一种联邦学习中数据操纵攻击的安全防御方法与流程
本发明涉及一种联邦学习的安全训练框架实现方法,更具体的说是涉及一种防御联邦学习中数据操纵攻击的安全训练框架的实现方法。
背景技术:
联邦学习是一种新兴的深度学习框架。在传统的集中式深度学习中,中心服务器需要收集大量的用户数据用于训练神经网络模型(简称模型),但是由于数据传输的网络通信开销较大、用户数据归属权以及用户数据隐私性等问题,用于进行深度学习的用户数据往往难以获取。而联邦学习采取了另一种训练神经网络模型的方式:在一轮训练中,每一个用户利用其私有数据训练本地模型,然后将本地模型的参数上传至中心服务器,由中心服务器将所有用户的参数进行融合生成全局模型的参数,再将全局模型的参数下发至用户,用户根据全局模型参数对本地模型进行更新,如此循环若干轮训练直至全局模型收敛,训练结束。基于这种技术,联邦学习能够在用户的私有训练数据不离开本地的前提下实现多个用户共同进行深度学习,完成指定的学习任务,如:图像分类、文本预测等,解决了传统的集中式深度学习中用户数据难以获取的问题。
但是,在联邦学习中也存在着一些安全隐患。由于参与联邦学习的用户并非全都是正常用户,一些恶意用户能够通过发动数据操纵攻击威胁到用户数据隐私以及影响神经网络模型的训练结果,对参与联邦学习的正常用户的数据安全性和模型可用性造成巨大的危害。数据操纵攻击是指恶意用户通过训练恶意的神经网络模型对上传至中心服务器的本地模型参数进行伪造、篡改而实现的一种攻击方式。其中,生成式对抗网络攻击和模型投毒攻击是两种代表性的数据操纵攻击。
在生成式对抗网络攻击中,恶意用户通过在本地训练生成式对抗网络进而窃取其他用户数据隐私,获得其他用户的私有训练数据,威胁到正常用户的数据安全。生成式对抗网络是一种深度神经网络模型,由一个生成模型和一个判别模型构成。生成模型的目标是生成能够以假乱真的训练数据,而判别模型的目标则是能够正确的对训练数据进行分类,区分出伪造的训练数据和真实的训练数据。生成式对抗网络的训练过程就是生成模型和判别模型的博弈过程。而在联邦学习中,恶意用户为了窃取其他正常用户的训练数据,需要通过生成模型不断生成伪造的训练数据,并将其对作为正常的训练数据来训练本地模型,进而对其他参与联邦学习的正常用户的训练过程造成干扰,在联邦学习的过程中,恶意用户和正常用户不断博弈,使得恶意用户的生成模型能够产生的数据越来越接近于正常用户的正常训练数据,从而达到获取其他用户私有训练数据的目标。
在模型投毒攻击中,恶意用户能够影响神经网络模型的训练结果,威胁到模型安全和可用性。以图像分类任务为例,恶意用户的目标是使得全局模型的分类结果出现预期的错误,如:将猫的图片分类为狗,将鞋子的图片分类为衬衫等。恶意用户通过伪造训练数据,篡改正常训练数据的标签(如将猫的图片的标签改为狗),利用伪造的训练数据来训练本地模型,然后将本地模型参数上传至中心服务器,致使全局模型的分类结果受到影响。在联邦学习的过程中,恶意用户通过不断上传恶意的本地模型参数对全局模型施加影响,最终导致全局模型分类结果出现恶意用户预期的错误。
生成式对抗网络攻击和模型投毒攻击会对参与联邦学习的正常用户造成巨大的威胁。目前,针对联邦学习中存在的安全问题也有一些相关的研究,现有技术中主要考虑的是抵御恶意的中心服务器对于联邦学习过程产生的危害,主要的技术包括利用差分隐私、同态加密等算法来保护用户的本地模型参数,减小其中的信息泄露。然而,现有的研究工作中缺乏如何防御对来自参与联邦学习用户造成的威胁的分析。由于数据操纵攻击的威胁来自参与联邦学习的用户内部,恶意用户能够藏匿于正常用户之中,其攻击方式更为隐蔽,攻击手法也更加难以进行检测和排查,已有的针对联邦学习中安全问题的防御技术难以有效的对抗上述两种数据操纵攻击,这也给参与联邦学习的用户带来了巨大的安全隐患。
