一种基于访问局部性的闪存页级地址映射方法及其系统与流程
本发明涉及闪存存储系统领域,具体涉及一种基于访问局部性的闪存页级地址映射方法及其系统。
背景技术:
闪存是一种非易失性存储,其具有高性能、低能耗、小体积和大容量等特点,目前越来越广泛地被应用于嵌入式设备和云数据中心中,取代传统的磁盘式存储介质。但是闪存区别于磁盘的固有特性,包括写前擦除,非对称的读写延迟,有限的寿命等特性,使得传统磁盘算法不能直接应用于闪存存储系统中,需要设计专用的闪存存储系统算法,形成闪存转换层为操作系统提供块设备接口,并充分发挥闪存的高性能特点,因此越来越多的研究集中于闪存存储算法中。
当前闪存地址映射的经典算法主要有dftl,fast和bast,不同映射粒度的映射算法分别存在如下缺点:页级地址映射缓冲区占用空间大,块级地址映射灵活性低,混合地址映射具有高昂的垃圾回收成本并降低了闪存的寿命,应对当前海量数据的存储和计算,传统的闪存映射算法已经无法满足需求。
页级地址映射算法中,最经典的dftl算法未考虑闪存存储系统的访问局部性,将页面回写均写入同一数据块中,造成垃圾回收时高昂的页面回收成本,此外顺序地址映射项未压缩导致顺序地址映射项占用了大量的缓冲区空间,且映射项命中率低,影响了闪存存储系统的地址映射效率。
因此,针对现有技术存在的上述缺点,有必要进行研究,以提供一种方案改善现有技术方案的不足。
技术实现要素:
本发明所要解决的是传统闪存地址映射方法存在垃圾回收成本高,映射效率低,空间浪费严重的问题,提供一种基于访问局部性的闪存页级地址映射方法。
为解决上述问题,本发明采用顺序映射项压缩和预取机制,以及基于聚类的页面温度探测和回写聚集机制,从而减少映射项缓冲区空间占用,提高缓冲区命中率,降低垃圾回收成本,保障闪存存储系统的耐久性。
为了克服现有技术存在的缺陷,本发明的技术方案如下:
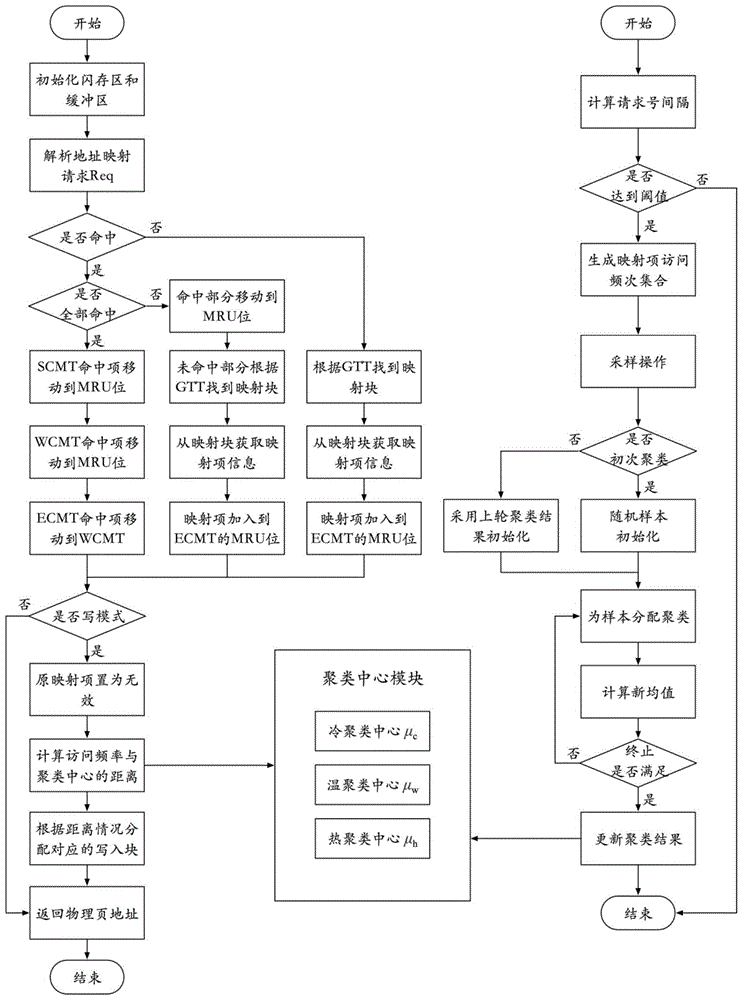
一种基于访问局部性的闪存页级地址映射方法,包含地址映射流程和聚类流程。
其中,地址映射流程包含以下步骤s1到s6:
步骤s1:初始化闪存区和缓冲区,将闪存区划分为数据块db和映射块mb,将缓冲区分为缓存映射表cmt和全局转换表gtt,具体是:
步骤s11:将闪存区进行初始化,将闪存区划分为若干数据块db和若干映射块mb,其中每个数据块用于存储数据信息,每个映射块用于存储地址映射信息,以便于寻找对应数据块;所有映射块的集合构成全局映射表gmt,闪存区中数据块占用了大部分的块资源,即闪存区中映射块所在资源比例大于数据块;映射块mb由若干映射页组成,映射页由若干映射项组成;
步骤s12:将缓冲区进行初始化,将缓冲区划分为cmt表和gtt表,其中gtt表用于存储各映射块在闪存中的位置信息;cmt表包括顺序缓存映射表scmt,工作缓存映射表wcmt和交换缓存映射表ecmt,三个表均用于记录当前活跃的缓存映射项;
上述scmt用于记录连续的地址映射项,即从连续的逻辑地址映射到相应的连续物理地址的映射项,该连续映射项由逻辑地址lpn、物理地址ppn和映射长度range三者组成;wcmt和ecmt均用于记录单一逻辑地址到单一物理地址的映射项,该映射项由逻辑地址lpn、物理地址ppn两者组成,其中wcmt用于存储ecmt命中导致的转移映射项,ecmt用于存储初次缓存的地址映射项和wcmt中淘汰的映射项。
步骤s2:在闪存区和缓冲区初始化完成后,对每一个到达的地址映射请求req,根据请求信息中逻辑地址,判断缓冲区是否发生命中,并判断命中类型为未命中,全部命中或部分命中;
所述地址映射请求req的请求信息包含reqlpn、reqrange和reqmode,其中reqlpn表示请求的逻辑地址,reqrange表示请求的范围大小,reqmode表示请求的读写模式。
