基于组合语义学习的服务包推荐方法及系统与流程
本发明涉及网络化服务检索技术领域,具体地,涉及一种基于组合语义学习的服务包推荐方法及系统。
背景技术:
在服务经济时代,以用户需求为中心的个性化服务因能为不同需求的用户提供定制化的服务而受到大众的关注,
组合服务技术为用户的需求提供个性化的解决方案。mashup作为服务计算的一项重要技术已经成为组合服务实现中的流行方法。已有一些面向终端用户开发的组合服务开发工具,直观的帮助开发人员利用现有服务开发功能复杂的组合服务。开发人员在交互界面上简单的“拖放”操作即可快速构建mashup。利用开发工具,非专业的开发人员一样能开发出功能复杂且形式多样的组合服务,降低了组合服务的开发周期和开发成本。
利用已有mashup开发工具为组合服务的构建提供了许多便利,然而,如何从海量服务中选择合适的服务仍然具有挑战性。理想的情况是开发人员给出所需设计的自然语言描述的mashup的功能规范,系统返回满足功能需求的若干服务。近年来,互联网上提供了数量庞大的各种服务,如何从服务集中为开发人员推荐合适的服务是现今的研究热点。
先前的研究往往为开发人员推荐一组功能与需求描述相似的服务,按照相似度对推荐的服务进行排序,开发人员仍然需要从中选择合适的服务来构建mashup,同时,推荐的单个服务往往无法满足开发人员的复杂需求。亟需设计一个服务推荐引擎能够为开发人员推荐一组互补的服务,完整涵盖开发人员的需求。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于组合语义学习的服务包推荐方法及系统。
根据本发明提供的一种基于组合语义学习的服务包推荐方法,包括:
步骤m1:采集现有的mashup应用及mashup应用所包含的原子服务;
步骤m2:基于mashup应用中使用的服务之间的协作关系,学习原子服务组合在一起形成的组合语义,构建语义服务包库;
步骤m3:围绕语义服务包库推荐一组互补的服务,完整涵盖mashup应用的功能需求。
优选地,所述步骤m2包括:
步骤m2.1:基于逻辑回归分类器将mashup应用及mashup应用所包含的原子服务的自然语言功能描述分解成语句块;
步骤m2.2:通过利用主题模型lda训练语句块,将每个语句块表示成主题向量;
步骤m2.3:将mashup应用根据不同粒度划分成服务包,将mashup应用表示成服务包的组合;
步骤m2.4:为服务包匹配mashup应用中的语句块,形成围绕服务包的预设数量的语义;利用聚类和过滤操作提取每个服务包的组合语义,构成语义服务包库。
优选地,所述步骤m3包括:
步骤m3.1:输入需要构造的mashup应用的自然语言功能描述,通过话语分割将需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量;
步骤m3.2:从语义服务包库中选择一组与需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量相匹配、相互之间功能互补的服务包;即计算语句块与语义服务包库的语义相似度,当相似度超过阈值时,语句块与语义服务包库的语义相似,即语句块由服务包覆盖,完整涵盖mashup应用的功能需求。
优选地,所述步骤m2.1包括:利用概率判别框架codra将mashup应用的自然语言功能描述转换成话语树,揭示自然语言功能描述中语句块之间的关系;其中,话语树中的叶子结点对应于语句块,话语树中相邻语句块之间通过关系进行标识;通过使用带有参数θ的logistic回归分类器确定功能描述中的mashup应用的自然语言功能描述中的每个单词是否为语句块的边界,从而将功能描述分割成语句块,基于斯坦福rst-dt语料库中利用l-bfgs学习参数θ,使用5重交叉验证避免过拟合;
