基于单图像的自适应三维人脸重建方法与流程
本发明属于计算机视觉和图形学领域,具体涉及人脸关键点检测和三维模型重建方法。
背景技术:
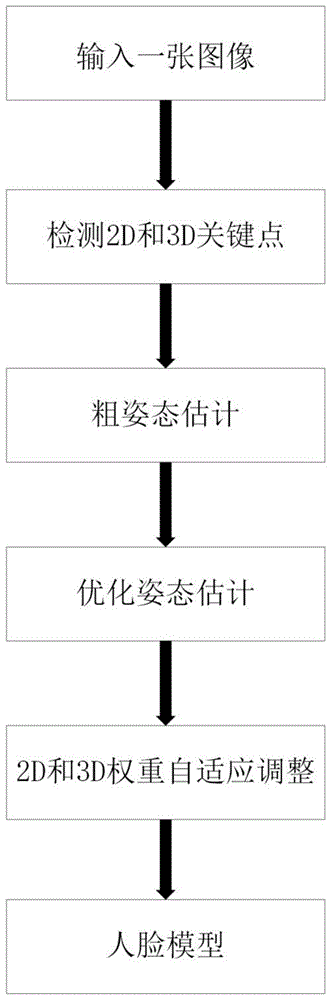
:在计算机视觉和计算机图形学中,三维人脸重建一直是一个具有挑战性的问题,虽然现有的基于多视角图像的方法已经取得了很好的效果,但对于单张输入图像来说,缺少人脸各个视角信息以致重建真实的三维人脸模型很有难度,目前大部分基于单图像重建的方法是基于良好的正面图像。然而在现实生活中,理想状态下的完全正面无遮挡的图像是很少的,常有头发或头部旋转等造成的遮挡,而人脸处于局部遮挡和极端姿态的情况下,想要重建接近真实的人脸模型仍然很棘手。近年来提出了不少深度学习的方法,luan等人(luantranandxiaomingliu,“nonlinear3dfacemorphablemodel,”inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,2018)提出非线性3dmm(3dmorphablemodel)通过dnns(深度神经网络)来学习shape(形状)和texture(纹理),不需要3d扫描,就能更好的表达人脸信息,hongweiyi等人(hongweiyi,chenli,qiongcao,xiaoyongshen,shengli,guopingwang,andyu-wingtai,“mmface:amulti-metricregressionnetworkforunconstrainedfacereconstruction,”inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,2019)提出了多度量回归网络用于无约束三维人脸重建,虽然能有效解决部分遮挡问题,但是深度学习方法本身依赖于良好的数据集作为训练,并且现实中的人脸图像和高精度模型对应的数据集也比较缺乏,对于测试的输入图像与数据集相差较大时往往不适用。为了有效解决遮挡问题,传统方法中zhu等人(xiangyuzhu,zhenlei,junjieyan,dongyi,andstanzli,“high-fidelityposeandexpressionnormalizationforfacerecognitioninthewild,”inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,2015)和luo等人(jiangluo,juyongzhang,bailindeng,haoli,andligangliu,“3dfacereconstructionwithgeometrydetailsfromasingleimage,”ieeetransactionsonimageprocessing,2018)提出标记点游走方法来更新轮廓点,但是他们需要人工手动标记关键点,这是耗时又费力的。本发明采用一种基于3dmm的2d和3d联合优化方法,充分利用2d和3d关键点信息,可以从单个图像自适应地重建3d人脸模型,该方法不仅对姿态估计有有效提升,对于局部遮挡和极端姿态下的人脸也是鲁棒的,并且无需人工参与,此发明在人脸识别、人脸动画等领域有着广泛的应用前景。技术实现要素:为克服现有技术的不足,本发明旨在提出一种鲁棒的通过单张图像实现自适应三维人脸模型的重建方法,从而准确地获取各个姿态下的人脸模型,为了达到上述目的,本发明采取的技术方案是基于单图像的自适应三维人脸重建方法,包括以下步骤:1)首先输入一张人脸图片;2)对于输入的图片,使用人脸关键点检测方法分别估计图片中人脸2d和3d关键点位置;3)根据检测到的2d关键点的左右轮廓点分别估计一个欧拉角,取水平方向旋转角yaw值最大的作为一个粗姿态估计;4)由步骤3)得到粗的姿态估计,将模型中的n个点投影在图像上,利用检测到的3d点替换被遮挡的2d轮廓点,再更新n个点估计一个优化后的姿态;5)由步骤4)得到优化后的姿态估计,根据所获得的姿态估计自适应地调整2d和3d关键点的权重;6)由步骤5)估计人脸的形状和表情参数,结合步骤4)得到的姿态参数拟合人脸模型。