步骤s3:根据命中情况的不同,分别进行不同的缓冲区维护和地址映射查询,具体是:
步骤s31:若地址映射请求在缓冲区中全部命中,则将scmt、wcmt中的命中项转移到当前所在映射表的最近被访问位置(简称mru位置),将ecmt中的命中项转移到wcmt的mru位置;若在映射项加入wcmt前,wcmt已满则根据最近最久未访问策略(简称lru策略)驱逐lru位置的映射项到ecmt中;
步骤s32:若地址映射请求在缓冲区中部分命中,则将命中部分如同步骤s31中的策略进行缓冲区维护(即如同s31中,将scmt、wcmt中的命中项转移到当前所在映射表的mru位置,将ecmt中的命中项转移到wcmt的mru位置;若在映射项加入wcmt前,wcmt已满则根据lru策略驱逐lru位置的映射项到ecmt中),未命中部分则根据gtt找到缓冲区中的映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续地址映射项(连续地址映射项是指逻辑页地址和物理页地址都保持连续的相邻映射项的集合),若是则将整个连续映射项预取加入scmt的mru位置,若否则加入ecmt的mru位置;若在映射项加入ecmt或scmt前,ecmt或scmt已满,则进行lru策略驱逐lru位置的映射项到闪存;
步骤s33:若地址映射请求在缓冲区中未命中,则采用s32中未命中部分进行缓冲区维护(即如同s32根据gtt找到缓冲区中的映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续映射项,若是则将整个连续映射项预取加入scmt的mru位置,若否则加入ecmt的mru位置;若在映射项加入ecmt或scmt前,ecmt或scmt已满,则进行lru策略驱逐lru位置的映射项到闪存)。
本发明区别于其他技术方案采用了顺序地址映射压缩技术,将连续地址映射项压缩为单一的scmt中的连续映射项,减少了缓冲区空间的损耗,此外连续映射项预取技术使得缓冲区的利用率和映射项的命中率都得到提升;
步骤s34:查询地址映射请求req对应的地址映射项,找到请求项逻辑地址reqlpn对应的物理地址reqppn;
步骤s4:对映射请求req,判断映射请求信息中的reqmode类型是否为写模式,若是则进入步骤s5,若否则进入步骤s6;
步骤s5:对写请求执行异地更新,并将原映射项置为无效,具体是:
步骤s51:获取当前的最新聚类中心,根据当前请求逻辑地址的访问频次,计算当前请求逻辑地址访问频次与冷聚中心μc、温聚中心μw和热聚中心μh的距离distance,计算如下:
其中d为逻辑地址访问频次f和聚类中心μ的维度,fi和μi分别表示访问频次f和聚类中心μ第i维的大小,由于访问频次维度均为一维,因此d为常数1。
步骤s52:页面温度评估:
根据公式(1),聚类归属为距离distance最小值所对应的聚集中心,若该聚类归属为冷聚中心则页面评估为冷页,若该聚类归属为温聚中心则页面评估为温页,若该聚类归属为热聚中心则页面评估为热页;根据聚类归属分配相应的写入块,同时将原映射项置为无效。其中写入块为冷写入块cb、温写入块wb或热写入块hb。
页面温度评估中的页面是指请求的逻辑地址reqlpn所指向的页面;
区别于现有技术方案,本发明基于页面的访问局部性特征评估页面,将页面的异地更新分配到物理地址不同的块中,使得相同的块中页面具有相似的局部性特征,从而降低页面的垃圾回收开销和访问延迟;
步骤s6:返回请求逻辑地址对应的物理地址reqppn。
聚类流程包含步骤s1,如下所示:
步骤s1:采用改进后k-means聚类方法对映射项进行聚类,得到冷聚中心μc、温聚中心μw和热聚中心μh,具体是:
步骤s11:判断当前请求序号与上一次执行聚类时的请求序号间隔是否到达到序号阈值λ,若是则进入步骤s12,否则进入步骤s17。
