一种内容的推荐方法和系统与流程
本申请涉及计算机技术,特别涉及一种内容的推荐方法和系统。
背景技术:
随着短视频、新闻资讯等内容平台的兴起,用户喜欢在闲暇时间通过客户端浏览各种短视频以及新闻app,例如抖音、微视、今日头条等。不同的用户在浏览同一个内容平台的时候,由于兴趣点的不同,平台需要推送不同的内容。另外对于用户来讲,他的兴趣很多时候是在不断变化的,由于短视频以及新闻观看时间短,如果服务器不能在短时间内快速响应用户的兴趣变化,用户的体验就会很差。
不同行业的推荐系统,虽然应用领域、场景不一样,但本质是类似的。所有的推荐系统都需要依靠内容和用户兴趣两个方面的特征来决策具体推荐内容。目前,所有的特征(内容特征、用户兴趣特征)都是在云服务器端做计算的,随着用户量的增加,云服务器的计算压力将会越来越大。随着网速的逐年提升和用户需求的不断增大,采用现有的内容推荐方法将会给云服务器带来越来越大的计算压力,如何减轻云服务器的计算压力,成为新时代急需解决的问题。
技术实现要素:
本申请提供一种内容的推荐方法和系统,能够极大地降低云服务器的计算压力。
为实现上述目的,本申请采用如下技术方案:
一种内容的推荐方法,包括:
智能终端根据用户对观看内容的行为,生成所述观看内容的分值发送给边缘服务器;其中,所述分值用于表示所述用户对所述观看内容的感兴趣程度;
所述边缘服务器接收所述分值后确定所述用户的兴趣特征向量,并从云服务器查询所述观看内容的内容特征向量;根据所述用户的兴趣特征向量、所述观看内容的内容特征向量和所述分值,更新所述用户的兴趣特征向量,并将所述分值和更新后的所述用户的兴趣特征向量发送给所述云服务器;
所述云服务器需要为所述用户推荐网络内容时,利用接收的更新后的所述用户的兴趣特征向量,确定所述云服务器的所有用户簇中与所述用户最匹配的用户簇,将该用户簇对应的内容加入初始推荐队列;
在初始推荐队列中,删除所述用户已经产生过行为的内容,将更新后的初始推荐队列排序后将前n个内容推荐给所述用户;其中,所述n为预设的正整数。
较佳地,在所述云服务器接收所述分值和更新后的所述用户的兴趣特征向量后,该方法进一步包括:
所述云服务器根据接收的所述分值、所述观看内容的内容特征向量和更新前/更新后所述用户的兴趣特征向量,更新所述观看内容的内容特征向量;
所述云服务器在根据所述分值确定所述用户对所述观看内容感兴趣时,利用更新后的所述观看内容的内容特征向量,确定所述云服务器的所有内容簇中与所述观看内容最匹配的内容簇,将该内容簇对应的内容加入初始推荐队列。
较佳地,所述确定所述云服务器的所有用户簇中与所述用户最匹配的用户簇包括:利用更新后的所述用户的兴趣特征向量,计算所述用户与各用户簇中心的距离,找出距离最近的用户簇作为与所述用户最匹配的用户簇。
较佳地,所述确定所述云服务器的所有内容簇中与所述观看内容最匹配的内容簇包括:利用更新后的所述观看内容的内容特征向量,计算所述观看内容与各内容簇中心的距离,找出距离最近的内容簇作为与所述观看内容最匹配的内容簇。
较佳地,当所述用户对所述观看内容感兴趣时,该方法进一步包括:将所述观看内容加入与所述用户最匹配的用户簇对应的内容队列。
较佳地,在更新所述观看内容的内容特征向量后,该方法进一步包括:将所述观看内容从当前所在的内容簇移除,加入与所述观看内容最匹配的内容簇。
较佳地,所述云服务器划分用户簇的方式包括:
所述云服务器根据所有用户的兴趣特征向量,利用k-means算法将所有用户划分成不同的簇,每个簇中不同用户的兴趣特征向量间的差异在第一设定范围内。
较佳地,所述云服务器划分内容簇的方式包括:
所述云服务器根据所有内容的内容特征向量,利用k-means算法将所有内容划分成不同的簇,每个簇中不同内容的内容特征向量间的差异在第二设定范围内。
较佳地,所述边缘服务器接收所述分值后确定所述用户的兴趣特征向量包括:所述边缘服务器在本地查询所述用户的兴趣特征向量,若未查询到,所述边缘服务器从所述云服务器获取所述用户的兴趣特征向量。
一种内容的推荐系统,包括:智能终端、边缘服务器和云服务器;
所述智能终端,用于根据用户对观看内容的行为,生成所述观看内容的分值发送给边缘服务器;其中,所述分值用于表示所述用户对所述观看内容的感兴趣程度;
所述边缘服务器,用于接收所述分值后确定所述用户的兴趣特征向量,并从云服务器查询所述观看内容的内容特征向量;根据所述用户的兴趣特征向量、所述观看内容的内容特征向量和所述分值,更新所述用户的兴趣特征向量,并将所述分值和更新后的所述用户的兴趣特征向量发送给所述云服务器;
所述云服务器,用于在需要为所述用户推荐网络内容时,利用接收的更新后的所述用户的兴趣特征向量,确定所述云服务器的所有用户簇中与所述用户最接近的用户簇,将该用户簇对应的内容加入初始推荐队列;还用于在初始推荐队列中,删除所述用户已经产生过行为的内容,将更新后的初始推荐队列排序后将前n个内容通过所述智能终端推荐给所述用户;其中,所述n为预设的正整数。
较佳地,所述云服务器包括:接收单元、学习单元、存储单元和推荐引擎单元;
所述接收单元,用于接收所述分值和更新后的所述用户的兴趣特征向量;
所述学习单元,用于根据所述分值、所述存储单元保存的所述观看内容的内容特征向量和更新前/更新后所述用户的兴趣特征向量,更新所述观看内容的内容特征向量,并将更新后的所述观看内容的内容特征向量保存在所述存储单元中;
所述存储单元,用于保存所有用户的兴趣特征向量和所有内容的内容特征向量;
所述推荐引擎单元,用于在需要为所述用户推荐网络内容时,利用接收的更新后的所述用户的兴趣特征向量,确定所述云服务器的所有用户簇中与所述用户最接近的用户簇,将该用户簇对应的内容加入初始推荐队列;还用于在根据所述分值确定所述用户对所述观看内容感兴趣时,利用更新后的所述观看内容的内容特征向量,确定所述云服务器的所有内容簇中与所述观看内容最接近的内容簇,将该内容簇对应的内容加入初始推荐队列;还用于在初始推荐队列中,删除所述用户已经产生过行为的内容,将更新后的初始推荐队列排序后将前n个内容推荐给所述用户。
由上述技术方案可见,本申请中,智能终端根据用户对观看内容的行为,生成观看内容的分值发送给边缘服务器;边缘服务器接收分值后确定用户的兴趣特征向量,并从云服务器查询观看内容的内容特征向量;根据用户的兴趣特征向量、观看内容的内容特征向量和分值,更新用户的兴趣特征向量,并将分值和更新后的用户的兴趣特征向量发送给云服务器;云服务器需要为用户推荐网络内容时,利用接收的更新后的用户的兴趣特征向量,确定云服务器的所有用户簇中与用户最匹配的用户簇,将该用户簇对应的内容加入初始推荐队列;在初始推荐队列中,删除用户已经产生过行为的内容,将更新后的初始推荐队列排序后将前n个内容推荐给用户。通过上述处理,将用户兴趣特征向量的更新处理在边缘服务器完成,在云服务器进行内容特征向量的更新与推荐内容的匹配和选择,从而大大减少了云服务器的计算压力。
