基于生成对抗网络的图像超分辨率方法与流程
本发明涉及计算机视觉领域,具体涉及基于生成对抗网络(gan)的图像超分辨率方法。
背景技术:
在日常的生产生活中,图像是一种重要的信息载体,而图像分辨率是衡量图像质量的重要标准之一。高分辨率图像包含更多的纹理特征,可以提供更多的信息,因此在生产生活中人们更希望获取到高分辨率图像。但是由于成像设备的参差不齐、网络传输过程图像信息的丢失等原因,通过图像超分辨率来提高图像的分辨率成本更低、效果好、更容易实现。因此图像超分辨率更为实用,对图像超分辨率任务的研究具有重要意义。
图像超分辨率方法主要分为三种:基于插值的、基于重建的和基于学习的。近年来,深度学习被广泛应用于计算机视觉领域,取得不错的效果,基于深度学习的图像超分辨率算法也不断提出并取得很好的重建效果和较快的重建速度。董超等人提出的srcnn首次将卷积神经网络(cnn)引入到图像超分辨率任务,并取得不错的重建效果。自此,大量基于cnn的图像超分辨率方法提出,学者通过加深网络来提高网络的重建性能。但是使用均方误差损失(mse)来优化网络会使得生成的图像过于平滑,视觉效果差。srgan(ledigc,theisl,huszárf,etal.photo-realisticsingleimagesuper-resolutionusingagenerativeadversarialnetwork[a].in:proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition[c],2017.4681–4690.)将生成对抗网络(gan)引入到图像超分辨率任务中,利用感知损失和对抗损失等损失函数来监督网络,使得生成图像具有更好的视觉效果,更加接近于真实图像。esrgan(wangx,yuk,wus,etal.esrgan:enhancedsuper-resolutiongenerativeadversarialnetworks[a].in:europeanconferenceoncomputervision[c],2018.63–79.)提出使用residual-in-residualdenseblock(rrdb)来构建生成网络,使用ragan(jolicoeur-martineaua.therelativisticdiscriminator:akeyelementmissingfromstandardgan[j].arxivpreprintarxiv:1807.00734,2018.)的判别网络来监督生成网络,生成的图像视觉效果更好。
但是上述的基于生成对抗网络(gan)的图像超分辨率方法srgan和esrgan也存在一些问题:
1)这些基于gan的图像超分辨率方法的判别网络往往只输出一个介于[0,1]的概率值,在整体上判断输入图像是生成的超分辨率图像还是真实高分辨率图像,以此来监督生成网络来生成更接近真实高分辨率图像的超分辨率图像。但是这种监督是粗糙的,生成网络不知道生成图像的哪个像素点的重建效果更好,哪个像素点的重建的效果更差。
2)这些基于gan的图像超分辨率方法通常包含两个独立的网络——生成网络和判别网络。但是,生成网络和判别网络的浅层部分都是用于提取图像的底层特征,包括边缘,角点等信息。这两个网络的浅层部分具有相似或者相同的作用,但是却独立在不同的分支中,增加了模型的参数量。其次,生成网络和判别网络在的信息传递上只有对抗损失,判别网络将对抗损失传递给生成网络,生成网络通过该损失学习生成使判别器分类错误的超分辨率图像。对抗损失对生成网络的影响是不充分的,不能全面地向生成网络反映出如何更好地生成靠近真实高分辨率图像的超分辨率图像的。
技术实现要素:
本发明的目的在于解决上述的问题,提供两种改进的基于gan的图像超分辨率方法。本发明通过改进的生成式对抗网络来解决图像超分辨率问题,使用判别网络来监督生成网络,使生成网络生成更接近于真实图像的超分辨率图像。与之前的基于gan的图像超分辨率网络比较,本发明能够生成更高质量的超分辨率图像。
本发明的目的至少通过以下技术方案之一实现。
基于生成对抗网络的图像超分辨率方法,包括以下步骤:
s1、获取训练数据集、验证数据集;
