一种基于深度随机博弈的空战机动策略生成技术的制作方法
本发明涉及空战博弈机动策略生成技术领域,特别设计一种基于深度随机博弈的空战机动策略生成技术。
背景技术:
空中力量在现代战争中起着越来越重要的作用,制空权的争夺很大程度上决定了战争的胜负。然而空中作战形势瞬息万变,需要采集的信息极为复杂,使得作战方在感知空战态势后做出决策变得困难,传统方法无法实现一种快速准确的空战策略。本发明提出了一种基于深度随机博弈的空战机动策略生成技术,该方法结合了深度强化学习和随机博弈的思想,能够有效地针对空战对手的行动策略实时地选择有利于我方的机动动作并取得优势地位,对空战博弈对抗中制空权的争夺具有重要意义。
技术实现要素:
本发明提供了一种基于深度随机博弈的空战机动策略生成技术,旨在感知空战态势后快速准确地获取一种能有效对抗对手的最优机动策略。
实现本发明的技术方案为:一种基于深度随机博弈的空战机动策略生成技术,包括如下步骤:
s1:根据飞机的运动学和动力学方程,构建双方战机的运动模型,结合空战规则,建立智能体的训练环境,并设置敌方机动策略;
s2:构建基于随机博弈和深度强化学习的红蓝双方智能体,确定每个智能体的状态空间、动作空间和奖励函数;
s3:使用随机博弈与深度强化学习相结合的极大极小值dqn算法构建神经网络,并训练红方智能体;
s4:在空战博弈中,训练完成的红方智能体通过感知当前的空战态势,实时地生成最优机动策略,与蓝方进行博弈对抗,引导战机在空战中占据有利的态势位置。
作为优选的技术方案,步骤s3中,所述极大极小值dqn算法训练智能体的过程包括:
s301:利用dqn处理战机的连续无限状态空间,创建两个神经网络,分别为当前q网络和目标q网络,初始化当前q网络参数为θ,目标q网络参数为θ-=θ。神经网络的输入为战机的状态特征,输出为该状态下所有红方可选动作a与蓝方可选动作o对应的状态动作值函数q(s,a,o);
s302:将智能体与环境交互得到的当前状态s、红方采取的动作a、蓝方采取的动作o、红方获取的奖励值r以及执行动作到达的下一状态s'作为一个五元组{s,a,o,r,s'}存储到记忆池;
s303:从记忆池中随机抽取一定大小的数据作为训练样本,将训练样本的s'值作为神经网络的输入,根据神经网络输出得到状态s'下的q[s'];
s304:采用极大极小值算法求解随机博弈状态s下的最优值函数为
s305:计算损失函数loss=(target_q-q(s,a,o,θ))2,采用梯度下降法进行优化,更新当前q网络参数。
作为优选的技术方案,步骤s4中,所述生成最优机动策略的方法是根据公式
本发明相对于现有技术具有如下的优点和效果:
1.本发明利用基于深度强化学习的技术,大大提高了计算效率,能够在5ms内生成一条指令,保证了策略生成的实时性。
2.本发明构建仿真环境,引入深度强化学习等方法探索一种近距空战机动策略智能生成技术,通过搭建面向深度强化学习的仿真环境,利用dqn算法训练网络生成指令,具有较高的适应性和智能性。
3.本发明结合随机博弈的思想,通过极大极小值算法求纳什均衡解,与传统方法相比,能够更加准确地针对对手可能执行的最优决策来选择自己的机动策略,从而可以有效应对高决策水平的对手,提高了我方博弈对抗的胜率。
附图说明
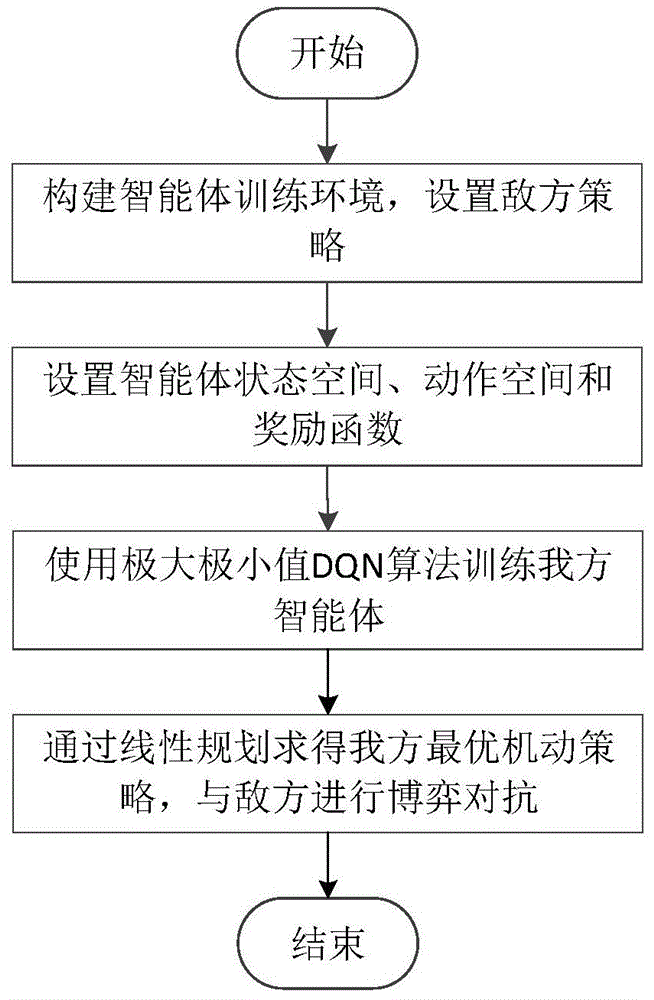
图1为本发明实施例的步骤流程图;
图2为本发明实施例的红蓝双方战机相对几何关系图;
图3为本发明实施例的极大极小值dqn算法训练过程示意图;
图4为本发明实施例的极大极小值dqn算法流程图;
具体实施方式
为了使本发明的目的、技术方案以及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