区别于现有聚类方案,本发明采用改进的基于请求间隔周期的聚类来减少聚类的频次,此外聚类算法独立于地址映射请求逻辑,不会对地址映射请求产生阻塞,从而降低聚类对闪存存储系统的性能消耗并降低地址请求的延迟;
步骤s12:根据公式(2)计算映射表中的映射项的访问频次flpn,计算公式如下所示:
其中n为逻辑地址lpn对应映射项的访问次数,ln(range)为scmt中连续映射项的映射范围的对数;
进而得到缓冲区中所有映射项的访问频次集合s,如下所示:
s={fmin,…,flpn.…,fmax|min≤lpn≤max,lpn∈cmt}(3)
步骤s13:对集合s进行采样,采样结果形成集合sample;若此次为初次聚类则使用sample集合中的随机三项作为聚类的初始聚类中心,否则采用上一轮聚类的结果(即冷聚中心μc、温聚中心μw和热聚中心μh)作为初始聚类中心。
本发明的初始化优化策略不同于常规聚类,仅在初次聚类中采用随机样本初始化,后续聚类均采用上一轮的聚类结果作为新聚类的初始聚类中心,在访问负载变动不大的情况下可以更快地收敛,此外本方法区别于现有的技术方案在原始映射项访问频次数据基础上进一步进行采样,进一步降低了聚类的性能消耗;
步骤s14:计算集合sample中的所有逻辑地址的访问频次与所有聚类中心的欧氏距离,距离计算如下所示:
其中d为逻辑地址访问频次f和聚类中心μ的维度,fi和μi表示访问频次f和聚类中心μ第i维的大小,由于访问频次维度均为一维,因此d为常数1。根据计算的距离,将逻辑地址的访问频次分配到距离最近的聚类;
步骤s15:对于每一个聚类,根据公式(5)计算新的均值点
其中
迭代完毕后的均值集合m如下所示:
其中ω表示聚类迭代停止时的总迭代次数;
步骤s16:计算最终的冷聚中心μc、温聚中心μw和热聚中心μh作为最新的聚类结果,计算如下:
一种基于访问局部性的闪存页级地址映射系统,包括缓冲区,闪存区,聚类执行模块,聚类中心模块以及页面分配模块;其中缓冲区包括顺序缓存映射表scmt,工作缓存映射表wcmt,交换缓存映射表ecmt以及全局转换表gtt,并对地址映射项进行缓存,以提供快速访问而不必访问闪存区中的映射块;闪存区包括数据块db和映射块mb,数据块db存储数据信息,映射块mb存储映射项信息,同时对缓冲区未命中的地址映射项提供访问;聚类执行模块执行聚类操作,通过对映射项聚类得到聚类中心;聚类中心模块存储并更新当前的聚类中心信息;页面分配模块根据聚类中心模块中的信息,对异地更新页面进行页面判别和分配操作。
所述scmt记录连续的地址映射项,即从连续的逻辑地址映射到相应的连续物理地址的映射项;wcmt记录单一的地址映射项,映射项来自ecmt命中导致的转移映射项;ecmt记录单一的地址映射项,其中存储了初次缓存的地址映射项和wcmt中淘汰的地址映射项;gtt记录映射块在闪存中的位置信息。
缓冲区所述缓存是根据地址映射请求在缓冲区中命中情况的不同,分别进行不同的缓冲区维护:若全部命中,则将scmt、wcmt中的命中项转移到所在映射表mru位置,将ecmt中的命中项转移到wcmt的mru位置;若部分命中,则将命中部分如同全部命中策略进行缓冲区维护,未命中部分则根据gtt找到对应映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续地址映射项,若是则将整个连续映射项预取加入scmt的mru位置,若否则加入ecmt的mru位置;若全部未命中,则采用部分命中中未命中策略进行缓冲区维护。
若在映射项加入wcmt前,wcmt已满则根据lru策略驱逐lru位置的映射项到ecmt中;
若在映射项加入ecmt或scmt前,ecmt或scmt已满,则进行lru策略驱逐lru位置的映射项到闪存区。
