基于统计深度特征的染色伪造图像检测方法及电子装置与流程
本发明属于图像取证领域,具体涉及一种基于统计深度特征的染色伪造图像检测方法及电子装置。
背景技术:
随着图像处理技术的提高,各类图像、视频编辑软件越来越多的出现在人们的日常生活中。根据2019年互联网趋势报告中数据,一半以上的推文与图像、视频等媒介有关,图像社交在互联网行业中占据着举足轻重的地位。以图像染色技术为例,随着深度学习技术在计算机视觉领域的兴起,基于深度学习的图像染色技术也取得了极大的进步,截止到目前,人为生成的染色图像可以轻而易举的骗过大部分非专业人士和机器设备。染色技术的发展为人们带来便利的同时,其带来的安全问题同样不容小觑。在新闻、证物和科学研究等方向,染色伪造图像的恶意使用严重威胁网络空间安全,为社会公平与发展带来巨大的损害。因此,有效的染色伪造图像检测方法的提出迫在眉睫。
图像染色技术是指通过一定的技术手段根据图像纹理信息将灰度图像转化为相同图像内容的彩色图像的过程,理想的染色伪造图像亮度信息与源图像相同,颜色分布符合人类认知习惯,视觉效果足以以假乱真。染色伪造图像检测技术则是指根据自然图像和染色伪造图像在颜色分布上的不同对二者作出正确的区分,防止现实世界中染色伪造图像引起的诈骗欺瞒事件。染色伪造图像检测技术起步较晚,于2016年首次在图像取证研究领域提出。目前已有的染色伪造图像检测技术分为两类,第一类是基于传统方法,分为特征提取和分类两个步骤,这一类方法输入待检测图像,首先进行人工特征提取,再利用传统分类器,比如支持向量机,输出该图像的真假信息。第二类是基于深度学习的端到端的方法,这类方法避免了复杂特征的设计和计算,将特征提取与分类任务同时融合到卷积神经网络设计之中,通过梯度反向传播学习各网络层最优参数,直接输出检测结果。
现有的染色伪造图像检测技术针对的染色方法种类有限,所针对的染色方法提出时间相对久远,没有因为染色技术的发展而进行扩充和更新。然而在自然场景下染色伪造图像的检测存在多变性,自然图像的图像内容千变万化,用于伪造染色图像的染色方法种类也可能各不相同,这就使得伪造图像检测任务的难度大大增加。另外,已有的基于深度学习的染色伪造图像检测方法用简单的二分类模型进行染色伪造图像的鉴别,没有针对染色伪造图像与自然图像在颜色统计分布上的差异提出创新性方法。针对染色伪造图像与自然图像的颜色统计分布进行深度特征提取有助于模型对二者的本质差别进行较好的学习,对于提高染色伪造图像检测的精度和鲁棒性至关重要。
中国专利申请cn201710382747.1公开了一种基于颜色统计差异的染色伪造图像检测方法,对染色伪造图像和自然图像的颜色统计差异人工进行特征编码,并利用传统分类器支持向量机得到检测结果。这种染色伪造图像检测方法属于传统方法,分类结果的好坏很大程度上取决于手工特征设计的好坏,虽然在当前的染色伪造图像数据集上取得了正确率为78.5%的检测结果,但是染色伪造图像检测模型的准确率仍有较大提升空间。
技术实现要素:
针对上述问题,本发明提出一种基于统计深度特征的染色伪造图像检测方法及电子装置,从而完成现实场景下的染色伪造图像检测任务。
本发明所采用的技术方案为:
一种基于统计深度特征的染色伪造图像检测方法,其步骤包括:
1)将图像从rgb颜色空间变换到可将亮度信息与色度信息解耦合的颜色空间,分别获取每个颜色通道的直方图统计分布信息,将所获得的直方图统计分布信息串联得到颜色统计分布向量;
2)提取颜色统计分布向量的统计深度特征,并对统计深度特征进行特征抽象任务,得到池化特征;
3)对池化特征进行分类,根据正负样本的概率值,判定染色伪造图像。
进一步地,可将亮度信息与色度信息解耦合的颜色空间包括lab颜色空间和/或hsv颜色空间。
进一步地,使用归一化方法,对得到的颜色统计分布向量进行预处理。
进一步地,通过一维卷积神经网络完成提取颜色统计分布向量的统计深度特征,对统计深度特征进行特征抽象任务,得到池化特征,并对池化特征进行分类,计算正负样本的概率值。
进一步地,一维卷积神经网络包括一卷积层、一池化层和若干全连接层。
进一步地,卷积层使用线性修正单元(relu)激活,前若干全连接层使用归一化指数函数(softmax)激活,最后的全连接层使用s型函数(sigmoid)激活。
进一步地,通过若干带有标签向量的染色伪造图像及对应的真实图像,基于分类损失函数,训练一维卷积神经网络。
进一步地,使用优化器自动计算训练一维卷积神经网络的学习率;所述优化器包括自适应矩估计(adam)优化器。
