一种基于区块链的数据扁平化方法及系统与流程
本发明涉及数据处理领域,尤其涉及一种基于区块链的数据扁平化方法及系统。
背景技术:
区块链技术是一种分布式数据处理技术,加密数据通过p2p网络通信技术发送给各个节点以达到全网节点共识,从而确保数据不可篡改和不可伪造。随着互联网技术的发展,区块链技术的去中心化、公开透明、不可篡改、可信任等优点,在智能合约、文件存储、供应链金融、身份验证、数字政务、电子商务、物联网、社交通讯等众多领域得到广泛应用。
随着区块链技术发展,区块链数据沉淀越来越大,对于新加入的节点完全同步区块链数据面临巨大挑战,数据同步过程耗费大量时间,浪费硬件资源,增加运营成本,提高区块链应用落地的门槛,不利于区块链生态发展。
在现有的区块链数据处理方案中,每个节点本地数据完全一致;缺失数据的节点都需要从所连接的节点同步数据,处理数据,本地保存数据,以达到区块链网络共识。节点收到区块数据后执行区块数据中的交易列表,本地保存区块数据、交易列表、执行交易的结果、账户数据;前三类数据均保存在本地数据库,而账户数据既保存在本地,又作为缓存存储在merkle-patriciatree结构体对象中。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是现有区块链交易业务中,在交易过程中,数据冗余非常大、区块数据同步效率非常低以及对硬件设备要求较高等。
为实现上述目的,本发明提供了一种基于区块链的数据扁平化方法,包括以下步骤:
建立数据扁平化节点;
数据扁平化节点通过分布式方式获取最新账户数据,得到账户数据快照,构建本地数据,参与共识;
定期清理不参与共识的数据,清理账户数据历史快照,达到区块链节点本地数据库数据扁平化。
进一步地,建立数据扁平化节点,具体包括:
准备一个节点,以数据扁平化标志启动,作为数据扁平化节点;
数据扁平化节点通过p2p连接多个区块链节点;
数据扁平化节点收集所有与数据扁平化节点连接的区块链节点同一区块数据,对比区块数据中的roothash,以备校验。
进一步地,数据扁平化节点通过分布式方式获取账户数据,得到账户数据快照,具体包括:
数据扁平化节点以分布式方式向多个区块链节点发送获取账户数据的命令,区块链节点群收到命令并行获取本地数据发送给数据扁平化节点,数据扁平化节点根据得到的本地数据构建本地账户数据,构建最新的账户数据快照对象。
进一步地,区块链中参与共识的数据设置为最新的所有的账户数据快照,每次账户数据的改变都会生成新的一份账户数据快照。
本发明另一较佳实施方式中提供了一种基于区块链的数据扁平化系统,包括:
新建模块,用于建立数据扁平化节点;
构建模块,用于数据扁平化节点通过分布式方式获取账户数据,得到账户数据快照,构建本地数据,参与共识;
清理模块,用于定期清理不参与共识的数据,达到区块链节点本地数据库数据扁平化。
进一步地,新建模块具体包括:
准备单元,用于准备一个节点,以数据扁平化标志启动,作为数据扁平化节点;
连接单元,用于数据扁平化节点通过p2p连接多个区块链节点;
对比单元,用于数据扁平化节点收集所有与数据扁平化节点连接的区块链节点同一区块数据,对比区块数据中的roothash,以备校验。
进一步地,构建单元具体包括:
数据扁平化节点以分布式方式向多个区块链节点发送获取账户数据的命令,区块链节点群收到命令并行获取本地数据发送给数据扁平化节点,数据扁平化节点根据得到的本地数据构建本地账户数据,构建最新的账户数据快照对象。
进一步地,区块链中参与共识的数据设置为最新的所有的账户数据快照,每次账户数据的改变都会生成新的一份账户数据快照。
本发明另一较佳实施方式中提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时,实现如上述中任一项的方法。
本发明另一较佳实施方式中提供了一种存储有计算机程序的计算机可读存储介质,其特征在于,计算机程序使计算机执行时实现如上述中任一项的一种基于区块链的数据扁平化方法。
技术效果
