之间存在关注关系,但是没直接有转发关系;假定用户u关注了用户v,用户v发送事件相关消息的时间比用户u早,即tv<tu;
3)弱关联关系:用户之间存在关注关系,但是双方在发贴时序上没有关系;假定用户u关注了用户v,但是用户v发送事件相关消息的时间比用户u晚,即tu<tv;用t*表示用户转发消息的时间。
步骤2事件传播模型构建,采用基本传染病si模型描述每条微博信息的传播,以1min为周期度量传播,利用真实数据集在固定时刻的参与用户数量作为基准去估计一条社交网络消息的影响力<i,从而构成一个n*1维的用户影响力矩阵<。
步骤3事件传播过程中关键节点选择中,采用了基于隔离效率的贪心算法,其方法步骤为:
首先设置初始关键节点集合q={};从种子节点集合qtemp中选取一个节点v,根据其出度计算引导该节点的成本
重复执行以上过程,直到关键节点集中节点数目与预设的引导节点数目相等;
接下来进行图搜索算法,执行过程为:
1)执行关键节点选择算法,得到一组节点qlist;
2)遍历qlist中的元素,构建一条节点选择顺序路径;
3)重复执行前两步得到多条节点路径;
4)根据多条路径构造最优节点集的关系矩阵;
5)用深度优先算法求解矩阵中的最长路径,并且要包含最多公共节点;路径上的节点为最终关键节点集合q={q1,q2,…,qqnum}。
以新浪微博为例:
步骤1,社交网络特定主题舆情事件传播数据流抽取:为了获取真实场景下的舆情事件数据集,我们获取了新浪微博上特定主题下的消息流数据。数据获取按照以下过程:
第1步:对新浪微博的主站点(https://weibo.com)以及新浪微博的wap站点(https://weibo.cn)进行网络请求抓包,分析微博登录过程的网络请求序列。按照请求序列模拟发送登录数据,获取用户cookie,实现爬虫程序自动登录微博站点;
第2步:模拟登录后,从微博搜索入口(https://s.weibo.com)输入舆情事件关键词,解析返回的搜索结果页的html得到该主题下的微博消息,内容包括发帖内容、发帖时间、微博id、发帖人信息(用户id、用户粉丝数、关注数、粉丝列表、关注列表、用户简介等)以及这条微博的转发情况。根据每条微博消息的转发,获取转发该条微博的用户信息,包含用户id、用户粉丝数、关注数、粉丝列表、关注列表、用户简介等;
步骤2,参与用户关注关系矩阵构建:根据获取到的每个事件参与用户的粉丝列表以及关注列表和微博转发关系,我们定义三种不同强度的关系用于描述用户之间的关系强度:
初始化矩阵:a(:,:)=0,aw(:,:)=0。
1)强关联关系:根据用户转发消息的时间顺序构建。如果用户u转发了用户v的微博,那么认为用户u关注了用户v,则有一条从v指向u的边,即
2)中等关联关系:用户之间存在关注关系,但是没直接有转发关系。假定用户u关注了用户v,用户v发送相关微博的时间比用户u早,即tv<tu,则
3)弱关联关系:用户之间存在关注关系,但是双方在发贴时序上没有关系。假定用户u关注了用户v,但是用户v发送事件相关微博的时间比用户u晚,即tu<tv。这说明用户v发送这条消息几乎没有受到用户u的影响,因此给定一个很大的常数tt作为响应时间,即
其中t*表示用户发送消息的时间。
步骤3,事件传播模型构建:由步骤1获取到的有转发的微博数为m,m条微博的总体转发量为n,一般情况下n>>m。根据所获取的消息的时间流,将消息的传播过程定义为时间序列ri={nt|t=1,…,t;i∈m},其中nt为在t时刻单位事件内(以分钟为单位)参与转发第i条微博的用户数量,t为观测时间,一般选择三天共计4320min。从观测时间的零点开始,第i条有转发的微博分别在tmi时刻发送出来。
