基于一阶段目标检测框架的实例分割方法与流程
本发明属于深度学习与计算机视觉技术领域,具体涉及基于一阶段目标检测框架的实例分割方法。
背景技术:
在过去几年中,计算机视觉的目标检测方向取得了巨大的进步,与其具有一定相关性的实例分割任务在借鉴了目标检测框架的强大功能后,也获得了一定的发展。
实例分割任务是指在图像中定位出潜在目标的位置,该位置使用检测目标框表示,再用语义分割的方式在不同目标区域内进行逐像素标记,该任务可以在目标检测的基础上进行相应扩展便可完成。不少工作都在对现有成熟的目标检测框架进行扩展,以完成实例分割的任务,但绝大多数工作都是对两阶段目标检测框架进行扩展,这种扩展在保证分割质量的同时,难以兼顾检测速度。
2018年,来自facebookai研究院的何凯明团队提出的基于两阶段目标检测框架的实例分割方法maskr-cnn,其简单且灵活的扩展方法使该领域更多地进一步关注目标检测和实例分割任务及其对应方法的共通性和相互扩展功能。然而,该方法目前在取得相应高质的分割结果的同时,牺牲了时间上的效率,这是该方法目前值得改进的地方。
maskr-cnn在时间效率上低效的原因之一是它使用的两阶段目标检测框架原有的问题。本发明通过对一阶段目标检测框架的有效扩展,提供更快的实例分割流程,有效解决上述问题。然而,通过一阶段目标检测框架扩展的实例分割方法并不能像maskr-cnn一样单纯直接扩展mask分支便可以完成相应的实例分割任务。对一阶段目标检测框架进行实例分割任务的扩展,需要解决不同对象检测目标框二义性问题和分割语义二义性问题。
因此,需要一种能够解决上述二义性问题,同时兼顾速度的实例分割方法。
技术实现要素:
鉴于背景技术所述的问题,本发明提供一种基于一阶段目标检测框架的实例分割方法,用以提供一种可以同时兼顾分割质量和模型速度的实例分割方法。
为了解决上述技术问题,本发明提供一种基于一阶段目标检测框架的实例分割方法,包括:
s1、将训练图像中的目标对象标注成网络输出层里密集的点对象;
s2、构建完整的基于一阶段目标检测框架的实例分割网络模型;
s3、设计一种适应实例分割任务的多任务损失函数用于深度学习训练;
s4、推断阶段,结合目标检测结果和语义分割结果最终获得实例分割结果。
进一步地,步骤s3中的多任务损失函数由目标检测框、对象置信度、对象分类和语义分割四部分的损失函数组成,具体如下:
s31、目标检测框部分采用交并比损失函数;
s32、对象置信度部分采用针对对象中心度改进的焦点损失函数,其表达式为:
s33、对象分类部分采用针对多分类任务改进的焦点损失函数,其表达式为:
s34、语义分割部分采用交叉熵损失函数,
其中,yt为标注的实际类别;
进一步地,在步骤s1中,每个训练图像中所含有的目标对象以密集的点对象形式进行表达,每个尺度下输出大小为[b,h,w]的张量,其中b为批处理大小,h、w为对应尺度的高度和宽度,当且仅当某个对象的目标检测框包含了张量里的一部分点,这部分点以点对象的形式进行编码,该点对象的编码方式如下:
s11、对象类别编码为one-hot向量,向量长度为c;
s12、对象置信度编码为对象中心度;
s13、目标检测框编码为长度为4的向量(l,r,t,b);
其中c为分类类别的数量,l、r、t、b分别表示该点对象中心到对应目标检测框的左、右、上、下四端的距离。
进一步地,在步骤s2中,所述基于一阶段目标检测框架的实例分割网络模型,包括主干网络、主体特征提取模块、目标检测模块和语义分割模块四个部分,具体如下:
s21、帮助完成基础特征提取的主干网络,包含一个接收图像张量输入的网络输入层和五个阶段的下采样特征提取层;
s22、主体特征提取模块主要对基础特征进行进一步的挖掘提取,包括从基础特征层到特征提取层的横向连接、从低层特征层到高层特征层自下而上的下采样和从高层特征层到低层特征层自上而下的上采样三个部分,最终每个尺度输出一层特征张量;