s2、采用两种不同的方法构建图像超分辨率模型,包括生成网络模型和判别网络模型;所述两种方法包括细粒度注意力机制的基于gan的图像超分辨率方法(fasrgan)以及特征共享的基于gan的图像超分辨率方法(fs-srgan);
s3、初始化步骤s2中建立的生成网络模型和判别网络模型的权重,初始化网络模型,选取优化器,设置网络训练的参数;
s4、首先使用l1损失来训练生成网络模型直到网络收敛,使得生成网络具有较好的重建图像的能力,保存训练过程中的生成网络模型;加载预训练好的生成网络模型,使用生成网络和判别网络的损失函数来同时训练生成网络模型和判别网络模型,直到生成网络和判别网络达到纳什平衡,保存此过程中的生成网络模型和判别网络模型;
s5、获取测试数据集;
s6、加载训练好的生成网络模型,将测试数据集输入到生成网络模型,生成超分辨率图像;
s7、计算生成的超分辨率图像与真实的高分辨率图像之间的峰值信噪比(psnr),计算生成图像的图像重建质量的评价指标,评估图像的重建质量。
进一步地,步骤s1中,采用div2k数据集中的若干张2k图像来制作成对的低分辨率-高分辨率图像作为训练数据集;对原始的2k图像进行下采样处理得到低分辨率图像,与原始的高分辨率图像构成训练样本对;由于原始的图像尺寸太大,直接输入到网络模型中进行训练会造成网络模型计算量过大,减慢训练速度,因此对训练图像进行随机剪裁,将低分辨率图像裁剪为m×k大小的图像块,其中m代表图像块的高度,k代表其宽度,对应的高分辨率图像裁剪为mr×kr,r为放大因子;为了增强训练数据集中数据的多样性和扩展数据量,将成对的训练数据即低分辨率-高分辨率图像进行翻转和旋转操作,包括90°、180°和270°;
所述验证数据集采用set5数据集,由5张图像组成,在网络训练过程用于评估生成网络的重建性能,利于观察生成网络模型的收敛程度。
进一步地,步骤s2中,细粒度注意力机制的基于gan的图像超分辨率方法中,所述的判别网络模型采用unet结构,上分支与传统的判别网络模型具有相同的结构,利用步长为2的池化层来减少特征图的空间大小,扩大感受野;经过r次池化层,特征图的空间大小变为原来的
所述判别网络模型的下分支采用不断上采样的方式,逐步扩大特征图的空间大小,将上分支与下分支具有相同大小的特征图进行串联,利于判别网络模型中的信息流动和对下分支中浅层次特征的充分利用;每个上采样后的特征图经过两个卷积层处理;下分支最终输出一个与输入图像大小相同的掩码图(maskmap),表示判别网络模型对输入图像的每个像素的判别信息,其中,该像素上的值越接近于1代表该像素与真实图像的对应像素越相似,反之越不相似;将此掩码图加入到生成网络模型的损失函数中,使生成网络模型关注于重建得不好的像素,监督生成网络模型去重建出更高质量的超分辨率图像;判别网络模型的损失函数包括两个部分:对抗损失和细粒度的attention损失,公式如下:
其中,xr和xf代表真实图像和生成图像,σ是sigmoid函数,c(x)指判别网络中sigmoid函数之前的输出,dra代表判别网络的函数,
其中,mr和mf分别代表了真实图像和生成图像的掩码图,w、h、c分别代表输入到生成网络模型的低分辨率图像的宽度、长度和通道数目,r为放大因子,则生成网络模型的输出图像的宽度为wr,而长度为hr。
进一步地,步骤s2中,细粒度注意力机制的基于gan的图像超分辨率方法中,所述生成网络模型采用rrdb(residual-in-residualdenseblock)作为基础模块,通过以线性串联的方式来堆叠a个rrdb来构建深层的网络结构,重建出高质量的超分辨率图像;生成网络模型的损失函数如下:
lg=l1+λadv*ladv+λattention*lattention+λpercep*lpercep;
其中,λadv、λattention、λpercep代表平衡不同损失函数项的系数;
lattention表示细粒度的attention损失,公式如下:
其中,mf是判别网络模型络生成的超分辨率图像的掩码图(maskmap),mf(w,h,c)表示生成图像isr(w,h,c)与真实图像之间的每个像素的差异,使用1-mf(w,h,c)的方法来给图像的每个像素分配不同的权重,使得与真实图像分布差异较大的像素受到更多的关注;