我们选择经典传染病模型si(susceptible-infected)作为信息传播模型去建模每条消息的传播情况。在si模型当中,节点有易感染(susceptible)和被感染(infected)两种状态。在信息传播过程中,已经发送事件相关微博的用户为感染状态i,暂时未发事件相关微博的用户为易感染状态s。未发送微博的用户看到自己关注的用户发送了相关微博,自己会以一定的概率<被影响,转发或者发送一条相关微博进而转变为被感染状态i。如此,信息会继续扩散到下一层。
单条有转发的消息的传播过程形式化定义如下:
aw(s,t)⊙a(s)*ib(i)<rand(s)
其中a代表用户邻接矩阵,aw代表边的权重,与转发时延和节点的感染时间点有关,a与aw是n维方阵,n代表事件参与的用户总数;⊙表示矩阵对应位置相乘;s代表还未转发消息的用户集合,i代表已经转发消息的用户集合,两者都为n*1的向量;ib是不同节点的感染率,与节点的属性有关,是一个n*1的向量;t代表当前时刻;rand(s)表示生成与向量s、i同维度的在0-1范围内的随机数向量。
在初始时刻t=0,s=u,
当t=tmi时,用户u发送了编号为i的微博,用户u的影响力为<u,更新ib、aw、s、i,形式化如下:
ib(u,1)=βu
aw(:,u)=aw(:,u)
s=u\{u},i=i∪{u}
记录仿真过程中转发或者发送微博用户随时间的变化情况,利用真实数据集中第i条微博在固定时刻t的参与转发的用户数量ri={nt|t=1,…,t;i∈m}作为groudtruth,用非线性最小二乘法去估计用户u的影响力<u,拟合度公式形式化定义如下:
对m条有转发的微博消息进行如上过程,构成一个n*1维的用户影响力矩阵ib。单条消息的影响力估计完成后,结合微博消息的时间流tm={tmi|i=1,…,t},随着时间t的变化,不同的用户受到影响发送或者转发了相关微博,这样就完成了事件整体的传播建模。
步骤4,种子节点筛选:由于参与用户节点数目众多,并且组合多样性,从n个节点中找出一组关键节点是一个np-hard问题。为了减少算法的时间复杂度,需要进行启发式筛选。我们提出一种从网络结构角度减少种子节点的方法。假设如果一个用户受到了正确的引导而放弃了参与该事件,我们可以认为用户不具有传播能力,进而其出度边起不到作用。在传播过程中,网络的二阶度<d2>与一阶度<d>的比值
同时,我们不希望选择到节点度很大的节点,因此我们需要控制种子节点的出度分布。经过上述两步筛选,最终得到种子节点集合qtemp。
步骤5,基于贪心算法的关键节点序列选择:初始关键节点集合q={};从种子节点集合qtemp中选取一个节点v,根据其出度计算引导该节点的成本
q=q∪{v},n=n\{v}
重复执行以上过程,直到关键节点集中节点数目与预设的引导节点数目相等,即|q|=qnum。
步骤6,图搜索解决随机性:基于仿真的节点重要度计算虽然相对准确,但是由于求解过程中存在随机性,同时网络中存在着大量对等节点,因此最优效率节点容易出现范围内的偏差。图搜索算法执行过程为:
1)执行关键节点选择算法,得到一组节点qlist;
2)遍历qlist中的元素,构建一条节点选择顺序路径;
3)重复执行前两步得到多条节点路径;
4)根据多条路径构造最优节点集的关系矩阵;
5)用深度优先算法求解矩阵中的最长路径,并且要包含最多公共节点。路径上的节点为最终关键节点集合q={q1,q2,…,qqnum}。
新浪微博数据集采集过程
图2展示了新浪微博数据集采集的整个流程。数据采集分为以下几个步骤:
第1步:对新浪微博的主站点(https://weibo.com)以及新浪微博的wap站点(https://weibo.cn)进行网络请求抓包,分析微博登录过程的网络请求序列。先使用get方法请求微博预登录地址,再使用用户名和密码构造post请求的请求体信息,请求登录地址(https://passport.weibo.cn/sso/login),最后使用get方法请求跳转的微博主页地址(https://weibo.cn),保存获取用户cookie。