s23、目标检测模块是负责得到目标检测结果的输出,五个不同尺度下的检测模块分别负责不同大小对象的检测,每个检测模块都包含两个分支,两个分支都接收主体特征提取模块提取到的特征张量,经过四个核大小为3,下采样尺度为1的卷积层得到特征张量,其中一个分支为回归分支,其特征张量经过输出通道数为4的卷积分支得到目标检测回归结果,另一个分支为分类分支,其特征张量分别经过输出通道数分别为c和输出通道数为1的卷积分支,得出目标置信度和分类概率结果;
s24、语义分割模块是负责得到语义分割结果的输出,该模块仅接收主体特征提取模块最底层的特征张量作为输入,经过四个核大小为3,下采样尺度为1的卷积层和输出通道数为c的卷积层,得出一个以类别划分的语义分割结果。
进一步地,实例分割网络模型输出五个不同尺度的目标检测结果和一个尺度的语义分割结果,推断阶段先将目标检测结果合并,再筛选出topk个结果,最后使用一种结合目标检测结果和语义分割结果的非极大值分割筛选方法,以获得最终的实例分割结果。
进一步地,所述非极大值分割筛选方法的算法步骤如下:
1)根据目标检测结果的对象得分对检测结果降序排序;
2)选择得分最高的检测对象m,加入最终检测结果列表,并从原列表中删除,同时根据该检测类别和检测框结果从语义分割结果中获得逐像素对应的分割结果,作为m的实例分割结果集,该集合分别以目标对象得分和每个像素对应的分割结果作为键值对来保存;
3)计算m与其他检测目标的交并比,找出当中交并比大于0.5的所有结果,从检测结果列表中删除,并将这些对象的目标的得分和分割结果加入到m的实例分割结果集中;
4)对m的所有候选实例分割结果,进行线性组合,获得m的最终实例分割结果;
5)重复2-4),直至检测结果列表为空,算法结束,返回最终检测结果列表。
与现有技术相比,本发明实现的有益效果是:只需要对原有成熟的一阶段目标检测框架进行少量修改,模型便可以同时完成实例分割任务,在保持原有框架的检测速度的基础上,得到质量较好的实例分割结果。
附图说明
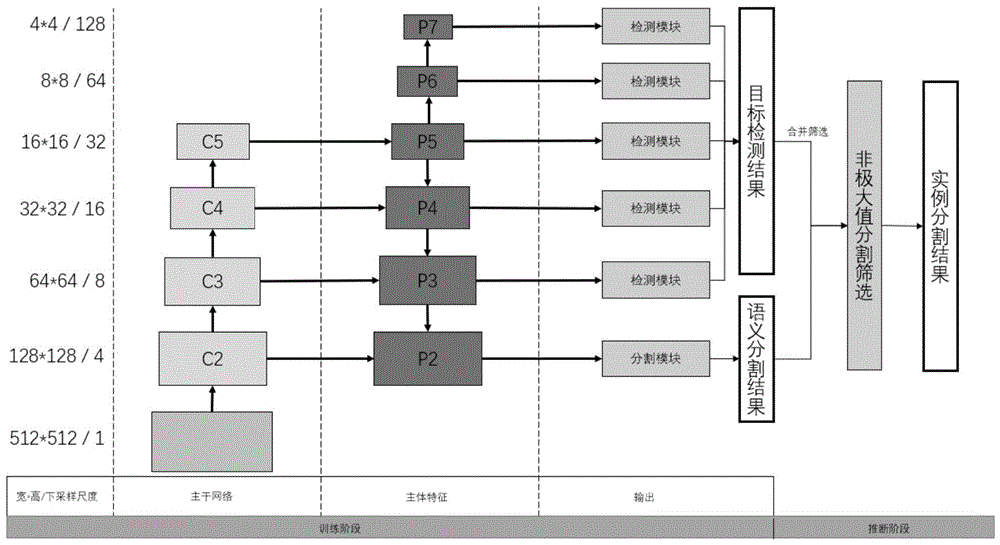
图1为基于一阶段目标检测框架的实例分割方法示意图;
图2为图像中的目标对象标注示意图;
图3为网络结构第二部分主体特征提取模块示意图;
图4为网络检测分支和分割分支模块结构示意图;
图5为数据集处理流程示意图。
具体实施方式
下面对本发明技术作进一步详细说明,但是本发明的实施方式并不限于此,其保护范围也不局限于所述实施例。
一种基于单目标检测框架的实例分割方法,其实施步骤如下:
s1、获取与实例分割任务相关的待检图像及其标注,并将训练图像中的目标对象标注成网络输出层里密集的点对象,如图2所示。该数据获取与预处理步骤如图5所示。在本实施例中,每个图像中所含有的目标对象都将以密集的点对象形式进行表达,每个尺度下输出大小为[b,h,w]的张量,其中b为批处理大小,h、w为对应尺度的高度和宽度,当且仅当某个对象的检测框包含了张量里的一部分点,这部分点以点对象的形式进行编码,该编码如图2所示,具体地,对每个点对象进行如下编码:
s11、对象类别编码为one-hot向量,向量长度为c;
s12、对象置信度编码为对象中心度;
s13、目标检测框编码为长度为4的向量(l,r,t,b),如图2(b)所示。
其中c为分类类别的数量,l、r、t、b分别表示该点对象中心到对应目标检测框的左、右、上、下四端的距离。
s2,构建完整的基于一阶段目标检测框架的实例分割网络模型,如图1训练阶段所示,原始图像经过主干网络完成基础特征提取,基础特征而后经过主体特征提取模块对特征进行进一步的挖掘,最后经过检测层和分割层获得网络模型最终的输出。完整的网络模型结构如图1训练阶段所示。本发明所设计的深度网络模型由一个主干网络、主体特征提取模块、多个目标检测模块和一个语义分割模块四部分组成,该四部分具体如下:
s21、帮助完成基础特征提取的主干网络,包含一个接收图像张量输入的网络输入层和五个阶段的下采样特征提取层,在本实施例中,选取resnet50-c4作为帮助完成基础特征提取的主干网络,该部分的特征提取能力已经在图像识别模型中得到验证,其结构大致如图1主干网络部分所示,其中包含一个网络输入层和5个阶段的特征层,图1省略了不作任何改动的特征c1层。如图1主干网络部分最底层所示,网络模型输入是图像尺寸为512*512的图像像素矩阵。
s22、主体特征提取模块主要对基础特征进行进一步的挖掘提取,主要包括从基础特征层到特征提取层的横向连接、从低层特征层到高层特征层自下而上的下采样和从高层特征层到低层特征层自上而下的上采样三个部分。在本实施例中,该模块的三部分如下描述所示:
1)该模块的第一部分是从基础特征层到特征提取层的横向连接,如图3横向连接部分所示,该横向连接由一个批规范化层(batchnormalization)和激活层(activation)前置的1*1卷积核构成,没有进行任何下采样或上采样操作。在本实施例中,共四个部分使用了该连接,如图1,c2到p2、c3到p3、c4到p4、c5到p5部分所示。
2)该模块的第二部分是从低层特征层到高层特征层自下而上的连接,如图3下采样部分所示,该连接是由一个批规范化层(batchnormalization)和激活层(activation)前置的3*3卷积核构成的,其中卷积进行了下采样操作。在本实施例中,共两个部分使用了该连接,如图1,p5到p6、p6到p7部分所示。
3)该模块的第三部分是从高层特征层到低层特征层自上而下的连接,如图3上采样部分所示,该连接是一个拼接层(concatenate),将上采样层和横向连接进行拼接。在本实施例中,共三个部分使用了该连接,如图1,p5到p4、p4到p3、p3到p2部分所示。
该模块的三个部分最终每个尺度输出一层特征张量。
s23、目标检测模块负责得到目标检测结果的输出,模型第三部分检测层是利用模型第二部分主体特征层生成的特征进行检测层的特征选择操作,最终输出两个结果分支。如图1所示,p3、p4、p5、p6、p7这5个部分的特征经过检测层的特征选择,生成相应的目标检测输出。在本实施例中,这五个检测模块分别负责不同大小对象的检测,p3、p4、p5、p6、p7所生成的检测块分别负责监测大小范围在[0,16]、[16,32]、[32,64]、[64,128]、[128,512]的对象,这种方法有利于模型对不同大小对象进行检测,每个检测模块都包含两个分支,两个分支都接收主体特征提取模块提取到的特征张量,经过四个核大小为3,下采样尺度为1的卷积层得到特征张量,其中,两个分支分别为分类分支和回归分支,分类分支的特征张量分别经过输出通道数分别为c和输出通道数为1的卷积分支,得出对象置信度和分类概率两个输出,如图4分类分支所示;回归分支对回归框进行回归预测,其特征张量经过输出通道数为4的卷积分支得到目标检测回归结果,如图4回归分支所示。回归分支输出的四个目标框位置参数为(l,r,t,b),最终卷积结果使用relu函数进行激活。分类分支的两个输出,其结果域为[0,1],最终的卷积结果使用sigmoid函数进行激活,其中,对象置信度采用目标中心度进行表示,对象中心度表示一个点对象位于该对象中心的程度的大小,其表达式为:
模型第四部分语义分割模块是负责得到语义分割结果的输出,该模块仅接收主体特征提取模块最底层的特征张量作为输入,经过四个核大小为3,下采样尺度为1的卷积层和输出通道数为c的卷积层,得出一个以类别划分的语义分割掩膜输出,其结果矩阵的尺寸为[b,128,128,c],最终卷积结果使用sigmoid函数进行激活,其中b为批处理大小,c为类别数量,在本实施例中,b等于12,c等于80(采用mscoco数据集)。