因此,针对联邦学习中的数据操纵攻击需要设计一种高效、可靠的防御方案,实现联邦学习的安全训练。
技术实现要素:
发明目的:针对现有技术中存在的问题与不足,提供了一种高效的在防御联邦学习中数据操纵攻击的安全训练框架的实现方法,能够有效防御恶意用户发动的数据操纵攻击,减小恶意用户对正常的联邦学习过程的影响,保障参与联邦学习的正常用户的数据安全和模型安全。
技术方案:联邦学习中数据操纵攻击的安全防御方法,其特征在于,包括以下几个步骤:
步骤1,中心服务器接收用户上传的本地模型参数,计算每个用户上传的本轮本地模型参数的相似程度及每个用户对应的融合系数;所述本地模型参数为用户采用私有训练数据训练一轮后的本地模型参数;
步骤2,中心服务器接收到本地用户一个训练周期的本地模型参数后,根据融合系数计算每个用户的本地模型参数的加权平均值得到全局模型参数,所述一个训练周期为预设的本地模型参数更新轮数;
步骤3,将全局模型参数下发至对应的用户,用户收到全局模型参数后更新本地模型参数。
作为优选,所述步骤1中,中心服务器接收用户i上传的本地模型参数
作为优选,所述步骤1具体包括:
步骤101,接收所述正常用户和恶意用户上传的本地模型参数
步骤102,选择每一位用户本地模型参数
步骤103,计算步骤102所得的所有用户的部分本地模型参数
步骤104,计算每一个用户的部分本地模型参数
步骤105,利用均值漂移算法计算步骤104所得的相似度的中心点
步骤106,计算步骤104所得的每个用户对应的相似度
步骤107,利用步骤106所得的聚集度
作为优选,所述步骤2和步骤3分别为:
步骤2,判断t是否为τ的倍数,若是,转到步骤3;否则,转到步骤1;所述t为用户实际训练轮数,τ为一个训练周期内包含的本地模型参数训练轮数;;
步骤3,计算全局模型参数
作为优选,在步骤1中,每一轮训练之后本地模型参数计算公式为
作为优选,在步骤104中,采用余弦相似度计算部分本地模型参数
所述向量
作为优选,在步骤105中,所述均值漂移算法的输入数据为步骤104所得的每一个用户的相似度
步骤1051,对于给定的每一个中心点ci,搜索其在指定半径r范围内的邻近点集合p,其中,半径r通常设置为一个较小的数值;
步骤1052,计算步骤1051所得的邻近点集合p的平均值
步骤1053,计算中心点ci与平均值
步骤1054,更新中心点
步骤1055,若步骤1053所得的差值小于设定的阈值,则算法终止,返回中心点ci;否则,转到步骤1051;
最终,以所得的中心点ci的众数作为最终的相似度的中心点
作为优选,所述用户包括正常用户和恶意用户,所述正常用户持有若干正常训练数据用于训练正常的本地模型,所述恶意用户持有若干正常训练数据以及若干用于数据操纵攻击的恶意训练数据用于训练恶意的本地模型。
有益效果:与现有技术相比,本发明通过一种新型的基于相似度计算的方法,结合异步更新策略,能够以较低的计算开销来防御生成式对抗网络攻击和模型投毒攻击这两种对联邦学习有较大威胁的数据操纵攻击,并且在实际实验中取得了良好的效果,能够有效的保护参与联邦学习的用户的数据安全和神经网络模型安全,为解决联邦学习中安全训练问题提供了新的思路和解决方案,具有广泛的应用前景和研究价值。
