雾霾形成的模糊认知图及其多维时间序列挖掘方法与流程
本发明一种雾霾形成的模糊认知图及其多维时间序列挖掘方法,属于大气污染的技术领域。
背景技术:
目前我国(特别是华北地区)雾霾形成呈现一种复杂性“新常态”,主要体现在以下两点。其一,从雾霾形成的污染颗粒物而言,大气污染类型从原来单一型向多变型转变,且多种污染物相互反应形成的“二次污染”日益凸显。其二,从气象条件来说,它的变化可能对雾霾形成产生巨大影响,其中全球气候变暖使得局部“极端天气”呈现多变性,厄尔尼诺的扰动导致雾霾发生的可能性增加;其次,我国西北部以治理风沙为目的的“三防工程”,以及内蒙南部与张北的大型风力电站,可能对华北地区的风力造成了一定的影响;另一方面,“南水北调工程”也许对该地区的湿度(形成雾霾的重要条件)产生了一定的影响。
在这种“新常态”下,雾霾预警的误报、漏报率较高,给城市交通、居民健康和心理带来了重大影响,削弱了雾霾防治决策与治理措施实施的效果。究其原因,雾霾形成具有模糊复杂性、动态非线性、混沌性,而传统的方法缺少研究雾霾形成因素间的非线性复杂关系,难以模拟它的动态演化过程,对形成条件发生微小变化的敏感度不够,直接导致雾霾应急预警与实际发生的不符。
事实上,雾霾形成是一个复杂的模糊系统,它涉及到以pm2.5为主的微细颗粒物、气象条件等,是它们共同作用的结果。污染物之间、气象条件之间、气象条件和污染物与雾霾形成之间都存在着复杂迭代的认知关系,比如空气中pm2.5主要有以固态形式排放出的一次粒子和nox、so2等前体污染物通过大气化学反应生成的二次粒子两种。因此,从模糊认知关系的角度为雾霾形成系统建模、研究系统中的复杂关系是雾霾形成研究的一重要科学问题。
而且,雾霾形成中隐藏着规模巨大的数据资源,这些监测数据(如各污染物排放浓度,气象状况的时序监测数据等)为雾霾形成的研究提供了海量的数据“样本”。因此,如何以这些时序数据为驱动,从巨大的历史数据中学习训练雾霾形成系统的非线性、动态变化,挖掘雾霾形成中的模糊认知关系(值),是雾霾形成亟待解决的一个科学问题。
为此,本发明另辟途径,从复杂模糊系统的视角对雾霾形成进行认知建模,以近年来华北地区出现的雾霾天气“样本”为驱动,模拟“新常态”下雾霾形成的演变过程,以揭示其中的非线性复杂关系。
技术实现要素:
本发明解决的技术问题:
雾霾形成是一个动态复杂系统,如何根据对雾霾形成的认知,构建雾霾形成模糊认知图,并提出一种在海量数据的驱动下进行雾霾形成模糊认知图的多维时间序列挖掘。
本发明的技术方案:
①雾霾形成的模糊认知图构建
根据fcm与雾霾形成复杂系统的原理,构建适用于这类复杂系统的主子结构模糊认知图ps-fcm的一般形式,数学模型如公式(1)、(2)所示。
其中,
公式(2),其中
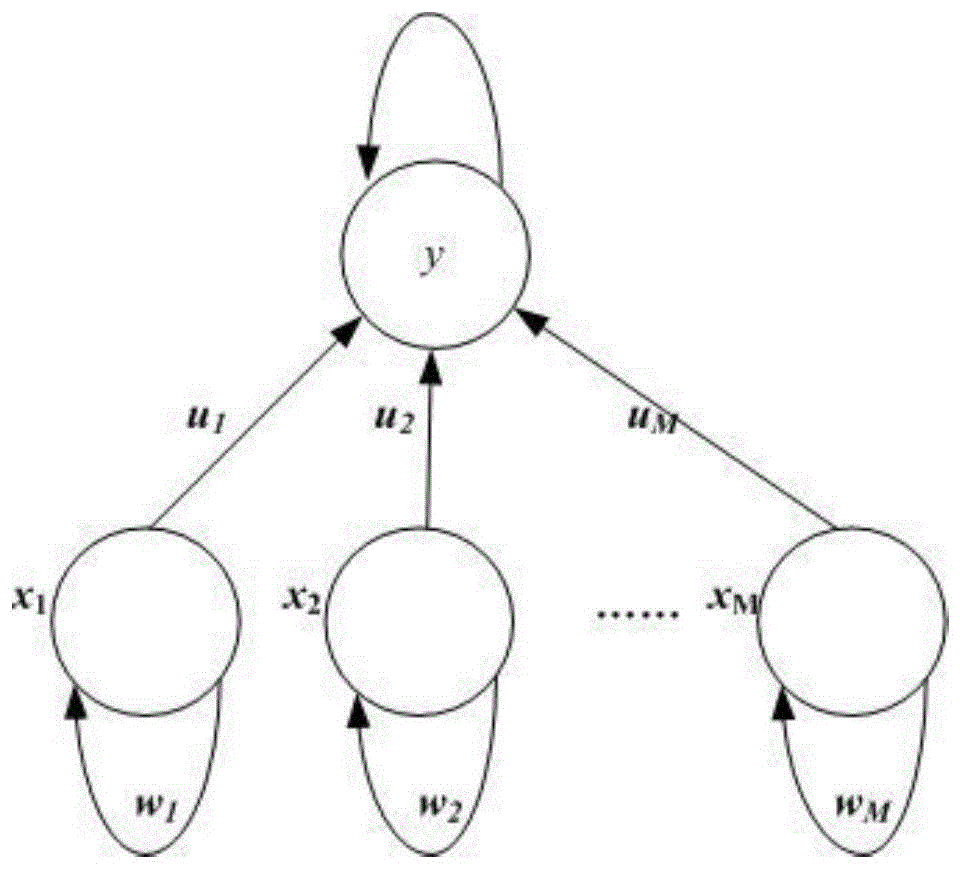
具体的,对雾霾形成,污染物的模糊认知子图表达为公式(2),气象的模糊认知子图表达为公式(2),与雾霾形成模糊认知主图表达为公式(1),从而形成主子结构的模糊认知图ps-fcm如图1,它是一个与时间相关的动态系统,如图2所示。
②雾霾形成模糊认知图的多维时间序列挖掘方法
在雾霾形成预测中,基于雾霾形成模糊认知图见公式(5),目标et是使预测结果与实际结果的差值最小。
在雾霾形成模糊认知图中u={…uji…}和
其中,定义
本发明的优点在于:本发明是针对雾霾形成这类复杂系统的特点,提出一种主子结构的模糊认知图ps-fcm,它包括一个模糊认知主图p-fcm和多个模糊认知子图s-fcms,在此基础上给出了ps-fcm的多维时间序列挖掘方法。它不仅可用于多维时间序列预测,还可以用于多维复杂关系的揭示。