l1表示内容损失,约束生成图像在内容上更加接近于真实图像,公式如下:
其中,
lpercep表示感知损失,目的是使生成图像在高阶的特征层面上与对应的高分辨率图像接近,采用预训练的vgg19网络的第54层的特征来计算感知损失,公式如下:
其中
ladv表示对抗损失,生成网络模型需要重建出使判别网络模型难以判别出是生成图像的超分辨率图像,因此其公式与判别网络模型的对抗损失相反,具体如下:
进一步地,步骤s2中,特征共享的基于gan的图像超分辨率方法中,将生成网络和判别网络的浅层特征提取模块协同起来,减少模型的参数;生成网络和判别网络共同优化浅层特征提取模块,有利于提取出更加有效的特征;共用的浅层特征提取模块采用特征图的大小不变的全卷积神经网络,公式如下:
hshared=fshared(x);
其中fshared代表共用的浅层特征提取模块的函数,hshared代表浅层特征提取模块所输出的特征图,x指的是输入到浅层特征提取模块的特征图。
进一步地,特征共享的基于gan的图像超分辨率方法中,所述生成网络模型包括浅层特征提取模块、深层特征提取模块和重建模块;其中,深层特征提取模块的基础模块与浅层特征提取模块的相同;浅层特征提取模型由s个rrdb构成,而深层特征提取模块由d个rrdb通过线性串联的方式堆叠而成,d>s,用于提取更多的抽象特征和高频特征,为重建出高质量的超分辨率图像提供重要信息;重建模块通过上采样层来将特征图放大到指定的尺寸,使用卷积层重建出超分辨率图像;
生成网络模型的损失函数包括对抗损失、内容损失和感知损失,如下:
lg=l1+λadv*ladv+λpercep*lpercep;
λadv和λpercep代表平衡不同损失函数项的系数;
l1表示内容损失,约束生成图像在内容上更加接近于真实图像,公式如下:
其中,
lpercep表示感知损失,目的是使生成图像在高阶的特征层面上与对应的高分辨率图像接近,采用预训练的vgg19网络的第54层的特征来计算感知损失,公式如下:
其中
ladv表示对抗损失,生成网络模型需要重建出使判别网络模型难以判别出是生成图像的超分辨率图像,因此其公式与判别网络模型的对抗损失相反,具体如下:
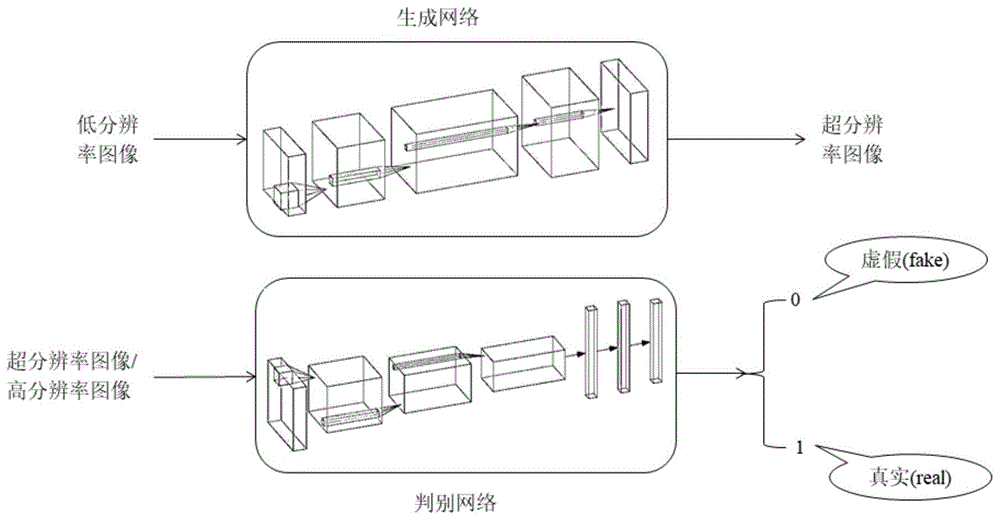
进一步地,特征共享的基于gan的图像超分辨率方法中,所述判别网络模型是一个分类网络,需要使用更大的感受野去获取图像在整体上的抽象特征;使用类似vgg网络的结构作为判别网络模型,判别网络模型由n个卷积层组合和一个线性分类器组成,所述卷积层组合是由卷积核为3的一层卷积和卷积核为4,步长为2的卷积层组成的;为了减少信息的损失,判别网络模型使用了步长为2的卷积层来替代池化层,从而减小特征图的大小;为了保持较好的特征表达能力,在减小特征图的同时增加通道的数目;最后,将特征图变为一维的向量,并通过两层的全连接网络输出对输入图像判别的分类值,其中0表示生成图像(fake),1表示真实图像(real);
判别网络模型的损失函数为对抗损失,具体如下:
其中,xr和xf代表真实图像和生成图像,σ是sigmoid函数,c(x)指判别网络中sigmoid函数之前的输出,dra代表判别网络的函数,
进一步地,步骤s3中,对所述生成网络模型和判别网络模型中的所有卷积层采用kaiming_normal来初始化其权重;选取adam作为网络训练时的优化器;
所述网络训练的参数包括:指定训练数据集和验证数据集的路径、指定放大因子r、输入到网络的批数据量、初始学习率lr_initial;adam优化器的参数、生成网络和判别网络的损失函数中各项损失函数的系数以及训练的迭代次数niter。
迭代训练的过程中,生成网络模型和判别网络模型的损失函数的收敛曲线可能会产生震荡,表明当前的学习率过大,因此,在同时训练生成网络模型和判别网络模型时,每隔lr_step步将学习率减半,加速生成网络模型和判别网络模型的收敛速度,提高生成网络模型的重建性能和判别网络模型的判别性能;在训练过程中使用adam优化器来对生成网络模型和判别网络模型的梯度进行反向传播,不断更新两个模型的权重。