附图说明
图1为本发明实施例中联邦学习数据操纵攻击示意图。
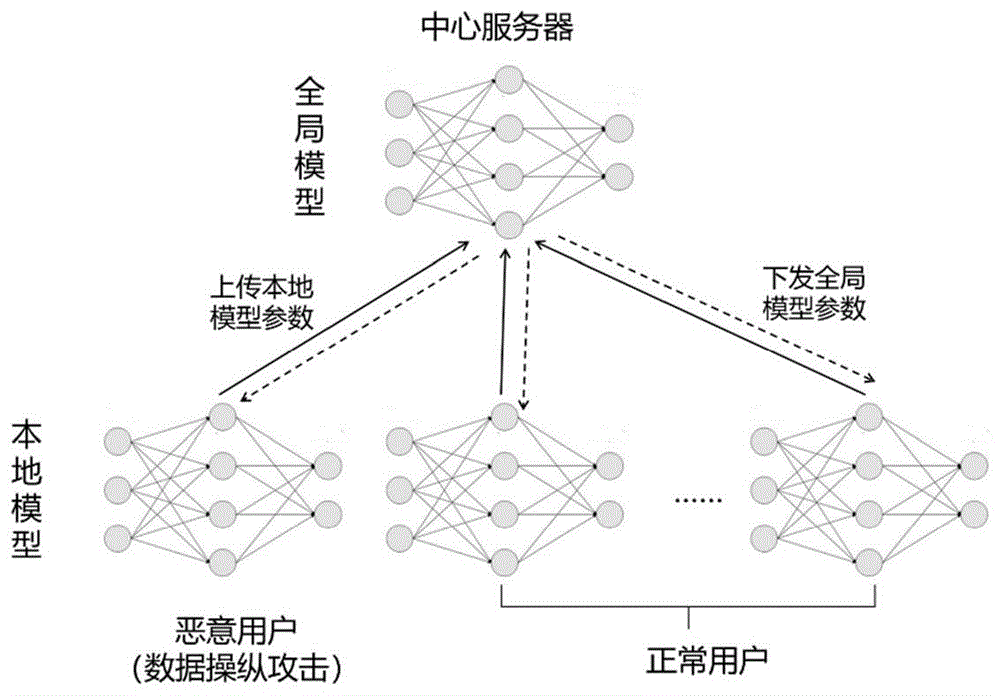
图2为本发明实施例防御联邦学习中数据操纵攻击的安全训练框架图。
图3为本发明实施例中余弦相似度示意图。
图4为本发明实施例恶意用户与正常用户的余弦相似度差异图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明。
本发明实施例公开了一种防御联邦学习中数据操纵攻击的安全训练框架的实现方法。
本发明实施例提供的联邦学习数据操纵攻击,如图1所示:包括三种执行主体:若干正常用户,一个恶意用户以及一个中心服务器。所述正常用户、恶意用户和中心服务器共同进行联邦学习以完成指定的图像分类任务。所述正常用户均持有若干正常训练数据用于训练正常的本地模型,所述恶意用户持有若干正常训练数据以及若干用于数据操纵攻击的恶意训练数据用于训练恶意的本地模型,上述每一个用户的训练数据为其私有,不对外公开。所述中心服务器接收来自所述正常用户和所述恶意用户上传的本地模型参数(实线箭头),并根据本地模型参数计算全局模型参数,然后将全局模型参数下发至所述正常用户和恶意用户(虚线箭头)。所述正常用户利用正常训练数据训练本地模型,并将本地模型参数上传至所述中心服务器,并且根据中心服务器下发的全局模型参数更新本地模型参数。所述恶意用户利用伪造的恶意训练数据来训练本地模型,将篡改、操纵后的本地模型参数上传至所述中心服务器,从而实现数据操纵攻击,达到窃取其他正常用户的私有训练数据,影响模型训练结果等攻击目标,并且所述恶意用户能够通过训练所持有的若干正常训练数据伪装成正常用户,从而在达到攻击目标的前提下,尽可能的绕过所述安全训练框架的防御技术。
图2为本发明所述的防御联邦学习中数据操纵攻击的安全训练框架图。所述安全训练框架的实体以及数据传输方式等与图1所示的数据操纵攻击示意图相同。所述安全训练框架的核心部分为中心服务器,即利用所述中心服务器通过对所述正常用户和恶意用户上传的本地模型参数进行分析,利用一种新型的基于相似度的计算方式检测出所述恶意用户,并且通过降低所述恶意用户的本地模型参数在全局模型参数的权重(融合系数)来抵御数据操纵攻击,降低所述恶意用户的攻击成功率,从而保护所述正常用户的数据安全和神经网络模型安全。
下面具体解释图2中上述三种执行主体的动作流程。
本实施例中的安全训练框架的一轮训练表示所述正常用户或恶意用户利用持有的训练数据训练一次本地模型,所述安全训练框架采取异步更新策略,即所述安全训练框架以一个训练周期为单位进行全局模型更新,其中所述一个训练周期为预设的本地模型参数更新轮数τ。
正常用户和恶意用户在一个训练周期内执行的动作流程相同:用户周期性的训练本地模型,然后向中心服务器上传本地模型参数并根据中心服务器更新本地模型参数。t为正常用户或恶意用户实际训练轮数,i为正常用户或恶意用户对应的标识,
步骤s1,用户i进行第t轮训练,即利用持有的训练数据训练一轮本地模型,并将训练后的本地模型参数
具体的,每一轮训练之后本地模型参数计算公式为
其中,η为神经网络模型学习率,g为梯度函数,本发明实施例中采用随机梯度下降算法。随机梯度下降算法通过在小批量训练数据上计算损失函数的梯度来更新神经网络模型参数,适用于训练数据较多的场景。
