一种基于多实例学习的信用风险评估模型生成方法与流程
本发明涉及信用评估领域,具体涉及一种基于多实例学习的信用风险评估模型生成方法。
背景技术:
随着信息时代的快速发展,信用风险评估成为金融机构研究的重要课题之一。它是将不确定性转化为风险控制过程。高质量的风险管理使银行能够建立健全的决策体系,减少损失。根据巴塞尔银行监管委员会巴塞尔协议ii将银行风险分为三类:(1)信用风险,(2)市场风险,(3)经营风险。因此,从银行安全的角度来看,信用风险已成为银行业研究的一个重要课题,信用风险评估被认为是一个复杂的多维问题,它主要是基于大量的历史数据,如监护人,工作状态,以前的信用历史,个人帐户状态等,目的是了解申请人的行为和预测风险。因此,信用风险度量和管理体系的制定主要着眼于申请人的分类或信用评分。
且在专利名称为:“一种基于文本分析的信用风险评估方法及装置”(申请号:2015106953161,申请公布日:2017.05.03)中公开了一种基于文本分析的信用风险评估方法及装置,其中,所述方法还包括:获取借款人的文本;对所述文本进行分析,得到基本语言特征,所述基本语言特征用于预测借款人是否会违约;将所述基本语言特征输入到预设的信用风险评估模型,得到从所述信用风险评估模型输出的所述借款人的信用风险值;输出所述借款人的信用风险值。
上述专利汇中使用到了例如线性判别分析(lda)和逻辑回归(lr)等方法用于构建信用评估模型。这些统计方法因其简单易操作、易于实现而得到广泛的应用。然而,它们相对较差的预测性能限制了它们的使用,尤其是在具有大量特征维的大型数据集上。为了有效地使用信用评估模型,信用评估模型必须在分类性能和可解释性之间寻求良好的平衡。
技术实现要素:
本发明创新地提出一种基于多实例学习的信用风险评估模型生成方法,能够解决用户数据高维度、无标签问题,以提高风险评估模型的准确率与召回率。
本发明的技术方案如下所示:
一种基于多实例学习的信用风险评估模型生成方法,包括以下步骤:
s1:收集用户的相关数据源信息,具体包括个人信息数据和历史动态行为数据;
s2:对获取到的数据源信息利用最小hausdorff距离聚类特征提取用户的历史行为特征向量;
s3:将所述历史行为特征向量和个人信息数据进行结合,构建新向量数据集;
s4:采用基于径向基函数的多实例学习方法对上述结合的新向量数据集进行训练,基于评价模型指标函数来构建信用风险评估模型;
s5:对所述信用风险评估模型的效果进行预测,通过适应度函数来检验模型的正确性。
优选的,步骤s2中所述的用户历史行为特征向量的提取过程具体为:
s2.1:将s1的历史动态行为数据聚集成k个集群;
s2.2:通过每个集群中心的距离映射到历史行为特征向量中,采用距离函数d为最小hausdorff距离度量,具体定义为:
s2.3:将历史行为特征向量记为
优选的,步骤s2.3中所述的标准差
优选的,步骤s3中所述新向量数据集的具体构建步骤为:
s3.1:将所述历史行为特征向量
s3.2:将用户的个人信息数据记为向量
