基于监督语义耦合一致的跨模态哈希检索方法及系统与流程
本发明属于电子商务,多媒体智能及数据挖掘技术领域,特别涉及一种基于监督语义耦合一致的跨模态哈希检索方法及系统。
背景技术:
随着网络智能媒体技术的快速发展,信息检索也呈现多元化形态,而多元化检索的需求不仅仅涉及到传统单一模态情景下的内容检索,也涉及到多模态之间互相关的内容检索,通过多模态信息检索能够更加全面的展现检索内容所包含的数据信息。如:可利用检索的文本信息,产生对应语义相关性的图像信息、视频信息、语音信息等各种模态数据信息。而不同模态之间的信息关联性需在检索前,进行相应的信息挖掘,从而诞生了通过利用一种模态的信息内容来搜索与之关联的其他模态数据的方法,称为跨模态检索技术。
为了能够将各模态下的信息建立相互关联性,通过构建一种公共子空间的方式,通过利用投影映射转换将各个模态下的数据特征信息进行相似性度量,实现各个模态下关联度较大的特征具有内联性,既而有效解决跨模态数据信息的检索。如:论文“rasiwasian,pereirajc,covielloe,etal.anewapproachtocross-modalmultimediaretrieval.”中提出了一种相关分析cca方法,通过构建投影矩阵进行最大化度量各个模态数据特征信息间的相似性;论文“putthividhyad,attiasht,nagarajanss.topicregressionmulti-modallatentdirichletallocationforimageannotation.”中通过借鉴狄利克雷模型,构建了基于主题回归模型的跨模态检索方法,其分别对不同模态进行独自学习该模态的潜在主题信息,结合回归模型来建立各个模态间的潜在主题关系,能够较好的刻画不同模态间的语义关联性,但是这类方法通常对模态的主体分布要求有较强的假设,为此在实际应用过程中具有一定的局限性。鉴于不同模态的类型不一致且分布在各种空间中,当前主流方法是通过学习不同模态类型特征的中间的公共空间,并在共同空间中对各个模态特征进行相似性度量,以此实现跨模态的检索;然而大多数算法都忽略了模态特征表示的语义关联性,即没有充分考虑到各个模态间的语义信息以及各模态自身的内联信息,导致模态特征类别辨析度不强,降低查询的精准性和鲁棒性。
技术实现要素:
本发明的目的在于提供一种能使得各个模态不仅能够监督学习到自身的哈希码,同时也能够保持各个模态间的语义一致性的跨模态哈希检索方法及系统。
实现本发明目的的技术解决方案为:一种基于监督语义耦合一致的跨模态哈希检索方法,包括以下步骤:
步骤1,提取各模态数据库中模态样本数据的特征,构建样本库集合;
步骤2,求取样本库集合中各模态样本的哈希编码;
步骤3,提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码;
步骤4,对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果。
进一步地,步骤1所述提取各模态数据库中模态样本数据的特征,构建样本库集合,具体包括:
步骤1-1,针对每一模态,构建其对应的数据特征提取模型,并对该模型进行训练;
步骤1-2,利用训练后的模型提取对应模态样本数据的特征;
步骤1-3,根据提取的特征构建样本库集合{p_marry,q_marry,y_marry},其中p_marry=[p1,p2,p3…,ps]为第一模态数据特征矩阵,q_marry=[q1,q2,q3…,qs]为第二模态数据特征矩阵,y_marry=[y1,y2,y3…,ys]为标签数据特征矩阵。
进一步地,步骤2所述求取样本库集合中各模态样本的哈希编码,具体包括:
步骤2-1,构建各模态对应的线性分离器损失函数;
针对第一模态数据特征矩阵中的样本pi,假设其转化后的哈希二位码为
式中,
针对第二模态数据特征矩阵中的样本qi,假设其转化后的哈希二位码为
式中,
步骤2-2,定义第一模态和第二模态的邻近区域相似性矩阵分别为
式中,nm(p)为第一模态特征数据p的m近邻集合,nm(q)为第二模态特征数据q的m近邻集合;
由此构建模态近邻约束损失函数:
式中,ν为模态近邻约束损失函数的约束平衡参数;
步骤2-3,利用矩阵运算将模态近邻约束损失函数转换为:
式中,tr(·)为矩阵的迹,
步骤2-4,利用映射矩阵f1、f2分别将第一模态和第二模态特征转换为对应的哈希编码矩阵:
b1=f1p_marry,b2=f2q_marry
由此构建各个模态相互间的耦合语义一致性损失函数:
式中,λ、θ均为耦合语义一致性损失函数的平衡参数;
步骤2-5,结合上述步骤2-1至步骤2-4,构建全局损失函数:
步骤2-6,求解所述全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值;
步骤2-7,进一步求取符号函数sign(b1)和sign(b2),分别获得样本库集合中第一模态、第二模态对应的离散哈希编码矩阵。
进一步地,步骤2-7求解所述全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值,采用的求解方式为:求解某一参数时,固定其余参数,进行迭代更新优化求解,直至收敛。
进一步地,步骤3所述提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码,具体过程包括:
假设待检索模态数据的特征为d,根据步骤2-7获得的f1或f2求取待检索模态数据的哈希编码:
b=f1d或f2d
之后进一步求取待检索模态数据的离散哈希编码:
b=sign(b)=sign(f1d)或sign(f2d)。
进一步地,步骤4所述对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果,具体包括:
求取待检索模态数据的哈希编码与各模态样本的哈希编码的汉明距离;
将小于预设阈值的汉明距离对应的模态样本作为待检索模态数据的检索结果。
一种基于监督语义耦合一致的跨模态哈希检索系统,所述系统包括:
样本库构建模块,用于提取各模态数据库中模态样本数据的特征,构建样本库集合;
第一求取模块,用于求取样本库集合中各模态样本的哈希编码;
第二求取模块,用于提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码;
检索模块,用于对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果。
进一步地,所述样本库构建模块包括:
模型构建及训练单元,用于针对每一模态,构建其对应的数据特征提取模型,并对该模型进行训练;
特征提取单元,用于利用训练后的模型提取对应模态样本数据的特征;
样本库构建单元,用于根据提取的特征构建样本库集合{p_marry,q_marry,y_marry},其中p_marry=[p1,p2,p3…,ps]为第一模态数据特征矩阵,q_marry=[q1,q2,q3…,qs]为第二模态数据特征矩阵,y_marry=[y1,y2,y3…,ys]为标签数据特征矩阵。
进一步地,所述第一求取模块包括:
第一损失函数构建单元,用于构建各模态对应的线性分离器损失函数;
针对第一模态数据特征矩阵中的样本pi,假设其转化后的哈希二位码为
式中,
针对第二模态数据特征矩阵中的样本qi,假设其转化后的哈希二位码为
式中,
第二损失函数构建单元,用于定义第一模态和第二模态的邻近区域相似性矩阵分别为
式中,nm(p)为第一模态特征数据p的m近邻集合,nm(q)为第二模态特征数据q的m近邻集合;
由此构建模态近邻约束损失函数:
式中,ν为模态近邻约束损失函数的约束平衡参数;
第三损失函数构建单元,用于利用矩阵运算将模态近邻约束损失函数转换为:
式中,tr(·)为矩阵的迹,
第四损失函数构建单元,用于利用映射矩阵f1、f2分别将第一模态和第二模态特征转换为对应的哈希编码矩阵:
b1=f1p_marry,b2=f2q_marry
由此构建各个模态相互间的耦合语义一致性损失函数:
式中,λ、θ均为耦合语义一致性损失函数的平衡参数;
第五损失函数构建单元,用于结合上述损失函数,构建全局损失函数:
第一求取单元,用于求解所述全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值;