本发明公开的一种基于区块链的数据扁平化方法针对现有技术中随着区块链的高度增加,本地沉淀数据日趋增加的问题,删除本地区块数据、交易数据、执行交易的结果数据、历史账户数据快照,最终节点本地数据最精简,去除冗余和繁杂,达到数据扁平化;如果区块链网络中没有新增账户,那么本方案数据扁平化启动的节点将不会有数据增加。
本发明公开的一种基于区块链的数据扁平化方法针对现有方案中同步数据缓慢、高运算的问题,采用分布式同步账户数据的方式充分利用区块链节点资源,大幅提高构建本地数据的速度,数据扁平化节点可以以任意区块高度启动,无须像现有方案从区块高度0开始同步数据。现有方案同步数据是一种缓慢、高运算的任务,同步的过程就是计算的过程,完整地播放历史的过程;本方案完全丢弃此低效的同步过程,以给定区块数据的roothash为依据,以分布式方式充分利用区块链节点资源,高效构建本地账户数据快照,以形成有效的区块链节点。
本发明公开的一种基于区块链的数据扁平化方法去除了大量冗余的数据,大幅降低硬件资源要求、降低区块链应用落地门槛,如手机、平板等轻型移动设备均可成为区块链节点;采用分布式构建账户数据方式,在网络较好情况下,为轻型设备秒接入区块链成为区块链节点提供基础。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1是本发明的一个较佳实施例的一种基于区块链的数据扁平化方法的数据扁平化启动流程示意图;
图2是本发明的一个较佳实施例的一种基于区块链的数据扁平化方法的获取区块链账户列表流程示意图;
图3是本发明的一个较佳实施例的一种基于区块链的数据扁平化方法的获取区块链账户数据流程示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下描述中,为了说明而不是为了限定,提出了诸如特定内部程序、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
实施例一
在现有技术中,区块链交易业务中的数据处理方案具有以下几个缺陷:
1)现有区块数据处理方案数据冗余非常大
在现有区块链交易业务的数据处理方案中,节点在本地保存了大量数据,包括区块数据、交易数据、交易结果数据和账户数据等,造成数据冗余非常大,数据沉淀厚重且繁杂。
2)现有区块链交易业务的数据处理方案区块数据同步效率非常低
在现有区块链交易业务的数据处理方案中,区块数据同步效率非常低,新加入的节点需要同步区块链历史数据,用时少则数小时,多则数月,数据越多,时间越长;需要同步数据的节点每次只能与一个节点进行同步,导致数据同步效率非常低。
3)现有区块链交易业务的数据处理方案对硬件设备要求较高
在现有区块链交易业务的数据处理方案中,必须配置大容量存储介质,存储区块链产生的大量数据,导致硬件设备重型化,不利于区块链应用落地。
针对上述缺陷,本发明公开了一种基于区块链的数据扁平化方法及系统,本发明公开是基于区块链数据扁平化技术,实现区块链数据同步协议,即通过分布式获取账户数据的方式构建本地数据;本发明公开的目的是删除一切不参与共识的数据达到数据扁平化,去除冗余和繁杂,最终节点落地极小的数据量,加入区块链网络和参与共识。本实施例的一种基于区块链的数据扁平化方法包括以下步骤:
步骤100,建立数据扁平化节点;
步骤200,数据扁平化节点通过分布式方式获取账户数据,得到账户数据快照,构建本地数据,参与共识;
步骤300,定期清理不参与共识的数据,达到区块链节点本地数据库数据扁平化。
区块链节点本地存储的数据主要有区块数据、交易列表、执行交易的结果和账户数据;区块数据是指区块链节点打包的区块,而区块通常包含区块编号、时间、交易列表等信息区块数据保存在本地并不参与共识;交易列表是区块链交易集合,即保存在区块数据中,为方便检索又单独以key-value的形式保存本地,其中key是交易的hash,value是交易的16进制编码;执行交易的结果包含有交易执行状态,执行所在区块编号、日志等信息,保存在本地;账户数据包括账户号、交易编号、账户额度和智能合约字节码等信息。其中,区块数据、交易列表、执行交易的结果等数据并不参与区块链共识,在区块链中参与共识的数据是最新的所有账户数据快照,每次账户数据的改变都会生成新的一份账户数据快照。本实施例实现采用最新的账户数据快照构建本地数据系库,即构建最新merkle-patriciatree对象,此对象数据也是参与区块链网络共识唯一数据。merkle-patriciatree是一种经过改良的、融合了默克尔树和前缀树两种树结构优点的数据结构,是以太坊中用来组织管理账户数据、生成交易集合哈希的重要数据结构。
