一种大数据预分析的方法及装置与流程
本发明涉及大数据采集预分析领域,具体涉及一种大数据预分析的方法及装置。
背景技术:
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产,一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征,面对海量的数据,在前期需要将获取的大数据进行处理预分析,以便快速得到大数据的分析结果。
技术实现要素:
本发明的目的在于提供一种大数据预分析的方法及装置,通过对获取海量的样本数据进行训练分析,可以得到海量样本数据之间的关系得到数据分析模型,通过预设的数据结构对样本数据进行初期分析,得到样本数据集,有利于提高后期对样本数据集的训练分析,将样本数据集进行异常值识别并处理,得到过滤数据集,可以有效消除异常值对构建数据分析模型的影响,提高数据分析模型中数据关系的平稳性,进一步地对过滤数据集进行聚类得到标准数据集可以提高模型的训练速度,对标准数据集进行训练分析,得到标准数据集的数据分析模型,通过数据分析模型达到对大数据预分析的目的,有效提高对大数据分析的效率,解决了现有技术方案中对大数据预分析效率低的问题;
本发明对样本数据集进行异常值识别并处理时,通过均值计算公式对样本数据集中数据进行均值计算,得到样本数据集中数据的样本平均值,利用公式对样本数据集进行样本标准差计算得到样本数据集的样本标准差,继续利用公式对样本数据集进行检验统计量进行计算,得到样本数据集的检验统计量,根据检验统计量计算得到检验临界值,通过检验临界值对样本数据集检验计算得到的结果进行判断,可以有效提取样本数据集中的异常值,通过公式对异常值进行计算判断,得到高度异常值或者低度异常值,并做进一步的处理,达到对样本数据集中异常值的识别和处理,有效提高样本数据集中样本数据的准确性和平稳性,为数据分析模型的构建提供了有效的数据,解决了现有技术方案中样本数据集中样本数据不可靠导致模型分析的结果误差大的问题。
本发明的目的可以通过以下技术方案实现:
一种大数据预分析的方法,所述方法包括:
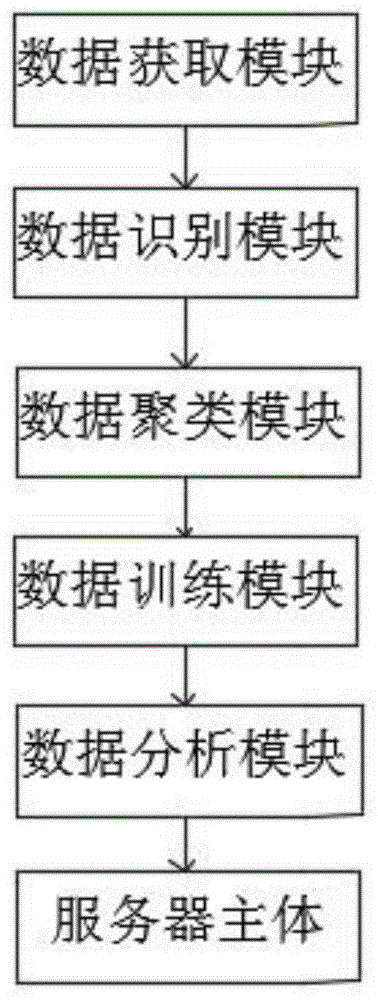
步骤一:数据获取模块获取样本数据,根据预设的数据结构将所述样本数据建立样本数据集并存储至服务器主体中;
步骤二:数据识别模块对所述样本数据集进行异常值识别并处理,生成过滤数据集;
步骤三:数据聚类模块对所述过滤数据集进行聚类,得到标准数据集;
步骤四:数据训练模块将所述标准数据集进行训练分析,得到所述标准数据集的数据分析模型;
步骤五:数据分析模块获取待分析数据,将所述待分析数据通过所述数据分析模型进行分析,得到分析结果,通过所述服务器主体将所述结果转发给用户的显示设备。
优选的,所述对所述样本数据集进行异常值识别并处理,生成过滤数据集的具体步骤包括:
步骤一:利用公式
步骤二:利用公式
步骤三:利用公式
步骤四:根据所述检验统计量确定检验水平,通过公式b1=g1-α(k)计算得到检验临界值;其中,α表示预设检验水平系数,k表示所述检验水平系数对应的检验值;
步骤五:通过所述检验临界值对所述样本数据集的检验统计量进行判断,当gn>b1时,则判断xn为异常值;否则判断无异常值;
步骤六:利用公式b2=g1-α'(n)计算得到所述异常值的删除水平值;其中,α'(n)表示异常值的删除系数,当gn>b2时,则判断xn为高度异常值;否则判断xn为低度异常值;
步骤七:对所述高度异常值进行删除,将所述低度异常值进行均值计算,得到低度均值,将所述低度均值替换所述低度异常值,并存储至所述样本数据集。
优选的,所述对所述过滤数据集进行聚类,得到标准数据集的具体计算步骤如下:
步骤一:随机选择所述过滤数据集中k个样本作为k个中心点;