所述聚类执行模块包括循环检查模块、初始化模块、迭代计算模块以及更新模块;
循环检查模块检查当前聚类条件是否已经满足,即当前请求序号与上一次执行聚类时的请求序号间隔是否达到序号阈值λ;
初始化模块对初始聚类中心进行初始化工作,包含初次随机初始化和后续采用上一轮聚类结果初始化;
迭代计算模块进行聚类中的迭代计算部分,即根据公式(2)计算映射表中的映射项的访问频次flpn,进而得到缓冲区中所有映射项的访问频次集合s;对集合s进行采样,采样结果形成集合sample;根据公式(4)计算集合sample中所有逻辑地址的访问频次与所有聚类中心的欧氏距离,将逻辑地址的访问频次分配到距离最近的聚类;对于每一个聚类,根据公式(6)计算新的均值点
更新模块对聚类中心模块中的三种聚类中心进行更新操作。
所述聚类中心模块包括冷聚类中心,温聚类中心和热聚类中心;冷聚类中心是聚类中心中映射项访问频次最小的聚类中心;温聚类中心是聚类中心中映射项访问频次中等的聚类中心;热聚类中心是聚类中心中映射项访问频次最大的聚类中心。
所述页面分配模块包括页面判别模块和写入块分配模块;页面判别模块根据当前页面与聚类中心模块中各个中心距离情况,判别页面的冷温热属性;写入块分配模块根据页面判别结果分别为不同的页面分配冷写入块cb,温写入块wb以及热写入块hb。
与现有技术相比,本发明具有的有益效果:
(1)映射效率高:本发明采用了顺序地址映射压缩和预取技术,在维持较低的缓冲区空间开销的情况下,提高了缓冲区命中率,改善了现有页级地址映射方法空间占用高,地址映射命中率低的缺点;
(2)访问延迟低:本发明开创性地通过页面温度探测和回写聚集机制,动态地将页面划分到访问局部性相似的块中,降低了垃圾回收开销,并减少了垃圾回收对页面访问延迟的影响,提高了页面访问的稳定性;
(3)计算开销小:本发明在聚类时采用了访问间隔机制和采样机制,大大减少了聚类所需的计算量,此外,在初始化阶段采用上一轮的聚类结果作为本轮聚类的初始聚类中心,在访问负载变动不大的情况下可以更快地收敛。
附图说明
图1为本发明方法的流程图;
图2为本发明系统的结构图;
图3(1)为本发明系统的缓冲区结构图;
图3(2)为本发明系统的页面分配模块结构图;
图3(3)为本发明系统的闪存区结构图;
图3(4)为本发明系统的聚类执行模块结构图;
图3(5)为本发明系统的聚类中心模块结构图;
图4为本发明方法对比现有方案的实验对比图。
具体实施方式
以下将结合附图对本发明提供的技术方案作进一步说明,本方法的流程图如附图1所示。
一种基于访问局部性的闪存页级地址映射方法,包含地址映射流程和聚类流程。
其中,地址映射流程包含以下步骤s1到s6:
步骤s1:初始化闪存区和缓冲区,将闪存区划分为数据块db和映射块mb,将缓冲区分为缓存映射表cmt和全局转换表gtt,具体是:
步骤s11:将闪存区进行初始化,将闪存区划分为若干数据块db和若干映射块mb,其中每个数据块用于存储数据信息,每个映射块用于存储地址映射信息,以便于寻找对应数据块;所有映射块的集合构成全局映射表gmt,闪存区中数据块占用了大部分的块资源,即闪存区中映射块所在资源比例大于数据块;映射块mb由若干映射页组成,映射页由若干映射项组成;
步骤s12:将缓冲区进行初始化,将缓冲区划分为cmt表和gtt表,其中gtt表用于存储各映射块在闪存中的位置信息;cmt表包括顺序缓存映射表scmt,工作缓存映射表wcmt和交换缓存映射表ecmt,三个表均用于记录当前活跃的缓存映射项;
上述scmt用于记录连续的地址映射项,即从连续的逻辑地址映射到相应的连续物理地址的映射项,该连续映射项由逻辑地址lpn、物理地址ppn和映射长度range三者组成;wcmt和ecmt均用于记录单一逻辑地址到单一物理地址的映射项,该映射项由逻辑地址lpn、物理地址ppn两者组成,其中wcmt用于存储ecmt命中导致的转移映射项,ecmt用于存储初次缓存的地址映射项和wcmt中淘汰的映射项。
