一种跨媒体检索困难样本的方法与流程
本发明属于自然语言理解技术领域,具体涉及一种跨媒体检索困难样本的方法。
背景技术:
随着互联网技术和社交媒体的飞速发展,各种媒体形式的数据出现爆炸性增长。互联网用户对信息检索的要求逐渐提高。传统的基于单一媒体的信息检索方法已经无法满足互联网用户的需求,用户更希望通过检索一种模态的媒体信息就可以查询到其它多种媒体类型的结果。为了满足这一需求,跨媒体信息检索技术越来越受到关注。
2004年,hardoon等人首次将典型相关分析cca(canonicalcorrelationanalysis)应用于跨媒体信息检索任务。cca是一种线性数学模型,主要目的是学习子空间用于最大化两组异构数据的成对相关性。输入图像/文本对之后,cca通过将图像和文本特征映射到最大相关子空间来度量文本和图像之间的相似性。
近年来,随着深度学习的迅猛发展,越来越多的基于深度神经网络的跨媒体信息检索模型被提出。原始数据集是成对的正例,即表示相同语义概念的文本/图像对。为了提供模型训练所需的负例,通常的做法是随机组合不同语义概念的图像和文本,构成负的图像/文本对。基于深度神经网络的模型通常使用神经网络对跨媒体数据进行特征提取,由于其非线性映射的特点,深度学习模型对各种复杂的媒体数据具有良好的表达能力。dcca(deepcca)就是cca模型的非线性扩展,用于学习两种类型媒体数据之间的复杂非线性变换。它为不同的媒体类型的数据构建了一个具有共享层的网络,其中包含两个子网,通过学习使输出层最大相关。这种构建数据集的方法为模型的训练带来了不可避免的问题:随机组合的负样本中存在大量很容易被模型准确检测出的简单样本,这类样本对模型的训练贡献甚微。然而数据集中总是存在一些容易被错误分类的正样本和负样本,这类样本被称为困难样本。在模型训练过程中,常常因为受到大量简单样本的影响而忽略少量容易被错误分类的困难样本的影响,导致模型不能收敛到更好的结果,陷入局部最优。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提出一种跨媒体检索困难样本的方法。
为实现上述目的,本发明采用如下技术方案:
一种跨媒体检索困难样本的方法,包括以下步骤:
步骤1,计算表征文本图像对中的文本与图像的文本描述之间的相关性大小的细粒度标签;
步骤1.1,从文本图像对的原始数据集d中随机选取属于同一语义类别的文本和图像构成正样本数据集
步骤1.2,从d中提取与p中
步骤1.3,计算正样本数据集p和负样本数据集e中任意一个文本图像对的细粒度标签:
步骤2,基于细粒度度标签计算文本图像对的相似度;
步骤2.1,利用图卷积模型gcn(graphconvolutionalnetwork)提取输入文本t的文本特征vt;
步骤2.2,利用卷积神经网络模型ccn(convolutionalneuralnetworks)提取输入图像i的图像特征vi;
步骤2.3,基于vt、vi构建正样本数据集
式中,
与现有技术相比,本发明具有以下有益效果:
本发明通过计算表征文本图像对中的文本与图像的文本描述之间的相关性大小的细粒度标签,基于细粒度度标签计算文本图像对的相似度,实现了困难样本的跨媒体检索。本发明充分利用文本信息与图像信息相比包含更丰富信息的特点,通过充分挖掘训练数据中的困难样本,并根据困难程度为它们分配细粒度标签,基于细粒度度标签计算文本图像对的相似度,提高了跨媒体检索困难样本的准确率。
附图说明
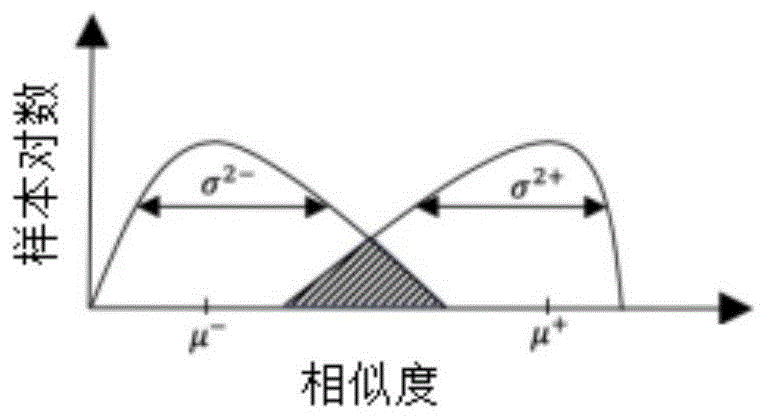
图1为文本图像对相似度分布曲线示意图,横轴为相似度,纵轴为样本对数。
具体实施方式
下面结合附图对本发明作进一步详细说明。
本发明实施例一种跨媒体检索困难样本的方法,所述方法包括以下步骤:
s101、计算表征文本图像对中的文本与图像的文本描述之间的相关性大小的细粒度标签;
s1011、从文本图像对的原始数据集d中随机选取属于同一语义类别的文本和图像构成正样本数据集
s1012、从d中提取与p中
s1013、计算正样本数据集p和负样本数据集e中任意一个文本图像对的细粒度标签:
s102、基于细粒度度标签计算文本图像对的相似度;
s1021、利用图卷积模型gcn提取输入文本t的文本特征vt;
s1022、利用卷积神经网络模型ccn提取输入图像i的图像特征vi;
s1023、基于vt、vi构建正样本数据集
式中,
