一种细胞检测方法与流程
本发明涉及计算机神经网络技术应用领域,尤其涉及一种细胞检测方法。
背景技术:
基于深度卷积神经网络的图像语义分割技术被广泛的应用于细胞检测问题。相比于传统视觉算法,基于深度卷积神经网络的图像语义分割技术取得了显著的性能提升。
一些经典的深度卷积神经网络结构,如fcn(fullyconvolutionalneuralnetworks),u-net和segnet在细胞检测问题中已然成为了基准方案。但由于细胞检测问题中错综复杂的场景,如粘连细胞,背景噪声以及细胞大小和形态的多变,使得这些基于深度卷积神经网络的图像语义分割技术在细胞检测问题上的性能仍有待进一步提升。
目前的一些细胞检测技术由于不能充分利用点标注监督信息进而不能进一步有效提高细胞检测性能。
技术实现要素:
本发明旨在提供一种基于知识蒸馏、更有效地利用点标注信息从而提高细胞检测性能的细胞检测方法。
为达到上述目的,本发明是采用以下技术方案实现的:
一种细胞检测方法,包括以下步骤:
步骤s1:由人工在测试图像上标注点标注信息,并从点标注信息中提取若干个标签;
步骤s2:通过对若干个标签进行联合学习,得到若干个教师模型;
步骤s3:对若干个教师模型的权重进行学习优化;
步骤s4:基于步骤s3中得到的教师模型的权重,生成加权标签,并用于训练单个学生模型;
步骤s5:基于步骤s4中得到的训练后的学生模型完成对细胞检测的测试,得到检测结果。
优选的,在步骤s1中,从点标注信息中提取若干个标签的过程的表达式如下所示:
y′=targetextraction(y′)
={y1,y2,…,yn}
其中y′为点标注,y′为从y′中提取到的若干标签的集合,n为y′中元素的个数;targetextraction的表达式如下:
c=s/2
σ=((s-1)*0.5-1)*0.3+0.8
其中,(i,j)为标签中高斯核的坐标,s为高斯核的尺度,c为高斯核的中心点,σ为高斯核的平滑方差。
进一步的,在步骤s2中,通过步骤s1所得到的若干个标签,构造深度卷积模型输出与n个标签间的联合损失函数losst,如下所示:
其中y为教师模型的输出,n为标签的个数。
进一步的,在步骤s2中,随机生成m组
进一步的,在步骤s3中,将所得到的m个教师模型的输出进行加权,得到加权输出yw如下所示:
其中β为教师模型的权重参数。
进一步的,在步骤s3中,基于加权输出yw和标签y1构建损失函数如下所示:
并基于lossw优化教师模型权重参数β。
进一步的,在步骤s4中,基于所得到的m个教师模型以及教师模型的权重参数,生成加权标签——即用于训练学生模型的标签y′w,如下所示:
进一步的,在步骤s4中,基于得到的标签y′w来构建损失函数losss如下所示:
其中,ys为学生模型的输出,并基于losss优化学生模型参数得到学生模型。
优选的,在步骤s5中,将测试图像输入学生模型,由学生模型生成预测结果图,并采用二维局部极值点查找算法来查找预测结果图中的局部极值点,最后将局部极值点显示到测试图像上,得到检测结果。
优选的,在步骤s5之后,基于性能度量指标,采用全卷积网络fcn作为集成模型来测试性能;所述性能度量指标包括tp、fp、fn、precision、recall、acc以及f1,tp为检测正确的细胞数量,fp为检测错误的细胞数量,fn为漏检的细胞数量,precision为精准率,recall为召回率,f1为整体性能,acc为整体准备率,并由下列关系式表示:
所述全卷积网络fcn为所述教师模型和所述学生模型的基础结构。
本发明具有以下有益效果:
1、本发明从人工标注的点标注信息中提取若干个标签,用于表达点标注的不同形态,相对于当前直接使用点标注信息的做法来讲,这样的做法为更有效地利用点标注信息提供了基础;
2、在本发明中,对教师模型的权重进行学习优化,并基于教师模型优化的加权标签,使得学生模型的预测更为合理,最终提升了细胞检测的综合性能。
附图说明