附图说明
图1是集成多模糊认知子图于一体的主子结构模糊认知图。
图2是主子结构模糊认知图的动态结构。
具体实施方式
本发明获取的数据包括,第一类是污染物浓度,来自北京环境保护检测中心,时间跨度从2015/1/2到2017/3/10,pm2.5,so2,no2,o3,co等污染物的实时排放浓度,每三个小时采集一次(2:00,5:00,8:00,11:00,14:00,17:00,20:00and23:00),共六千多条数据;第二类是气象条件数据,来自开放web网站https://rp5.ru/,时间跨度从2015/1/2到2017/3/10,有温度(t)、大气压(p)、相对湿度(rh)、风速(wp)以及是否为雾霾(haze)等气象的实时动态,每三个小时采集一次(2:00,5:00,8:00,11:00,14:00,17:00,20:00and23:00)。
第一步,使用pm2.5、so2、no2、o3、co五个维度的特征构建污染物模糊认知子图,使用温度(t)、大气压(p)、相对湿度(rh)、风速(wp)四个维度构建气象模糊认知子图,与雾霾(haze)情况一同构建主子结构的雾霾形成模糊认知图ps-fcm。
其中,
第二步,进行数据的模糊化处理,使用
j∈{pm2.5,no2,co,o3,so2,t,p,rh,wp};min(xi)为第i维数据集最小值,max(xi)为第i维数据集最大值。在原始数据中,雾霾一维特征的实际状态有两种0和1。
第三步,随机初始化权重向量u和w,基于上述获取的数据,根据公式(6)更新权重向量u和w中的任一向量,直到满足公式(5)为止。
第四步,得到最优的权重向量u和w,基于权重向量u和w,将t-1时数据带入公式(1)与公式(2)得到t时的预测结果
第五步,根据反模糊化处理xit=(max(xi)-min(xi))ait+min(xi)得到预测的原始结果
采用不同阈值函数f中不同的参数c值,参数c为公式(3)和公式(4)中转换函数f中的参数,是得到预测结果如表1-表6所示。
表1不同阈值函数与参数下的单个维度预测结果
表1中,就雾霾单个变量的预测结果来看,i.三种函数和参数都达到了较好的区分效果;ii.在参数c=5时的tan-sigmoid函数预测结果更接近实际值。值得注意的是,在参数c=1时的tan-sigmoid函数预测结果与参数c=5时的tan-sigmoid函数预测结果相比,有较小的取值范围。
表2不同阈值函数与参数下的多维度预测结果
表2中,在雾霾形成多个维度的预测结果来看,在参数c=1时的tan-sigmoid函数预测结果在三种情况下是最好的,如表2所示。
表3多维度预测结果
表3中,在参数c=1时的tan-sigmoid函数预测结果与实际值的均方误差。
表4多维因素对雾霾的影响权重
表4中,从ps-fcm的主模糊认知图(主系统)中即u可以看到,二氧化氮(no2)是雾霾形成的主要污染物,气压(p)是雾霾形成的主要气象条件,整体来讲,气象条件对雾霾形成的影响高于污染物的影响。
表5污染物子系统中的影响权重
表5中,在ps-fcm中的污染物子系统中,pm2.5是最主要的污染物,在对pm2.5的贡献中,no2排放是对pm2.5影响最大的,而且它对其他污染物影响也是最大的;此外不能忽视的还有臭氧(o3),它的排放对pm2.5影响也较大。
表6气象子系统中的影响权重
表6中,在ps-fcm中的气象子系统中,气压是对其他气象条件影响的主要因素。
- 还没有人留言评论。精彩留言会获得点赞!