在本实施例中,红蓝双方战机进行1v1近距空战机动博弈,一种基于深度随机博弈的空战机动策略生成技术,智能化生成机动策略,引导红方战机在空战中到达有利态势位置;如图1所示,该方法包括下述步骤:
s1:根据飞机的运动学和动力学方程,构建双方战机的运动模型,结合空战规则,建立智能体的训练环境,并设置敌方机动策略;
s2:构建基于随机博弈和深度强化学习的红蓝双方智能体,确定每个智能体的状态空间、动作空间和奖励函数;
s3:使用随机博弈与深度强化学习相结合的极大极小值dqn算法构建神经网络,并训练红方智能体;
s4:在空战博弈中,训练完成的红方智能体通过感知当前的空战态势,实时地生成最优机动策略,与蓝方进行博弈对抗,引导战机在空战中占据有利的态势位置。
所述步骤s1具体包括以下步骤:
在本实施例中,设定空战博弈的环境,空域范围限制在水平面内,水平面横坐标x∈[-10km,10km],水平面纵坐标y∈[-10km,10km]。根据飞机的运动学和动力学方程,构建战机的运动模型如下:
其中,(xpos,ypos)表示战机在坐标系下的位置,υ表示战机速度,ψ表示航迹偏角,φ和
在本实施例中,红方战机的目标是在蓝方战机背后取得并保持优势地位,使用视界角(aa)和天线偏转角(ata)来量化这个优势位置,航向交叉角(hca)也用于描述红蓝战机之间的朝向差异。红蓝双方战机相对几何关系如图2所示。
所述步骤s2具体包含以下步骤:
根据影响战机空战态势的因素,构建红蓝双方基于随机博弈的状态空间为
在本实施例中,战机的可选机动动作设置为向左滚转、维持滚转和向右滚转,分别用l,s,r代表这3种可选动作,构建离散的动作空间,红方的动作空间为ar={l,s,r},蓝方动作空间为ab={l,s,r};
在本实施例中,战机的优势奖励函数主要根据视界角(aa)和天线偏转角(ata)来量化。战机占据有利态势需要满足的要求如下:
其中,d表示红蓝双方战机的欧氏距离,dmin和dmax分别表示满足优势态势的最小与最大距离,本实施例中分别为100米和500米,aa表示战机的视界角,其绝对值应小于aamax,本实施例中为60度,ata表示战机的天线偏转角,其绝对值应小于atamax,本实施例中为30度。同时满足上式三个条件则判定战机取得优势,并获得奖励值r=1,若取得优势地位的是敌方,则战机获取的奖励值r=-1,此外其他情况判定为平局且战机获取奖励值r=0。
所述步骤s3具体包含以下步骤:
s301:利用dqn处理战机的连续无限状态空间,创建两个神经网络,分别为当前q网络和目标q网络,初始化当前q网络参数为θ,目标q网络参数为θ-=θ。神经网络的输入为战机的状态特征,输出为该状态下所有红方可选动作a与蓝方可选动作o对应的状态动作值函数q(s,a,o);
s302:将智能体与环境交互得到的当前状态s、红方采取的动作a、蓝方采取的动作o、对应的奖励值r以及执行动作到达的下一状态s'作为一个五元组{s,a,o,r,s'}存储到记忆池,设置记忆库存储上限为100000组数据;
s303:从记忆池中随机抽取256组数据作为一个训练样本,将训练样本的s'值作为神经网络的输入,根据神经网络输出得到状态s'下的q[s'];
s304:采用极大极小值算法求解随机博弈状态s下的最优值函数为
s305:计算损失函数loss=(target_q-q(s,a,o,θ))2,采用梯度下降法进行优化,更新q网络参数。
极大极小值dqn训练过程示意图如图3所示,极大极小值dqn算法流程图如图4所示。
所述步骤s4具体包含以下步骤:
根据公式
本发明的上述算例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!