本实施例的实现分为两个阶段。第一阶段是计算文本相似度的细粒度标签,由步骤s101实现;第二阶段是基于细粒度标签实现跨模态信息检索,由步骤s102实现。第一阶段的主要目标是测量文本图像对中的文本与图像的原始文本描述之间的相关性。与图像相比,文本描述通常包含更丰富和更具体的信息。因此,本实施例采用图像的原始文本描述表示图像语义,通过计算原始文本与文本图像对中的文本之间的相似度判断样本的困难程度。对于正样本,相似度越小,样本难度越大;对于负样本,相似度越大,样本难度越大。
步骤s101具体包括s1011~s1013。
步骤s1011基于原始数据集d构建正样本数据集p和负样本数据集e。
步骤s1012基于d、p、e提取正文本对和负文本对,并分别计算每个正文本对和负文本对的相似度。相似度采用余弦相似度。
步骤s1013根据每个正文本对和负文本对的相似度,根据公式(1)、(2)计算正样本数据集p和负样本数据集e中任意一个文本图像对的细粒度标签。根据公式(1)、(2)可知,细粒度标签的最大值为1,最小值为0。
步骤s102具体包括s1021~s1023。
步骤s1021利用图卷积模型gcn提取输入文本t的文本特征。gcn将卷积操作扩展到了图结构的数据中,因此具有很强的学习图的局部特征和固定特征的能力,并被广泛应用于文本分类任务。在近期的研究中,gcn表现出了强大的文本语义建模及文本分类能力。在本实施例中,gcn包含两个卷积层,每一层卷积之后进行一次relu;然后,通过一个全连接层将文本特征映射到潜在的共享语义空间。
步骤s1022利用卷积神经网络模型ccn提取输入图像i的图像特征。ccn是提取图像特征的常用模型。也可以采用预训练的vgg-19提取图像特征。对于给定的一个224×224的图像,选择vgg-19中倒数第二层,即fc7层输出的4096维的向量;之后通过一层全连接层将其映射到潜在的共享语义空间。
步骤s1023基于上一步提取的文本特征和图像特征构建正样本数据集和负样本数据集,分别计算正、负样本数据集中每个文本图像对的相似度,并利用细粒度标签进行修正。
作为一种可选实施例,模型学习的损失函数loss为:
loss=(σ2++σ2-)+λmax(0,m-(μ+-μ-))(5)
式中,μ+、σ2+为
在本实施例中,为了减少模型对困难样本识别错误的比例,使神经网络模型收敛到更好的结果,对损失函数进行了改进,如公式(5)~(9),改进后的相似度是经细粒度标签修正后的值。图1中的左曲线表示不同语义类别的文本图像对的相似度分布,右曲线表示相同语义类别的文本图像对的相似度分布,阴影部分面积大小反映了误报比例的大小。根据公式(5),使损失函数最小的结果是使μ+最大,使μ-、σ2-、σ2+最小。根据图1,很显然,μ-、σ2-、σ2+越小、μ+越大,阴影部分面积越小。因此,损失函数最小时阴影部分面积达到最小,使误报比例降低。根据(4)式,经细粒度标签修正后,负样本对的相似度增大,负简单样本增加的少,负困难样本增加的多,学习过程中对负困难样本的惩罚增加,相当于图1中的左曲线右移。同理,根据(3)式,正样本对的相似度减小,正简单样本减少的少,正困难样本减少的多,学习过程中对正困难样本的惩罚增加,相当于图1中的右曲线左移。左曲线右移、右曲线左移的结果是阴影部分面积增大,学习过程使阴影部分面积最小,加大了对困难样本的关注,使模型收敛到更好的结果。
为了验证本发明的有效性,下面给出一组实验数据。实验采用三个数据集,分别是english-wiki、tvgraz和chinese-wiki,分别包含2866、2360和3103个文本图像对。利用本发明方法和现有的gin模型在三个数据集上进行跨媒体检索。本发明与gin最大的区别在于加入了对困难样本的挖掘以及对不同困难程度的样本的细粒度标签分配,在损失函数的计算过程中加入了细粒度标签,加强了困难样本对模型学习的影响。实验结果如表1所示。
表1实验结果
由表1可知,本发明方法的准确率明显优于其它模型,与gin相比,在english-wiki,tvgraz和chinese-wiki上分别增加了约4%、3%和10%。这表明通过细粒度标签标记的样本困难程度的信息有助于提升现有模型在跨媒体信息检索任务中的性能。同时证明了本发明在分配细粒度标签任务中的有效性,这些细粒度标签的引入使得模型的学习更加关注困难样本,进一步提升了模型检索性能。
上述仅对本发明中的几种具体实施例加以说明,但并不能作为本发明的保护范围,凡是依据本发明中的设计精神所做出的等效变化或修饰或等比例放大或缩小等,均应认为落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!