一种基于词向量的中文年报标题分类方法与流程
发明涉及标题分类技术领域,具体为一种基于词向量的中文年报标题分类方法。
背景技术:
随着网络技术的发展,以及互联网的普及,人们进入到了信息时代。在这个时代里,各种各样的信息充斥着人们的生活,人们在每天的工作学习中,都要面对数不胜数的新闻、微博、报告即使这样,信息还是在爆炸式地增长,因此对这些海量的数据进行信息抽取显得十分必要。
在金融领域,每天也同样会产生大量的文本数据,其中就包括企业年报。年报是企业的法定义务,企业通过年报向社会提供企业的基本信息,有利于社会公众和交易相对人了解企业,并让国家相关管理部门可以及时掌握企业的状况。企业年报是投资者重要的参考材料,抽取其中的重要信息十分关键,可以对市场、企业、投资方产生重要影响。各企业的年报虽然在格式上有相似的地方,但也存在些许差异,这给我们对企业年报进行研究带来了困难。因此,如果能对企业年报的标题进行抽取,有利于我们了解整篇年报的文章结构,对于将企业年报规范化也有着重要意义,传统的人工提取方式需要耗费巨大的人力和时间成本,而词向量的抽取方法效果差,准确力低。
技术实现要素:
针对现有技术的不足,发明提供了一种基于词向量的中文年报标题分类方法,解决了传统的人工提取方式需要耗费巨大的人力和时间成本,而词向量的抽取方法效果差,准确力低的问题。
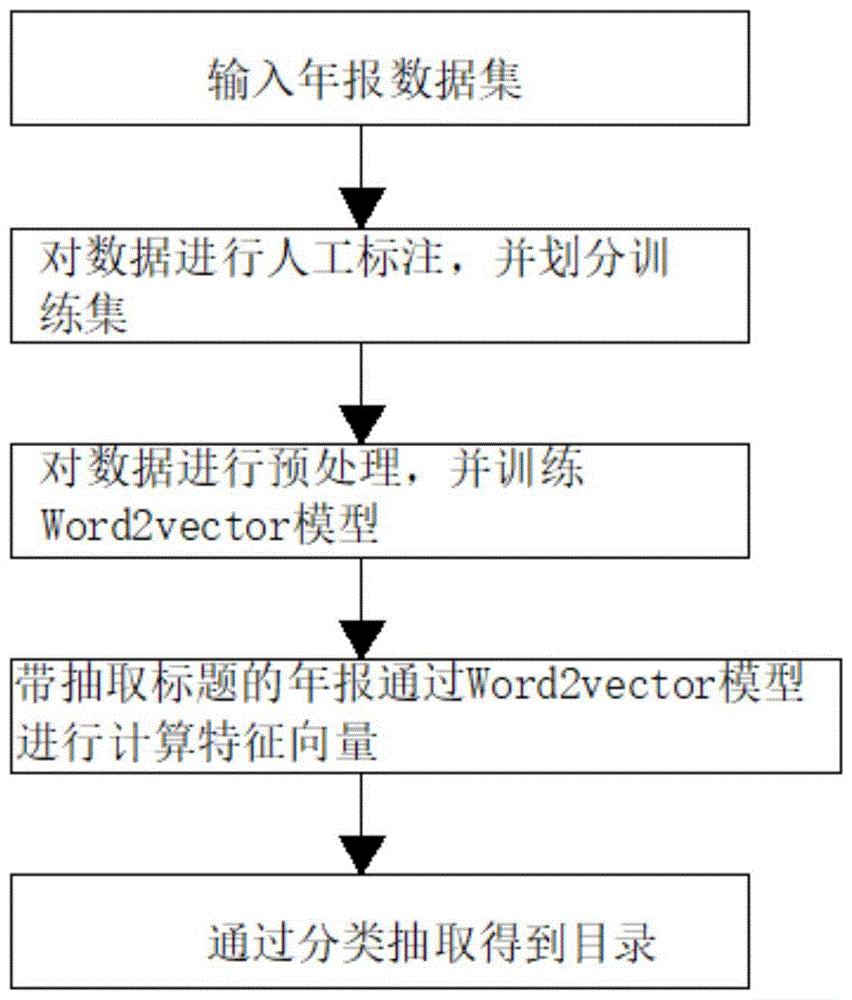
为实现以上目的,发明通过以下技术方案予以实现:一种基于词向量的中文年报标题分类方法,具体步骤为:
步骤1、输入企业年报数据集;
步骤2、对数据进行人工标注,并划分训练集;
步骤3、对数据进行预处理,并训练word2vector模型;
步骤4、待抽取标题的年报通过word2vector模型进行计算特征向量;
步骤5、通过分类抽取得到目录。
优选的,步骤3预处理具体为分词和去掉停用词。
优选的,步骤3中word2vector模型采用cbow模型,具体步骤为:
a、定窗口大小k,将窗口内除中心词wt外的所有词语分别生成独热向量;
b、将输入权重矩阵与独热向量相乘,得到每个词语的输入向量;
c、计算这2k个上下文词语词向量的平均值;
d、通过输出词向量矩阵乘以上下文词向量得到一个分数向量;
e、利用函数将分数向量转化为概率分布;
f、利用交叉熵作为损失函数,通过随机梯度下降算法优化输入权重矩阵和输出词向量矩阵。
优选的,步骤a中独热向量可通过对词语的词典序进行独热编码生成。
优选的,步骤e中所述函数具体为softmax函数。
优选的,步骤c中所述平均值用以表示上下文词向量。
有益效果
发明提供了一种基于词向量的中文年报标题分类方法。具备以下有益效果:
该基于词向量的中文年报标题分类方法,通过word2vec模型将每个词转化为向量,并用平均值代表标题的特征向量,最后通过支持向量机分类算法对标题进行分类识别,通过标题的识别对年报的架构进行划分,进一步提取出人们最想关注的重点,可以对企业年报进行规范化,统一相似标题,方便人们阅读和进一步的信息抽取,解决了传统的人工提取方式需要耗费巨大的人力和时间成本,而词向量的抽取方法效果差,准确力低的问题。