所述步骤m2.2包括:重复预设次数利用主题模型lda获得mashup应用中语句块以及mashup应用中语句块所包含的原子服务所对应的主题模型lda所建立的主题分布,当主题间的平均相似度最小时,主题模型最优,从而确定主题数量;利用最优主题模型lda训练语句块,将每个语句块表示成主题向量;
所述步骤m2.3包括:将被重用的服务包看作集合分割问题,提高包含服务个数在预设范围内的服务包的权重,通过分割后的服务包数量约束分割的粒度,利用gurobi工具将mashup应用分割成服务包的组合。
优选地,所述步骤m2.4包括:当mashup应用中的语句块与服务包中服务之间的语义相似度超过阈值,则mashup应用中的语句块与服务包之间具有显式语义相似关系,服务包继承当前mashup应用中的语句块的语义;
当mashup应用中的语句块与服务包中服务之间的语义相似度不超过阈值时,则mashup应用中的语句块与服务包无关或mashup应用中的语句块的语义并不对应服务包中单个服务的语义,而表示的是服务包中所有服务的集合语义,即组合语义;
将mashup应用中的语句块的语义分配给所有的服务包后,再通过聚类过程过滤不相关的服务包;根据mashup应用中的语句块的语义之间的距离,将mashup应用中的语句块的语义划分成k个类族,保持mashup应用中的语句块的语义类族紧密连接,再使用k-means聚类来划分服务包的组合语义,构成语义服务包库。
根据本发明提供的一种基于组合语义学习的服务包推荐系统,包括:
模块m1:采集现有的mashup应用及mashup应用所包含的原子服务;
模块m2:基于mashup应用中使用的服务之间的协作关系,学习原子服务组合在一起形成的组合语义,构建语义服务包库;
模块m3:围绕语义服务包库推荐一组互补的服务,完整涵盖mashup应用的功能需求。
优选地,所述模块m2包括:
模块m2.1:基于逻辑回归分类器将mashup应用及mashup应用所包含的原子服务的自然语言功能描述分解成语句块;
模块m2.2:通过利用主题模型lda训练语句块,将每个语句块表示成主题向量;
模块m2.3:将mashup应用根据不同粒度划分成服务包,将mashup应用表示成服务包的组合;
模块m2.4:为服务包匹配mashup应用中的语句块,形成围绕服务包的预设数量的语义;利用聚类和过滤操作提取每个服务包的组合语义,构成语义服务包库。
优选地,所述模块m3包括:
模块m3.1:输入需要构造的mashup应用的自然语言功能描述,通过话语分割将需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量;
模块m3.2:从语义服务包库中选择一组与需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量相匹配、相互之间功能互补的服务包;即计算语句块与语义服务包库的语义相似度,当相似度超过阈值时,语句块与语义服务包库的语义相似,即语句块由服务包覆盖,完整涵盖mashup应用的功能需求。
优选地,所述模块m2.1包括:利用概率判别框架codra将mashup应用的自然语言功能描述转换成话语树,揭示自然语言功能描述中语句块之间的关系;其中,话语树中的叶子结点对应于语句块,话语树中相邻语句块之间通过关系进行标识;通过使用带有参数θ的logistic回归分类器确定功能描述中的mashup应用的自然语言功能描述中的每个单词是否为语句块的边界,从而将功能描述分割成语句块,基于斯坦福rst-dt语料库中利用l-bfgs学习参数θ,使用5重交叉验证避免过拟合;