正常用户和恶意用户所训练的神经网络模型结构相同。在实际操作中,根据恶意用户发动的数据操纵攻击类型的不同,其训练本地模型以及上传本地模型参数过程与正常用户有所差异。例如:在生成式对抗网络攻击中,恶意用户需要额外训练一个生成模型用以窃取其他正常用户的训练数据。在模型投毒攻击中,恶意用户为了影响全局模型的训练结果,提升攻击成功率,需要成倍的扩大所上传的本地模型参数。并且,恶意用户为了能够更好的伪装自身的攻击行为,欺骗中心服务器将其视为正常用户,会采取一些更为隐蔽的攻击方式,例如:通过训练一定数量的正常训练数据使得其本地模型参数与正常用户更为接近等。
步骤s2,检查中心服务器是否下发更新全局模型参数
步骤s3,根据全局模型参数
本发明实施例采用异步更新策略,即在一个训练周期中,用户需要训练τ轮本地模型,并且在每一轮训练之后将本地模型参数上传至中心服务器,但是一个训练周期中心服务器只下发一轮全局模型参数。α为本地模型参数的更新率,取值介于0到1之间,α越大则表示本地模型受全局模型更新的影响越大,也即全局模型参数与本地模型参数的相似程度越高。
本发明所述安全训练框架的核心部分为中心服务器,即中心服务器通过分析用户上传的本地模型参数,检测出所述恶意用户,并且通过降低恶意用户的本地模型参数在在全局模型参数的权重即融合系数的方式,来抵御恶意用户发动的数据操纵攻击,降低恶意用户的攻击成功率,从而保护所述正常用户的数据安全和神经网络模型安全。由于所述恶意用户在发动数据操纵攻击时,需要不断的篡改、操纵其上传给所述中心服务器的本地模型参数,才能实现其攻击目标,因此,即使所述恶意用户通过训练一定量的正常训练数据来伪装成正常用户,从长期的训练过程来看,恶意用户与正常用户上传的本地模型参数依然有较为明显的差异。
本发明中心服务器周期性的使用一种新型的基于相似度的方法计算每个所述正常用户和恶意用户的本地模型参数的相似程度,用以计算每个用户对应的融合系数,并根据融合系数计算所有用户的本地模型参数的加权平均值得到全局模型参数,然后将全局模型参数下发至每一个用户。
步骤101,接收所述正常用户和恶意用户上传的本地模型参数
步骤102,选择每一个用户本地模型参数
为了提高算法的效率,降低计算开销,以及减小极小的本地模型参数对于后续分析的影响,本发明选取绝对值较大的本地模型参数来计算相似度。索引是指向量或数组即一组数据中每一个元素的位置,本发明中的本地模型参数、全局模型参数、融合系数等都是数组。计算索引的并集是为了保证每一个用户选择的部分模型参数的数量相同,便于后续的相似度计算。具体的,选择本地模型参数的数量可以视实际情况而定,比如选择绝对值最大的前10%的本地模型参数。
步骤103,计算步骤102所得的所有用户的部分本地模型参数
本发明以中位数为基准,计算每一个用户的部分本地模型参数与中位数的相似度。中位数是顺序排列的一组数据中居于中间位置的数。
步骤104,计算每一个用户的部分本地模型参数
作为优选,本发明使用余弦相似度计算部分本地模型参数
在本发明的余弦相似度计算过程中,上述向量
本实施例中将相似度计算和异步更新策略相结合,以一种向前看的方式来计算相似度,即如果将训练模型的过程视为一个不断前进的过程,那么在计算相似度时相当于以上一个训练周期的全局模型参数为基准点观察后面几轮训练中本地模型参数变化的趋势。本发明采用向前看的相似度计算方式是为了减小在联邦学习过程中随机梯度下降算法的随机性对相似度计算造成的影响,以免对正常用户的训练产生干扰,由于在一个训练周期中全局模型参数只更新一次,而本地模型参数更新τ轮,相应的也要进行τ轮相似度计算,通过观察多轮本地模型参数的变化能够更好的分析不同用户之间本地模型参数的趋势,也更能区分出恶意用户和正常用户的本地模型参数的差别,避免因为随机性带来的扰动造成的负面影响。