进一步地,步骤s4中,在网络训练的初期使用多个损失函数训练会使得网络训练动荡,损失函数的曲线难以收敛;因此,首先采用l1损失对生成网络模型进行预训练,得到预训练好的生成网络模型。训练过程中采用adam优化器进行梯度的反向传播,更新参数;初始学习率为lr_g,迭代次数为niter_g,每隔lr_step_g次迭代对学习率进行减半,加快生成网络模型的收敛和提高生成网络模型的重建性能;接着使用上述的生成网络的损失函数和判别网络的损失函数来同时训练生成网络模型和判别网络模型;当生成网络模型和判别网络模型达到纳什平衡时,生成网络模型生成的超分辨率图像,使得判别网络模型不能区分出是生成的超分辨率图像还是真实的高分辨率图像;
步骤s5中,测试数据集采用图像超分辨率任务中常见的测试数据集set5、set14、urban100、bsd100、manga109和div2k验证集测试数据集。
进一步地,步骤s7中,采用根均方误差(rmse)和感知指数(pi)作为图像重建质量的评价指标,将图像转到ycbcr空间,在y通道上进行计算根均方误差或者峰值信噪比pnsr。
其中h、w为低分辨率图像的长度和宽度,r为放大因子,x为真实图像,
mse为均方误差,n为每像素的比特数;psnr的单位是分贝(db),数值越大表示失真越小,重建质量越好;
其中ma(mac,yangcy,yangx,etal.learningano-referencequalitymetricforsingle-imagesuper-resolution[j].computervisionandimageunderstanding,2017,158:1-16)与niqe(mittala,fellow,ieee,etal.makinga'completelyblind'imagequalityanalyzer[j].ieeesignalprocessingletters,2013,20(3):209-212.)是两个无参考图像测量方式,用于感知质量评估;pi被用来作为2018pirmchallengeonperceptualimagesuper-resolution(blauy,mechrezr,timofter,etal.the2018pirmchallengeonperceptualimagesuper-resolution[a].ineuropeanconferenceoncomputervision[c],2018.7794-7803.)的评价指标之一;pi与人类对图像的主观评价有相关性,数值越小,在一定程度上反映了图像越具有感知质量,为了保证重建的超分辨率图像在内容上与真实的高分辨率图像相似,pi通常需要与mse结合来评价重建图像的质量。
相比于现有技术,本发明的优点在于:
1)本发明提出了基于生成对抗网络的图像超分辨率方法,包括细粒度注意力机制的基于gan的图像超分辨率方法(fasrgan)和特征共享的基于gan的图像超分辨率方法(fs-srgan)。其中fasrgan采用unet结构来构建判别网络,使其输出一个在整体图像上判断输入图像是生成的图像还是真实的图像的介于[0,1]的分类值,和一个在像素层面上判断输入图像在每个像素上与真实的图像之间的差异的掩码图(maskmap)。将maskmap加入到生成网络模型的损失函数中,使生成网络更加关注于重建图像中效果较差的部分,从而重建出质量更好的超分辨率图像。fs-srgan将生成网络和判别网络的浅层特征提取部分进行共享,使得这两个网络共用一个浅层特征提取模块,在减少生成网络模型和判别网络模型的参数量的同时,让生成网络和判别网络的损失函数来共同优化该浅层特征提取模块,有利于该模块提取到对生成网络和判别网络更加有效的特征,从而提高生成网络的重建能力。
2)本发明通过优化网络结构来提升网络重建超分辨率图像的性能,解决图像超分辨率问题,并且取得比当前主流的图像超分辨率方法更好的重建效果。
附图说明
图1基于生成对抗网络(gan)方法的图像超分辨率方法的网络模型,生成网络(generator)包括浅层特征提取模块、深层特征提取模型、重建模块,重建高质量的超分辨率图像,而判别网络(discriminator)包含浅层特征提取、深层抽象特征表示、分类器,判别输入图像为真实高分辨率图像(real)还是虚假的生成图像(fake);
