基于强化学习的对抗性视频时刻检索方法、装置、计算机设备和存储介质与流程
【技术领域】
本发明涉及视频时刻检索领域,尤其涉及一种基于强化学习的对抗性视频时刻检索方法、装置、计算机设备和存储介质。
背景技术:
视频检索,旨在从一组可能的视频集合中检索与查询语句文本所描述语义最相关的视频。由于现代生活节奏的加快和信息的不断增加,迫切需要快速找到最符合人们实际需求的相关信息,特别是在视频领域,人们已经越来越更希望浏览一个与他们的兴趣相匹配的短视频时刻而不是整个视频。为了满足这一需求,出现了在语言查询下的视频时刻检索任务,其目的是定位与查询语句语义最相关视频时刻的开始点和结束点。
现有的视频时刻检索方法,如“通过语言查询的视频时刻定位”,其主要的步骤有:1、抽取视频片段特征和查询语句的特征;2、将视频片段特征和查询语句进行多模态处理,得到更丰富的语义信息;3、多层感知机分别预测视频和句子的匹配度分数和时间偏置。此方法是基于查询语句,从候选集合中选出最匹配的视频片段并增加时间偏置,其中候选集是通过滑动窗口策略切分生成的,然而为了满足定位的精确性,这种策略往往需要密集的切分,所以非常耗时,无法满足动态查询的需求,这要求视频片段的长度是变长的而不是固定的。另一方面,使用时间偏置虽然可以使定位不受限于窗口的大小,但是对偏置的预测不够稳定反而会损害到返回给查询的视频片段质量。
还有通过“阅读、观察和移动:视频中根据自然语言描述的时刻定位强化学习”,主要的步骤有:1、输入完整视频和查询语句成为强化学习代理的环境;2、抽取视频全局特征,视频片段特征,视频片段定位信息和查询文本的特征构成当前时刻的状态;3、强化学习代理根据当前状态输出对定位边界移动的动作,不断重复直至定位逐渐收敛。基于强化学习实现视频时刻定位的工作是引入强化学习的第一份工作,它能摆脱对于滑动窗口候选的依赖,实现更精准的定位。但是对代理奖励的设计却没有太多的探索。现有基于强化学习的方法借助每次定位边界移动前后的交并比(iou)来计算,这是缺乏语义探索的并且固定的奖励值导致模型缓慢和不稳定的收敛。
总结来说,现有的两大类处理视频时刻检索的方法主要有两大类:基于滑动窗口候选集的排序方法和基于强化学习的定位方法以及基于滑动窗口候选集的排序方法是预先使用滑动窗口的策略将视频进行切分生成候选集,然后对候选集进行与查询文本的匹配,根据匹配度排序得到结果。显然这种方法产生了过多的片段,耗时较长,所以有学者引入强化学习把问题抽象成了一个连续性决策问题去直接定位(视频的开始帧和结束帧),尽管他们也取得了很好的效果,但对代理的奖励设计却没有太多的探索,这些方法往往不是稳定的。
基于滑动窗口候选集的排序方法和基于强化学习的定位方法各有利弊,排序方法擅长对众多视频时刻候选进行排序,但无法形成一定数量的合理候选集耗时过大,而定位方法则利用强化学习代理来控制来定位边界,但不能应用于大规模检索场景效率较低。
因此,有必要提供一种改进的视频时刻检索方法以解决上述问题。
技术实现要素:
本发明克服了现有技术的不足,提供了一种基于强化学习的对抗性视频时刻检索方法、装置、计算机设备和存储介质。
为达到上述目的,本发明解决其技术问题所采用的技术方案:提供一种基于强化学习的对抗性视频时刻检索方法,包括如下步骤:
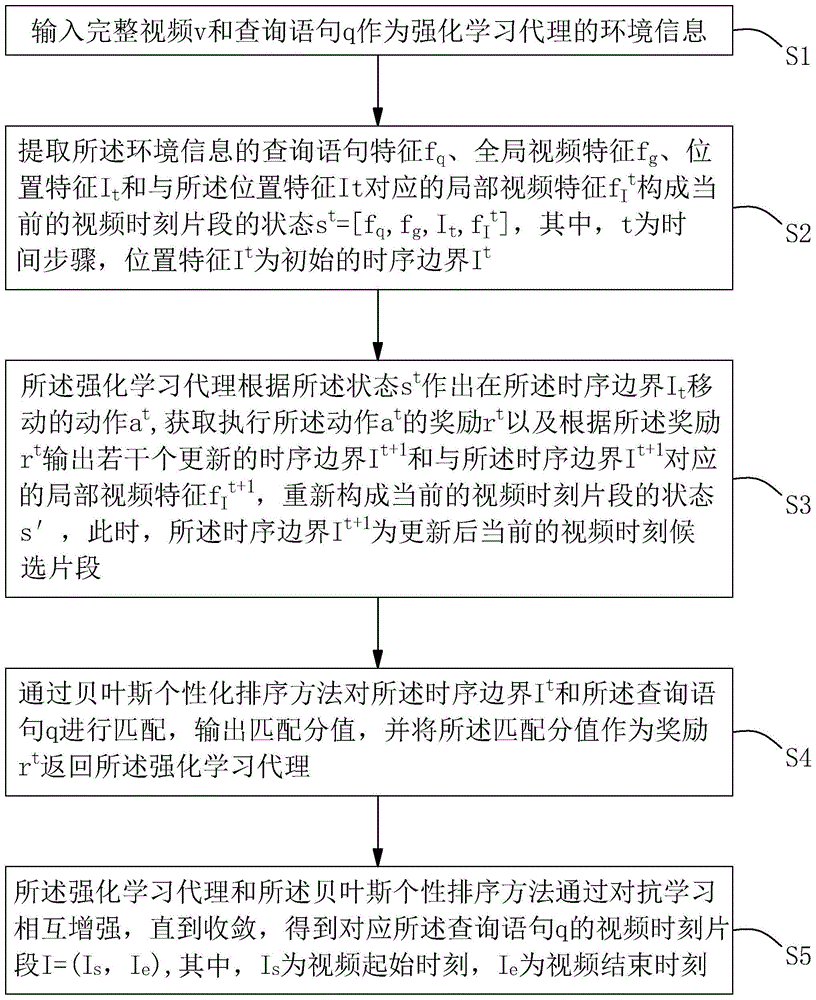
s1:输入完整视频v和查询语句q作为强化学习代理的环境信息;
s2:提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it;
s3:所述强化学习代理根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s',此时,所述时序边界it+1为更新后当前的视频时刻候选片段;
s4:通过贝叶斯个性化排序方法对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