附图说明
图1为本发明基于词向量的中文年报标题分类方法的流程图。
具体实施方式
下面将结合发明实施例中的附图,对发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是发明一部分实施例,而不是全部的实施例。基于发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于发明保护的范围。
请参阅图1,发明提供一种技术方案:一种基于词向量的中文年报标题分类方法,具体步骤为:
步骤1、输入企业年报数据集;
步骤2、对数据进行人工标注,并划分训练集;
步骤3、对数据进行预处理,并训练word2vector模型;
步骤4、待抽取标题的年报通过word2vector模型进行计算特征向量;
步骤5、通过分类抽取得到目录。
进一步地,步骤3预处理具体为分词和去掉停用词。
进一步地,步骤3中word2vector模型采用cbow模型,具体步骤为:
a、定窗口大小k,将窗口内除中心词wt外的所有词语分别生成独热向量;
b、将输入权重矩阵与独热向量相乘,得到每个词语的输入向量;
c、计算这2k个上下文词语词向量的平均值;
d、通过输出词向量矩阵乘以上下文词向量得到一个分数向量;
e、利用函数将分数向量转化为概率分布;
f、利用交叉熵作为损失函数,通过随机梯度下降算法优化输入权重矩阵和输出词向量矩阵。
进一步地,步骤a中独热向量可通过对词语的词典序进行独热编码生成。
进一步地,步骤e中函数具体为softmax函数。
进一步地,步骤c中平均值用以表示上下文词向量。
一种基于词向量的中文年报标题分类方法,具体步骤为:步骤1、输入企业年报数据集;步骤2、对数据进行人工标注,并划分训练集;步骤3、对数据进行预处理,步骤3预处理具体为分词和去掉停用词,并训练word2vector模型;步骤4、待抽取标题的年报通过word2vector模型进行计算特征向量;步骤5、通过分类抽取得到目录;
步骤3中word2vector模型采用cbow模型,具体步骤为:a、定窗口大小k,将窗口内除中心词wt外的所有词语分别生成独热向量;b、将输入权重矩阵与独热向量相乘,得到每个词语的输入向量;c、计算这2k个上下文词语词向量的平均值;d、通过输出词向量矩阵乘以上下文词向量得到一个分数向量;e、利用函数将分数向量转化为概率分布;f、利用交叉熵作为损失函数,通过随机梯度下降算法优化输入权重矩阵和输出词向量矩阵,步骤a中独热向量可通过对词语的词典序进行独热编码生成,步骤e中函数具体为softmax函数,步骤c中平均值用以表示上下文词向量。
通过word2vec模型将每个词转化为向量,并用平均值代表标题的特征向量,最后通过支持向量机分类算法对标题进行分类识别,通过标题的识别对年报的架构进行划分,进一步提取出人们最想关注的重点,可以对企业年报进行规范化,统一相似标题,方便人们阅读和进一步的信息抽取。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!