图2本发明的训练流程图与测试流程图;
图3为细粒度注意力机制的基于gan的图像超分辨率方法(fasrgan)的判别网络,其中,k、s、g分别表示卷积层中卷积核大小、卷积步长和通道数;
图4为特征共享的基于gan的图像超分辨率方法(fs-srgan)的网络模型;
图5为本发明提出的两个基于gan的图像超分辨率方法的网络训练方式和步骤;
图6为本发明中的fasrgan与当前流行的图像超分辨率方法在放大因子为4时的结果示意图;
图7为本发明中fasrgan的消融实验结果示意图,去掉细粒度注意力机制;
图8为当放大因子为4时,本发明中fs-srgan与当前流行的图像超分辨率方法的视觉对比图;
图9为本发明中fs-srgan的消融实验结果示意图,去掉特征共享机制;
图10为在放大因子为4时,本发明中提出的两种方法与当前流行的图像超分辨率方法在数据集urban100中均方根误差(rmse)与感知指标(pi)之间的权衡,其中fa+fs-gan将本发明中的细粒度注意力机制和特征共享机制融合到同一个基于gan的图像超分辨率模型中;
图11为本发明训练过程中,当放大因子为4时,本发明方法在set14数据集上平均pi值的变化曲线,其中fa+fs-gan将本发明中的细粒度注意力机制和特征共享机制融合到同一个基于gan的图像超分辨率模型中。
具体实施方式
下面结合实施例及附图对本发明的具体实施作进一步详细的描述,但本发明的实施方式不限于此。
实施例:
基于生成对抗网络的图像超分辨率方法,如图2所示,包括以下步骤:
s1、获取训练数据集、验证数据集;
本实施例中,采用div2k数据集中的800张2k图像来制作成对的低分辨率-高分辨率图像作为训练数据集;对原始的2k图像进行下采样处理得到低分辨率图像,与原始的高分辨率图像构成训练样本对;由于原始的图像尺寸太大,直接输入到网络模型中进行训练会造成网络模型计算量过大,减慢训练速度,因此对训练图像进行随机剪裁,将低分辨率图像裁剪为m×k大小的图像块,其中m代表图像块的高度,k代表其宽度,对应的高分辨率图像裁剪为mr×kr,r为放大因子;本实例中,将低分辨率图像裁剪为48×48大小的图像块,则当放大因子为2时,其对应的高分辨率图像块为96。为了增强训练数据集中数据的多样性和扩展数据量,将成对的训练数据即低分辨率-高分辨率图像进行翻转和旋转操作,包括90°、180°和270°;
所述验证数据集采用set5数据集,由5张图像组成,在网络训练过程用于评估生成网络的重建性能,利于观察生成网络模型的收敛程度。
s2、采用两种不同的方法构建图像超分辨率模型,包括生成网络模型和判别网络模型;所述两种方法包括细粒度注意力机制的基于gan的图像超分辨率方法(fasrgan)以及特征共享的基于gan的图像超分辨率方法(fs-srgan);
如图3所示,细粒度注意力机制的基于gan的图像超分辨率方法中,所述的判别网络模型采用unet结构,上分支与传统的判别网络模型具有相同的结构,利用步长为2的池化层来减少特征图的空间大小,扩大感受野;经过r次池化层,特征图的空间大小变为原来的
所述判别网络模型的下分支采用不断上采样的方式,本实施例采用双线性对特征图进行上采样,逐步扩大特征图的空间大小,将上分支与下分支具有相同大小的特征图进行串联,利于判别网络模型中的信息流动和对下分支中浅层次特征的充分利用;每个上采样后的特征图经过两个卷积核为3的卷积层处理;下分支最终输出一个与输入图像大小相同的掩码图(maskmap),表示判别网络模型对输入图像的每个像素的判别信息,其中,该像素上的值越接近于1代表该像素与真实图像的对应像素越相似,反之越不相似;将此掩码图加入到生成网络模型的损失函数中,使生成网络模型关注于重建得不好的像素,监督生成网络模型去重建出更高质量的超分辨率图像;判别网络模型的损失函数包括两个部分:对抗损失和细粒度的attention损失,公式如下:
其中,xr和xf代表真实图像和生成图像,σ是sigmoid函数,c(x)指判别网络中sigmoid函数之前的输出,dra代表判别网络的函数,
