一种动态场景下基于语义分割的直接法视觉定位方法与流程
本发明涉及深度学习在视觉里程计(visualodometry)中的应用,属于slam(simultaneouslocalizationandmapping)同步定位与建图领域。
背景技术:
视觉slam(同时定位与建图,带有回环检测)或vo(视觉里程计,不带回环检测)是机器人在未知环境下自主运行的关键技术。基于机器人外部传感器检测到的环境数据,slam构造了机器人的周围环境图,同时给出了机器人在环境图中的位置。与雷达、声纳等测距仪器相比,视觉传感器具有体积小、功耗低、信息采集丰富等特点,能够在外部环境中提供丰富的纹理信息。因此,视觉slam已经成为当前研究的热点,并应用于自主导航、vr/ar等领域。
传统的视觉slam(带有回环检测)或者vo(不带回环检测)在恢复场景信息和相机运动时是基于静态环境假设的。场景中的动态物体会影响定位精度。目前,传统的基于点特征的视觉slam算法通过检测动态点并将其标记为外点来处理简单的动态场景问题。orb-slam通过ransac、卡方检验、关键帧法和局部地图减少了动态物体对定位精度的影响。2013年,有学者提出了一种新的关键帧表达和更新方法,用于对动态环境进行自适应建模,有效地检测和处理动态环境中的外观或结构变化。同年,有学者引入了多摄像机间姿态估计和建图的方法用于处理动态场景。2018年有学者提出将深度学习中的语义分割技术与现有的slam或者vo系统结合,通过语义分割获得场景中的动态物体先验信息,在特征点提取过程中剔除动态物体特征,为后续定位提供稳健的静态区域特征点。上述基于深度学习的方法都是特征点法,显著提高了基于特征点的视觉slam系统在动态环境下的定位精度和鲁棒性。基于直接法的slam或vo在动态场景中的定位精度有待提高。
技术实现要素:
本发明所要解决的技术问题是:
为了提升传统vo在动态场景下的定位精度和鲁棒性,提供一种动态场景下基于语义分割的直接法视觉定位方法,能够对场景中的动态物体进行分割,降低场景中的动态物体对定位的干扰。
本发明为解决上述技术问题采用以下技术方案:
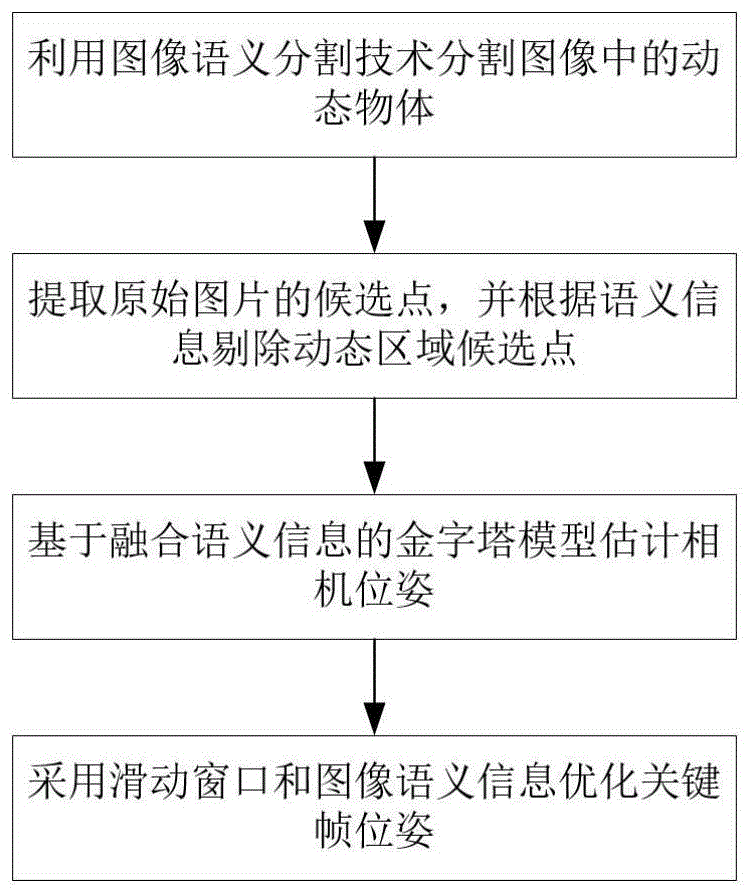
一种动态场景下基于语义分割的直接法视觉定位方法,包括以下步骤:
步骤1、采集原始图像,并利用深度学习中的图像语义分割技术分割所述原始图像中的动态物体,获得包含动态物体像素级语义信息的语义图像;
步骤2、在所述原始图像中提取候选点,并根据步骤1获取的语义图像剔除动态区域候选点,仅保留静态区域候选点;
步骤3、基于步骤2中保留的静态区域候选点,结合图像金字塔模型和步骤1获取的语义图像估计相机位姿;
步骤4、基于滑动窗口和和步骤1获得的语义信息的语义图像对关键帧位姿进行优化。
作为本发明一种动态场景下基于语义分割的直接法视觉定位方法的进一步优选方案,在步骤1中,获得包含动态物体像素级语义信息的语义图像,具体包含如下步骤:
步骤1.1、定义常见动态物体类别,所定义类别中,动态物体包括:人、自行车、汽车、摩托车、飞机、公共汽车、火车、卡车、船、鸟、猫、狗、马、羊、牛、大象、熊、斑马、长颈鹿;
步骤1.2、对于原始图像i,将其输入到语义分割卷积神经网络maskr-cnn中对图像中包含的步骤1.1所述动态物体进行分割,获得包含动态物体像素级语义信息的语义图像isem;其中,所述语义分割卷积神经网络maskr-cnn已知;isem是黑白图像,其中,黑色区域像素值为0,且代表动态区域;白色区域像素值为1,且代表静态区域;