所述模块m2.2包括:重复预设次数利用主题模型lda获得mashup应用中语句块以及mashup应用中语句块所包含的原子服务所对应的主题模型lda所建立的主题分布,当主题间的平均相似度最小时,主题模型最优,从而确定主题数量;利用最优主题模型lda训练语句块,将每个语句块表示成主题向量;
所述模块m2.3包括:将被重用的服务包看作集合分割问题,提高包含服务个数在预设范围内的服务包的权重,通过分割后的服务包数量约束分割的粒度,利用gurobi工具将mashup应用分割成服务包的组合。
优选地,所述模块m2.4包括:当mashup应用中的语句块与服务包中服务之间的语义相似度超过阈值,则mashup应用中的语句块与服务包之间具有显式语义相似关系,服务包继承当前mashup应用中的语句块的语义;
当mashup应用中的语句块与服务包中服务之间的语义相似度不超过阈值时,则mashup应用中的语句块与服务包无关或mashup应用中的语句块的语义并不对应服务包中单个服务的语义,而表示的是服务包中所有服务的集合语义,即组合语义;
将mashup应用中的语句块的语义分配给所有的服务包后,再通过聚类过程过滤不相关的服务包;根据mashup应用中的语句块的语义之间的距离,将mashup应用中的语句块的语义划分成k个类族,保持mashup应用中的语句块的语义类族紧密连接,再使用k-means聚类来划分服务包的组合语义,构成语义服务包库。
与现有技术相比,本发明具有如下的有益效果:通过对mashup自然语言功能描述的挖掘来发现服务的组合语义,并形成语义服务包库,围绕语义服务包库,为用户推荐一组互补的服务,以尽可能完整涵盖功能需求。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明的推荐框架示意图;
图2为本发明的话语分析中话语树示意图;
图3为本发明的聚类和过滤过程示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
根据本发明提供的一种基于组合语义学习的服务包推荐方法,包括:
步骤m1:采集现有的mashup应用及mashup应用所包含的原子服务;
步骤m2:基于mashup应用中使用的服务之间的协作关系,学习原子服务组合在一起形成的组合语义,构建语义服务包库;
具体地,所述步骤m2包括:
步骤m2.1:根据现有mashup应用及其包含的服务构造语义服务包库,系统对mashup及其包含的服务的自然语言功能描述进行话语分析,基于逻辑回归分类器将mashup应用及mashup应用所包含的原子服务的自然语言功能描述分解成语句块;
具体地,所述步骤m2.1包括:利用概率判别框架codra进行话语分析,将mashup应用的自然语言功能描述转换成话语树,揭示自然语言功能描述中语句块之间的关系;
其中,话语树中的叶子结点对应于语句块,话语树中相邻语句块之间通过关系进行标识;通过使用带有参数θ的logistic回归分类器确定功能描述中的mashup应用的自然语言功能描述中的每个单词是否为语句块的边界,从而将功能描述分割成语句块,基于斯坦福rst-dt语料库中利用l-bfgs学习参数θ,使用5重交叉验证避免过拟合;
步骤m2.2:通过利用主题模型lda训练语句块,将每个语句块表示成主题向量;