其中,mr和mf分别代表了真实图像和生成图像的掩码图,w、h、c分别代表输入到生成网络模型的低分辨率图像的宽度、长度和通道数目,r为放大因子,则生成网络模型的输出图像的宽度为wr,而长度为hr。
如图1所示,细粒度注意力机制的基于gan的图像超分辨率方法中,所述生成网络模型结构与既有的基于生成对抗网络的图像超分辨率方法,esrgan(wangx,yuk,wus,etal.esrgan:enhancedsuper-resolutiongenerativeadversarialnetworks[a].in:europeanconferenceoncomputervision[c],2018.63–79.)的结构类似,包含浅层特征提取模块、深层特征提取模块和重建模块。所述的生成网络模型采用一层3×3卷积作为浅层特征提取模块,采用rrdb(residual-in-residualdenseblock)作为基础模块,通过以线性串联的方式来堆叠a个rrdb来构建深层特征提取模块,本实施例将a设置为23,提取的深层特征经过上采样层和重建层,重建出高质量的超分辨率图像,本实施例的上采样层采用sub-pixel的方法,重建层为一层3×3的卷积;生成网络模型的损失函数如下:
lg=l1+λadv*ladv+λattention*lattention+λpercep*lpercep;
其中,λadv、λattention、λpercep代表平衡不同损失函数项的系数;
lattention表示细粒度的attention损失,公式如下:
其中,mf是判别网络模型络生成的超分辨率图像的掩码图(maskmap),mf(w,h,c)表示生成图像isr(w,h,c)与真实图像之间的每个像素的差异,使用1-mf(w,h,c)的方法来给图像的每个像素分配不同的权重,使得与真实图像分布差异较大的像素受到更多的关注;
l1表示内容损失,约束生成图像在内容上更加接近于真实图像,公式如下:
其中,
lpercep表示感知损失,目的是使生成图像在高阶的特征层面上与对应的高分辨率图像接近,采用预训练的vgg19网络的第54层的特征来计算感知损失,公式如下:
其中
ladv表示对抗损失,生成网络模型需要重建出使判别网络模型难以判别出是生成图像的超分辨率图像,因此其公式与判别网络模型的对抗损失相反,具体如下:
如图4所示,特征共享的基于gan的图像超分辨率方法中,将生成网络和判别网络的浅层特征提取模块协同起来,减少模型的参数;生成网络和判别网络共同优化浅层特征提取模块,有利于提取出更加有效的特征;共用的浅层特征提取模块采用特征图的大小不变的全卷积神经网络,公式如下:
hshared=fshared(x);
其中fshared代表共用的浅层特征提取模块的函数,hshared代表浅层特征提取模块所输出的特征图,x指的是输入到浅层特征提取模块的特征图。
如图4所示,特征共享的基于gan的图像超分辨率方法中,所述生成网络模型包括浅层特征提取模块、深层特征提取模块和重建模块;其中,深层特征提取模块的基础模块与浅层特征提取模块的相同;浅层特征提取模型由s个rrdb构成,而深层特征提取模块由d个rrdb通过线性串联的方式堆叠而成,d>s,用于提取更多的抽象特征和高频特征,为重建出高质量的超分辨率图像提供重要信息;重建模块通过上采样层来将特征图放大到指定的尺寸,使用卷积层重建出超分辨率图像;本实施例将s设为1,d设为16,上采样层采用sub-pixel的方式。
生成网络模型的损失函数包括对抗损失、内容损失和感知损失,如下:
lg=l1+λadv*ladv+λpercep*lpercep;
λadv和λpercep代表平衡不同损失函数项的系数;
l1表示内容损失,约束生成图像在内容上更加接近于真实图像,公式如下:
其中,
lpercep表示感知损失,目的是使生成图像在高阶的特征层面上与对应的高分辨率图像接近,采用预训练的vgg19网络的第54层的特征来计算感知损失,公式如下:
其中
ladv表示对抗损失,生成网络模型需要重建出使判别网络模型难以判别出是生成图像的超分辨率图像,因此其公式与判别网络模型的对抗损失相反,具体如下:
如图4所示,特征共享的基于gan的图像超分辨率方法中,所述判别网络模型是一个分类网络,需要使用更大的感受野去获取图像在整体上的抽象特征;使用类似vgg网络的结构作为判别网络模型,判别网络模型由n个卷积层组合和一个线性分类器组成,所述卷积层组合是由卷积核为3的一层卷积和卷积核为4,步长为2的卷积层组成的,本实施例将n设为5;为了减少信息的损失,判别网络模型使用了步长为2的卷积层来替代池化层,从而减小特征图的大小;为了保持较好的特征表达能力,在减小特征图的同时增加通道的数目;最后,将特征图变为一维的向量,并通过两层的全连接网络输出对输入图像判别的分类值,其中0表示生成图像(fake),1表示真实图像(real);
判别网络模型的损失函数为对抗损失,具体如下:
其中,xr和xf代表真实图像和生成图像,σ是sigmoid函数,c(x)指判别网络中sigmoid函数之前的输出,dra代表判别网络的函数,
s3、初始化步骤s2中建立的生成网络模型和判别网络模型的权重,初始化网络模型,选取优化器,设置网络训练的参数;
对所述生成网络模型和判别网络模型中的所有卷积层采用kaiming_normal来初始化其权重;选取adam作为网络训练时的优化器;
所述网络训练的参数包括:指定训练数据集和验证数据集的路径、指定放大因子r、输入到网络的批数据量b、初始学习率lr_initial;adam优化器的参数、生成网络和判别网络的损失函数中各项损失函数的系数以及训练的迭代次数niter。
本实施例中,在训练细粒度注意力机制的基于gan的图像超分辨率网络时,输入到网络的批数据量b设为12、初始学习率lr_initial设为0.0001;训练特征共享的基于gan的图像超分辨率网络时,批数据量设为32、初始学习率lr_initial为0.0001;所述的细粒度注意力机制的基于gan的图像超分辨率方法,生成网络的损失函数中lattention损失的系数为0.02,ladv损失的系数为0.005,lpercep损失的系数为1;所述的特征共享的基于gan的图像超分辨率方法,生成网络的损失函数中的ladv损失的系数为0.005,lpercep损失的系数为1;两种方法的训练的迭代次数niter都设为5×105。
迭代训练的过程中,生成网络模型和判别网络模型的损失函数的收敛曲线可能会产生震荡,表明当前的学习率过大,因此,在同时训练生成网络模型和判别网络模型时,每隔lr_step步将学习率减半,加速生成网络模型和判别网络模型的收敛速度,提高生成网络模型的重建性能和判别网络模型的判别性能,本实施例中,lr_step设为50000;在训练过程中使用adam优化器来对生成网络模型和判别网络模型的梯度进行反向传播,不断更新两个模型的权重,本实施例中,adam的参数设置为:β1=0.9,β2=0.999以及ε=10-8。
s4、如图5所示,在网络训练的初期使用多个损失函数训练会使得网络训练动荡,损失函数的曲线难以收敛;首先使用l1损失来训练生成网络模型,使得生成网络具有较好的重建图像的能力,保存训练过程中的生成网络模型;在本实施例中,训练过程中采用adam优化器进行梯度的反向传播,更新参数,其参数设置为β1=0.9,β2=0.999以及ε=10-8;初始学习率lr_g为0.0002,迭代次数niter_g为1×106,每隔lr_step_g=2×105次迭代对学习率进行减半,加快生成网络模型的收敛和提高生成网络模型的重建性能。接着加载预训练好的生成网络模型,使用上述的生成网络的损失函数和判别网络的损失函数来同时训练生成网络模型和判别网络模型;生成网络和判别网络是一种对抗的关系,像是一种博弈游戏,生成网络需要生成与真实图像尽可能相近的超分辨率图像,使得判别网络不能区分输入的图像为真实图像还是生成图像;当生成网络模型和判别网络模型达到纳什平衡时,即判别网络模型的损失函数大概为0.5时,生成网络模型生成的超分辨率图像,使得判别网络模型不能区分出是生成的超分辨率图像还是真实的高分辨率图像。
本实施例中,每隔5000次迭代训练,将使用验证数据集对生成网络模型的性能做一个评估,计算其峰值信噪比(pnsr);首先对验证数据集的高分辨率图像(hr)进行下采样处理,得到对应的低分辨率图像(lr),组成验证图像对。