进一步地,步骤100,建立数据扁平化节点,具体包括:
步骤101,准备一个节点,以数据扁平化标志启动,作为数据扁平化节点;
步骤102,数据扁平化节点通过p2p连接多个区块链节点;
步骤103,数据扁平化节点收集所有与数据扁平化节点连接的区块链节点同一区块数据,对比区块数据中的roothash,以备校验。
数据扁平化节点是以数据扁平化标志启动的节点,清空本地历史数据,通过p2p连接多个区块链节点,当收到任何一个节点的第一个区块数据时获取区块数据中的roothash以备最后校验。
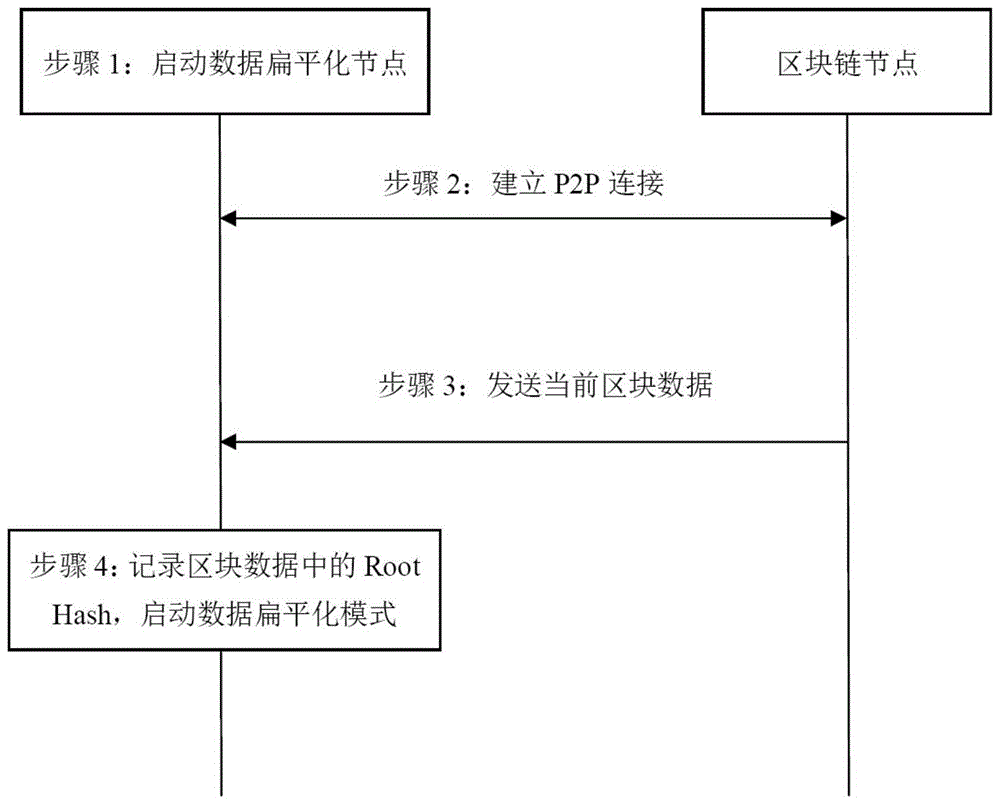
区块链节点启动形式有两种:1、区块链节点正常启动;2、区块链节点按数据扁平化模式启动。如图1所示,本实施例的启动数据扁平化模式的具体过程如下:
步骤1、准备区块链新节点,设置数据扁平化参数,以数据扁平化模式启动,删除本地区块数据;
步骤2、数据扁平化节点手动添加一个或多个在线的区块链节点,建立p2p网络连接;
步骤3、当区块链节点收到或产生一个新的区块时,广播给数据扁平化节点;
步骤4、根据最新区块数据获取roothash,以备获取账户数据后校验,该区块数据作为数据扁平化节点的第一个区块数据。
进一步地,步骤200,数据扁平化节点通过分布式方式获取账户数据,得到账户数据快照,具体包括:
数据扁平化节点以分布式方式向多个区块链节点发送获取账户数据的命令,区块链节点群收到命令并行获取本地数据发送给数据扁平化节点,数据扁平化节点根据得到本地数据构建本地账户数据,构建最新的账户数据快照对象。
分布式构建区块链账户数据的merkle-patriciatree对象,数据扁平化节点可以与多个区块链节点p2p连接,通过多个节点发过来的同一个区块数据的roothash一致,说明此roothash可行度非常高,数据扁平化节点向区块链节点发送获取账户列表命令,获得账户数据构本地建账户列表,数据扁平化节点再以分布式方式向多个区块链节点发送获取账户数据,区块链节点群收到命令并行获取本地数据发送给数据扁平化节点,数据扁平化节点构建本地账户数据,构建最新的merkle-patriciatree对象。因此,数据扁平化节点先获取账户列表,再获取账户数据;由于账户列表数据较小,账户数据较大,数据扁平化节点先获取账户列表后再以分布式方式请求账户数据。
其中,如图2所示,获取区块链账户列表流程的步骤如下:
步骤201、数据扁平化节点向区块链节点发送“获取账户”的命令;
步骤202、区块链节点遍历本地区块链数据得到所有账户列表,数量多则分批发送;
步骤203、数据扁平化节点收到账户列表后缓存到本地,并求出总列表hash值以备校验;
步骤204、区块链节点当所有的账户发送完毕后,向数据扁平化节点发送结束标志;
205、数据扁平化节点收到结束标志后,向区块链节点发送账户列表hash值;
步骤206、区块链节点验证hash值与本地是否一致,并向数据扁平化发送验证结果;
步骤207、如果验证不通过,根据索引查找丢失的账户列表;重新请求,直到获取所有的账户列表。
当数据扁平化节点获取账户列表后,以分布式方式获取账户数,如图3所示,获取账户数据流程的步骤如下:
步骤208、数据扁平化节点向区块链节点集群发送“获取账户数据”的命令,此命令包含需要获取账户数据的账户列表;
步骤209、区块链节点集群根据账户列表遍历本地区块链数据得到对应账户的数据,单个账户的数据大则拆分发送,账户列表的数据过多则分批发送;