所述步骤m2.2包括:重复预设次数利用主题模型lda获得mashup应用中语句块以及mashup应用中语句块所包含的原子服务所对应的主题模型lda所建立的主题分布,当主题间的平均相似度最小时,主题模型最优,从而确定主题数量;利用最优主题模型lda训练语句块,将每个语句块表示成主题向量;当主题模型中训练数据顺序打乱时会产生不同的主题,因此,重复多次运行lda来获得稳定的结果。
步骤m2.3:将mashup应用根据不同粒度划分成服务包,将mashup应用表示成服务包的组合;
所述步骤m2.3包括:每个mashup可以分为多个服务包的组合,对于mashup来说,分割的结果并不唯一。mashup的分割目标是寻找未来有较高概率被重用的服务包,因此,将其建模为一个优化问题。包含服务个数比较少的服务包往往出现的频率较大,因此通过提高包含服务个数较多的服务包的权重。将被重用的服务包看作集合分割问题,提高包含服务个数在预设范围内的服务包的权重,通过分割后的服务包数量约束分割的粒度,利用gurobi工具将mashup应用分割成服务包的组合;
步骤m2.4:为服务包匹配mashup应用中的语句块,形成围绕服务包的预设数量的语义;利用聚类和过滤操作提取每个服务包的组合语义,构成语义服务包库。
具体地,所述步骤m2.4包括:当mashup应用中的语句块与服务包中服务之间的语义相似度超过阈值,则mashup应用中的语句块与服务包之间具有显式语义相似关系,服务包继承当前mashup应用中的语句块的语义;
当mashup应用中的语句块与服务包中服务之间的语义相似度不超过阈值时,则mashup应用中的语句块与服务包无关或mashup应用中的语句块的语义并不对应服务包中单个服务的语义,而表示的是服务包中所有服务的集合语义,即组合语义;
将mashup应用中的语句块的语义分配给所有的服务包后,再通过聚类过程过滤不相关的服务包;根据mashup应用中的语句块的语义之间的距离,将mashup应用中的语句块的语义划分成k个类族,保持mashup应用中的语句块的语义类族紧密连接,而语义类簇之间的距离尽可能大,再使用k-means聚类来划分服务包的组合语义,构成语义服务包库。
步骤m3:围绕语义服务包库推荐一组互补的服务,完整涵盖mashup应用的功能需求。
具体地,所述步骤m3包括:
步骤m3.1:为开发人员推荐一组满足其功能需求的服务包,开发人员输入需要构造的mashup应用的自然语言功能描述,通过话语分割将需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量;
步骤m3.2:从语义服务包库中选择一组与需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量相匹配、相互之间功能互补的服务包推荐给开发人员,从而完整覆盖用户需求。即计算语句块与服务包的语义相似度,当相似度超过给定阈值时,语句块与服务包的语义相似,即语句块的语义可由服务包覆盖,完整涵盖mashup应用的功能需求。
推荐的目标是找到服务包组合,其中服务包覆盖尽可能多的语义,同时,最小化服务包之间的语义重复。可将其建模为一个优化问题。这个优化问题是np问题,由于推荐组合中服务包数量一般都较小,因此,应用全局搜索算法利用gurobi工具包来解决。经过统计分析,mashup包含的服务包数量较小,因此可以使用贪心近似算法来解决和实现此问题。
本发明针对服务功能和相互之间的关系,推荐一组适合创建mashup的服务。通过对mashup自然语言功能描述的挖掘来发现服务的组合语义,并形成语义服务包库,围绕语义服务包库,为用户推荐一组互补的服务,以尽可能完整涵盖功能需求。
