一种基于实例分割的多人体姿态检测及状态判别方法与流程
本发明涉及机器学习及机器视觉的技术领域,具体涉及一种基于实例分割的多人体姿态检测及状态判别方法。
背景技术:
随着大数据和人工智能时代的到来,信息技术与学校教育教学的融合逐步成为探究的焦点。智慧课堂正是将先进的信息采集技术与传输技术、智能传感技术及计算机处理技术高校整合利用到教育领域的新兴概念。在教育教学过程中,学生的听课状态能够最有效的对于学生的学习程度和教师的授课情况进行反馈。而现有的教学反馈仍旧以人工分析和评估为主,耗时多,效率低且评估不全面。实例分割在检测目标的基础上还能够分割出目标物体的像素,并且可以对同一物体的不同个体进行标注。实例分割已经被广泛用于自动驾驶、医学检测、服装分类、精准农业等领域。随着人工智能的发展,实例分割也可以逐步应用到智慧课堂当中。
目前提出的学生听课状态识别分析的方法较少,主要以单一的人脸识别,人体姿态检测,或是脑电波监测等方法。这些方法都存在着不可避免的缺陷,准确率低,实时性不高,成本较高,受众体验感较差等。本发明为实现学生听课状态的判别与分析提供解决方法。以摄像头采集学生课堂情况,实现方式简便,成本较低,同时本发明可以实现实时识别,识别精度较高,能够在分割学生个体与课堂背景的基础上同时完成对于学生个体的人体姿态检测和课堂状态判别,可以输出学生个体不同听课状态的标签并以不同颜色的掩码对处于不同听课状态的学生个体进行分类。并且本发明提供了一种对于多人课堂效率分析的计算方法,可以在一个课堂时段检测结束后得出学生个体的听课效率,具有识别效率高、识别精度良好、抗复杂环境干扰性强等特点。
技术实现要素:
本发明的目的是提供一种实时性强、识别率高、抗背景环境干扰能力强的基于实例分割的多人体姿态检测及状态判别方法。
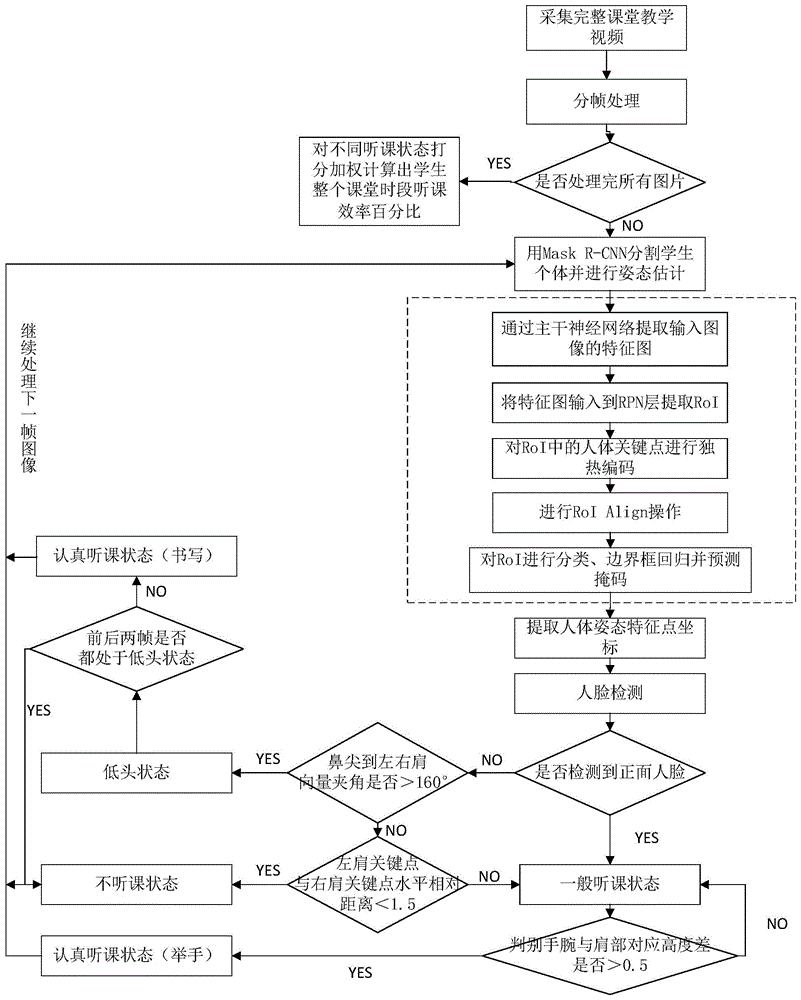
为实现上述目的,本发明采用了如下技术方案:所述的一种基于实例分割的多人体姿态检测及状态判别方法,包括以下步骤:
步骤1:以正面角度采集学生上课视频,每5秒提取一帧,对于采集的视频进行分帧处理,得到课堂视频的全部分帧图像;
步骤2:利用实例分割模型分割出课堂视频的全部原始分帧图像中的学生个体和非学生个体,以不同颜色的掩码标注不同学生个体,同时进行姿态检测,提取出各学生人体姿态的18个关键点,并进行标注连接,从而得到不同颜色掩码和人体关键点连接标注的课堂图像;
步骤3:利用dlib模型,检测出每个学生个体正面人脸所在位置;
步骤4:对学生的听课状态进行具体判别:如果能够检测到正面人脸则根据提取出的人体关键点坐标关系判断学生是处于一般听课状态还是举手状态;如果无法检测到学生正面人脸则根据提取出的人体坐标关键点角度判断学生是否处在低头或侧身交头接耳状态;
步骤5:根据步骤1~步骤4对课堂视频的全部原始分帧图像进行处理,得到标注学生个体姿态的全部标注分帧图像,同时输出学生课堂状态,对于不同课堂状态进行打分加权计算,得出各学生在整个课堂时段的听课效率百分比。
进一步地,所述步骤1包括:
步骤1.1:录制整个课堂时段的全体学生正面视频,并保存至计算机;
步骤1.2:对于存储的课堂时段全体学生正面视频进行分帧操作,设置每5秒提取一帧待处理图像,并将图像输出进行存储;
进一步地,所述步骤2包括:
步骤2.1:将步骤1得到的课堂视频的全部原始分帧图像输入到实例分割模型的主干神经网络中进行处理从而得到输入图片中的特征图,提取出的特征图将作为后续处理的输入;
步骤2.2:将步骤2.1得到的特征图输入到实例分割模型中的区域生成网络rpn层中,以滑动窗口扫描图像寻找存在目标的区域,从而得到感兴趣区域roi;
步骤2.3:对于每一个生成的感兴趣区域进行检测,当检测到感兴趣区域包含人这一种类时,会对人体身上每一个关键点的位置进行独热编码,对应人体每一关键点生成一个掩码;
步骤2.4:对rpn层的输出结果roi进行对齐操作,然后在特征图上提取每个roi对应的特征;
步骤2.5:将经过步骤2.3处理后的roi分别送入到实例分割模型中的一种基于快速区域的卷积网络fastr-cnn和全卷积神经网络fcn两个分支,fastr-cnn对roi进行姿态分类和边界框回归,全卷积神经网络fcn为每个roi生成掩码。
步骤2.6:对于学生个体的姿态关键点进行坐标提取,将提取出的坐标关键点信息以csv文件形式保存。
进一步地,所述步骤2.1包括:
所述主干神经网络包括残差网络resnet101和特征图金字塔网络fpn构成。
残差网络resnet101是由一个7*7*64的输入卷积,后经过33个残差块buildingblock,最后通过一个全连接层fc进行分类,由于每个残差块为3层,所以共有101层网络。每一残差块表示为:
xn+1=h(xn)+f(xn,wn)
其中xn+1为每一残差块的输出,xn为该残差块的输入,wn指卷积操作,f(xn,wn)表示残差部分,h(xn)=w’nxn表示直接映射部分,w’n是1×1卷积操作。
将残差网络resnet101分为5个阶段,对应得到特征图金字塔网络fpn网络中5个不同尺度的特征图输出。
进一步地,所述步骤2.2包括:
步骤2.2.1:区域生成网络rpn层通过滑动窗口为每个位置生成9种预先设定好长宽比和面积的目标框,目标框称为锚箱anchorbox。所述9种初始锚箱包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1∶1,1∶2,2∶1);
步骤2.2.2:对于生成的初始锚箱进行裁剪过滤后,区域生成网络rpn层通过softmax函数判断锚点属于前景还是背景,即是学生个体还是教室背景,此外还为属于前景的锚箱进行第一次坐标修正。
进一步地,所述步骤2.2.2包括:
softmax函数是用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,并且归一化保证和为1,从而使得多分类的概率之和也刚好为1。
softmax函数定义如下:
其中,vi是分类器前级输出单元的输出。i表示类别索引,c表示总的类别个数。si表示的是当前元素的指数与所有元素指数和的比值。通过这个softmax函数就可以将多分类的输出数值转化为相对概率。
softmax的损失函数loss多数为交叉熵形式:
其中ti表示真实值,yi表示softmax函数求出的值。
输入一个样本,只有一个神经元对应了该样本的正确类别;如果这个神经元输出的概率值越高,则按照以上的函数公式,其产生的损失就越小;反之,则产生的损失就越高。训练好的softmax函数可用于对特征图进行分类。
进一步地,所述步骤2.3包括:
独热编码为一位有效编码。人体姿态检测时,人本身作为一个目标实例进行分类检测,人体每个部位的关键点对应于一个独热编码,每一个人体标注18个关键点,关键点的标注方式参照coco数据集中人体关键点的标注方式。