附图说明
图1为本申请中内容推荐方法的基本流程示意图;
图2为本申请中内容推荐系统的基本结构示意图;
图3为本申请内容推荐方法中智能终端的处理流程图;
图4为本申请内容推荐方法中边缘服务器的处理流程图;
图5为本申请内容推荐方法在云服务器中的处理示意图;
图6为本申请方法在云服务器中的推荐内容流程图;
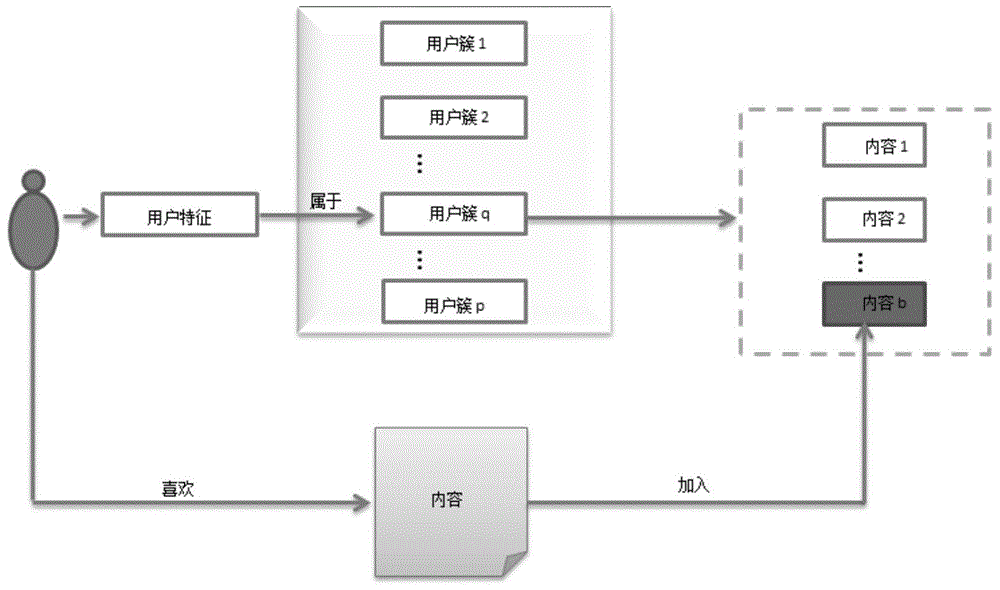
图7为本申请方法在云服务器中用户簇关联内容示意图
图8为本申请方法在云服务器中内容簇的示意图。
具体实施方式
为了使本申请的目的、技术手段和优点更加清楚明白,以下结合附图对本申请做进一步详细说明。
本申请提供的内容推荐方法和系统,通过边缘服务器和云服务器的配合,提供一种新的内容推荐方式。其中,通过边缘服务器计算用户的兴趣特征,云服务器计算内容的特征,并可以通过聚合、过滤、排序等操作为用户提供个性化内容,通过这种将用户兴趣特征的计算下放到边缘服务器的方式,减轻云服务器端的压力,从而快速响应用户的兴趣变化,及时推送用户感兴趣的内容。
图1为本申请中内容推荐方法的基本流程示意图,图2为本申请中内容推荐系统的基本结构示意图。图1可以在图2所示的系统中实施。如图1和图2所示,该方法包括:
步骤101,智能终端根据用户对观看内容的行为,生成观看内容的分值发送给边缘服务器。
本步骤的处理在智能终端完成。当用户a观看内容b(例如短视频)时,智能终端采集用户a对观看内容b的行为,并据此生成分值。其中,分值用于表示用户a对观看内容b的感兴趣程度,也就是用户a对观看内容b的喜爱程度,优选地,分值越大,表明用户a越喜欢观看内容b。
智能终端的处理流程可以如图3所示。具体智能终端的组成可以包括以下四个模块:
1.接收单元
该单元主要用于从云服务器接收云服务器推送给客户端的内容。
2.行为采集单元
该单元主要用于采集用户的行为,比如是否重复观看,是否点赞,是否转发,是否只看了一两秒就离开等。
3.行为转换单元
该单元将用户的行为转换为等级分值,生成该用户对内容的喜爱程度,分值越大,表明用户越喜欢。
4.发送单元
该单元用于客户端将内容分值传送给边缘服务器。
步骤102,边缘服务器接收分值后确定用户a的兴趣特征向量,并从云服务器查询观看内容b的内容特征向量。
其中,用户的兴趣特征向量用于表征一个用户的兴趣特征,可以包括多个方面的兴趣,因此以向量形式表示。内容特征向量用于表征一个内容的具体特征,也可以包括多个方面的特征,因此以向量形式表示。例如当内容为某部电影时,其内容特征向量可以包括电影名称、电影类型、电影主演等。
边缘服务器首先在本地查询用户a的兴趣特征向量,如果本地未查询到,则从云服务器获取用户a的兴趣特征向量。进一步地,边缘服务器还需要从云服务器查询观看内容b的内容特征向量。
步骤103,边缘服务器根据查询到的用户a的旧兴趣特征向量、观看内容b的内容特征向量和接收的分值,更新用户a的兴趣特征向量,并将分值和更新后用户a的新兴趣特征向量发送给云服务器。
本步骤在边缘服务器进行用户a的兴趣特征向量更新。其中,将边缘服务器查询到的用户a的兴趣特征向量称为旧兴趣特征向量,将更新后用户a的兴趣特征向量称为新兴趣特征向量。边缘服务器利用用户a的旧兴趣特征向量、观看内容b的内容特征向量和接收的分值,计算用户a的新兴趣特征向量。具体可以通过协同过滤算法计算新的兴趣特征向量。在计算得到新的兴趣特征向量后,将该兴趣特征向量和边缘服务器接收的分值发送给云服务器,从而使云服务器可以更新并保存用户的兴趣特征向量。