步骤二:利用公式c=min||xi-uk||2计算所述过滤数据集中的样本数据与k个所述中心的距离最小值;其中,xi表示所述过滤数据集中的样本数据,uk表示第k个中心点;
步骤三:根据所述样本数据与k个所述中心点的距离最小值,将所述样本数据归类至所述中心点,通过对所述过滤数据集中的样本数据进行迭代,直至所述过滤数据集中的所有所述样本数据均归类至k个所述中心点;
步骤四:获取k个所述中心点中所述样本数据的对象属性,将所述对象属性进行整合,并将整合后的所述对象属性作为指标组合样本类的属性,并在所述指标组合样本类的属性中添加设置方法和获取方法,得到k个指标组合样本类;
步骤五:将k个所述指标组合样本类中的数据进行归一化处理,得到划分为不同的指标组合的标准数据集。
优选的,所述将所述标准数据集进行训练分析,得到所述标准数据集的数据分析模型的具体步骤如下:
s1:利用线性回归函数
s2:将所述拟合数据集映射至所述线性回归函数,生成分析函数;
s3:对所述分析函数进行对数推导,得到似然函数;
s4:利用预设定的特征条件,获取所述标准数据集中的数据特征和拟合数据集中的数据特征;
s5:将所述标准数据集中的数据特征和所述拟合数据集中的数据特征进行对比判断;
s6:若所述标准数据集中的数据特征和所述拟合数据集中的数据特征之间的差异大于或等于预设的阈值,则调整所述线性回归函数中预设定的参数后,对所述标准数据集继续进行拟合计算;
s7:若所述标准数据集中的数据特征和所述拟合数据集中的数据特征之间的差异小于预设的阈值,将所述似然函数和所述线性回归函数进行组合,得到训练分析完成的数据分析模型。
一种大数据预分析的装置,包括数据获取模块、数据识别模块、数据聚类模块、数据训练模块、数据分析模块和服务器主体,所述数据获取模块用户获取海量的样本数据,所述数据识别模块用于对所述过滤数据集进行聚类,所述数据训练模块将所述标准数据集进行训练分析,所述数据分析模块对待分析数据进行分析输出分析结果,所述服务器主体的内部固定安装有腔体,所述腔体的内表面固定安装有第一固定柱和第二固定柱,所述第一固定柱位于第二固定柱的一侧,所述第一固定柱和第二固定柱之间设置有若干个连接块,所述腔体的内部设置有若干个防护块,所述防护块的内表面固定连接有插块,所述插块的内部设置有若干个插口,若干个所述插口呈等间距排列,所述防护块的内部固定安装有防护板,所述防护板与防护块之间设置有卡槽,所述防护块的内表面固定安装有第一凸块,所述防护板的外表面固定安装有第二凸块,所述防护板的内部固定安装有卡块,所述卡块的内部设置有若干个隔离块,所述卡块的内表面活动连接有转柱,所述转柱的外表面活动连接有隔离板。
本发明的有益效果为:
1、本发明通过对获取海量的样本数据进行训练分析,可以得到海量样本数据之间的关系得到数据分析模型,通过预设的数据结构对样本数据进行初期分析,得到样本数据集,有利于提高后期对样本数据集的训练分析,将样本数据集进行异常值识别并处理,得到过滤数据集,可以有效消除异常值对构建数据分析模型的影响,提高数据分析模型中数据关系的平稳性,进一步地对过滤数据集进行聚类得到标准数据集可以提高模型的训练速度,对标准数据集进行训练分析,得到标准数据集的数据分析模型,通过数据分析模型达到对大数据预分析的目的,有效提高对大数据分析的效率;
2、本发明对样本数据集进行异常值识别并处理时,通过均值计算公式对样本数据集中数据进行均值计算,得到样本数据集中数据的样本平均值,利用公式对样本数据集进行样本标准差计算得到样本数据集的样本标准差,继续利用公式对样本数据集进行检验统计量进行计算,得到样本数据集的检验统计量,根据检验统计量计算得到检验临界值,通过检验临界值对样本数据集检验计算得到的结果进行判断,可以有效提取样本数据集中的异常值,通过公式对异常值进行计算判断,得到高度异常值或者低度异常值,并做进一步的处理,达到对样本数据集中异常值的识别和处理,有效提高样本数据集中样本数据的准确性和平稳性,为数据分析模型的构建提供了有效的数据,提高了数据分析模型对大数据分析的准确性。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明一种大数据预分析的方法的整体结构原理框图;