进一步地,所述步骤2.4包括:
步骤2.4.1:使用已有的vgg16网络,选取卷积步长为32,则经过vgg16网络层后的感兴趣区域映射到特征图中的大小为原来的1/32,如果此时映射到特征图的大小为浮点数,则不进行取整操作,保留浮点数;
步骤2.4.2:设定经池化后固定成大小为7*7的特征图,特征图上经过映射后的大小为n*n,n表示特征图边长。将n*n大小的候选区域划分成49个大小相同的小区域,每个小区域的大小为(n/7)*(n/7);
步骤2.4.3:采样点数为4,即将每个(n/7)*(n/7)大小的小区域平分成四份,每一份取其中心点位置的像素,采用双线性插值法进行计算得到四个点的像素值;
步骤2.4.4:将小区域的像素值设定为经过双线性插值法计算得到的四个点像素值中的最大值,依次类推,将49个小区域所得到得49个像素值组成大小为7*7的特征图。
进一步地,所述步骤4包括:
步骤4.1:如果能检测到正面人脸,则根据提取出的人体姿态关键点信息进一步对于听课状态进行判别,通过判断δh的大小来判别学生个体是否处于举手状态,手腕与肩部关键点高度差δh计算公式为:
或是:
其中y左肩为左肩关键点位置的纵坐标,y右肩为右肩关键点位置的纵坐标,y左腕为左腕关键点位置的纵坐标,y右腕为右腕关键点位置的纵坐标,y鼻尖为鼻尖关键点位置的纵坐标,x鼻尖为鼻尖关键点位置的横坐标,x左肩为左肩关键点位置的横坐标,x右肩为右肩关键点位置的横坐标;
如果高度差δh大于0.5则判定学生个体处于认真听课状态(举手),否则判定学生处于一般听课状态。
步骤4.2:如果不能检测到正面人脸,则根据提取出的人体姿态关键点信息和前后两帧图像之间的关系进行进一步判别。
根据一般生活经验和实验统计,低头状态鼻尖位置处关键点到左肩和右肩点向量间的夹角在170°~200°区间内分布,非低头状态鼻尖点到左肩点和右肩点向量间的夹角在90°~120°区间内集中分布,选取160°为低头状态与非低头状态的分界。根据一般生活经验和实验统计,低头看书或是书写时都是短暂低头,如果是前一帧学生个体处于低头状态而其后一帧处于抬头状态,则将其记为认真听课状态(书写),否则根据一般生活经验判定学生为不听课状态。
如果鼻尖到左右肩向量夹角<160°,判别出人体不处于低头状态,则继续根据左肩关键点与右肩关键点间水平相对距离进一步判别学生个体的听课状态。根据一般生活经验和实验统计,侧身状态下左肩关键点与右肩关键点间水平相对距离小于1.5。计算左肩关键点与右肩关键点间水平相对距离δx的归一化标准公式:
其中x左肩为左肩关键点位置的横坐标,x右肩为右肩关键点位置的横坐标,y脖子为脖颈关键点位置的纵坐标,x脖子为脖颈关键点位置的横坐标,y鼻尖为鼻尖关键点位置的纵坐标,x鼻尖为鼻尖关键点位置的横坐标;
如果左右肩水平距离小于1.5,则判定学生为侧身交头接耳的不听课状态,否则判定学生个体处于一般听课状态。
进一步地,所述步骤5包括:
根据不同的听课状态进行打分加权计算出学生在整个课堂时段的听课效率百分比:
对于步骤4中判别出的处于听课状态的学生个体,如果学生处于一般听课状态每检测到一次打0.6分;
对于步骤4中判别出的处于听课状态的学生个体,如果学生处于书写状态每检测到一次打0.8分,如果处于举手状态每检测到一次打1分;