上述步骤102~103的处理在边缘服务器完成,如图4所示,具体边缘服务器可以包括以下三个单元:
1.接收单元
该单元接收来自智能终端的用户a对所看内容b的分值,还从本地查找用户旧的兴趣特征向量,如果没有,再从云服务器端查询用户的旧的兴趣特征向量。
该单元还从云服务器查询用户a所看内容b的内容特征向量。
2.学习单元
该单元通过采集过来的内容分值、内容特征向量和用户旧的兴趣特征向量,通过协同过滤算法,计算出新的用户兴趣特征向量。
3.发送单元
该单元将计算出的用户新的兴趣特征向量,以及收集到的内容分值,发送到云服务器。
步骤104,云服务器需要为用户a推荐网络内容时,利用接收的更新后的用户a的兴趣特征向量,确定云服务器的所有用户簇中与用户a最匹配的用户簇,将该用户簇对应的内容加入初始推荐队列。
其中,在云服务器中将所有用户划分为若干用户簇,同一用户簇中的不同用户,其兴趣相近。同时,在云服务器中还将所有内容划分为若干内容簇,同一内容簇中的不同内容,其特征相近。
优选地,云服务器划分用户簇的方式可以包括:云服务器根据所有用户的兴趣特征向量,利用k-means算法将所有用户划分成不同的簇,每个用户簇中不同用户的兴趣特征向量间的差异在第一设定范围内,这样保证每个用户簇中不同的用户具有类似的兴趣特征向量。每个用户簇对应有一个内容队列,用于保存该簇内用户感兴趣的内容。
优选地,云服务器划分内容簇的方式可以包括:云服务器根据所有内容的内容特征向量,利用k-means算法将所有内容划分成不同的簇,每个簇中不同内容的内容特征向量间的差异在第二设定范围内,这样保证每个内容簇中不同的内容具有类似的内容特征向量。
在为用户a选择推荐内容时,最基本地,基于上述用户簇,可以利用接收的更新后的用户a的兴趣特征向量,确定云服务器的所有用户簇中与用户a最匹配的用户簇,将该用户簇对应的内容加入初始推荐队列。其中,确定与用户a最匹配的用户簇,可以是利用更新后的用户a的兴趣特征向量,计算用户a与各用户簇中心的距离,找出距离最近的用户簇作为与用户a最匹配的用户簇。当然,还可以选择其他现有匹配方式,这里就不再赘述。
通过上述方式可以得到初始推荐队列,这里是最简单的初始推荐队列,接下来可以直接执行步骤106。或者,在以上初始推荐队列的基础上,优选地,还可以通过如下步骤105进一步丰富初始推荐队列,然后再执行步骤106。
步骤105,云服务器根据接收的分值、观看内容b的内容特征向量和更新前用户a的兴趣特征向量,更新观看内容b的内容特征向量;在根据分值确定用户a对观看内容b感兴趣时,利用更新后的观看内容b的内容特征向量,确定云服务器的所有内容簇中与观看内容b最匹配的内容簇,将该内容簇对应的内容加入初始推荐队列。
这里,云服务器接收边缘服务器发来的分值后,首先更新观看内容b的内容特征向量。具体地,根据接收的分值、观看内容b的内容特征向量和更新前用户a的兴趣特征向量,更新观看内容b的内容特征向量。
在更新内容特征向量后,若根据分值确定用户a对观看内容b感兴趣,则利用更新后的观看内容b的内容特征向量,确定云服务器的所有内容簇中与观看内容b最匹配的内容簇,将该内容簇对应的内容加入初始推荐队列。其中,确定与观看内容b最匹配的内容簇,可以是利用更新后的观看内容b的内容特征向量,计算观看内容b与各内容簇中心的距离,找出距离最近的内容簇作为与观看内容b最匹配的内容簇。