步骤s2:在闪存区和缓冲区初始化完成后,对每一个到达的地址映射请求req,根据请求信息中逻辑地址,判断缓冲区是否发生命中,并判断命中类型为未命中,全部命中或部分命中;
所述地址映射请求req的请求信息包含reqlpn、reqrange和reqmode,其中reqlpn表示请求的逻辑地址,reqrange表示请求的范围大小,reqmode表示请求的读写模式。
步骤s3:根据命中情况的不同,分别进行不同的缓冲区维护和地址映射查询,具体是:
步骤s31:若地址映射请求在缓冲区中全部命中,则将scmt、wcmt中的命中项转移到当前所在映射表的最近被访问位置(简称mru位置),将ecmt中的命中项转移到wcmt的mru位置;若在映射项加入wcmt前,wcmt已满则根据最近最久未访问策略(简称lru策略)驱逐lru位置的映射项到ecmt中;
步骤s32:若地址映射请求在缓冲区中部分命中,则将命中部分如同步骤s31中的策略进行缓冲区维护(即如同s31中,将scmt、wcmt中的命中项转移到当前所在映射表的mru位置,将ecmt中的命中项转移到wcmt的mru位置;若在映射项加入wcmt前,wcmt已满则根据lru策略驱逐lru位置的映射项到ecmt中),未命中部分则根据gtt找到缓冲区中的映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续地址映射项(连续地址映射项是指逻辑页地址和物理页地址都保持连续的相邻映射项的集合),若是则将整个连续映射项预取加入scmt的mru位置,若否则加入ecmt的mru位置;若在映射项加入ecmt或scmt前,ecmt或scmt已满,则进行lru策略驱逐lru位置的映射项到闪存;
步骤s33:若地址映射请求在缓冲区中未命中,则采用s32中未命中部分进行缓冲区维护(即如同s32根据gtt找到缓冲区中的映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续映射项,若是则将整个连续映射项预取加入scmt的mru位置,若否则加入ecmt的mru位置;若在映射项加入ecmt或scmt前,ecmt或scmt已满,则进行lru策略驱逐lru位置的映射项到闪存)。
本发明区别于其他技术方案采用了顺序地址映射压缩技术,将连续地址映射项压缩为单一的scmt中的连续映射项,减少了缓冲区空间的损耗,此外连续映射项预取技术使得缓冲区的利用率和映射项的命中率都得到提升;
步骤s34:查询地址映射请求req对应的地址映射项,找到请求项逻辑地址reqlpn对应的物理地址reqppn;
步骤s4:对映射请求req,判断映射请求信息中的reqmode类型是否为写模式,若是则进入步骤s5,若否则进入步骤s6;
步骤s5:对写请求执行异地更新,并将原映射项置为无效,具体是:
步骤s51:获取当前的最新聚类中心,根据当前请求逻辑地址的访问频次,计算当前请求逻辑地址访问频次与冷聚中心μc、温聚中心μw和热聚中心μh的距离distance,计算如下:
其中d为逻辑地址访问频次f和聚类中心μ的维度,fi和μi分别表示访问频次f和聚类中心μ第i维的大小,由于访问频次维度均为一维,因此d为常数1。
步骤s52:页面温度评估:
根据公式(1),聚类归属为距离distance最小值所对应的聚集中心,若该聚类归属为冷聚中心则页面评估为冷页,若该聚类归属为温聚中心则页面评估为温页,若该聚类归属为热聚中心则页面评估为热页;根据聚类归属分配相应的写入块,同时将原映射项置为无效。其中写入块为冷写入块cb、温写入块wb或热写入块hb。
页面温度评估中的页面是指请求的逻辑地址reqlpn所指向的页面;