第二求取单元,用于求取符号函数sign(b1)和sign(b2),分别获得样本库集合中第一模态、第二模态对应的离散哈希编码矩阵。
进一步地,所述检索模块包括:
第三求取单元,用于求取待检索模态数据的哈希编码与各模态样本的哈希编码的汉明距离;
检索单元,用于将小于预设阈值的汉明距离对应的模态样本作为待检索模态数据的检索结果。
本发明与现有技术相比,其显著优点为:1)将各个模态数据学习到各自具有判别性的离散哈希码,且对每个模态间的哈希表示进行交替耦合表示,并结合模态数据的局部流行结构一致性,有效提升了各模态学到的哈希码的判别力度和紧凑鲁棒性,同时也提高了模态内间的数据信息区分能力;2)考虑到多媒体模态数据量不断增长,需使用高效的模态检索方式来进行处理,为此本发明利用学习到的编码二进制哈希码,加速各个模态间的检索速率,有利于实现对大规模数据集进行快速检索。
下面结合附图对本发明作进一步详细描述。
附图说明
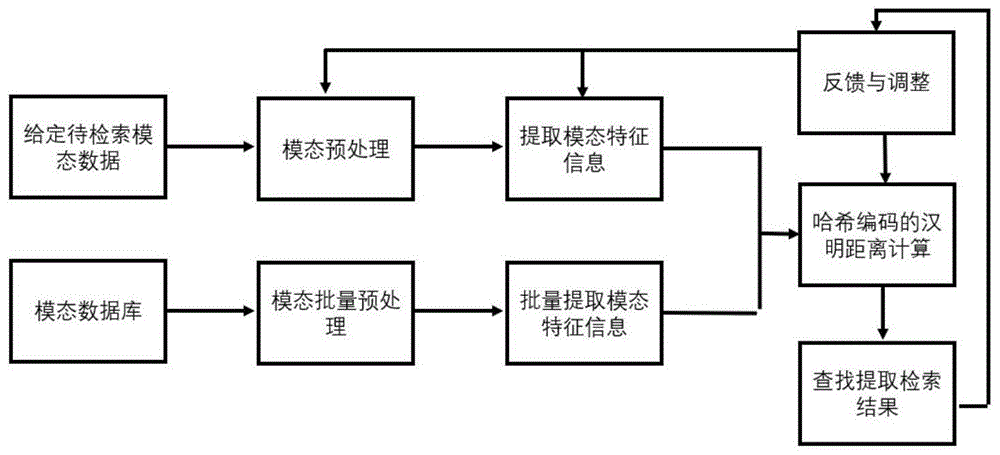
图1为一个实施例中基于监督语义耦合一致的跨模态哈希检索方法的流程图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
在一个实施例中,结合图1,提供了一种基于监督语义耦合一致的跨模态哈希检索方法,该方法包括以下步骤:
步骤1,提取各模态数据库中模态样本数据的特征,构建样本库集合;
步骤2,求取样本库集合中各模态样本的哈希编码;
步骤3,提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码;
步骤4,对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果。
进一步地,在其中一个实施例中,上述步骤1提取各模态数据库中样本数据的特征,构建样本库集合,具体包括:
步骤1-1,针对每一模态,构建其对应的数据特征提取模型,并对该模型进行训练;
步骤1-2,利用训练后的模型提取对应模态样本数据的特征;
步骤1-3,根据提取的特征构建样本库集合{p_marry,q_marry,y_marry},其中p_marry=[p1,p2,p3…,ps]为第一模态数据特征矩阵,q_marry=[q1,q2,q3…,qs]为第二模态数据特征矩阵,y_marry=[y1,y2,y3…,ys]为标签数据特征矩阵。
进一步地,在其中一个实施例中,上述步骤2求取样本库集合中各模态样本的哈希编码,具体包括:
步骤2-1,为了能够学习各个模态的哈希映射,将各个模态映射到汉明空间中,构建线性分离器模型来学习各个模态的哈希编码:
针对第一模态数据特征矩阵中的样本pi,假设其转化后的哈希二位码为b1i以及对应的标签为yi,由此构建第一模态线性分离器损失函数:
式中,
针对第二模态数据特征矩阵中的样本qi,假设其转化后的哈希二位码为
式中,
步骤2-2,为了能够保持第一模态以及第二模态在其原始空间中的流行近邻关系,定义第一模态和第二模态的邻近区域相似性矩阵分别为
式中,nm(p)为第一模态特征数据p的m近邻集合,nm(q)为第二模态特征数据q的m近邻集合;
为此构建模态近邻约束损失函数:
式中,ν为模态近邻约束损失函数的约束平衡参数;
步骤2-3,利用矩阵运算将模态近邻约束损失函数转换为:
式中,tr(·)为矩阵的迹,
步骤2-4,为了能够使得第一模态和第二模态分别学习到相互之间的语义一致性,利用映射矩阵f1、f2分别将第一模态和第二模态特征转换为对应的哈希编码矩阵:
b1=f1p_marry,b2=f2q_marry
由此构建各个模态相互间的耦合语义一致性损失函数为:
式中,λ、θ为耦合语义一致性损失函数的平衡参数,以使耦合语义一致性损失函数在求解参数时达到最优。
步骤2-5,结合上述步骤2-1至步骤2-4,构建全局损失函数:
步骤2-6,求解上述全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值;