s5、获取测试数据集,采用图像超分辨率任务中常见的测试数据集set5、set14、urban100、bsd100、manga109和div2k验证集测试数据集;
本实施例中,采用六个标准的测试数据集进行图像超分辨率模型效果的验证。这个六个测试集是:set5、set14、bsd100、urban100、manga109和div2k的验证集(包含100张2k高分辨率图像)。set5、set14、bsd100是一些自然图像的集合;urban100是100张具有高频信息的城市图像的集合;manga109是109张日本漫画图像的集合;div2k包含多个场景。这些数据集被广泛地应用在各种各样的超分辨率模型验证上,具有极好的代表性和说服力。首先对数据集的高分辨率图像进行下采样操作得到对应的低分辨率图像。也可以获取生产生活中的需要进行放大的低分辨率图像作为测试的输入。
s6、在测试阶段,只需要使用生成网络模型来对低分辨率图像进行图像超分辨率处理,不需要判别网络模型;加载训练好的生成网络模型,将测试数据集输入到生成网络模型,生成超分辨率图像;
s7、计算生成的超分辨率图像与真实的高分辨率图像之间的峰值信噪比(psnr),计算生成图像的图像重建质量的评价指标,评估图像的重建质量。
采用根均方误差(rmse)和感知指数(pi)作为图像重建质量的评价指标,将图像转到ycbcr空间,在y通道上进行计算根均方误差或者峰值信噪比pnsr。
其中h、w为低分辨率图像的长度和宽度,r为放大因子,x为真实图像,
mse为均方误差,n为每像素的比特数,如8、16;在本实例中,psnr是在灰度图像的y通道上计算,灰度图像的像素取值范围为[0,255],因此n取8;psnr的单位是分贝(db),数值越大表示失真越小,重建质量越好;
其中ma(mac,yangcy,yangx,etal.learningano-referencequalitymetricforsingle-imagesuper-resolution[j].computervisionandimageunderstanding,2017,158:1-16)与niqe(mittala,fellow,ieee,etal.makinga'completelyblind'imagequalityanalyzer[j].ieeesignalprocessingletters,2013,20(3):209-212.)是两个无参考图像测量方式,用于感知质量评估;pi被用来作为2018pirmchallengeonperceptualimagesuper-resolution(blauy,mechrezr,timofter,etal.the2018pirmchallengeonperceptualimagesuper-resolution[a].ineuropeanconferenceoncomputervision[c],2018.7794-7803.)的评价指标之一;pi与人类对图像的主观评价有相关性,数值越小,在一定程度上反映了图像越具有感知质量,为了保证重建的超分辨率图像在内容上与真实的高分辨率图像相似,pi通常需要与mse结合来评价重建图像的质量。
图6和图8分别是本发明的fasrgan和fs-srgan与其他图像超分辨率方法的视觉效果对比图,本发明的两种方法均比其他图像超分辨率方法的重建效果更好。
图7和图9分别是本发明的fasrgan和fs-srgan的消融实验对比效果图,在生成对抗网络中分别加入本发明提出的细粒度注意力机制和特征共享机制都能提升模型的重建能力。
图10是更好重建精度(rmse)和更好的视觉感知质量(pi)的权衡图。从图中可以得出,本发明提出的fasrgan和fs-srgan,以及两者的结合都取得较好的权衡。图11是在训练过程中,随着训练步数的增长,本发明提出的fasrgan和fs-srgan,以及两者的结合的感知指数的变化曲线。由图可知,fs-srgan的训练过程更加稳定,而fasrgan的感知指数更低,重建性能更好。
上述实施例是本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!