第2步:模拟登录后,从微博搜索入口(https://s.weibo.com)输入舆情事件关键词,解析返回的搜索结果页的html得到该主题下的微博消息,内容包括发帖内容、发帖时间、微博id、发帖人信息(用户id、用户粉丝数、关注数、粉丝列表、关注列表、用户简介等)。如果这条微博有人转发,获取转发该条微博的用户信息,包含用户id、用户粉丝数、关注数、粉丝列表、关注列表、用户简介等;如果这条微博没有被转发,则获取微博博主的用户信息。
用户关注关系矩阵构建过程
图3展示了用户关注关系矩阵构建的整个流程。在得到了传播数据集以及用户数据集后,对数据进行处理构建用户关系矩阵。我们定义了三种不同强度的关系用于描述用户之间的关系强度:
初始化矩阵:a(:,:)=0,aw(:,:)=0。
1)强关联关系:根据用户转发消息的时间顺序构建。如果用户u转发了用户v的微博,那么认为用户u关注了用户v,则有一条从v指向u的边,即
2)中等关联关系:用户之间存在关注关系,但是没直接有转发关系。假定用户u关注了用户v,用户v发送相关微博的时间比用户u早,即tu<tu,则
3)弱关联关系:用户之间存在关注关系,但是双方在发贴时序上没有关系。假定用户u关注了用户v,但是用户v发送事件相关微博的时间比用户u晚,即tu<tv。这说明用户v发送这条消息几乎没有受到用户u的影响,因此给定一个很大的常数tt作为响应时间,即
其中t*表示用户发送消息的时间。
事件传播模型构建过程
图4展示了事件传播模型构建的整个流程。首先输入微博消息时间流tm={tmi|i=1,…,t},对每条微博消息进行传染病模型仿真从而得到该条消息的影响力,对应发送该条消息用户的影响力<u,构成一个n*1维的用户影响力矩阵ib。
单条有转发的消息的传播过程形式化定义如下:
aw(s,t)⊙a(s)*ib(i)<rand(s)
其中a代表用户邻接矩阵,aw代表边的权重,与转发时延和节点的感染时间点有关,a与aw是n维方阵,n代表事件参与的用户总数;⊙表示矩阵对应位置相乘;s代表还未转发消息的用户集合,i代表已经转发消息的用户集合,两者都为n*1的向量;ib是不同节点的感染率,与节点的属性有关,是一个n*1的向量;t代表当前时刻;rand(s)表示生成与向量s、i同维度的在0-1范围内的随机数向量。
在初始时刻t=0,s=u,
当t=tmi时,用户u发送了编号为i的微博,用户u的影响力为<u,更新ib、aw、s、i,形式化如下:
ib(u,1)=βu
aw(:,u)=aw(:,u)
s=u\{u},i=i∪{u}
记录仿真过程中转发或者发送微博用户随时间的变化情况,利用真实数据集中第i条微博在固定时刻t的参与转发的用户数量ri={nt|t=1,…,t;i∈m}作为groudtruth,用非线性最小二乘法去估计用户u的影响力<u。
关键节点序列选择过程
图5展示了关键节点序列选择的步骤。首先设置初始关键节点集合q={};从种子节点集合qtemp中选取一个节点v,根据其出度计算引导该节点的成本
q=q∪{v},n=n\{v}
重复执行以上过程,直到关键节点集中节点数目与预设的引导节点数目相等,即|q|=qnum。
接下来进行图搜索算法,执行过程为:
1)执行关键节点选择算法,得到一组节点qlist;
2)遍历qlist中的元素,构建一条节点选择顺序路径;
3)重复执行前两步得到多条节点路径;
4)根据多条路径构造最优节点集的关系矩阵;
5)用深度优先算法求解矩阵中的最长路径,并且要包含最多公共节点。路径上的节点为最终关键节点集合q={q1,q2,…,qqnum}。
- 还没有人留言评论。精彩留言会获得点赞!