步骤210、数据扁平化节点收到账户数据后缓存到本地,此缓存带有merkle-patriciatree功能;循环执行步骤208~步骤210,直到获取到所有的账户数据
步骤211、当获得所有账户数据后,启动数据处理过程,获得最终的merkle-patriciatreeroothash,若该hash与图1中获得的roothash相比一致则通过,不一致则通过账户列表数据检查数据完整性、正确性,可随机选择其他节点,继续发送“获取账户数据”命令以请求缺失的账户数据或校验数据;
步骤212、因执行上述步骤需要数秒到数分钟时间,此期间区块链会产生新的区块,所以需要请求该期间的区块数据;
步骤213、同步获取到少量区块数据;
步骤214、数据扁平化节点的区块高度与区块链网络一致,并且能正常接收区块数据,则表示已加入区块链网络,并完成区块链数据扁平化过程。
进一步地,区块链中参与共识的数据设置为最新的所有的账户数据快照,每次账户数据的改变都会生成新的一份账户数据快照。
执行区块链中的交易是唯一改变merkle-patriciatree的方式,其中,交易包含转账交易和调用智能合约交易,任何状态的改变都会改变merkle-patriciatree对象,从而改变roothash(roothash指的是merkle-patriciatree根节点的哈希值)。
打包区块的节点或执行区块的节点会执行相关交易,改变merkle-patriciatree对象状态,并把最新的roothash保存在最新的区块数据中,最后形成区块数据广播给其他节点。节点打包区块时会把自己的地址记录到区块中,本地有交易也会一并打包到区块中,最终该区块被整个区块链网络接收,则该节点为打包区块的节点;如果打包区块时打包了本地的交易,则会改变merkle-patriciatree对象状态并计算出最新的roothash值写入区块,区块广播;其他节点接收该区块,也会执行该区块中的交易,也会改变merkle-patriciatree对象状态并计算出最新的roothash值;最终roothash值一致则表示达到共识。
以下将举一具体的例子来说明基于区块链数据扁平化的实施过程:
1)准备一个节点,以数据扁平化标志启动,作为数据扁平化节点f1;
2)准备多个区块链节点n2、n3…,与f1节点建立p2p网络连接;
3)f1收集其中所有区块链节点同一区块数据,比对此区块数据种的roothash,一致则f1保存,不一致则f1继续收集直到获取同一区块数据roothash一致,目的保证数据安全性;
4)f1向一个区块链节点“获取账户”命令,f1最终获取完整的账户列表并缓存本地;
5)f1分别向所有区块链节点发送“获取账户数据”命令,收到命令的区块链节点群根据f1提供的部分账户列表分发数据,最终f1收到并缓存所有的账户数据;
6)f1根据账户数据构建merkle-patriciatree对象,得到roothash与3)中的roothash比对,如果比对不一致,检查缺失数据并重新请求,达到两者hash一致表明得到正确的账户数据快照,最终把账户数据提交到本地数据库;
7)f1同步缺失的少量区块,这些区块是f1在3)到6)过程中期间区块链网络产生,最终f1的区块高度与区块链节点的区块高度一致;
8)用户创建区块链交易从账户a转账10到账户b,往区块链节点n2发出此交易,区块链网络中有节点打包此交易并广播区块数据;
9)f1收到该区块数据,在f1节点分别查询账户a余额减少10,账户b余额增加10,f1在区块链网络不分叉,通过多次转账不同账户和调用智能合约可以得知f1具备数据完整性;
10)f1定期清理历史的区块数据、交易数据、执行交易的结果数据、历史账户快照数据,以达到几乎无沉淀数据,最终实现数据扁平化。
本发明公开的一种基于区块链的数据扁平化方法针对现有技术中随着区块链的高度增加,本地沉淀数据日趋增加的问题,删除本地区块数据、交易数据、执行交易的结果数据、历史账户数据快照,最终节点本地数据最精简,去除冗余和繁杂,达到数据扁平化;如果区块链网络中没有新增账户,那么本方案数据扁平化启动的节点将不会有数据增加。