根据本发明提供的一种基于组合语义学习的服务包推荐系统,包括:
模块m1:采集现有的mashup应用及mashup应用所包含的原子服务;
模块m2:基于mashup应用中使用的服务之间的协作关系,学习原子服务组合在一起形成的组合语义,构建语义服务包库;
具体地,所述模块m2包括:
模块m2.1:根据现有mashup应用及其包含的服务构造语义服务包库,系统对mashup及其包含的服务的自然语言功能描述进行话语分析,基于逻辑回归分类器将mashup应用及mashup应用所包含的原子服务的自然语言功能描述分解成语句块;
具体地,所述模块m2.1包括:利用概率判别框架codra进行话语分析,将mashup应用的自然语言功能描述转换成话语树,揭示自然语言功能描述中语句块之间的关系;
其中,话语树中的叶子结点对应于语句块,话语树中相邻语句块之间通过关系进行标识;通过使用带有参数θ的logistic回归分类器确定功能描述中的mashup应用的自然语言功能描述中的每个单词是否为语句块的边界,从而将功能描述分割成语句块,基于斯坦福rst-dt语料库中利用l-bfgs学习参数θ,使用5重交叉验证避免过拟合;
模块m2.2:通过利用主题模型lda训练语句块,将每个语句块表示成主题向量;
所述模块m2.2包括:重复预设次数利用主题模型lda获得mashup应用中语句块以及mashup应用中语句块所包含的原子服务所对应的主题模型lda所建立的主题分布,当主题间的平均相似度最小时,主题模型最优,从而确定主题数量;利用最优主题模型lda训练语句块,将每个语句块表示成主题向量;当主题模型中训练数据顺序打乱时会产生不同的主题,因此,重复多次运行lda来获得稳定的结果。
模块m2.3:将mashup应用根据不同粒度划分成服务包,将mashup应用表示成服务包的组合;
所述模块m2.3包括:每个mashup可以分为多个服务包的组合,对于mashup来说,分割的结果并不唯一。mashup的分割目标是寻找未来有较高概率被重用的服务包,因此,将其建模为一个优化问题。包含服务个数比较少的服务包往往出现的频率较大,因此通过提高包含服务个数较多的服务包的权重。将被重用的服务包看作集合分割问题,提高包含服务个数在预设范围内的服务包的权重,通过分割后的服务包数量约束分割的粒度,利用gurobi工具将mashup应用分割成服务包的组合;
模块m2.4:为服务包匹配mashup应用中的语句块,形成围绕服务包的预设数量的语义;利用聚类和过滤操作提取每个服务包的组合语义,构成语义服务包库。
具体地,所述模块m2.4包括:当mashup应用中的语句块与服务包中服务之间的语义相似度超过阈值,则mashup应用中的语句块与服务包之间具有显式语义相似关系,服务包继承当前mashup应用中的语句块的语义;
当mashup应用中的语句块与服务包中服务之间的语义相似度不超过阈值时,则mashup应用中的语句块与服务包无关或mashup应用中的语句块的语义并不对应服务包中单个服务的语义,而表示的是服务包中所有服务的集合语义,即组合语义;
将mashup应用中的语句块的语义分配给所有的服务包后,再通过聚类过程过滤不相关的服务包;根据mashup应用中的语句块的语义之间的距离,将mashup应用中的语句块的语义划分成k个类族,保持mashup应用中的语句块的语义类族紧密连接,而语义类簇之间的距离尽可能大,再使用k-means聚类来划分服务包的组合语义,构成语义服务包库。
模块m3:围绕语义服务包库推荐一组互补的服务,完整涵盖mashup应用的功能需求。