具体步骤如下:3-1)3dmm是一种3d人脸统计模型,属基于主成分分析的线性模型,其顶点表示为:v(α,β)=msha(α)+mexp(β)(1)其中msha表示形状向量,mexp表示表情向量,α是形状参数,β是表情参数,msha和mexp定义为:其中是平均形状,是平均表情,γsha和γexp分别是由扫描的中性形状和表情训练得到的主成分系数;3-2)根据步骤3)得到一个粗姿态估计后,由步骤4)得到优化后的姿态估计pπ,r,t,其中t是位移向量,s是缩放系数,π定义为:其中r为由罗德里格斯公式表示的3×3旋转矩阵:其中i是一个3×3的单位阵,是关于y的斜对称矩阵,模型的欧拉角向量利用罗德里格斯公式得到欧拉角到旋转矩阵的变换;3-3)2d拟合约束e2d定义为:vk是3d人脸模型的第k个顶点,li是与顶点对应的第i个关键点,l2d,i是第i个检测到的2d关键点,通过最小化2d关键点l2d,i和模型投影的2d点位置之间的欧氏距离来求解3dmm参数;3-4)为了结合3d深度信息来解决不可见区域的歧义性,提出3d-to-3d拟合约束:其中姿态参数和优化求解方式与e2d相似,lg3d,i是归一化为2维坐标的第i个3d关键点;3-5)为了有效地结合2d和3d关键点信息,利用权重自适应调整方法:其中设置ε值为0.5,即以人脸旋转角度45°为界,当旋转角度大于45°时,取wλ=1,2d和3d权重调整如下:其中设置调整权重w值为0.5。当wλ=0时,人脸旋转角度小于45°,2d和3d权重调整如下:3-6)期望每个形状和表情参数都服从正态分布,均值和方差为零。形状和表情先验项定义如下:ep(α,β)=λαeprior(α)+λβeprior(β)(13)其中eprior(α)是形状先验,eprior(β)是表情先验,λα和λβ是他们对应的权重系数;形状先验定义为:表情先验定义为:其中αi与βi分别表示第i个形状和表情参数,nα和nβ分别表示形状和表情参数总数,δα和δβ是主成分形状和表情对应的特征值,实验证明添加形状和表情先验可以有效地提高重建准确率;3-7)最后总的2d和3d的联合优化求解过程如下,将其视为一个非线性最小二乘问题:efit(α,β,pπ,r,t)=λ2de2d(α,β,pπ,r,t)+λ3de3d(α,β,pπ,r,t)+ep(α,β)(16)其中λ2d是2d拟合约束的权重系数,λ3d是3d拟合约束的权重系数,通过求解的姿态,形状和表情参数从而得到拟合的人脸模型。本发明的方法的特点及效果:本发明方法根据单张图片进行遮挡和极端姿态下的三维人脸重建,该方法利用了3d关键点的深度信息和2d关键点有效信息自适应地重建人脸模型,具体具有以下特点:1、操作简单,易于实现;2、联合2d和3d优化,将三维人脸重建问题转化到一个统一的2d和3d优化框架;3、由粗到精的姿态估计,减少由错误姿态估计产生的误差;4、2d和3d权重自适应调整,减少由于遮挡造成的模型重建错误;附图说明本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:图1为本发明方法的流程图;图2为2d和3d关键点估计图;图3为本发明最终拟合出的三维模型结果。具体实施方式本本发明采取的技术方案是基于单张图片进行遮挡和极端姿态下的自适应三维人脸重建,包括以下步骤:1)首先输入一张人脸图片;2)对于输入的图片,使用人脸关键点检测方法分别估计图片中人脸2d和3d关键点位置;3)根据检测到的2d关键点的左右轮廓点分别估计一个欧拉角,取水平方向旋转角yaw值最大的作为一个粗姿态估计;4)由步骤3)得到粗的姿态估计,将模型中的n个点投影在图像上,利用检测到的3d点替换被遮挡的2d轮廓点,再更新n个点估计一个优化后的姿态;较佳的n=68。