步骤2-7,求取符号函数sign(b1)和sign(b2),分别获得样本库集合中第一模态、第二模态对应的离散哈希编码矩阵。这里,符号函数b=sign(a)表示,如果a值大于等于0,则b值对应转换为1值,如果a值小于0值,则b值转换为0值。
进一步地,在其中一个实施例中,由于lloss目标函数是一个非凸函数,无法直接进行求解,因此上述步骤2-7求解全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值,采用的求解方式为:求解某一参数时,固定其余参数,进行迭代更新优化求解,直至收敛。
具体过程包括:
利用随机矩阵对参数b1,b2,f1,f2,w1,w2进行初始化处理;
通过中心化处理对第一模态特征和第二模态特征矩阵p_marry、q_marry构建拉普拉斯矩阵;
固定参数b1,b2,f1,f2,w1,对w2求偏导;
固定参数b1,b2,f1,f2,w2,对w1求偏导;
固定参数b1,b2,f1,w1,w2,对f2求偏导;
固定参数b1,b2,f2,w1,w2,对f1求偏导;
固定参数b1,f1,f2,w1,w2,对b2求偏导;
固定参数b2,f1,f2,w1,w2,对b1求偏导。
通过不断迭代更新上述未知六个参数,直到收敛。
进一步地,在其中一个实施例中,上述步骤3提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码,具体过程包括:
假设待检索模态数据的特征为d,根据步骤2-7获得的f1或f2求取待检索模态数据的哈希编码:
b=f1d或f2d
之后进一步求取待检索模态数据的离散哈希编码:
b=sign(b)=sign(f1d)或sign(f2d)。
进一步地,在其中一个实施例中,上述步骤4对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果,具体包括:
求取待检索模态数据的哈希编码与各模态样本的哈希编码的汉明距离;
将小于预设阈值的汉明距离对应的模态样本作为待检索模态数据的检索结果。
作为一种具体示例,以图像模态和文本模态为例,本发明基于监督语义耦合一致的跨模态哈希检索方法包括:
1)构建13个卷积层,3个全连接层和5个池化层的卷积神经网络vgg16模型,并对vgg16模型进行训练,之后利用训练后的vgg16模型对图像模态数据库中的图像进行特征提取;
2)构建一个全局向量glove模型对文本数据进行建模,其通过对单词进行转换成具有语义特性向量形式,对glove模型进行训练,之后利用训练后的glove模型对文本模态数据库中的文本进行特征提取。
3)根据上述提取的特征构建样本库集合{p_marry,q_marry,y_marry},其中p_marry=[p1,p2,p3…,ps]为图像数据特征矩阵,q_marry=[q1,q2,q3…,qs]为文本数据特征矩阵,y_marry=[y1,y2,y3…,ys]为标签数据特征矩阵。
4)针对图像数据特征中的样本pi,假设其转化后的哈希二位码为
式中,
5)针对文本数据特征矩阵中的样本qi,假设其转化后的哈希二位码为
其中,
6)为了能够保持图像模态以及文本模态在其原始空间中的流行近邻关系,定义图像和文本模态的邻近区域相似性矩阵
其中,nm(p)为图像特征数据p的m近邻集合,nm(q)为文本特征数据q的m近邻集合。这里,优选地,设定m=5。
7)由于图像模态的特征信息在局部区域内具有相似性,为此利用哈希二位码进行相似性度量,从而约束图像和文本的具有近邻一致性,为此构建模态近邻约束损失函数:
式中,ν为损失函数的约束平衡参数;
利用矩阵运算将上述模态近邻约束损失函数转换为:
式中,tr(·)为矩阵的迹,
8)为了能够使得图像模态和文本模态分别学习到相互之间的语义一致性,利用映射矩阵fima,ftex分别将文本和图像特征转换对应的哈希编码矩阵:
bima=fimap_marry,btex=ftexq_marry
为此构建各个模态相互间的耦合语义一致性损失函数:
9)根据上述过程构建全局损失函数:
10)求解全局损失函数,获取参数bima,btex,fima,ftex,wima,wtex的值,采用的求解方式为:求解某一参数时,固定其余参数,进行迭代更新优化求解,直至收敛。