具体地,所述模块m3包括:
模块m3.1:为开发人员推荐一组满足其功能需求的服务包,开发人员输入需要构造的mashup应用的自然语言功能描述,通过话语分割将需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量;
模块m3.2:从语义服务包库中选择一组与需要构造的mashup应用的自然语言功能描述分解成语句块及语句块对应的主题向量相匹配、相互之间功能互补的服务包推荐给开发人员,从而完整覆盖用户需求。即计算语句块与服务包的语义相似度,当相似度超过给定阈值时,语句块与服务包的语义相似,即语句块的语义可由服务包覆盖,完整涵盖mashup应用的功能需求。
推荐的目标是找到服务包组合,其中服务包覆盖尽可能多的语义,同时,最小化服务包之间的语义重复。可将其建模为一个优化问题。这个优化问题是np问题,由于推荐组合中服务包数量一般都较小,因此,应用全局搜索算法利用gurobi工具包来解决。经过统计分析,mashup包含的服务包数量较小,因此可以使用贪心近似算法来解决和实现此问题。
本发明针对服务功能和相互之间的关系,推荐一组适合创建mashup的服务。通过对mashup自然语言功能描述的挖掘来发现服务的组合语义,并形成语义服务包库,围绕语义服务包库,为用户推荐一组互补的服务,以尽可能完整涵盖功能需求。
以下优选例对本发明作更为详细的说明:
以下将结合本发明的附图,对本发明实施例中的技术方案进行清楚、完整的描述和讨论,显然,这里所描述的仅仅是本发明的一部分实例,并不是全部的实例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
为了便于对本发明实施例的理解,下面将结合附图以具体实施例为例作进一步的解释说明,且各个实施例不构成对本发明实施例的限定。
本发明通过以下技术方案实现:
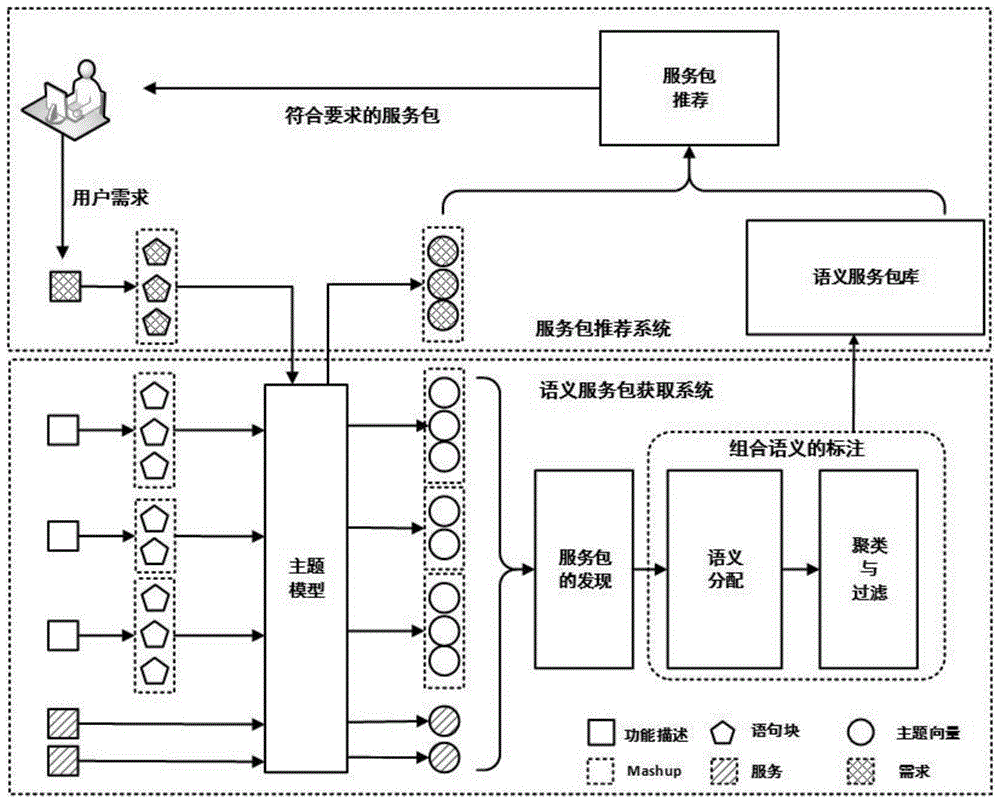
一种基于组合语义学习的服务包推荐方法,根据mashup文本描述挖掘服务的组合语义,根据用户需求推荐一组互补的服务。基于组合语义学习的服务包推荐框架包含两个子系统:语义服务包获取系统和服务包推荐系统。见图1示意图,其中:
语义服务包获取系统:根据现有mashup及其包含的服务构造语义服务包库。系统对mashup及其包含的服务的自然语言功能描述进行话语分析,基于逻辑回归分类器将自然语言功能描述分解成语句块,利用主题模型训练语句块,将每个语句块表示成主题向量。将现有mashup根据不同粒度划分成服务包,于是mashup可以表示成服务包的组合。为服务包匹配mashup中的语句块,形成围绕服务包的若干语义。利用聚类和过滤操作提取每个服务包的组合语义,构建语义服务包库。
服务包推荐系统:为开发人员推荐一组满足其功能需求的服务包。开发人员输入所需构造的mashup的自然语言功能描述时,系统将需求分解成语句块及其对应的主题向量。从语义服务包库中选择一组服务包推荐给开发人员,其中,每个服务包不仅与需求描述中的语句块相匹配,相互之间功能互补,从而完整覆盖用户需求。
具体步骤为:
s1、基于主题模型的语义提取
利用一种概率判别框架codra进行话语分析,将mashup的自然语言功能描述转换成话语树,揭示自然语言功能描述中语句块之间的关系,其中,话语树中的叶子结点对应于语句块,话语树中相邻语句块之间通过关系进行标识,见图2示意图。通过使用带有参数θ的logistic回归分类器确定描述中的单词是否为语句块的边界:
p(y|w,θ)=bernoulli(y|sigmoid(θtx)(1)