另外进一步优选地,当用户a对观看内容b感兴趣时,还可以进一步将观看内容b加入与用户a最匹配的用户簇对应的内容队列,并将观看内容b从当前所在的内容簇移除,加入与观看内容b最匹配的内容簇。
步骤106,在初始推荐队列中,删除用户a已经产生过行为的内容,将更新后的初始推荐队列排序后将前n个内容推荐给用户a。
本步骤的处理在云服务器中进行。对于初始推荐队列进行过滤,去除用户a已经产生过行为的内容。进一步地,可以对更新后的初始推荐队列进行排序,具体排序依据可以根据需要设定,例如按照新颖性、流行度和多样性等进行排序。最后将初始推荐队列中的前n个内容推荐给用户a,也就是发送给智能终端。
上述步骤104~106的处理在云服务器完成,用于计算内容特征向量的算法模型,以及推荐模型,如图5所示。具体云服务器可以包括以下五个单元:
1.接收单元
该单元接收来自边缘服务器的用户对所看内容的分值和用户新的兴趣特征向量。
2.学习单元
该单元根据边缘服务器传过来的用户对内容的分值、用户兴趣特征向量,以及旧的内容特征向量,根据协同过滤算法,学习出新的内容特征向量。其中,在更新内容特征向量时使用的用户兴趣特征向量可以是用户旧的兴趣特征向量,也可以是用户新的兴趣特征向量,根据实验表明,使用用户旧的兴趣特征得到的新的内容特征向量更加准确。
3.存储单元
该单元存储用户兴趣特征向量,以及内容特征向量。
4.推荐引擎单元
该根据所有用户兴趣特征向量,用k-means算法将用户分为p个簇,每个簇有类似的兴趣特征向量;根据内容特征向量,用k-means算法将内容分为k个簇,每个簇的内容有相类似的特性向量。
当给用户a推荐内容时,该单元利用边缘服务器发送过来的用户新的兴趣特征向量,计算用户a和所有p个用户簇中心的距离,找出距离最近的用户簇q,将用户簇q对应的内容放入初始推荐队列。如图6所示。
根据接收单元接收到的用户a对内容d的喜欢程度分值,确定用户a是否喜欢内容d,若喜欢,则用云端服务器学习单元计算出的内容d的新的内容特征向量,计算内容d和所有k个内容簇中心的距离,找出距离最近的内容簇e,将内容簇e对应的内容加入初始推荐队列。如图6所示。
如果用户a喜欢内容b,用边缘服务器发送过来的用户新的兴趣特征向量,计算用户a和p个用户簇中心的距离,找出距离最近的用户簇q,将内容b放入用户簇q相关联的内容队列。如图7所示。
用云端服务器学习单元计算出的内容d的新的特征向量,计算内容d和k个内容簇中心的距离,找出距离最近的内容簇e,将内容d从原来所在的内容簇移除,放入内容簇e相关联的内容队列。如图8所示。
对初始推荐队列过滤,去除用户a已经产生过行为的内容;对初始推荐队列排序,根据新颖性,流行度,多样性对内容进行排序;将初始推荐队列的前n个内容放入最终推荐队列。
至此,本申请中的内容推荐方法流程结束。通过上述本申请的处理,每一个智能终端给边缘服务器传送用户对内容(例如短视频)的评分,边缘服务器基于机器学习算法,完成用户新的兴趣特征向量的学习,云服务器不再需要计算用户兴趣特征向量,只需要根据边缘服务器传送过来的新的用户兴趣特征向量,根据推荐算法,给用户推送新的内容(例如短视频),优化响应时间。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!