基于机器学习算法的RPV材料辐照脆化预测模型的开发方法与流程
本发明涉及金属材料性能评估领域
技术领域:
,具体涉及一种基于机器学习算法的rpv材料辐照脆化预测模型的开发方法。
背景技术:
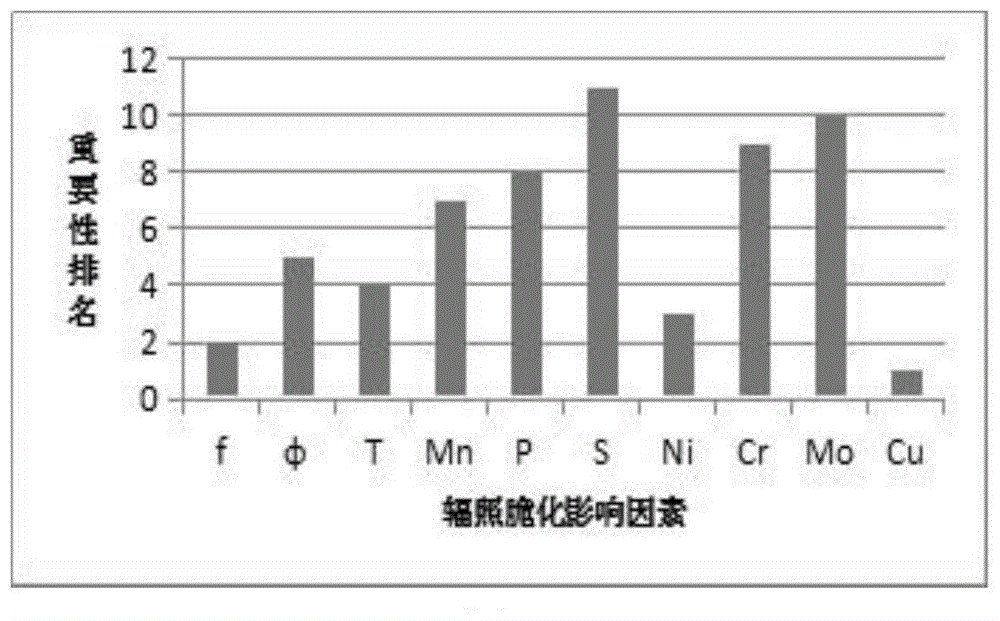
:反应堆压力容器(rpv)是反应堆一回路压力边界,在核电站寿期内不可更换,其安全工作年限成为决定核电厂寿命的关键。rpv在服役期间受快中子(e>1mev)辐照的影响,导致rpv发生辐照脆化效应。辐照脆化将导致在役rpv低应力破断,直接威胁核电站安全。虽然核电厂依据辐照监督大纲开展辐照监督试样的冲击试验可得到rpv钢的韧脆转变温度增量△t41j,但无法连续的评定rpv钢辐照脆化程度,也无法对未来辐照脆化趋势进行预测。因此,开发建立rpv钢辐照脆化预测模型有现实的工程应用需求。尽管现有的模型已经根据辐照脆化机制进行了改进,但由于对rpv辐照脆化机制认知的不足,采用常规基于辐照脆化物理机制建立预测模型的方法在提升模型精度、扩大模型使用范围(运行至60年甚至80年)方面已经难以获得进一步的发展。机器学习是对大量已知信息或数据进行规律总结,并在遇到新问题时形成及时判断、决策及预测的过程。通过机器学习算法可以从相互关联的辐照脆化影响因素中获得辐照性能变化规律。与传统预测模型开发过程相比,机器学习不考虑具体的辐照脆化机制,而是直接从辐照脆化数据入手,通过分析数据内部规律预测辐照性能。技术实现要素:有鉴于此,为了克服现有技术的缺陷以及达到上述目的,本发明的目的是提供一种基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,实现rpv辐照脆化预测模型准确、快捷的建立。为了达到上述目的,本发明采用以下的技术方案:一种基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,包括如下步骤:1)确定rpv辐照脆化的关联因素,所述关联因素至少包括中子注量f、化学元素cu的含量、p含量;2)依据步骤1)确定的关联因素收集rpv辐照脆化数据,数据科目为韧脆转变温度δt41j及步骤1)中的辐照脆化关联因素;3)对步骤2)中收集的辐照脆化数据进行特征选择与数据清洗;4)对经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据进行可视化分析或相关性分析,确定化学元素cu的含量为对辐照脆化影响最显著的因素;5)依据化学元素cu含量,将将经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据划分为至少5种类别,其中至少一种数据类别的cu含量≤0.07%,且至少一种数据类别的cu含量>0.26%;6)依据步骤5)确定的cu含量数据类别,采用分层抽样的方法将数据划分为训练集和测试集;7)将步骤6)中训练集数据与测试集数据采用贝叶斯函数进行归一化,归一化之前将中子注量f、注量率取对数计算,即logf和8)采用不同机器学习算法,使用归一化后的训练集数据,调整参数后,建立基于某种机器学习算法的rpv辐照脆化预测模型;9)根据步骤8)建立的辐照脆化预测模型,采用归一化后的测试集数据,依次开展预测值-试验值的分布分析、残差标准差sd分析、r2分析和残差r分析;10)对通过步骤9)的预测模型,开展cu含量影响分析,得到最终建立的rpv辐照脆化预测模型。根据本发明的优选实施方面,步骤1)中所述关联因素包括中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn、si含量。根据本发明的优选实施方面,步骤3)中所述特征选择采用包裹型处理方法,得到关联因素的重要性排名,去除辐照脆化数据中对辐照脆化影响重要性后三位的数据科目,确定rpv辐照脆化影响因素;所述数据清洗包括异常值剔除和重复值修正。根据本发明的优选实施方面,所述异常值剔除指删除δt41j≤0的数据条目;所述重复值修正指辐照脆化影响因素相同但δt41j不同的数据,其中δt41j取算术平均值。根据本发明的优选实施方面,步骤6)中所述训练集和测试集中都包含至少5种cu含量类别的部分数据;且所述训练集数据量为总数据量的80%,测试集数据为总数据量的20%。根据本发明的优选实施方面,步骤8)中所述机器学习算法包括k最近邻、线性回归、岭回归、套索回归、决策树、支持向量机、adaboost、gbdt和xgboost等。