图2为本发明一种大数据预分析的装置整体结构图;
图3为本发明中防护块的结构图。
图中:1、服务器主体;2、腔体;3、第一固定柱;4、第二固定柱;5、连接块;6、防护块;7、插块;8、插口;9、防护板;10、第一凸块;11、第二凸块;12、卡槽;13、卡块;14、隔离块;15、隔离板;16、转柱。
具体实施方式
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1-3所示,一种大数据预分析的方法,所述方法包括:
步骤一:数据获取模块获取样本数据,根据预设的数据结构将所述样本数据建立样本数据集并存储至服务器主体1中;
步骤二:数据识别模块对所述样本数据集进行异常值识别并处理,生成过滤数据集;
步骤三:数据聚类模块对所述过滤数据集进行聚类,得到标准数据集;
步骤四:数据训练模块将所述标准数据集进行训练分析,得到所述标准数据集的数据分析模型;
步骤五:数据分析模块获取待分析数据,将所述待分析数据通过所述数据分析模型进行分析,得到分析结果,通过所述服务器主体1将所述结果转发给用户的显示设备。
所述对所述样本数据集进行异常值识别并处理,生成过滤数据集的具体步骤包括:
步骤一:利用公式
步骤二:利用公式
步骤三:利用公式
步骤四:根据所述检验统计量确定检验水平,通过公式b1=g1-α(k)计算得到检验临界值;其中,α表示预设检验水平系数,k表示所述检验水平系数对应的检验值;
步骤五:通过所述检验临界值对所述样本数据集的检验统计量进行判断,当gn>b1时,则判断xn为异常值;否则判断无异常值;
步骤六:利用公式b2=g1-α'(n)计算得到所述异常值的删除水平值;其中,α'(n)表示异常值的删除系数,当gn>b2时,则判断xn为高度异常值;否则判断xn为低度异常值;
步骤七:对所述高度异常值进行删除,将所述低度异常值进行均值计算,得到低度均值,将所述低度均值替换所述低度异常值,并存储至所述样本数据集。
所述对所述过滤数据集进行聚类,得到标准数据集的具体计算步骤如下:
步骤一:随机选择所述过滤数据集中k个样本作为k个中心点;
步骤二:利用公式c=min||xi-uk||2计算所述过滤数据集中的样本数据与k个所述中心的距离最小值;其中,xi表示所述过滤数据集中的样本数据,uk表示第k个中心点;
步骤三:根据所述样本数据与k个所述中心点的距离最小值,将所述样本数据归类至所述中心点,通过对所述过滤数据集中的样本数据进行迭代,直至所述过滤数据集中的所有所述样本数据均归类至k个所述中心点;
步骤四:获取k个所述中心点中所述样本数据的对象属性,将所述对象属性进行整合,并将整合后的所述对象属性作为指标组合样本类的属性,并在所述指标组合样本类的属性中添加设置方法和获取方法,得到k个指标组合样本类;
步骤五:将k个所述指标组合样本类中的数据进行归一化处理,得到划分为不同的指标组合的标准数据集。
所述将所述标准数据集进行训练分析,得到所述标准数据集的数据分析模型的具体步骤如下:
s1:利用线性回归函数
s2:将所述拟合数据集映射至所述线性回归函数,生成分析函数;
s3:对所述分析函数进行对数推导,得到似然函数;
s4:利用预设定的特征条件,获取所述标准数据集中的数据特征和拟合数据集中的数据特征;
s5:将所述标准数据集中的数据特征和所述拟合数据集中的数据特征进行对比判断;