对于步骤4中判别出的处于走神或是交头接耳等不听课状态的学生个体,每检测到一次打0分;
最终每个学生个体的整个课堂时段的听课效率百分比p的计算公式为:
其中,r为学生个体处于举手状态的总帧数,1为学生处于书写状态的总帧数,s为学生个体处于一般听课状态的总帧数,n为得到课堂视频的连续帧图像总帧数。
由以上技术方案可知,本发明实施例提供一种多人体姿态检测及多人课堂状态判别分析方法,包括:步骤1:以正面角度采集学生上课视频,每5秒提取一帧,对于采集的视频进行分帧处理,得到课堂视频的全部原始分帧图像;步骤2:利用实例分割模型分割出课堂视频的全部原始分帧图像中的学生个体和非学生个体,以不同颜色的掩码标注不同学生个体,同时进行姿态检测,提取出各学生人体姿态的18个关键点,并进行标注连接,从而得到不同颜色掩码和人体关键点连接标注的课堂图像;步骤3:利用dlib模型,检测出每个学生个体正面人脸所在位置;步骤4:对学生的听课状态进行具体判别:如果能够检测到正面人脸则根据提取出的人体姿态关键点信息判断学生是处于一般听课状态还是举手状态;如果无法检测到学生正面人脸则根据提取出的人体姿态关键点信息判断学生是否处在低头或侧身交头接耳状态;步骤5:根据步骤1~步骤4对课堂视频的全部原始分帧图像进行处理,得到标注学生个体姿态的全部标注分帧图像,同时输出学生课堂状态,对于不同课堂状态进行打分加权计算,得出各学生在整个课堂时段的听课效率百分比。
通过上述技术方案的实施,本发明的有益效果是:(1)提供了视频分帧处理的方法,选取合适的时间间隔,能够大大提高检测效率;(2)提供了基于实例分割的多学生人体姿态检测及听课状态分析的方法,对于多人姿态进行了较为精确的检测,检测效率高,适用于复杂环境背景。(3)结合人脸检测,提出了一种人体姿态判别算法对人体姿态关键点之间的关系进行分析,从达到对学生多种具体听课状态的分析判别,从而对于学生听课效率达到较为准确的判断;(4)实现成本低,识别效率高,抗复杂环境干扰能力强。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
图1是本发明所述的一种基于实例分割的多人体姿态检测及状态判别方法的流程框图。图2是本发明所述的实例分割的主干神经网络。
图3是本发明所述的人体18个特征点对应序号及位置图。
图4是本发明所述的对学生进行人脸检测输出的结果图。
图5是本发明具体实施例中对学生进行人体姿态检测及关键点标注示意图。
图6是本发明具体实施例中对学生进行课堂状态判别的输出结果图。
具体实施方式
实施例
在本实施例中,以每5秒一帧,提取100帧图像的听课实验视频为例,对完整课堂时段中学生个体检测及听课状态自主识别方法进行说明;
参照图1,为本发明实施例提供的一种基于实例分割的多人体姿态检测及状态判别方法,包括以下步骤:
步骤1:以正面角度采集学生上课视频,每5秒提取一帧,对于采集的视频进行分帧处理,得到课堂视频的全部原始分帧图像;
步骤2:利用实例分割模型【可参考郑健红,鲍官军,张立彬,荀一,陈教料.结合深度学习与支持向量机的金属零件识别[j].中国图象图形学报,2019,24(12):2233-2242.】分割出课堂视频的全部原始分帧图像中的学生个体和非学生个体,以不同颜色的掩码标注不同学生个体,同时进行姿态检测,提取出各学生人体姿态的18个关键点,并进行标注连接,从而得到不同颜色掩码和人体关键点连接标注的课堂图像;