11)求取符号函数sign(bima)和sign(btex),分别获得样本库集合中图像模态、文本模态对应的含有0和1的离散哈希编码矩阵。
12)假设待检索模态数据为图像模态时,利用fima求取待检索模态数据的哈希编码:
bima=fimad
进而求取待检索模态数据的离散哈希编码bima:
bima=sign(bima)=sign(fimad)
之后求取待检索模态数据的哈希编码bima与数据库中文本模态对应的哈希编码的汉明距离,汉明距离最小的即为搜索到的待检索图像模态对应的文本模态中相似的样本数据信息;
假设待检索模态数据为文本模态时,利用ftex求取待检索模态数据的哈希编码:
btex=ftexd
进而求取待检索模态数据的哈希编码btex:
btex=sign(btex)=sign(ftexd)
之后求取待检索模态数据的哈希编码btex与数据库中图像模态对应的哈希编码的汉明距离,汉明距离最小的即为搜索到的待检索文本模态对应的图像模态中相似的样本数据信息。
在一个实施例中,提供了一种基于监督语义耦合一致的跨模态哈希检索系统,该系统包括:
样本库构建模块,用于提取各模态数据库中模态样本数据的特征,构建样本库集合;
第一求取模块,用于求取样本库集合中各模态样本的哈希编码;
第二求取模块,用于提取待检索模态数据的特征,并根据该特征求取待检索模态数据的哈希编码;
检索模块,用于对比待检索模态数据的哈希编码与各模态样本的哈希编码,对比结果符合预设条件的模态样本即作为待检索模态数据的检索结果。
进一步地,在其中一个实施例中,上述样本库构建模块包括:
模型构建及训练单元,用于针对每一模态,构建其对应的数据特征提取模型,并对该模型进行训练;
特征提取单元,用于利用训练后的模型提取对应模态样本数据的特征;
样本库构建单元,用于根据提取的特征构建样本库集合{p_marry,q_marry,y_marry},其中p_marry=[p1,p2,p3…,ps]为第一模态数据特征矩阵,q_marry=[q1,q2,q3…,qs]为第二模态数据特征矩阵,y_marry=[y1,y2,y3…,ys]为标签数据特征矩阵。
进一步地,在其中一个实施例中,上述第一求取模块包括:
第一损失函数构建单元,用于构建各模态对应的线性分离器损失函数;
针对第一模态数据特征矩阵中的样本pi,假设其转化后的哈希二位码为
式中,
针对第二模态数据特征矩阵中的样本qi,假设其转化后的哈希二位码为
式中,
第二损失函数构建单元,用于定义第一模态和第二模态的邻近区域相似性矩阵分别为
式中,nm(p)为第一模态特征数据p的m近邻集合,nm(q)为第二模态特征数据q的m近邻集合;
由此构建模态近邻约束损失函数:
式中,ν为模态近邻约束损失函数的约束平衡参数;
第三损失函数构建单元,用于利用矩阵运算将模态近邻约束损失函数转换为:
式中,tr(·)为矩阵的迹,
第四损失函数构建单元,用于利用映射矩阵f1、f2分别将第一模态和第二模态特征转换为对应的哈希编码矩阵:
b1=f1p_marry,b2=f2q_marry
由此构建各个模态相互间的耦合语义一致性损失函数:
第五损失函数构建单元,用于结合上述损失函数,构建全局损失函数:
第一求取单元,用于求解全局损失函数,获取参数b1,b2,f1,f2,w1,w2的值;
第二求取单元,用于求取符号函数sign(b1)和sign(b2),分别获得样本库集合中第一模态、第二模态对应的离散哈希编码矩阵。
进一步地,在其中一个实施例中,上述检索模块包括:
第三求取单元,用于求取待检索模态数据的哈希编码与各模态样本的哈希编码的汉明距离;
检索单元,用于将小于预设阈值的汉明距离对应的模态样本作为待检索模态数据的检索结果。
综上,本发明不仅考虑了高层语义关系,同时还考虑了各个模态之间的内联耦合性,使得各个模态不仅能够监督学习到自身的哈希码,同时也能够保持各个模态间的语义一致性。本发明能够有效提升哈希码的判别力度和紧凑鲁棒性,加速模态间的检索速率,提升跨模态检索的准确率。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!