s3、设计一种适应实例分割任务的多任务损失函数用于深度学习训练。本发明所设计的多任务损失函数由目标检测框、对象置信度、对象分类和对象分割掩膜四部分的损失函数组成。
s31、目标检测框部分采用交并比损失函数;目标检测框的损失函数大致有两种方案,一种是基于回归误差的损失函数,另一种是基于交并比的损失函数。在本实施例中,目标检测框的标注和输出都采用(l,r,t,b)的表示方式,且该表示方式比起传统的(x,y,w,h)要更直观且在交并比的计算上更高效,所以本发明中多任务损失函数的目标检测框部分采用交并比损失函数。
s32、对象置信度部分采用采用针对对象中心度改进的焦点损失函数,该改进的焦点损失函数可以使目标检测任务的精度得到改善,在本实施例中,该改进的焦点损失函数被定义为:
其中,yt为标注的实际类别;
s33、对象分类部分采用针对多分类任务改进的焦点损失函数,该改进的焦点损失函数可以使数据集中的样本数量属于少数的对象分类精度得到改善,在本实施例中,该改进的焦点损失函数被定义为:
其中,nt为该类别对象在数据集中的数量,
s34,在本实施例中,语义分割部分采用交叉熵损失函数。
在神经网络训练中,使用随机梯度下降方法对网络参数进行优化,在本实施例中,初始学习率设置为0.01,动量为0.9,权重衰减为0.0005,批大小为12,总迭代轮次为300轮,其中每轮包括500个批次,学习率在180轮、240轮、280轮进行下降,下降比率为0.1。
s4、推断阶段,将模型输出作后处理,以获得最终的结果,结合目标检测结果和语义分割结果,深度网络模型输出五个不同尺度的目标检测结果和一个尺度的语义分割结果,先将目标检测结果合并,再筛选出topk个结果,最后使用一种结合目标检测结果和语义分割结果的非极大值分割筛选方法,以获得最终的实例分割结果,如图1推断阶段所示。具体如下:
对于语义分割模块的输出,可以直接作为分割掩膜结果。而对于目标检测模块的输出,要经过以下步骤处理:首先获取5个检测模块的输出,获得所有的目标检测结果,其中的目标检测框位置参数(l,r,t,b)需要解码成(x,y,x,y)的传统表示方式,并乘上每个输出对应的下采样尺度以还原到原图对应的大小,最后合并所有检测输出,得到初始的检测结果。同时可以直接将语义分割模块的输出作为分割掩膜结果;然后,对获得的初始检测结果按对象得分进行排序,选择其中的topk个结果,并筛选出其中对象得分大于0.5的结果。
在获得经过后处理的检测结果和分割结果后,使用修改后的非极大值分割筛选方法(nms)对检测结果和分割结果进行筛选处理,其算法步骤如下:
1)根据目标检测结果的对象得分对检测结果降序排序;
2)选择得分最高的检测对象m,加入最终检测结果列表,并从原列表中删除,同时根据该检测类别和检测框结果从语义分割结果中获得逐像素对应的分割结果,作为m的实例分割结果集,该集合分别以目标对象得分和每个像素对应的分割结果作为键值对来保存;
3)计算m与其他检测目标的交并比,找出当中交并比大于0.5的所有结果,从检测结果列表中删除,并将这些对象的目标的得分和分割结果加入到m的实例分割结果集中;
4)对m的所有候选实例分割结果,进行线性组合,获得m的最终实例分割结果;
5)重复2-4),直至检测结果列表为空,算法结束,返回最终检测结果列表。
最终获得的检测结果列表,包含最终检测对象的对象得分、所属类别、目标检测框和对象分割掩膜,可以作为实例分割任务的最终输出。
综上所述,该实例分割方法能够一定程度地兼顾检测质量和检测速度,对原有成熟的一阶段目标检测框架进行少量修改即可,模型简单但高效实用。
上述实施例为本发明里实验效果较好的实施方式,但并非对本发明做任何实现方式、形式上的限制,任何根据本发明的技术方案的简单修改、简化、组合、替换等改动方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!