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序执行上述方法。
一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述方法。
与现有技术相比,本发明具有以下优点:
1)本发明利用端到端的深度学习技术对染色伪造图像和自然图像的统计分布差异进行深度特征提取并完成分类任务,染色伪造图像检测模型的性能得到大大提升,相比中国专利申请cn201710382747.1中提出的染色伪造图像检测方法准确率提升了14.91个百分点,取得了93.41%的高性能;
2)染色伪造图像检测模型速度较快,在图形处理器(gpu)平台下10000张图像的处理时间为972.42秒,其中数据读取时间为966.97秒,模型处理时间为5.45秒;
3)染色伪造图像检测模型鲁棒性较强。
附图说明
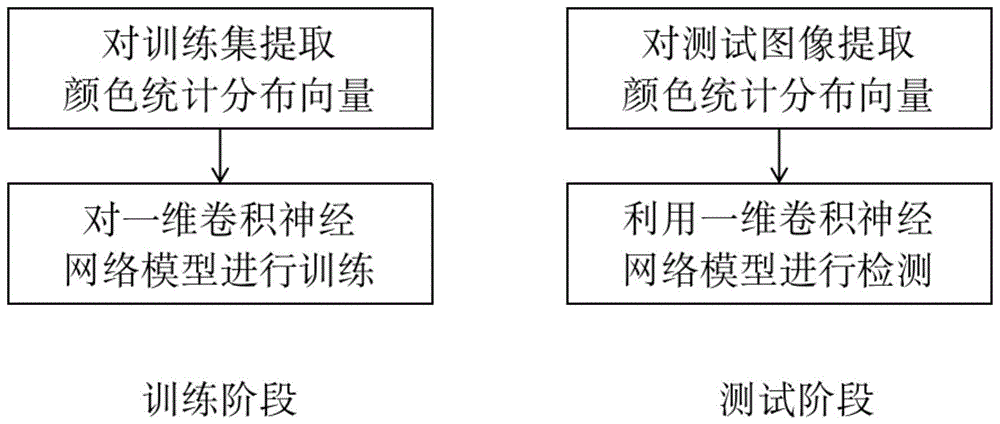
图1是本发明的方法流程图。
图2是颜色统计分布向量提取流程图。
图3是一维卷积神经网络结构图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本发明的一种基于统计深度特征的染色伪造图像检测方法,包括训练阶段和检测阶段,如图1所示,所述训练阶段包括以下步骤:
1)将训练图像集(包括染色伪造图像和其对应的自然图像)中的每张图像从rgb颜色空间变换到可将亮度信息与色度信息解耦合的颜色空间,分别获取每个颜色通道的直方图统计分布信息,将所获得的统计分布信息串联得到颜色统计分布向量;其中所述的可将亮度信息与色度信息解耦合的颜色空间包括lab颜色空间、hsv颜色空间等。
2)构建一个一维卷积神经网络,对每张训练图像的颜色统计分布向量进行预处理操作,以使得颜色统计分布向量适合输入神经网络进行训练处理;其中所述的预处理操作包括归一化等。
3)基于分类损失函数,将每张训练图像的颜色统计分布向量输入所构建的一维卷积神经网络进行深度特征提取,并最终训练得到染色伪造图像深度检测模型。
所述构建的一维卷积神经网络包括卷积层、池化层和全连接层处理,具体对网络输入数据的处理过程为:
3-1)将归一化的颜色统计分布向量输入卷积层学习图像的统计深度特征;
3-2)将统计深度特征输入池化层,该池化层进行最大值池化操作,对统计深度特征进行特征抽象任务,得到池化特征;
3-3)将池化特征输入到全连接层,该全连接层由三个全连接操作组成,对每个输入样本数据进行分类,输出正负样本的概率值。
所述对一维卷积神经网络模型进行的染色伪造图像检测训练步骤包括:
3-4)将训练图像标签表示为一个由0和1组成的标签向量;其中0为负例即代表真实彩色图像,1为正例即代表染色伪造图像,反之亦可;
3-5)对训练集中的每幅染色伪造图像和真实彩色图像按照上述方式分别计算颜色统计分布向量,与其对应的标签向量一起送入上述构建的一维卷积神经网络使用随机梯度下降进行端到端的训练;
3-6)使用优化器(如adam优化器等)自动计算每维的学习率,训练次数达到设定值时结束。
所述检测阶段包括以下步骤:
1)基于训练步骤1)中所述颜色统计分布向量构建方式,对待检测图像提取其颜色统计分布向量;
2)基于训练步骤2)中所述预处理操作对检测步骤1)中所述待检测图像的颜色统计分布向量进行预处理,并基于训练步骤3)中所述染色伪造图像深度检测模型进行检测,以得到检测结果。
下面举一具体实施例来更好的解释说明本发明。该实施例步骤包括:
1)构建颜色统计分布向量。
如图2所示,首先将训练图像集中的10000张染色伪造图像及其对应的10000张真实彩色图像从rgb空间变换到可将亮度信息与色度信息解耦合的颜色空间,lab颜色空间和hsv颜色空间中。
将输入图像从rgb颜色空间变换至lab颜色空间的具体过程如下:
a)读取输入图像,获取其在rgb颜色空间下的表示数据。
b)根据如下公式对rgb颜色空间进行处理,得到对应的xyz颜色空间下的表示数据,
其中,r、g、b分别表示图像在rgb颜色空间下三个通道,x、y、z分别表示图像在xyz颜色空间下三个通道,矩阵系数为国际照明委员会1931年提出的定值。
c)根据如下公式对xyz颜色空间进行处理,得到对应的lab颜色空间下的表示数据,
其中,l、a、b分别表示图像在lab颜色空间下的三个通道,xn、yn、zn取值分别为95.047、100.0和108.883,变换系数为国际照明委员会1976年提出的定值。
