一种基于加权支持向量机的水声目标识别方法与流程
本发明属于水声目标识别技术领域,特别是涉及一种基于加权支持向量机的水声目标识别方法。
背景技术:
随着声纳技术、信号检测与估计、计算机处理等技术的进步,水声目标识别技术已经发展成为一门具有独立体系的学科。该研究从目标特性分析、目标特征提取和目标识别分类器选择与设计三个方向出发,探究水下目标的分类识别问题。随着现代水声信号处理技术的发展,各类分类器不断被应用至水声目标识别系统中,使得水下目标识别技术向着智能化、自主化的趋势得到飞跃的发展。目前应用在水声目标识别问题中的决策分类方法主要有以下四种:1.遗传算法,通过模拟生物进化过程中的基因遗传和突变原理,寻找最优种群结构的智能优化算法。2.神经网络方法,模拟人脑处理运算方式,以神经元为基点建立非线性网络,能自主的进行学习训练,自适应调节分类网络结构实现对样本的分类预测。3.模糊识别方法,利用模糊集理论中最大隶属度原则或临近原则对样本类别进行判决。4.统计学习分类方法,通过对大量样本的统计分析,获取不同类别目标统计分布特征之间的差异,对测试集样本的统计分布特征进行距离度量,实现类别模式之间的匹配。
然而,水声目标工况多变、海洋环境信道复杂以及样本数据难以获取等因素为水声目标识别带来了极大的挑战。由于神经网络是基于机器学习的经验风险最小化准则,在训练样本数目不足时可能引起“过学习”或“欠学习”问题,严重影响分类性能。而模糊识别方法主要依靠人的主观因素,不具有自主学习能力,不适用于复杂分类系统。基于统计学习的支持向量机分类器利用结构风险最小化准则解决了小样本、非线性的分类问题,有效的避免了样本有限、维度灾难、过学习以及局部最小值等问题,在水声目标识别中有重要的应用价值。
技术实现要素:
本发明目的是为了解决由水声目标工况多变、海洋环境信道复杂以及样本数据难以获取等因素引起的目标分类器鲁棒性不强、识别效率低的问题,提出了一种基于加权支持向量机的水声目标识别方法。
本发明是通过以下技术方案实现的,本发明提出一种基于加权支持向量机的水声目标识别方法,具体包括以下步骤:
步骤一:对获取的n类水声目标样本数据,进行分帧预处理;其中n大于等于2;
步骤二:根据步骤一得到的预处理样本,利用谱分析特征提取方法获得各类样本的特征向量,作为分类器特征样本库;
步骤三:将水声目标特征样本两两组合生成
步骤四:根据步骤三中生成的二元目标分类对,分别设定加权支持向量机识别模型的核函数参数及惩罚因子参选范围,选择各类目标40%的特征样本作为参选训练数据,以k折交叉验证方法作为分类器识别性能评价标准,设置步长,利用网格搜索法寻找最优核函数参数及惩罚因子;
步骤五:根据步骤四中获得的最优核函数参数及惩罚因子,选取各类目标70%的特征样本输入到对应的加权支持向量机识别模型进行训练,所述各类目标70%的特征样本中包含步骤四中的参选训练数据;
步骤六:根据步骤五中获得训练完成的二元水声目标识别分类器,令未参加训练的30%特征样本数据作为测试样本,同时输入到
步骤七:统计分类器的识别正确率,评价分类器性能,当识别正确率低于设定阈值时,返回步骤四,提高参选样本数量,重新选择模型参数。
进一步地,在步骤一中,对水声目标样本数据进行分帧,也就是将信号样本分割成一段一段的帧序列,分帧之后,每一帧的长度称为“帧长”,帧序列的数目称为“帧数”,以每一帧数据作为一个样本。
进一步地,在步骤二中,根据步骤一中获得的预处理样本,对每一帧样本数据进行谱分析提取特征,提取的特征包括:
利用lofar谱分析获得水声目标信号的频域线谱特征;
利用demon谱分析获得水声目标信号调制谱的基频特征;
利用高阶谱分析抑制水声目标信号中的高斯噪声,获得信号中非线性耦合特征;
利用小波变换分析获得水声目标信号中的能量尺度变化特征;