s6:若所述标准数据集中的数据特征和所述拟合数据集中的数据特征之间的差异大于或等于预设的阈值,则调整所述线性回归函数中预设定的参数后,对所述标准数据集继续进行拟合计算;
s7:若所述标准数据集中的数据特征和所述拟合数据集中的数据特征之间的差异小于预设的阈值,将所述似然函数和所述线性回归函数进行组合,得到训练分析完成的数据分析模型。
一种大数据预分析的装置,包括数据获取模块、数据识别模块、数据聚类模块、数据训练模块、数据分析模块和服务器主体1,所述数据获取模块用户获取海量的样本数据,所述数据识别模块用于对所述过滤数据集进行聚类,所述数据训练模块将所述标准数据集进行训练分析,所述数据分析模块对待分析数据进行分析输出分析结果,所述服务器主体1的内部固定安装有腔体2,所述腔体2的内表面固定安装有第一固定柱3和第二固定柱4,所述第一固定柱3位于第二固定柱4的一侧,所述第一固定柱3和第二固定柱4之间设置有若干个连接块5,所述腔体2的内部设置有若干个防护块6,所述防护块6的内表面固定连接有插块7,所述插块7的内部设置有若干个插口8,若干个所述插口8呈等间距排列,所述防护块6的内部固定安装有防护板9,所述防护板9与防护块6之间设置有卡槽12,所述防护块6的内表面固定安装有第一凸块10,所述防护板9的外表面固定安装有第二凸块11,所述防护板9的内部固定安装有卡块13,所述卡块13的内部设置有若干个隔离块14,所述卡块13的内表面活动连接有转柱16,所述转柱16的外表面活动连接有隔离板15。
本发明的工作原理为:
获取海量的样本数据,根据预设的数据结构将所述样本数据建立样本数据集;对所述样本数据集进行异常值识别并处理,利用公式
将所述标准数据集进行训练分析,利用线性回归函数
本发明中的装置包括包括数据获取模块、数据识别模块、数据聚类模块、数据训练模块、数据分析模块和服务器主体1,通过获取海量的样本数据,将海量的样本数据和样本数据训练分析得到的数据关系存储至服务器主体1中,将插块7的外表面活动安装有防护块6,通过防护块6内部设置的第一凸块10、第二凸块11和卡槽12固定在插块7上,通过设置的隔离板15和转柱16的配合使用,将缆线穿过隔离板15与插块7上的插口8进行连接,隔离板15和转柱16对插块7上的若干个插口8起到防护隔离的作用;
通过对获取海量的样本数据进行训练分析,可以得到海量样本数据之间的关系得到数据分析模型,通过预设的数据结构对样本数据进行初期分析,得到样本数据集,有利于提高后期对样本数据集的训练分析,将样本数据集进行异常值识别并处理,得到过滤数据集,可以有效消除异常值对构建数据分析模型的影响,提高数据分析模型中数据关系的平稳性,进一步地对过滤数据集进行聚类得到标准数据集可以提高模型的训练速度,对标准数据集进行训练分析,得到标准数据集的数据分析模型,通过数据分析模型达到对大数据预分析的目的,有效提高对大数据分析的效率;
通过对样本数据集进行异常值识别并处理时,通过均值计算公式对样本数据集中数据进行均值计算,得到样本数据集中数据的样本平均值,利用公式对样本数据集进行样本标准差计算得到样本数据集的样本标准差,继续利用公式对样本数据集进行检验统计量进行计算,得到样本数据集的检验统计量,根据检验统计量计算得到检验临界值,通过检验临界值对样本数据集检验计算得到的结果进行判断,可以有效提取样本数据集中的异常值,通过公式对异常值进行计算判断,得到高度异常值或者低度异常值,并做进一步的处理,达到对样本数据集中异常值的识别和处理,有效提高样本数据集中样本数据的准确性和平稳性,为数据分析模型的构建提供了有效的数据,提高了数据分析模型对大数据分析的准确性。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!