将输入图像从rgb颜色空间变换至hsv颜色空间的具体过程如下:
a)读取输入图像,获取其在rgb颜色空间下的表示数据。
b)根据如下公式对rgb颜色空间进行处理,得到对应的xyz颜色空间下的表示数据,
υ=max
其中,h、s、v分别表示图像在hsv颜色空间下的三个通道,max,min分别表示r、g、b三通道中的最大值和最小值。
随后,对a颜色通道进行直方图统计,将[-128,127]区间平均分为256个子区间,依次统计a通道的像素点在每个子区间内出现的次数,按照子区间端点值从小到大的顺序记录对应频次值,构成一个1*256长度的子向量。
对b颜色通道进行直方图统计,将[-128,127]区间平均分为256个子区间,依次统计b通道的像素点在每个子区间内出现的次数,按照子区间端点值从小到大的顺序记录对应频次值,构成一个1*256长度的子向量。
对h颜色通道进行直方图统计,将[0,360]区间平均分为256个子区间,依次统计h通道的像素点在每个子区间内出现的次数,按照子区间端点值从小到大的顺序记录对应频次值,构成一个1*256长度的子向量。
对s颜色通道进行直方图统计,将[0,1]区间平均分为256个子区间,依次统计s通道的像素点在每个子区间内出现的次数,按照子区间端点值从小到大的顺序记录对应频次值,构成一个1*256长度的子向量。
将四个子向量按照a、b、h、s的顺序串联拼接到一起,最终组成一个1*1024大小的颜色统计分布向量,其中l和v通道表示图像亮度信息,对于染色伪造图像与自然图像区分的作用有限,本发明不予考虑。
2)归一化处理与一维卷积神经网络的构建。
按照如下公式对颜色统计分布向量进行归一化处理得到统计特征,将颜色统计分布向量的取值范围映射为[0,1],并使向量各项相加之和为1,
其中,x表示直方图每个子区间的频数,n取值为255。
随后,构建一个一维卷积神经网络,包括1个卷积层,1个池化层,3个全连接层,具体结构如图3所示。
3)深度模型训练。
将训练图像标签表示为一个由0和1组成的标签向量,其中0为负例(即代表真实图像),1为正例(即代表染色伪造图像),并将每幅训练图像所提取的颜色统计分布向量和所述标签向量一起输入到一维卷积神经网络中进行训练,具体训练过程如下:
a)将归一化的颜色统计分布向量输入卷积层学习统计深度特征,卷积层包括一次卷积和一次激活操作,卷积核大小为3*3,卷积过程不进行填充,激活函数选择relu激活,所得到的统计深度特征作为池化层的输入。
b)将统计深度特征输入到池化层,该池化层进行最大池化操作,窗口大小为3,对统计深度特征进行特征抽象任务,得到池化特征。
c)将池化特征输入全连接层,该全连接层包括三个全连接和三个激活函数操作,三个全连接输出节点分别为512、256和2,前两个全连接操作后的激活函数都为softmax激活,最后一个全连接操作后采用了sigmoid激活,对每个输入样本进行分类,输出正负样本的概率值。
d)计算网络预测结果与输入图像真实标签的交叉熵,此计算作为损失函数以优化一维卷积神经网络。
e)不断重复上述训练过程,使用adam优化器调节学习率,批处理大小(batchsize)设为32,初始学习率设为0.001,当迭代次数达到给定值时结束训练,保存模型数据。
4)检测未知图像(即待检测图像)。
对待检测图像进行颜色统计分布向量计算,将颜色统计分布向量输入上述保存模型,经过卷积、池化和全连接操作,输出概率值,通过比较染色伪造图像和真实彩色图像的概率大小输出最终结果。
为了验证本发明方法的有效性和实用性,以10000幅染色伪造图像和相应的10000幅自然图像作为训练图像集,根据步骤1)-步骤3)训练了一个染色伪造图像深度检测模型,并对另外10000幅待检测图像,提取每一幅待检测图像的颜色统计分布向量,并将其输入染色伪造图像深度检测模型进行检测,得到一个由0和1组成的标签向量,再与该10000幅待检测图像的实际(真实)标签向量做对比,染色伪造图像深度检测模型所得的结果的正确率为93.41%,相比中国专利申请cn201710382747.1中染色伪造图像检测方法78.50%的准确率提升了14.91个百分点,可见本发明方法有效可行。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替代,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!