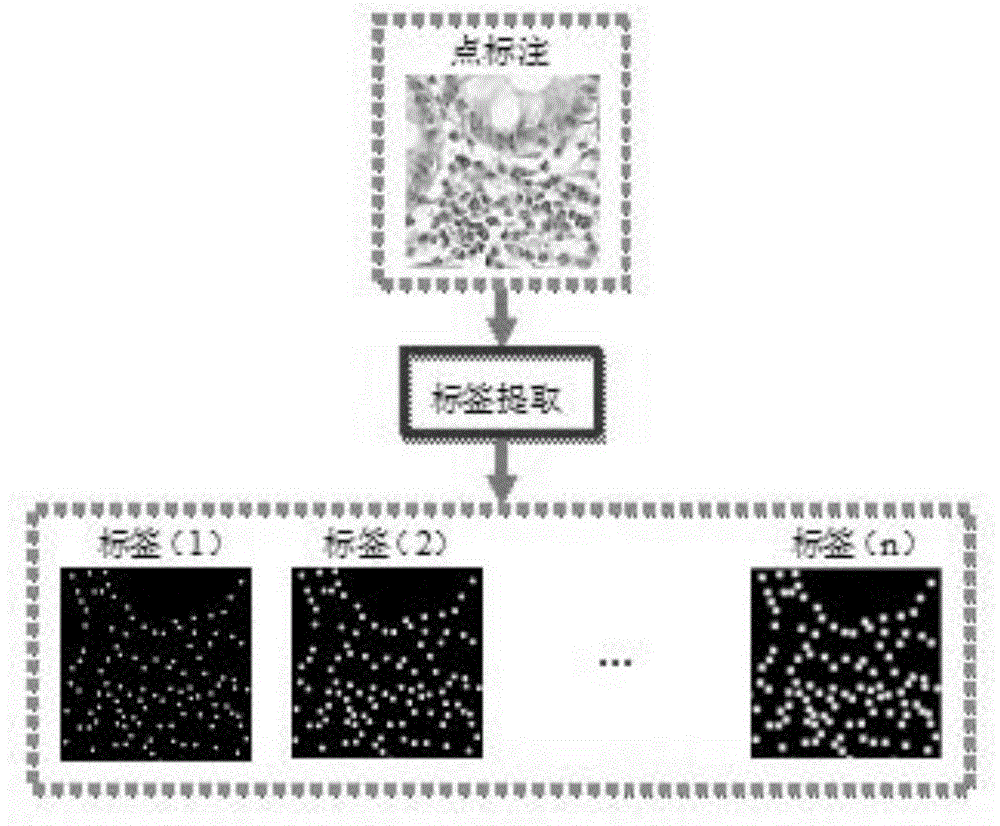
图1为本发明步骤s1中从点标注信息中提取若干个标签的流程图;
图2为本发明步骤s2中教师模型训练流程图;
图3为本发明步骤s3的流程图;
图4为本发明步骤s4的流程图;
图5为本发明步骤s5的流程图;
图6为本发明实施例性能测试结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。
一种细胞检测方法,包括以下步骤:
步骤s1:
不同于目前的一些方法直接使用点标注信息,为了更有效的利用点标注信息,由人工在测试图像上标注好点标注信息,并从点标注信息中提取若干个标签。
从点标注信息中提取若干个标签的过程的表达式如下所示:
y′=targetextraction(y′)
={y1,y2,…,yn}
其中y′为点标注,y′为从y′中提取到的若干标签的集合,n为y′中元素的个数。
基于点标注的多标签提取的流程如图1所示。提取的n个标签是通过采用不同尺度的高斯核标注来表示点标注的不同形态的。targetextraction的表达式如下
c=s/2
σ=((s-1)*0.5-1)*0.3+0.8
其中,(i,j)为标签中高斯核的坐标,s为高斯核的尺度,c为高斯核的中心点,σ为高斯核的平滑方差。最终提取到的多标签示例如图1中的所输出的结果所示。
步骤s2:
教师模型训练的流程如图2所示,通过对若干个标签进行联合学习,得到若干个教师模型。
通过步骤s1所得到的若干个标签,构造深度卷积模型输出与n个标签间的联合损失函数losst,如下所示:
其中y为教师模型的输出,n为标签的个数。
然后随机生成m组
步骤s3:
如图3所示,对若干个教师模型的权重进行学习优化。
具体地,将所得到的m个教师模型的输出进行加权,得到加权输出yw如下所示:
其中β为教师模型的权重参数。
基于加权输出yw和标签y1构建损失函数如下所示:
然后基于lossw优化教师模型权重参数β。
步骤s4:
如图4所示,基于步骤s3中得到的教师模型的权重,生成加权标签,并用于训练单个学生模型。
具体地,基于所得到的m个教师模型以及教师模型的权重参数,生成加权标签——即用于训练学生模型的标签y′w,如下所示:
其中,α等于β。
基于得到的标签y′w来构建损失函数losss如下所示:
其中,ys为学生模型的输出,并基于losss优化学生模型参数得到最终的学生模型。
步骤s5:
如图5所示,基于步骤s4中得到的学生模型完成对细胞检测的测试,得到检测结果。
具体地,将测试图像输入学生模型,由学生模型生成预测结果图,并采用二维局部极值点查找算法来查找预测结果图中的局部极值点,最后将局部极值点显示到测试图像上,得到检测结果。
其中,所述二维局部极值点查找算法可以为python库skimage中集成的peak_local_max方法。
在步骤s5之后,可基于性能度量指标,采用全卷积网络fcn作为集成模型来测试性能。所述性能度量指标包括tp、fp、fn、precision、recall、acc以及f1,tp为检测正确的细胞数量,fp为检测错误的细胞数量,fn为漏检的细胞数量,precision为精准率,recall为召回率,f1为整体性能,acc为整体准备率,并由下列关系式表示:
所述全卷积网络fcn为所述教师模型和所述学生模型的基础结构。
在实施例中,取上述的m=6,n=6,训练集200张大小为1024×1024的图像,验证集60张1024×1024图像,最终性能测试结果如图6所示。其中ours表示本发明所提供技术方案。
从图6中的对比可以看出,本发明所提供技术方案能够在precision和recall指标间达到更好的平衡,最终根据综合评估指标f1和acc上的数据表现,证明本发明所提供技术方案取得了更好的性能。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!