步骤3:利用dlib模型【可参考陈美玲.安检过程中人脸识别技术的关键算法研究[d].辽宁工业大学,2019.】,检测出每个学生个体正面人脸所在位置。
步骤4:对学生的听课状态进行具体判别:如果能够检测到正面人脸则根据提取出的人体关键点坐标关系判断学生是处于一般听课状态还是举手状态;如果无法检测到学生正面人脸则根据提取出的人体坐标关键点角度判断学生是否处在低头或侧身交头接耳状态;
步骤5:根据步骤1~步骤4对课堂视频的全部原始分帧图像进行处理,得到标注学生个体姿态的全部标注分帧图像,同时输出学生课堂状态,对于不同课堂状态进行打分加权计算,得出各学生在整个课堂时段的听课效率百分比。
下面结合附图和具体实施例对本发明作进一步说明。
在本发明实施例中,采用的是一种基于实例分割的多人体姿态检测及状态判别分析方法,其中实例分割主干神经网络结构图如图2所示。
在本发明实施例中,所述步骤1包括:
步骤1.1:录制整个课堂时段的全体学生正面视频,将所录制的视频保存至计算机;
步骤1.2:对于存储的课堂时段全体学生正面视频进行分帧操作,设置每5秒提取一帧待处理图像,并将图像输出进行存储;
在本发明实施例中,所述步骤2包括:
步骤2.1:将步骤1得到的课堂视频的全部原始分帧图像输入到实例分割模型的主干神经网络中进行处理从而得到输入图片中的特征图,提取出的特征图将作为后续处理的输入;
步骤2.2:将步骤2.1得到的特征图输入到实例分割模型中的区域生成网络rpn【可参考王文,周晨轶,徐亦白,卢杉,周梦兰.一种采用级联rpn的多尺度特征融合电表箱锈斑检测算法[j].计算机与现代化,2020(01):117-121.】层中,以滑动窗口扫描图像寻找存在目标的区域,从而得到感兴趣区域roi;
步骤2.3:对于每一个生成的感兴趣区域进行检测,当检测到感兴趣区域包含人这一种类时,会对人体身上每一个关键点的位置进行独热编码。对应人体每一关键点生成一个掩码;
步骤2.4:对rpn层的输出结果roi进行对齐操作,然后在特征图上提取每个roi对应的特征;
步骤2.5:将经过步骤2.3处理后的roi分别送入到实例分割模型中的一种基于快速区域的卷积网络fastr-cnn【可参考曹诗雨,刘跃虎,李辛昭.基于fastr-cnn的车辆目标检测[j].中国图象图形学报,2017,22(05):671-677.】和全卷积神经网络fcn【可参考翁健.基于全卷积神经网络的全向场景分割研究与算法实现[d].山东大学,2017.】两个分支,fastr-cnn对roi进行姿态分类和边界框回归,fcn为每个roi生成掩码
步骤2.6:对于学生个体的姿态关键点进行坐标提取,将提取出的坐标关键点信息以csv文件形式保存;。
在本发明实施例中,所述步骤2.1包括:
主干神经网络由resnet101【可参考齐永锋,马中玉.基于深度残差网络的多损失头部姿态估计[j/ol].计算机工程:1-8[2020-03-18].】和特征图金字塔网络fpn(featurepyramidnetworks)【可参考刘云,钱美伊,李辉,王传旭.深度学习的多尺度多人目标检测方法研究[j/ol].计算机工程与应用:1-10[2020-03-16].】构成。
resnet101这一残差网络是由一个7*7*64的输入卷积,后经过33个残差块(buildingblock),最后通过一个全连接层(fullyconnectedlayers,简称为fc)进行分类,由每个残差块为3层,所以共有101层网络。每一残差块可以表示为:
xn+1=h(xn)+f(xn,wn)
其中xn+1为每一残差块的输出,xn为该残差块的输入,wn指卷积操作,f(xn,wn)表示残差部分,h(xn)=w’nxn表示直接映射部分,w’n是1×1卷积操作。
将resnet101网络分为5个阶段,对应得到fpn网络中5个不同尺度的特征图输出。
在本发明实施例中,所述步骤2.2包括:
步骤2.2.1:rpn通过滑动窗口为每个位置生成9种预先设定好长宽比和面积的目标框,又称之为锚箱anchorbox。这9种初始锚箱包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1∶1,1∶2,2∶1);
步骤2.2.2:对于生成的初始锚箱进行裁剪过滤后,rpn通过softmax函数【可参考江白华.基于深度学习的人脸识别研究[d].安徽理工大学,2019.】判断锚点属于前景还是背景,即是学生个体还是教室背景,此外还为属于前景的锚箱进行第一次坐标修正。
在本发明实施例中,所述步骤2.3包括:
独热编码为一位有效编码。人体姿态检测时,人本身可以作为一个目标实例进行分类检测,人体每个部位的关键点对应于一个独热编码【可参考梁杰,陈嘉豪,张雪芹,周悦,林家骏.基于独热编码和卷积神经网络的异常检测[j].清华大学学报(自然科学版),2019,59(07):523-529.】,每一个人体标注18个关键点,关键点的标注方式参照coco数据集【一个大型的、丰富的物体检测,分割和字幕数据集,其处理方式可参考张相怡.面向场景理解的细粒度图像分割算法研究[d].北京交通大学,2019.】中人体关键点的标注方式。如图3所示,标号从0-17依次为:鼻尖、脖子、右肩、右肘、右腕、左肩、左肘、左腕、右胯、右膝盖、右脚踝、左胯、左膝盖、左脚踝、右眼、左眼、右耳和左耳。
在本发明实施例中,所述步骤2.4包括:
步骤2.4.1:使用已有的vgg16网络【可参考冯国徽.基于卷积神经网络vgg模型的小规模图像分类[d].兰州大学,2018.】,选取卷积步长为32,则经过vgg16网络层后的感兴趣区域映射到特征图中的大小为原来的1/32,如果此时映射到特征图的大小为浮点数,则不进行取整操作,保留浮点数;
步骤2.4.2:假设经池化后固定成大小为7*7的特征图,假设特征图上经过映射后的大小为n*n,n表示特征图边长。将n*n大小的候选区域划分成49个大小相同的小区域,每个小区域的大小为(n/7)*(n/7);
步骤2.4.3:假定采样点数为4,即将每个(n/7)*(n/7)大小的小区域平分成四份,每一份取其中心点位置的像素,采用双线性插值法【可参考邹学瑜,刘昌禄,胡敬营.基于双线性插值算法的缩放ip核设计[j].计算技术与自动化,2017,36(01):113-117.】进行计算得到四个点的像素值;
步骤2.4.4:将小区域的像素值设定为经过双线性插值法计算得到的四个点像素值中的最大值,依次类推,将49个小区域所得到得49个像素值组成大小为7*7的特征图。
在本发明实施例中,所述步骤4包括:
步骤4.1:通过步骤3对学生个体进行人脸检测输出的结果如图4所示。若能检测到正面人脸则根据提取出的人体姿态关键点信息进一步对于听课状态进行判别。通过步骤2检测出的人体姿态及关键点标注图如图5所示。通过判断δh的大小来判别学生个体是否处于举手状态,手腕与肩部关键点高度差δh计算公式为:
或是:
其中y左肩为左肩关键点位置的纵坐标,y右肩为右肩关键点位置的纵坐标,y左腕为左腕关键点位置的纵坐标,y右腕为右腕关键点位置的纵坐标,y鼻尖为鼻尖关键点位置的纵坐标,x鼻尖为鼻尖关键点位置的横坐标,x左肩为左肩关键点位置的横坐标,x右肩为右肩关键点位置的横坐标;
如果手腕与肩部关键点高度差δh大于0.5则判定学生个体处于认真听课状态(举手),否则判定学生处于一般听课状态。
步骤4.2:若不能检测到正面人脸,则根据提取出的人体姿态关键点信息和前后两帧图像之间的关系进行进一步判别。
根据一般生活经验和实验统计,低头状态鼻尖位置处关键点到左肩和右肩点向量间的夹角在170°~200°区间内分布,非低头状态鼻尖点到左肩点和右肩点向量间的夹角在90°~120°区间内集中分布,选取160°为低头状态与非低头状态的分界。
根据一般生活经验和实验统计,低头看书或是书写时都是短暂低头,如果是前一帧学生个体处于低头状态而其后一帧处于抬头状态,则将其记为认真听课状态(书写),否则根据一般生活经验判定学生为不听课状态。
若鼻尖到左右肩向量夹角<160°,判别出人体不处于低头状态,则继续根据左肩关键点与右肩关键点间水平相对距离进一步判别学生个体的听课状态。根据一般生活经验和实验统计,侧身状态下左肩关键点与右肩关键点间水平相对距离小于1.5。计算左肩关键点与右肩关键点间水平相对距离δx的归一化标准公式:
其中x左肩为左肩关键点位置的横坐标,x右肩为右肩关键点位置的横坐标,y脖子为脖颈关键点位置的纵坐标,x脖子为脖颈关键点位置的横坐标,y鼻尖为鼻尖关键点位置的纵坐标,x鼻尖为鼻尖关键点位置的横坐标;
若左右肩水平距离小于1.5,则判定学生为侧身交头接耳的不听课状态,否则认定学生个体处于一般听课状态。
如图6中所示,检测到了学生课堂的三种课堂状态,以“talking”标注侧身交头接耳的学生个体,以“listening”标注处于一般听课状态的同学,以“absent-minded”标注低头走神的同学,举手状态与低头书写状态分别以“raise-hand”和“writing”标注,因图6中并未检测到,所以不予显示。同时不同的听课状态以不同颜色的掩码加以区分。
在本发明实施例中,所述步骤5包括:
根据不同的听课状态进行打分加权计算出学生在整个课堂时段的听课效率百分比:
对于步骤4中判别出的处于听课状态的学生个体,如果学生处于一般听课状态每检测到一次打0.6分;
对于步骤4中判别出的处于听课状态的学生个体,如果学生处于书写状态每检测到一次打0.8分,如果处于举手状态每检测到一次打1分;
对于步骤4中判别出的处于走神或是交头接耳等不听课状态的学生个体,每检测到一次打0分;
最终每个学生个体的整个课堂时段的听课效率百分比p的计算公式为:
其中,r为学生个体处于举手状态的总帧数,l为学生处于书写状态的总帧数,s为学生个体处于一般听课状态的总帧数,n为得到课堂视频的连续帧图像总帧数。
本发明提供了一种基于实例分割的多人体姿态检测及状态判别方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出如果干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!