步骤1.3、对由原始图像组成的图像序列i={i1,i2,i3,i4,…,in}进行所述步骤1.1至1.2的操作,最终得到仅包含动态物体的语义图像序列
作为本发明一种动态场景下基于语义分割的直接法视觉定位方法的进一步优选方案,在步骤2中,在原始图像中提取候选点,并保留静态区域候选点,具体包含如下步骤:
步骤2.1、对于关键帧ii,将其划分成d×d的图像块;
步骤2.2、设定梯度阈值t,对于每一个图像块,选择在该图像块的所有像素点中梯度最大且大于阈值t的像素点p作为预选候选点;
步骤2.3、若图像块中所有像素点的梯度均小于阈值t,令t'=0.75×t,选择在该图像块的所有像素点中梯度最大且大于阈值t'的像素点p作为预选候选点;
步骤2.4、设定像素间隔d,记p点上、下、左、右间隔为d的四个像素点为p1,p2,p3,p4;
步骤2.5、对于p点及其相邻的p1,p2,p3,p4,根据语义图像
若
若
作为本发明一种动态场景下基于语义分割的直接法视觉定位方法的进一步优选方案,在步骤3中,采用金字塔模型恢复相机运动,具体包含如下步骤:
步骤3.1、对于关键帧ii,以0.5的缩放因子对图像进行缩放,分别获得相对于ii分辨率
步骤3.2、对于后续帧ij及其对应的语义图像
步骤3.3、对于
其中,p'是p在
步骤3.4、对于每个候选点p,根据其在
步骤3.5、将
步骤3.6、以在k-1层的相对位姿优化结果tk-1作为本次优化的初值,利用高斯牛顿法对
步骤3.7、对金字塔的所有层按照由上至下的顺序重复步骤3.3-3.6,最终获得关键帧ii和后续帧ij之间的相对位姿tk;
作为本发明一种动态场景下基于语义分割的直接法视觉定位方法的进一步优选方案,在步骤4中,采用滑动窗口和语义信息对关键帧位姿进行优化,具体包含如下步骤:
步骤4.1、对于关键帧ii中的单个点p,它投影到滑动窗口中另一关键帧il上形成的光度误差为:
其中p'是p在il上的投影点,ti和tl分别是图像ii和il的曝光时间,ai,al,bi,bl是图像的光度传递函数参数,np是包括p点及周围相邻点共8个点的集合,wp是权重因子,‖.‖γ是huber范数;
步骤4.2、对于关键帧ii每个候选点p,根据其在il中投影点p'的位置,计算一个剔除标签cpl决定该点的投影残差是否去除:
步骤4.3、遍历滑动窗口内的所有关键帧,将关键帧中的所有候选点向窗口内其他关键帧进行投影,统计并累加所有的光度误差:
其中,f是滑动窗口内所有关键帧的集合,pi是关键帧ii中所有候选点的集合,obs(p)指能够观测到p点的关键帧集合;
步骤4.4、利用高斯牛顿法对efull进行优化,即可获得所有关键帧的优化后的位姿,完成对相机运动的跟踪。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明首先采用深度学习中的有监督学习方式对原始图像中的动态物体进行分割,得到语义图像;在此基础上,从原始图像中提取候选点并根据语义图像对动态物体候选点进行剔除,从而提升了传统基于直接法的视觉里程计在动态场景下的定位精度和鲁棒性;
2、本发明提出的方法定位结果优于传统的dso的定位结果,在动态场景中的定位精度提高71%到86%。
附图说明
图1是本方法流程图;
图2是图像金字塔表示图;