本发明中,以模型参数中的元素为单位进行相似度计算,即需要对每一个用户的每一个部分模型参数计算对应的相似度,而非将部分模型参数作为一个向量进行计算。以元素为单位计算相似度,能够具体的分析每一个用户在对应索引上的参数,由于在训练神经网络模型的过程中,不同位置的模型参数具有不同的作用,表现出不同的数值变化,恶意用户的本地模型参数往往在某些位置具有较为明显的差异,对于模型参数逐一进行分析能够更加精确的检测出恶意用户的威胁,并且降低对正常用户训练模型的干扰。类似的,下述的中心点
步骤105,利用均值漂移算法计算步骤104所得的相似度的中心点
均值漂移算法是一种常用的基于密度的聚类算法,对于给定一组的数据点,该算法试图找到这些数据点的密集区域,并且计算出每个密集区域(簇)的中心点作为聚类中心,也就是数据分布的质心(重心)。图4为本发明在实际实验中所得的恶意用户和正常用户在不同训练周期的余弦相似度差异的示意图,每一轮训练中,恶意用户与正常用户的余弦相似度差异明显,而正常用户之间的余弦相似度分布极为近似。本发明利用均值漂移算法,对步骤104所得余弦相似度进行聚类分析,计算出正常用户的余弦相似度分布的聚类中心(图4所示的三角形),从而检测出发动数据操纵攻击的恶意用户。
本发明中实施例中均值漂移算法的输入数据为步骤104所得的每一个用户的相似度
步骤1051,对于给定的每一个中心点ci,搜索其在指定半径r范围内的邻近点集合p,其中,半径r通常设置为一个较小的数值,具体可以视实际情况而定;
步骤1052,计算步骤1051所得的邻近点集合p的平均值
步骤1053,计算中心点ci与平均值
步骤1054,更新中心点
步骤1055,若步骤1053所得的差值小于设定的阈值,通常为0.001·r,则算法终止,返回中心点ci;否则,转到步骤1051;
最终,以所得的中心点ci的众数作为最终的相似度的中心点
步骤106,计算步骤104所得的每个用户对应的相似度
聚集度表示表示相似度
步骤107,利用步骤106所得的聚集度
融合系数
步骤2,判断t是否为0的倍数,若是,转到步骤3;否则,转到步骤101;所述t为用户实际训练轮数,τ为一个训练周期内包含的本地模型参数训练轮数;
步骤3,计算全局模型参数
循环上述训练过程直至训练轮数达到最大迭代次数,全局模型收敛,联邦学习训练结束。
本实施例中的融合系数即为计算全局模型参数时的每一个用户的本地模型参数对应的权重,融合系数的取值在0到1之间,某用户融合系数越大表示该用户的本地模型参数的权重越大。在联邦学习中,全局模型参数的计算公式
本发明将恶意用户和正常用户的共同进行联邦学习的过程视为不同用户之间的博弈过程,用户通过博弈获得一定的收益,所有用户的共同博弈目标是训练得到一个较好的全局模型,而恶意用户还需要实现其数据操纵攻击的目标,即恶意用户期望通过数据操纵攻击获得额外的收益。针对恶意用户的这种不良行为,本发明中所述中心服务器需要其进行一定的惩罚以保证博弈的公平性,即确保所有的用户的收益大致相同。本发明所述的安全训练框架通过对恶意用户的不良行为进行惩罚,降低其融合系数而达到防御数据操纵攻击的目标。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!