区别于现有技术方案,本发明基于页面的访问局部性特征评估页面,将页面的异地更新分配到物理地址不同的块中,使得相同的块中页面具有相似的局部性特征,从而降低页面的垃圾回收开销和访问延迟;
步骤s6:返回请求逻辑地址对应的物理地址reqppn。
聚类流程包含步骤s1,如下所示:
步骤s1:采用改进后k-means聚类方法对映射项进行聚类,得到冷聚中心μc、温聚中心μw和热聚中心μh,具体是:
步骤s11:判断当前请求序号与上一次执行聚类时的请求序号间隔是否到达到序号阈值λ,若是则进入步骤s12,否则进入步骤s17。
区别于现有聚类方案,本发明采用改进的基于请求间隔周期的聚类来减少聚类的频次,此外聚类算法独立于地址映射请求逻辑,不会对地址映射请求产生阻塞,从而降低聚类对闪存存储系统的性能消耗并降低地址请求的延迟;
步骤s12:根据公式(2)计算映射表中的映射项的访问频次flpn,计算公式如下所示:
其中n为逻辑地址lpn对应映射项的访问次数,ln(range)为scmt中连续映射项的映射范围的对数;
进而得到缓冲区中所有映射项的访问频次集合s,如下所示:
s={fmin,…,flpn.…,fmax|min≤lpn≤max,lpn∈cmt}(3)
步骤s13:对集合s进行采样,采样结果形成集合sample;若此次为初次聚类则使用sample集合中的随机三项作为聚类的初始聚类中心,否则采用上一轮聚类的结果(即冷聚中心μc、温聚中心μw和热聚中心μh)作为初始聚类中心。
本发明的初始化优化策略不同于常规聚类,仅在初次聚类中采用随机样本初始化,后续聚类均采用上一轮的聚类结果作为新聚类的初始聚类中心,在访问负载变动不大的情况下可以更快地收敛,此外本方法区别于现有的技术方案在原始映射项访问频次数据基础上进一步进行采样,进一步降低了聚类的性能消耗;
步骤s14:计算集合sample中的所有逻辑地址的访问频次与所有聚类中心的欧氏距离,距离计算如下所示:
其中d为逻辑地址访问频次f和聚类中心μ的维度,fi和μi表示访问频次f和聚类中心μ第i维的大小,由于访问频次维度均为一维,因此d为常数1。根据计算的距离,将逻辑地址的访问频次分配到距离最近的聚类;
步骤s15:对于每一个聚类,根据公式(5)计算新的均值点
其中
迭代完毕后的均值集合m如下所示:
其中ω表示聚类迭代停止时的总迭代次数;
步骤s16:计算最终的冷聚中心μc、温聚中心μw和热聚中心μh作为最新的聚类结果,计算如下:
本方法对应的系统模块及其子模块如附图2和附图3所示。
一种基于访问局部性的闪存页级地址映射系统,包括缓冲区100,闪存区300,聚类执行模块400,聚类中心模块500以及页面分配模块200;其中缓冲区100包括顺序缓存映射表scmt101,工作缓存映射表wcmt102,交换缓存映射表ecmt103以及全局转换表gtt104,并对地址映射项进行缓存,以提供快速访问而不必访问闪存区中的映射块302;闪存区包括数据块db301和映射块mb302,数据块db301存储数据信息,映射块mb302存储映射项信息,同时对缓冲区未命中的地址映射项提供访问;聚类执行模块400执行聚类操作,通过对映射项聚类得到聚类中心;聚类中心模块500存储并更新当前的聚类中心信息;页面分配模块200根据聚类中心模块500中的信息,对异地更新页面进行页面判别和分配操作。
所述scmt101记录连续的地址映射项,即从连续的逻辑地址映射到相应的连续物理地址的映射项;wcmt102记录单一的地址映射项,映射项来自ecmt103命中导致的转移映射项;ecmt103记录单一的地址映射项,其中存储了初次缓存的地址映射项和wcmt102中淘汰的地址映射项;gtt104记录映射块在闪存中的位置信息。