其中,x表示自然语言功能描述中单词w的词法-句法特征向量。如果w是语句块的边界则y=1,,否则y=0。w表示单词,上标t表示转置,p()表示概率,bernoulli()表示伯努利函数,sigmoid()表示阀值函数,模型的l2损失函数为:
其中,n表示单词个数,
进一步利用lda获得mashup中语句块以及mashup中包含的服务所对应的主题分布,模型在单词w上指定了以下分布:
其中,zj表示相关主题,t表示主题数量。当主题间的平均相似度avgsim最小时模型最优,根据这一定理来确定主题数量:
当主题模型中训练数据顺序打乱时会产生不同的主题,因此,通过重复运行lda来提高结果的稳定性。
s2、可重用服务包的发现
每个mashup可以分成多个服务包的组合。对于mashup来说,分割的结果并不惟一。mashup的分割目标是寻找未来有较高概率被重用的服务包。因此,可以将其建模为一个优化问题:
xj∈{0,1}(j=1,2,...,n)
其中,
本质上可重用服务包的发现是一个集合分割问题,利用gurobi工具将mashup分割成服务包的组合。
s3、组合语义的标注
如果语句块与服务包中服务之间的语义相似度超过给定阈值,则认为语句块与服务包之间具有显式语义相似关系,那么,服务包继承了该语句块的语义。否则,它们之间可能有有两种关系:(1)语句块与服务包无关;(2)语句块的语义并不对应服务包中单个服务的语义,而表示的是服务包中所有服务的集体语义,称之为组合语义。
为了标注组合语义,先将语句块的语义分配给所有服务包,再通过聚类过程过滤掉不相关的服务包。根据语义之间的距离,将语义划分成k个类簇,尽量保持语义类簇中的语义紧密连接,而语义类簇之间的距离尽可能大。可以使用k-means聚类来划分服务包的语义。
部分语义类簇是由服务包中的服务从与其具有显示语义相似关系的语句块中继承所得,其余类簇如果相对较大,则代表此服务包的组合语义,因为类似的组合语义经常出现在包含此服务包的mashup中。因此,如果类簇的大小超过给定的阈值,则将其视为组合语义。余下的较小类簇表示的是一个个分散的语义,表示这些语义并不经常出现在mashup中,可以过滤掉这些不相关的语义,见图3示意图。
s4、基于组合语义学习的服务包推荐算法
将开发人员输入的需求描述分割成语句块及其对应的主题向量,计算语句块与服务包的语义相似度,当相似度超过给定阈值时,语句块与服务包的语义相似,即语句块的语义可由服务包覆盖。推荐的目标是找到服务包组合,其中的服务包覆盖尽可能多的语义,同时,最小化服务包之间的语义重复。可将其建模为一个优化问题:
ri∈{0,1}(i=1,2,...,n)
其中,ri表示服务包pi是否包含在推荐组合中,n表示sspa系统中语义服务包库中服务包的总数,simi表示服务包pi与需求描述之间的语义相似度,dupij表示服务包pi与服务包pj之间的语义重叠度,d表示推荐组合中包含的服务包的数量。
这个优化问题是np问题,由于推荐组合中服务包数量d一般都较小,因此,应用全局搜索算法利用gurobi工具包来解决。经过统计分析,mashup包含的服务包数量较小,因此使用贪心近似算法来解决和实现此问题。
本发明针对服务功能和相互之间的关系,推荐一组适合创建mashup的服务。通过对mashup自然语言功能描述的挖掘来发现服务的组合语义,并形成语义服务包库,围绕语义服务包库,为用户推荐一组互补的服务,以尽可能完整涵盖功能需求。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!