图3是dso在三个动态序列中的定位轨迹平面图;
图4是本方法在三个动态序列中的定位轨迹平面图;
图5是dso与本方法在三个动态序列的定位轨迹误差对比图;
图6是dso与本方法在三个动态序列的x,y,z三轴上的定位结果对比图;
图7是dso与本方法在三个动态序列的定位误差箱型图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本技术领域技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
随着深度学习技术的发展,人们对图像的语义信息进行了探索,借此提高视觉slam的性能。语义分割是计算机视觉中的基本任务,在语义分割中需要将视觉输入分为不同的语义可解释类别。本发明提出一种动态场景下基于语义分割的直接法视觉定位方法,旨在通过降低动态物体干扰,提高动态场景下视觉里程计的定位精度,同时可以获得场景丰富的语义信息。
本发明提出一种动态场景下基于语义分割的直接法视觉定位方法,图1是本方法流程图。本发明首先采用深度学习中的语义分割技术对图像中的动态物体进行分割,获得像素级别的动态物体语义信息;在此基础上,从原始图像中根据像素点梯度信息提取候选点并根据语义信息对动态区域的候选点进行剔除,仅保留静态区域的候选点;然后基于保留的候选点采取融合图像语义信息的金字塔模型估计相机位姿;最后基于滑动窗口优化并结合图像语义信息对关键帧的位姿进行优化,完成对相机的运动跟踪。
步骤1,获得包含动态物体像素级语义信息的语义图像:
步骤1.1、定义常见动态物体类别,所定义类别中,动态物体包括:人、自行车、汽车、摩托车、飞机、公共汽车、火车、卡车、船、鸟、猫、狗、马、羊、牛、大象、熊、斑马、长颈鹿;
步骤1.2、对于原始图像i,将其输入到语义分割卷积神经网络maskr-cnn中对图像中包含的步骤1.1.1所述动态物体进行分割,获得包含动态物体像素级语义信息的语义图像isem。其中所述maskr-cnn已知;isem是黑白图像,其中黑色区域像素值为0,代表动态区域;白色区域像素值为1,代表静态区域;
步骤1.3、对由原始图像组成的图像序列i={i1,i2,i3,i4,…,in}进行所述步骤1.1.1至1.1.2的操作,最终得到仅包含动态物体的语义图像序列
步骤2,在原始图像中提取候选点,并保留静态区域候选点:
步骤2.1、对于关键帧ii,将其划分成d×d的图像块;
步骤2.2、设定梯度阈值t,对于每一个图像块,选择在该图像块的所有像素点中梯度最大且大于阈值t的像素点p作为预选候选点;
步骤2.3、若图像块中所有像素点的梯度均小于阈值t,令t'=0.75×t,选择在该图像块的所有像素点中梯度最大且大于阈值t'的像素点p作为预选候选点;
步骤2.4、设定像素间隔d,记p点上、下、左、右间隔为d的四个像素点为p1,p2,p3,p4;
步骤2.5、对于p点及其相邻的p1,p2,p3,p4,根据语义图像
若
若
步骤3,采用金字塔模型恢复相机运动:
步骤3.1、对于关键帧ii,以0.5的缩放因子对图像进行缩放,分别获得相对于ii分辨率
步骤3.2、对于后续帧ij及其对应的语义图像
步骤3.3、对于
其中p'是p在
步骤3.4、对于每个候选点p,根据其在
步骤3.5、将
步骤3.6、以在k-1层的相对位姿优化结果tk-1作为本次优化的初值,利用高斯牛顿法对