缓冲区100所述缓存是根据地址映射请求在缓冲区中命中情况的不同,分别进行不同的缓冲区维护:若全部命中,则将scmt101、wcmt102中的命中项转移到所在映射表mru位置,将ecmt103中的命中项转移到wcmt102的mru位置;若部分命中,则将命中部分如同全部命中策略进行缓冲区维护,未命中部分则根据gtt104找到对应映射块,在映射块中根据请求的reqlpn找到需要查找的映射项,然后判断该映射项周围是否出现连续地址映射项,若是则将整个连续映射项预取加入scmt101的mru位置,若否则加入ecmt103的mru位置;若全部未命中,则采用部分命中中未命中策略进行缓冲区维护。
若在映射项加入wcmt102前,wcmt102已满则根据lru策略驱逐lru位置的映射项到ecmt中;
若在映射项加入ecmt103或scmt101前,ecmt103或scmt101已满,则进行lru策略驱逐lru位置的映射项到闪存区。
所述聚类执行模块400包括循环检查模块401、初始化模块402、迭代计算模块403以及更新模块404;
循环检查模块401检查当前聚类条件是否已经满足,即当前请求序号与上一次执行聚类时的请求序号间隔是否达到序号阈值λ;
初始化模块402对初始聚类中心进行初始化工作,包含初次随机初始化和后续采用上一轮聚类结果初始化;
迭代计算模块403进行聚类中的迭代计算部分,即根据公式(2)计算映射表中的映射项的访问频次flpn,进而得到缓冲区中所有映射项的访问频次集合s;对集合s进行采样,采样结果形成集合sample;根据公式(4)计算集合sample中所有逻辑地址的访问频次与所有聚类中心的欧氏距离,将逻辑地址的访问频次分配到距离最近的聚类;对于每一个聚类,根据公式(6)计算新的均值点
更新模块404对聚类中心模块中的三种聚类中心进行更新操作。
所述聚类中心模块500包括冷聚类中心501,温聚类中心502和热聚类中心503;冷聚类中心501是聚类中心中映射项访问频次最小的聚类中心;温聚类中心502是聚类中心中映射项访问频次中等的聚类中心;热聚类中心503是聚类中心中映射项访问频次最大的聚类中心。
所述页面分配模块200包括页面判别模块201和写入块分配模块202;页面判别模块根据当前页面与聚类中心模块中各个中心距离情况,判别页面的冷温热属性;写入块分配模块根据页面判别结果分别为不同的页面分配冷写入块cb,温写入块wb以及热写入块hb。
采用真实负载仿真平台对本发明的方法和系统进行评估,实验主机配置为英特尔i78700k处理器,32gb3200mhz内存,ubuntu10.04lts操作系统,实验平台选取为基于disksim基础上的flashsim闪存仿真平台,实验数据方面采用了多个真实场景数据集,包括来自金融机构olap的数据集financial1和financial2,以及来自知名搜索引擎的websearch1和websearch2数据集。
在实验中,采用了dftl作为对比算法,实验结果表明,相比于dftl,本发明的方法和系统减少了垃圾回收开销,提升了缓冲区映射表的命中率,减少了块擦除次数。其中,附图4为本方法与对比方法的归一化实验对比图。
与现有技术相比,本发明采用了顺序地址映射压缩和预取技术,在维持较低的缓冲区空间开销的情况下,提高了缓冲区命中率,改善了现有页级地址映射方法空间占用高,地址映射命中率低的缺点;此外,本发明开创性地通过页面温度探测和回写聚集机制,动态地将页面划分到访问局部性相似的块中,降低了垃圾回收开销,并减少了垃圾回收对页面访问延迟的影响,提高了页面访问的稳定性;在聚类时采用了访问间隔机制和采样机制,在初始化阶段采用上一轮的聚类结果作为本轮聚类的初始聚类中心,在访问负载变动不大的情况下可以更快地收敛,减少了聚类所需的计算量。
以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!