本发明公开的一种基于区块链的数据扁平化方法针对现有方案中同步数据缓慢、高运算的问题,采用分布式同步账户数据的方式充分利用区块链节点资源,大幅提高构建本地数据的速度,数据扁平化节点可以以任意区块高度启动,无须像现有方案从区块高度0开始同步数据。现有方案同步数据是一种缓慢、高运算的任务,同步的过程就是计算的过程,完整地播放历史的过程;本方案完全丢弃此低效的同步过程,以给定区块数据的roothash为依据,以分布式方式充分利用区块链节点资源,高效构建本地账户数据快照,以形成有效的区块链节点。
本发明公开的一种基于区块链的数据扁平化方法去除了大量冗余的数据,大幅降低硬件资源要求、降低区块链应用落地门槛,如手机、平板等轻型移动设备均可成为区块链节点;采用分布式构建账户数据方式,在网络较好情况下,为轻型设备秒接入区块链成为区块链节点提供基础。
实施例二
本实施例提供了一种基于区块链的数据扁平化系统,包括:
新建模块,用于建立数据扁平化节点;
构建模块,用于数据扁平化节点通过分布式方式获取账户数据,得到账户数据快照,构建本地数据,参与共识;
清理模块,用于定期清理不参与共识的数据,达到区块链节点本地数据库数据扁平化。
进一步地,新建模块具体包括:
准备单元,用于准备一个节点,以数据扁平化标志启动,作为数据扁平化节点;
连接单元,用于数据扁平化节点通过p2p连接多个区块链节点;
对比单元,用于数据扁平化节点收集所有与数据扁平化节点连接的区块链节点同一区块数据,对比区块数据中的roothash,以备校验。
进一步地,构建单元具体包括:
数据扁平化节点以分布式方式向多个区块链节点发送获取账户数据的命令,区块链节点群收到命令并行获取本地数据发送给数据扁平化节点,数据扁平化节点根据得到的本地数据构建本地账户数据,构建最新的账户数据快照对象。
进一步地,区块链中参与共识的数据设置为最新的所有的账户数据快照,每次账户数据的改变都会生成新的一份账户数据快照。
本实施例是为了实现实施一所述方法,其实现方法同实施例一,此处将不再赘述。
实施例三
实施例三
本发明实施例三提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时,实现上述任一项的方法。
该实施例的计算机设备包括:处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,例如数据处理程序。所述处理器执行所述计算机程序时实现上述各个组网方法实施例中的步骤。或者,所述处理器执行所述计算机程序时实现上述各装置实施例中各模块/单元的功能。
示例性的,所述计算机程序可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在所述存储器中,并由所述处理器执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述计算机设备中的执行过程。
所述计算机设备可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。所述计算机设备可包括,但不仅限于,处理器、存储器。
所述处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
所述存储器可以是所述计算机设备的内部存储单元,例如计算机设备的硬盘或内存。所述存储器也可以是所述计算机设备的外部存储设备,例如所述计算机设备上配备的插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。进一步地,所述存储器还可以既包括所述计算机设备的内部存储单元也包括外部存储设备。所述存储器用于存储所述计算机程序以及所述计算机设备所需的其他程序和数据。所述存储器还可以用于暂时地存储已经输出或者将要输出的数据。
本发明实施例还提供了一种存储有计算机程序的计算机可读存储介质,其特征在于,所述计算机程序使计算机执行时实现上述任一项所述的一种基于区块链的数据扁平化方法。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!