步骤3.7、对金字塔的所有层按照由上至下的顺序重复步骤1.3.3-1.3.6,最终获得关键帧ii和后续帧ij之间的相对位姿tk;
步骤4,采用滑动窗口和语义信息对关键帧位姿进行优化:
步骤4.1、对于关键帧ii中的单个点p,它投影到滑动窗口中另一关键帧il上形成的光度误差为:
其中p'是p在il上的投影点,ti和tl分别是图像ii和il的曝光时间,ai,al,bi,bl是图像的光度传递函数参数,np是包括p点及周围相邻点共8个点的集合,wp是权重因子,‖.‖γ是huber范数;
步骤4.2、对于关键帧ii每个候选点p,根据其在il中投影点p'的位置,计算一个剔除标签cpl决定该点的投影残差是否去除:
步骤4.3、遍历滑动窗口内的所有关键帧,将关键帧中的所有候选点向窗口内其他关键帧进行投影,统计并累加所有的光度误差:
其中f是滑动窗口内所有关键帧的集合,pi是关键帧ii中所有候选点的集合,obs(p)指能够观测到p点的关键帧集合。
步骤4.4、利用高斯牛顿法对efull进行优化,即可获得所有关键帧的优化后的位姿。
实施例一
本发明利用添加动态物体噪声的euroc公开数据集详细评估在场景中的定位性能。euroc数据集中的图像的采集频率为20hz,分辨率为752x480,每张图片均匹配由运动捕获系统提供的高精度位姿真值,是静态场景数据集。我们将连续运动的动态行人视为一种噪声,人为合成到图像序列中,添加动态物体后的图像序列由静态场景变为动态场景。分别对euroc数据集中的v1_01,v2_01,v2_02三个序列添加了动态物体,并记修改后的数据序列的名称分别为v101_syn,v201_syn,v202_syn。,
实验基于一台配备有128gb内存、intelxeone5-2690v4cpu(14核,2.6ghz)和nvidiatitanvgpu(12g显存)的深度学习工作站,系统版本为ubuntu16.04。
图3和图4展示了dso与本方法在v101_syn,v201_syn,v202_syn中的定位轨迹平面图,本方法估计的轨迹相较于dso更加与真值更加贴近。
图5对比了本方法与dso在v101_syn,v201_syn,v202_syn的定位轨迹误差对比图。从中可以看出,dso的误差在相当一部分时间超过了1m,且波动明显。在v202_syn序列中的误差最大值超过了4m,不能满足室内定位的精度需求。本方法的轨迹误差较dso降低非常明显,最大值为v202_syn序列中的0.557m,且整个定位过程误差波动幅度小。
图6为dso与本法估计轨迹的xyz三轴定位结果随时间的变化情况,可以看出,相较于dso,本方法在各个轴中的定位结果均与真值均更加贴近。
图7为本法与dso的轨迹误差的箱形图,用于分析误差的离散分布情况。对比发现,在三个数据序列中,本文方法定位误差的上限和下限值均低于dso,中位数和上下四分位数较小,异常值较少,箱体扁平,表明本方法的轨迹误差分布较为集中,验证了本法在三个动态场景数据序列中的定位精度和算法鲁棒性均优于dso。
表1给出了本方法与dso在v101_syn,v201_syn,v202_syn三个动态场景序列的轨迹误差统计结果。从均方根误差(rmse)可以看出,本文算法通过结合图像语义分割后,定位精度较dso提升71%-86%。
表1
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!