根据本发明的优选实施方面,步骤8)中所述参数包括正则化项参数、学习率参数及每种算法的各自的特有参数。根据本发明的优选实施方面,步骤9)具体包括如下步骤:9.1)δt41j预测值-试验值的分布分析:绘制预测模型的预测值-试验值分布图,计算预测结果的sd,若分布图中≥95%的数据点分布在2倍sd以内,则进行下一步分析,否则舍弃该预测模型;9.2)对于通过步骤9.1)的预测模型,如果sd<12℃,且r2≥0.85,则进行下一步分析,否则舍弃该预测模型;9.3)对于通过步骤9.1)和9.2)的预测模型,依据步骤3)确定的辐照脆化影响因素,逐一进行r分析,其中,残差曲线通过最小二乘法确定。根据本发明的优选实施方面,步骤9.3)中,若|r|≤3.5℃,且|rmax+rmin|≤3.5℃,则进行下一步分析,否则舍弃该预测模型。根据本发明的优选实施方面,步骤10)具体包括如下步骤:10.1)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、si=0.25%、ni=0.7%为输入参数,计算cu含量≤0.2%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,判断拟合曲线的交叉点的cu含量是否满足0.06%≤cu≤0.08%,若满足则进行下一步分析,否则舍弃该预测模型;10.2)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、si=0.25%、ni=0.7%为输入参数,计算cu含量≥0.1%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,判断拟合曲线的交叉点的cu含量是否满足0.24%≤cu≤0.31%,若满足,则基于该算法的模型即为最终建立的rpv辐照脆化预测模型,否则舍弃该模型。在本发明的具体实施例中,基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,包括如下步骤:1)确定rpv辐照脆化关联因素,包括中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn、si、cr、mo、s含量;2)依据步骤1)确定的关联因素收集rpv辐照脆化数据,数据科目为韧脆转变温度δt41j及步骤1)中的辐照脆化关联因素;3)对收集的辐照脆化数据进行特征选择与数据清洗。特征选择采用包裹型处理方法,去除辐照脆化数据中对辐照脆化影响不显著的数据科目,确定rpv辐照脆化影响因素。数据清洗包括异常值剔除,重复值(仅δt41j不同)修正。异常值剔除指删除δt41j≤0的数据条目;重复值修正指辐照脆化影响因素相同但δt41j不同的数据,δt41j取算术平均值;4)对经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据进行可视化分析或相关性分析,确定化学元素cu的含量为对辐照脆化影响最显著的因素。5)依据化学元素cu含量,将经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据划分为5种类别,其中至少有一种数据类别的cu含量≤0.07%,且至少有一种数据类别的cu含量>0.26%;6)依据步骤5)确定的5种cu含量数据类别,采用分层抽样的方法将数据划分为训练集和测试集(训练集和测试集中都包含5种cu含量类别的部分数据),其中训练集数据量为总数据量的80%,测试集数据为总数据量的20%;7)将步骤6)中训练集数据与测试集数据采用贝叶斯函数进行归一化,归一化之前将中子注量f、注量率取对数计算,即logf,8)采用不同机器学习算法(包括k最近邻、线性回归、岭回归、套索回归、决策树、支持向量机、adaboost、gbdt和xgboost等),使用归一化后的训练集数据,调整参数(正则化项参数、学习率参数及每种算法的各自的特有参数)后,建立基于其中一种机器学习算法的rpv辐照脆化预测模型;9)根据步骤8建立的辐照脆化预测模型,采用归一化后的测试集数据,依次开展预测值-试验值的分布分析、残差标准差sd分析、r2分析和残差r分析。