将谱分析获得的特征值重组降维,归一化处理后,获得的特征向量称之为水声目标的特征样本,建立分类器特征样本库。
进一步地,所述步骤三具体为:
当特征样本库中目标个数n>2时,对应的训练样本集为{x1,x2,...,xn};将样本集中按样本类别两两组成训练样本集,即训练样本集ti-j(xi,xj)满足(i,j)∈{(i,j)|i>j,i,j=1,2,...,n};将标号为i的训练样本标记为正类点,标号为j的样本标记为负类点,形成
假设训练样本数据集
对于分类样本而言,存在部分样本线性不可分情况,即无法满足条件找到最优分类超平面,故式(1)中引入惩罚因子c和松弛变量ξ来降低yi[(w·xi)+b]≥1的约束;
支持向量机识别模型的最优分类超平面是依靠支持向量的位置确定的,与非支持向量无关,将分布在间隔面与超平面之间以及超平面一侧的支持向量称为边界支持向量,则类别中边界支持向量的比例越大样本被错分的比例也越大;从概率论的角度分类标号为-1的边界支持向量与标号为+1的边界支持向量出现的概率相同,如果正类样本数与负类样本数不相等,则表现为训练样本数少的类别边界支持向量比例大于训练样本数多的类别事件发生的概率大,即样本数少的类别中被错分的比例更大,因此引入对类别加权方法,将原始凸二次规划问题转化为:
式中:
其中,α表示拉格朗日乘子;i=1,2,...,n;j=1,2,...,n;
决策函数为:
选择高斯径向基核函数作为内积函数,所述内积函数表达式为:
其中σ表示高斯径向基核函数参数。
进一步地,所述网格搜索法寻找最优核函数参数及惩罚因子,具体为:
步骤1、首先根据经验确定惩罚因子c以及核函数参数σ的搜索范围;
步骤2、其次选择适合的步长,建立搜索网格(c,σ);
步骤3、基于每一个网格上的参数点训练加权支持向量机识别模型,以k折交叉验证的结果作为该参数点下分类器的识别精度;
步骤4、遍历全部网格后,选择使加权支持向量机识别模型对测试样本识别精度最高的参数。
进一步地,在步骤五中,选择各类目标70%的特征样本作为训练样本,分别对
进一步地,在步骤六中,将剩余30%的特征样本作为测试样本,同时输入到
对于输入样本x,建立用于表决判别意见的判别函数:
遍历所有的训练样本集获得
进一步地,在步骤七中,将混淆矩阵中分类正确的样本数占总样本数的比例称为识别正确率,作为识别评价标准;所述阈值取值为80%。
本发明的有益效果为:
(1)相比于机器学习方法,本发明方法避免了因数据不足引起的过拟合问题,能够有效地应对水声目标样本数据难以获取的问题。
(2)相比于原始支持向量机方法,本发明利用类别加权系数,有效的提高了识别目标样本数据不均衡条件下的正确识别率,在水声目标识别领域有重要的应用价值。
(3)本发明针对水声目标特性,选取合适的特征提取方法,具备自主挑选模型参数的能力,对水声目标的正确识别率在80%以上,分类器的稳定性高于现有分类方法。
附图说明
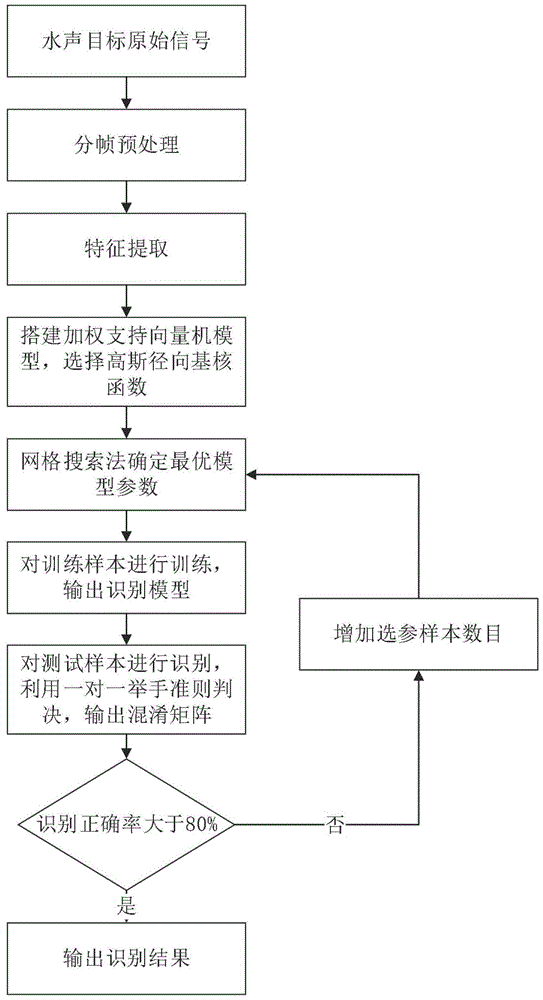
图1是基于加权支持向量机的水声目标识别方法流程图。
图2是加权支持向量机基本原理图。
图3是二元加权支持向量机识别混淆矩阵。
图4是多目标识别问题中一对一举手投票准则的基本示意图。
图5是四元加权支持向量机识别混淆矩阵。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
结合图1,本发明提出一种基于加权支持向量机的水声目标识别方法,具体包括以下步骤:
步骤一:对获取的n类水声目标样本数据,进行分帧预处理;其中n大于等于2;
在步骤一中,对水声目标样本数据进行分帧,也就是将信号样本分割成一段一段的帧序列,一般称这种处理方法为分帧处理,分帧之后,每一帧的长度称为“帧长”,帧序列的数目称为“帧数”,以每一帧数据作为一个样本。
步骤二:根据步骤一得到的预处理样本,利用谱分析特征提取方法获得各类样本的特征向量,作为分类器特征样本库;