s3.3:构建新向量
其中
优选的,步骤s5中适应度函数为质量函数和风险函数。
优选的,所述质量函数为对正确性的评分,其计算公式为:
更优选的,所述风险函数为通过计算信息值来区分高风险属性和低风险属性,其中高负值表示高风险,高正值表示低风险,计算公式为:
本发明的有益效果为:本发明中利用机器学习中的多实例学习方法结合径向基函数对用户相关数据集进行综合风险评估,解决了用户数据高维度、无标签问题,实现了最小化风险、最小化复杂性和最大化准确性的目标,不仅提高了信用风险评估模型的运行效率也提高了模型准确性和可解释性。
附图说明
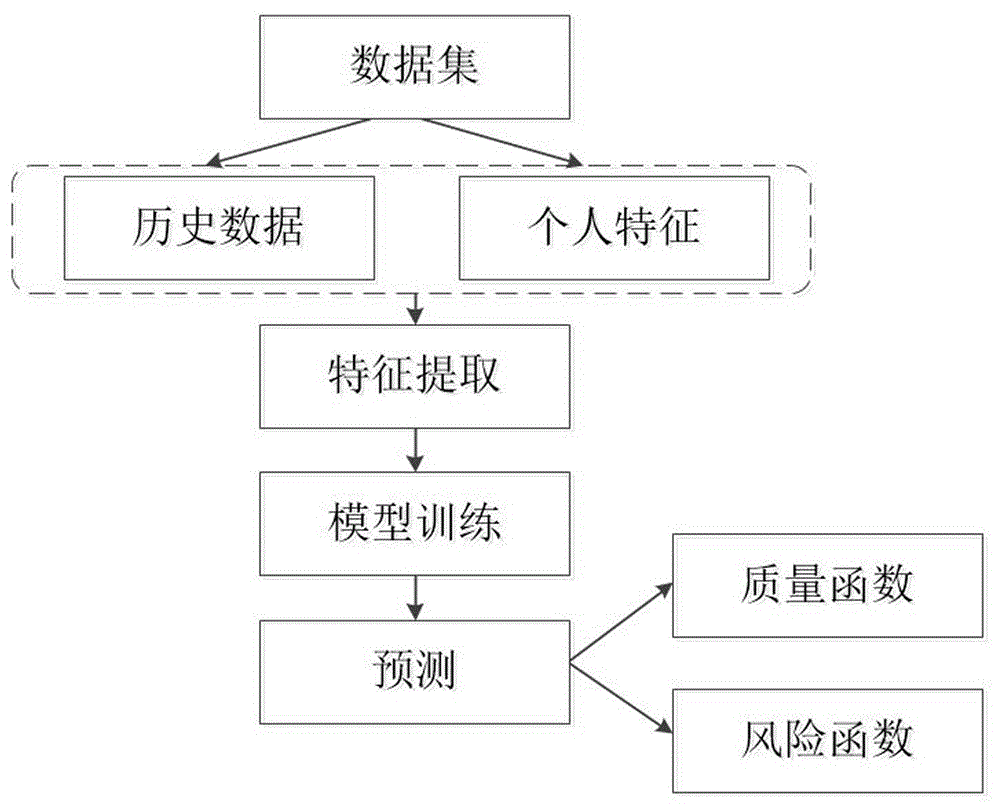
图1为本发明中信用风险评估模型生成的流程图。
具体实施方式
下面将结合附图对本发明的实施例进行详细的描述。
一种基于多实例学习的信用风险评估模型生成方法,如图1所示,包括以下步骤:
s1:收集用户的个人信息数据和历史动态行为数据。
s2:对获取到的数据源信息利用最小hausdorff距离聚类特征提取用户的历史行为特征向量,具体包括以下步骤:将历史动态行为数据聚集成k个集群。在聚集之前需要对数据集进行预处理,首先对缺失数据进行均值补充,并删除重复数据。这里由于数据是高维数据,需要先对数据集进行降维,在本发明中采用lda算法,在降维的同时获得其特征主题。接下来对预处理后的低维数据进行聚集;通过每个集群中心的距离映射到特征向量中,采用距离函数d为最小hausdorff距离度量,具体定义为:
s3:将所述历史行为特征向量和个人信息数据进行结合,构建新向量数据集,具体包括以下步骤:将通过上述步骤所获得的历史行为特征向量
s4:采用基于径向基函数的多实例学习方法对上述结合的新向量数据集进行训练,基于评价模型指标函数来构建信用风险评估模型,评价函数为
其中
s5:对所述信用风险评估模型的效果进行预测,通过两个适应度函数,即质量函数和风险函数,来检验模型的正确性。
其中质量函数为对正确性的评分,如果具有较高的精度分数,则认为解决方案具有较高的质量。其目的是最大限度地提高质量的规则生成的基础上收集的历史样本数据。实际上,使质量函数最大化意味着使数据集验证的正确分类规则最大化。其计算公式为:
风险函数为通过计算信息值来区分高风险属性和低风险属性,其中高负值表示高风险,高正值表示低风险,计算公式为:
以金融领域为例,用户历史动态行为数据可具体包括:征信查询次数,逾期次数,信用卡是否欠款,是否出国等,将这些行为构建成一个集群,结合用户个人信息,包括年龄、职业、收入、有无子女等构建成为一个新向量,作为多实例学习中的示例,对数据集进行训练,最终的目的是对新用户的信用风险评估类别做出预测。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准,特别指出,对于本领域技术人员来说,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!