具体包括如下步骤:9.1)δt41j预测值-试验值的分布分析:绘制预测模型的预测值-试验值分布图,计算预测结果的sd,若分布图中≥95%的数据点分布在2倍sd以内,则进行下一步分析,否则舍弃该预测模型;9.2)对于通过步骤9.1)的预测模型,如果sd<12℃,且r2≥0.85,则进行下一步分析,否则舍弃该预测模型;9.3)对于通过步骤9.1)和9.2)的预测模型,依据步骤3)确定的辐照脆化影响因素,逐一进行r分析,其中,残差曲线通过最小二乘法确定。若|r|≤3.5℃,且|rmax+rmin|≤3.5℃,则进行下一步分析,否则舍弃该预测模型。10)对通过步骤9)的预测模型,开展cu含量影响分析。具体包括如下步骤:10.1)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、si=0.25%、ni=0.7%为输入参数,计算cu含量≤0.2%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,判断拟合曲线的交叉点的cu含量是否满足0.06%≤cu≤0.08%,若满足则进行下一步分析,否则舍弃该预测模型;10.2)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、si=0.25%、ni=0.7%为输入参数,计算cu含量≥0.1%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,判断拟合曲线的交叉点的cu含量是否满足0.24%≤cu≤0.31%,若满足,则基于该算法的模型即为最终建立的rpv辐照脆化预测模型,否则舍弃该模型。由于采用了以上的技术方案,相较于现有技术,本发明的有益之处在于:本发明的基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,该方法基于辐照脆化数据的特征选择与数据清洗后,将cu作为辐照脆化影响的最显著因素,并依据cu含量进行数据分层抽样,形成训练集和测试集;采用多种机器学习算法建立辐照脆化预测模型,随后依次开展δt41j预测值与试验值的分布分析、sd分析、r2分析、r分析和cu含量影响分析,建立基于机器学习算法的rpv辐照脆化预测模型。本发明的预测模型的开发方法克服了常规方法无法对模型开发过程进行量化的问题,具有开发过程与量化指标明确、开发过程操作性强、建立模型的准确性高、模型开发过程复现性好的特点,具有很强的实用性。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例的步骤3)中基于包裹型的特征选择结果;图2为本发明实施例的步骤4)中δt41j随中子注量f和化学元素cu含量的变化关系;图3为本发明实施例的步骤9.1)中不同机器学习算法获得的预测值-试验值分布图;图4为本发明实施例的步骤9.2)中基于不同机器学习算法建立的辐照脆化预测模型的r2与sd分析;图5为本发明实施例的步骤9.3)中基于xgboost建立的预测模型,对辐照脆化影响因素中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn逐一进行r分析的结果;图6为本发明实施例的步骤10)得到的预测模型中δt41j随cu含量的变化曲线。具体实施方式为了使本
技术领域:
的人员更好地理解本发明的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。参见附图1-6,本实施例的基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,包括如下步骤:1)确定rpv辐照脆化关联因素。关联因素包括中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn、cr、mo、s含量。2)收集rpv辐照脆化数据。数据科目为韧脆转变温度(δt41j)及中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn、c、mo、s、cr含量,收集的部分rpv辐照脆化数据见表1。表1部分rpv辐照脆化数据3)对收集的辐照脆化数据进行特征选择与数据清洗。特征选择综合采用包裹型处理方法,得到如图1所示的重要性排名。根据重要性排名表,去除对辐照脆化数据中对辐照脆化影响不显著的数据科目s、mo和cr,继而确定中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn为韧脆转变温度(δt41j)的影响因素。