在步骤二中,根据步骤一中获得的预处理样本,对每一帧样本数据进行谱分析提取特征,提取的特征包括:
利用lofar谱分析获得水声目标信号的频域线谱特征;
利用demon谱分析获得水声目标信号调制谱的基频特征;
利用高阶谱分析抑制水声目标信号中的高斯噪声,获得信号中非线性耦合特征;
利用小波变换分析获得水声目标信号中的能量尺度变化特征;
将谱分析获得的特征值重组降维,归一化处理后,获得的特征向量称之为水声目标的特征样本,建立分类器特征样本库。
步骤三:将水声目标特征样本两两组合生成
在模式识别问题中,存在观测数据在原始样本空间中线性不可分情况,支持向量机的基本思想是将样本点变换至高维空间的线性可分样本,再寻找最优分类超平面将样本分开。然而水声目标独特的环境因素导致样本数据难以获得且数目不均衡,由此建立加权支持向量机分类识别模型,解决小样本、样本数目不均衡的水声目标识别问题。然而支持向量机仅适用于二元分类问题,当特征样本库中目标个数n>2时,对应的训练样本集为{x1,x2,...,xn};将样本集中按样本类别两两组成训练样本集,即训练样本集ti-j(xi,xj)满足(i,j)∈{(i,j)|i>j,i,j=1,2,...,n};将标号为i的训练样本标记为正类点,标号为j的样本标记为负类点,形成
假设训练样本数据集
对于分类样本而言,存在部分样本线性不可分情况,即无法满足条件找到最优分类超平面,故式(1)中引入惩罚因子c和松弛变量ξ来降低yi[(w·xi)+b]≥1的约束;
支持向量机识别模型的最优分类超平面是依靠支持向量的位置确定的,与非支持向量无关,将分布在间隔面与超平面之间以及超平面一侧的支持向量称为边界支持向量,则类别中边界支持向量的比例越大样本被错分的比例也越大;从概率论的角度分类标号为-1的边界支持向量与标号为+1的边界支持向量出现的概率相同,如果正类样本数与负类样本数不相等,则表现为训练样本数少的类别边界支持向量比例大于训练样本数多的类别事件发生的概率大,即样本数少的类别中被错分的比例更大,因此引入对类别加权方法,将原始凸二次规划问题转化为:
式中:
其中,α表示拉格朗日乘子;i=1,2,...,n;j=1,2,...,n;
决策函数为:
选择具有良好局部性质的高斯径向基核函数作为内积函数,所述内积函数表达式为:
其中σ表示高斯径向基核函数参数。
步骤四:根据步骤三中生成的二元目标分类对,分别设定加权支持向量机识别模型的核函数参数及惩罚因子参选范围,选择各类目标40%的特征样本作为参选训练数据,以k折交叉验证方法作为分类器识别性能评价标准,设置步长,利用网格搜索法寻找最优核函数参数及惩罚因子;
根据步骤三中获得的加权支持向量机识别模型,惩罚因子c的作用是用来约束最小化目标函数
所述网格搜索法寻找最优核函数参数及惩罚因子,具体为:
步骤1、首先根据经验确定惩罚因子c以及核函数参数σ的搜索范围;
步骤2、其次选择适合的步长,建立搜索网格(c,σ);
步骤3、基于每一个网格上的参数点训练加权支持向量机识别模型,以k折交叉验证的结果作为该参数点下分类器的识别精度;
步骤4、遍历全部网格后,选择使加权支持向量机识别模型对测试样本识别精度最高的参数。
其中,k折交叉验证的基本算法思路如下:首先将n个观测样本均匀随机的分为k个互不交叉的子集,组成样本集s1,s2,...,sk;其次进行k次机器学习算法的训练学习和测试,以第i次机器学习算法迭代为例:将si作为测试样本,其余k-i个样本集作为训练样本输入机器学习算法获得最优决策函数fi,利用fi对测试样本si进行识别预测。将正确的分类次数记为ti,机器学习的分类精度为:
则经过k次迭代运算后获得的正确识别次数为t1,t2,...,tk,机器学习平均分类精度为:
将平均分类精度作为该机器学习算法的优劣评价标准,值得一提的是机器学习算法的平均分类精度仅表示分类器性能,与某次测试训练识别结果无关。
步骤五:根据步骤四中获得的最优核函数参数及惩罚因子,选取各类目标70%的特征样本输入到对应的加权支持向量机识别模型进行训练,所述各类目标70%的特征样本中包含步骤四中的参选训练数据;
在步骤五中,选择各类目标70%的特征样本作为训练样本,分别对
步骤六:根据步骤五中获得训练完成的二元水声目标识别分类器,令未参加训练的30%特征样本数据作为测试样本,同时输入到
在步骤六中,将剩余30%的特征样本作为测试样本,同时输入到
对于输入样本x,建立用于表决判别意见的判别函数:
遍历所有的训练样本集获得
步骤七:统计分类器的识别正确率,评价分类器性能,当识别正确率低于设定阈值时,返回步骤四,提高参选样本数量,重新选择模型参数。
在步骤七中,将混淆矩阵中分类正确的样本数占总样本数的比例称为识别正确率,作为识别评价标准;另设定一个阈值(例如80%),当识别正确率低于阈值时,返回步骤四,提高参选样本数据的数据量,重新选取适合的模型参数。
实施例
步骤1、对于一个二元水声目标识别问题,现有a类目标为一段时长600s的货船辐射噪声数据,b类目标为一段时长900s的摩托艇辐射噪声数据。首先对连续信号进行分帧处理,分帧之后,每一帧的长度称为“帧长”,帧序列的数目称为“帧数”。设置分帧处理的信号帧长为0.5s,每一个帧序列看作一个样本,由此获得1200个a类样本帧序列及1800个b类样本帧序列,构建水声目标样本库。由于本发明方法属于监督学习,故需将a类样本标记为“-1”类,b类样本标记为“+1”类,生成一一对应的标签矩阵y={-1,+1}。
步骤2、根据步骤1中获得的样本帧序列,样本序列中包含了大量舰船辐射噪声特征信息,然而数据冗余度较高不利于模型计算,因此采用水声信号处理方法对样本序列进行特征提取实现数据降维。根据大量的舰船辐射噪声信号分析,舰船辐射噪声特征主要包含三个部分:线谱特征、连续谱特征以及调制特征。其中线谱特征主要由机械噪声和螺旋桨叶片振动产生,分布在1khz以下;连续谱特征表现在100-1000hz范围内连续谱存在一个峰值,当舰船航行速度较高时,螺旋桨高速运转产生空泡现象,连续谱在谱峰前以6db每倍频程递增,谱峰后以-6db每倍频程递减;舰船辐射噪声的调制是由于螺旋桨高速运转产生的基频及其谐波分量对辐射噪声信号的调制,反映了舰船的螺旋桨叶片数及运转频率。利用谱分析方法获取舰船辐射噪声特征的步骤为:
(1)对样本帧序列进行lofar谱分析,获取在帧长为0.5s的信号中,线谱频率的分布特征;
(2)对样本帧序列进行demon谱分析,获取在帧长为0.5s的信号中,调制成分中频率的分布特征;
(3)对样本帧序列进行11/2维谱分析,获取在帧长为0.5s的信号中,非线性耦合特性的分布特征;
(4)对样本帧序列进行小波变换分析,获取在帧长为0.5s的信号中,能量随尺度变化的分布特征;
(5)将所有特征首尾连接,通过降维分析,获得一个m维行向量(m的值取决于降维后有效数据的长度,本例中取m=180),称之为舰船目标的特征样本。
由此,水声目标特征样本库中包含两个部分:第一部分是一个3000×180的特征矩阵
步骤3、建立加权支持向量机识别模型,图2反映了模型的分类原理:利用内积函数将输入的非线性样本转化至高维空间中的线性样本,在高维空间中寻求最优分类平面,使得输入样本按类别划分并保持最大距离,选取合适的类别权系数,平衡各类样本支持向量数目对超平面选择的影响。
输入样本数据集
式中:
由此获得加权后的拉格朗日表达式为:
选择高斯径向基函数作为内积函数,其决策函数为:
步骤4、选取特征样本库中70%的样本数据作为训练样本,30%作为测试样本。从70%的训练样本中再选取40%作为参选训练数据,即选取480个a目标特征样本、720个b目标特征样本连同其对应的标签矩阵一同输入到步骤3中获得的加权支持向量机识别模型中进行训练。利用网格搜索法寻找最优参数的基本步骤如下:
1)首先,根据经验确定惩罚因子c搜索范围为(0~10),以及核函数参数σ的搜索范围为(0~5);
2)其次,选择适合的步长,惩罚因子c步长设置为0.1,核函数参数σ的步长设置为0.01,建立搜索网格(c,σ);
3)基于每一个网格上的参数点训练加权支持向量机模型,设置k折交叉验证的k=20,将参选样本分成20个均匀的子集s1,s2,...,s20,每个子集中包含24个a目标特征样本和36个b目标特征样本。当模型参数设置为c=0.1,σ=0.01时,分别将si(i=1,2,...,20)作为测试样本,其余19个样本集作为训练样本,输入到加权支持向量机识别模型中训练,获得平均分类器精度为65.45%;
4)同理遍历全部网格后,确定当模型参数选择c=4.1,σ=1.21时具备最高的平均分类器精度为98.24%,因此确定为在类目标识别条件下的最优模型参数。
步骤5、根据步骤4中样本数据的划分,将70%的训练样本即840个a类样本和1260个b类样本连同其对应的标签矩阵一同输入到参数为c=4.1,σ=1.21的加权支持向量机识别模型中,对模型进行训练,并将训练完成的模型保存。
步骤6、根据步骤4中样本数据的划分,将剩余30%的测试样本即360个a类样本和540个b类样本连同其对应的标签矩阵一同输入已经保存的识别模型中,得到的识别混淆矩阵如图3中所示。
步骤7、根据步骤6中的混淆矩阵,将分类正确的样本数占总样本数的比例称为识别正确率,计算该分类器对a、b两类目标的识别正确率为91.33%;将正例(或负例)分类正确的样本数占全部真实为正例(或负例)样本数的比例,称之为对正例(或负例)类识别率,则对a类样本的识别率为91.38%,对b类样本的识别率为91.29%。
对于多目标分类问题,要转化为多个双目标分类问题,所采用的一对一举手投票法则基本步骤如下:
首先,待分类目标包含一段时长600s的a类目标辐射噪声信号、一段时长900s的b类目标辐射噪声信号、一段时长800s的c类目标辐射噪声信号以及一段时长400s的d四类目标样本。设置帧长等于0.5s,进行分帧预处理,生成帧长为相等的目标样本库,利用步骤2中谱分析方法,对所有样本帧序列进行特征提取,建立四类水声目标特征样本库;
其次,四类目标两两组合构建6个二元分类模型,例如,a类目标与b类目标之间构成一个二元分类问题,根据步骤3~5,生成一个针对a、b两类目标的二元加权支持向量机模型,称之为ab类分类器,计算获得的平均分类器精度为98.24%。以此类推可以获得其余5个二元分类模型:ac类分类器的平均分类器精度为97.64%、ad类分类器的平均分类器精度为95.56%、bc类分类器的平均分类器精度为96.68%、bd类分类器的平均分类器精度为98.08%、cd类分类器的平均分类器精度为97.36%。
当测试样本输入时,同时输入到6个分类器中进行识别,并对识别结果进行投票,如图4中展示了某一个测试样本的识别过程,该测试样本属于a类目标,分别通过6个分类器,包含a类目标的分类器的识别结果是正确的会使a类识别结果票数+1,另外3个分类器无法同时为某一类目标识别结果投票,因此a类识别结果必定是票数最多者,该次识别结果的输出为a类目标。由此方法,遍历30%的测试样本获得识别混淆矩阵如图5所示,该四元水声目标分类识别模型的识别正确率为88.83%,对a类样本的识别率为86.94%,对b类样本的识别率为88.89%,对c类样本的识别率为91.25%,对d类样本的识别率为86.67%。
以上对本发明所提出的一种基于加权支持向量机的水声目标识别方法,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!