5)由步骤4)得到优化后的姿态估计,根据所获得的姿态估计自适应地调整2d和3d关键点的权重;7)由步骤5)估计人脸的形状和表情参数,结合步骤4)得到的姿态参数拟合人脸模型。具体步骤如下:3-1)3dmm是一种3d人脸统计模型,属基于主成分分析的线性模型,其顶点表示为:v(α,β)=msha(α)+mexp(β)(1)其中msha表示形状向量,mexp表示表情向量,α是形状参数,β是表情参数,msha和mexp定义为:其中是平均形状,是平均表情,γsha和γexp分别是由扫描的中性形状和表情训练得到的主成分系数;3-2)根据步骤3)得到一个粗姿态估计后,由步骤4)得到优化后的姿态估计pπ,r,t,其中t是位移向量,s是缩放系数,π定义为:其中r为由罗德里格斯公式表示的3×3旋转矩阵:其中i是一个3×3的单位阵,是关于y的斜对称矩阵,模型的欧拉角向量利用罗德里格斯公式得到欧拉角到旋转矩阵的变换;3-3)2d拟合约束e2d定义为:vk是3d人脸模型的第k个顶点,li是与顶点对应的第i个关键点,l2d,i是第i个检测到的2d关键点,通过最小化2d关键点l2d,i和模型投影的2d点位置之间的欧氏距离来求解3dmm参数;3-4)为了结合3d深度信息来解决不可见区域的歧义性,提出3d-to-3d拟合约束:其中姿态参数和优化求解方式与e2d相似,lg3d,i是归一化为2维坐标的第i个3d关键点;3-5)为了有效地结合2d和3d关键点信息,利用权重自适应调整方法:其中设置ε值为0.5,即以人脸旋转角度45°为界,当旋转角度大于45°时,取wλ=1,2d和3d权重调整如下:其中设置调整权重w值为0.5。当wλ=0时,人脸旋转角度小于45°,2d和3d权重调整如下:3-6)期望每个形状和表情参数都服从正态分布,均值和方差为零。形状和表情先验项定义如下:ep(α,β)=λαeprior(α)+λβeprior(β)(13)其中eprior(α)是形状先验,eprior(β)是表情先验,λα和λβ是他们对应的权重系数;形状先验定义为:表情先验定义为:其中αi与βi分别表示第i个形状和表情参数,nα和nβ分别表示形状和表情参数总数,δα和δβ是主成分形状和表情对应的特征值,实验证明添加形状和表情先验可以有效地提高重建准确率;3-7)最后总的2d和3d的联合优化求解过程如下,将其视为一个非线性最小二乘问题:efit(α,β,pπ,r,t)=λ2de2d(α,β,pπ,r,t)+λ3de3d(α,β,pπ,r,t)+ep(α,β)(16)其中λ2d是2d拟合约束的权重系数,λ3d是3d拟合约束的权重系数,通过求解的姿态,形状和表情参数从而得到拟合的人脸模型。表一是对micc数据集随机分为左右非正脸视角的两个数据集来测试本方法的提升效果,定量结果如下:2d3d2d+3d2d+3d+w2d+3d+p+w左视角3.1842.0532.0021.9041.812右视角3.1462.0262.2411.9111.835表一利用3drmse(3drootmeansquareerror)方法来进行定量评估,单位为毫米(mm),其中w表示提出的权重自适应方法,p表示由粗到精的姿态估计方法。表二是对micc数据集中选取正脸和侧脸两个视角图片拟合出的三维模型与真实数据的之间的误差结果:3ddfaprnoursfrontal2.2442.0861.819non-frontal2.3791.9341.770表二其中3ddfa(3ddensefacealignment)是通过卷积神经网络(cnn)对图像进行三维人脸模型拟合,prn(positionmapregressionnetwork)是一种端到端的方法联合预测人脸对齐和重建三维人脸模型,实验中基于3d点平均误差的单位为毫米(mm)。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1