对表1中δt41j≤0的数据条目进行删除;对表1中中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn相同但δt41j不同的数据,计算δt41j的算术平均值。4)对经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据进行可视化分析,分析结果见图2,结果表明,化学元素cu的含量为对辐照脆化影响最显著的因素。5)依据化学元素cu含量,将经过步骤3)中特征选择与数据清洗后的rpv辐照脆化数据划分为5种类别,具体cu含量的划分类别见表2。表2分层抽样中化学元素cu含量的类别cu含量类别cu含量10≤cu≤0.07%20.07≤cu≤0.11%30.11≤cu≤0.21%40.21≤cu≤0.31%5cu>0.31%6)依据表2确定的5种cu含量数据类别,采用分层抽样的方法将数据划分为训练集和测试集,其中训练集数据量为总数据量的80%,测试集数据为总数据量的20%。7)将步骤6)中的训练集数据与测试集数据采用贝叶斯函数进行归一化,归一化之前将中子注量f、注量率取对数,即logf,8)采用机器学习算法(包括k最近邻、线性回归、岭回归、套索回归、决策树、支持向量机、adaboost、gbdt和xgboost),使用归一化后的训练集数据,参数调整(正则化项参数、学习率参数及每种算法的各自的特有参数)后,建立基于某种机器学习算法的rpv辐照脆化预测模型。9)根据步骤8)建立的辐照脆化预测模型,采用归一化后的测试集数据,依次开展δt41j预测值与试验值的分布分析、残差标准差sd分析、r2分析和残差r分析,具体如下:9.1)δt41j预测值与试验值的分布分析图3中依次为基于k最近邻、线性回归、岭回归、套索回归、决策树、支持向量机、adaboost、gbdt和xgboost建立的预测模型的δt41j预测值-试验值分布图。其中,基于k最近邻、决策树建立的预测模型中预测值-试验值分布不满足≥95%的数据点分布在2倍sd以内的要求,舍弃这两种预测模型。9.2)对于通过步骤9.1)的预测模型进行sd分析。图4为预测模型预测结果的sd。根据图4,仅有基于xgboost的预测模型满足sd<12℃,且r2≥0.85的要求。9.3)对于基于xgboost建立的预测模型,对辐照脆化影响因素中子注量f、注量率辐照温度t、化学元素cu、p、ni、mn逐一进行r分析,分析结果见图5,图5即按上述因素次序依次排列。根据图5可计算获得,在残差曲线的随辐照脆化影响因素的变化范围内,满足|r|≤3.5℃,且|rmax+rmin|≤3.5℃的要求。10)对基于xgboost建立的辐照脆化预测模型,开展cu含量影响分析,得到最终建立的rpv辐照脆化预测模型。具体包括如下步骤:10.1)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、ni=0.7%为输入参数,计算cu含量≤0.2%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,结果如图6所示。图6结果表明,两段线性拟合曲线的交叉点的cu含量为cu=0.07%,满足0.06%≤cu≤0.08%的要求。10.2)以f=1×1019n/cm2、t=290℃、mn=1.4%、p=0.01%、ni=0.7%为输入参数,计算cu≥0.1%条件下δt41j随cu含量的变化曲线,随后对所获曲线进行两段线性拟合,结果如图6所示。结果表明,两段线性拟合曲线的交叉点的cu含量为0.26%,满足0.24%≤cu≤0.31%的要求。所以得到基于xgboost建立的模型即为最终建立的rpv辐照脆化预测模型。本发明的基于机器学习算法的rpv材料辐照脆化预测模型的开发方法,该方法基于辐照脆化数据的特征选择与数据清洗后,将cu作为辐照脆化影响的最显著因素,并依据cu含量进行数据分层抽样,形成训练集和测试集;采用多种机器学习算法建立辐照脆化预测模型,随后依次开展δt41j预测值与试验值的分布分析、sd分析、r2分析、r分析和cu含量影响分析,建立基于机器学习算法的rpv辐照脆化预测模型。本发明的预测模型的开发方法克服了常规方法无法对模型开发过程进行量化的问题,具有开发过程与量化指标明确、开发过程操作性强、建立模型的准确性高、模型开发过程复现性好的特点,具有很强的实用性。上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1