s5:所述强化学习代理和所述贝叶斯个性排序方法通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
优选的,在步骤s3中,还包括:通过深度确定性策略梯度算法更新所述强化学习代理以输出若干个更新的时序边界it+1,所述深度确定性策略梯度算法由评论家网络、演员网络、评论家网络参数滞后网络以及演员网络参数滞后网络构成,所述评论家网络根据所述奖励rt判断所述动作at是否为最优动作,所述演员网络用于执行所述最优动作以获得更新的时序边界lt+1,所述评论家网络参数滞后网络以及所述演员网络参数滞后网络通过软更新方法更新各自滞后网络的参数。
优选的,所述评论家网络通过最小化损失函数l来学习与最优策略π对应的动作值函数q(s,a):
l(ω)=es,a,r,s'~m[(q(s,a|ω)-r+γmaxq*(s',a'|ω*))2]
其中,q(s,a)是所述评论家网络的动作值函数,ω是所述动作值函数q(s,a)的变化参数,γ是所述动作值函数q(s,a)的折扣因子,用于平衡所述奖励rt和所述动作值函数q(s,a)的预估值之间的重要性,q*是预设的参数滞后网络,ω*是q*的变化参数,[s,a,r,s']均从记忆库m中采样获得,以从过去的经验中获得启示,s是未更新的视频时刻片段的状态,a是未更新的动作,a'是更新后的动作,当所述动作值函数q(s,a)最逼近所述最优策略π时,所述强化学习代理将获得最大奖励。
优选的,所述演员网络执行动作a=π(s;θ)更新所述时序边界it,通过损失函数j求所述动作值函数q(s,a)增大方向的导数,以使所述动作值函数q(s,a)取得最大值,求导后的策略梯度为:
其中,μ为确定性策略梯度,θ为所述确定性策略梯度μ的参数。
优选的,在步骤s4中,包括:
s41:所述查询语句q包括标记的真实视频时刻τ=(τs、τe),提取所述查询语句q、时序边界it和真实视频时刻τ的特征,其中,τs为标记的真实视频起始时刻,τe为标记的真实视频结束时刻;
s42:通过预设公共空间以及所述查询语句q的特征、时序边界it的特征和所述真实视频时刻τ的特征获取所述查询语句q的映射函数、时序边界it的映射函数以及所述真实视频时刻τ的映射函数;
s43:通过元素级乘法、元素级加法和全连接获取所述查询语句q的映射函数和所述时序边界it的映射函数结合函数以及所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数;
s44:根据所述查询语句q的映射函数和所述时序边界it的映射函数结合函数以及根据所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数,输出更新的时序边界it中接近所述真实视频时刻τ的匹配分值。
优选的,在步骤s5中,包括:
s51:获取所述时序边界和所述真实视频时刻τ的交并比;
s52:根据所述交并比及所述查询语句q和所述时序边界it的映射函数得出联合损失函数;
s53:通过所述贝叶斯个性化排序方法的损失结合所述联合损失函数得出所述最大奖励r;
s54:通过所述强化学习代理输出所述最大奖励时的时序边界i=(is,ie)。
优选的,所述强化学习代理的参数θ和所述贝叶斯个性化排序方法的参数
其中,k为所述更新的所述时序边界的总数量,lsc为所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数。
本发明还提供一种基于强化学习的对抗性视频时刻检索装置,其特征在于,所述装置包括:
输入模块,所述输入模块用于输入完整视频v和查询语句q作为强化学习代理的环境信息;
提取特征模块,所述提取特征模块用于提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it;
候选集生成模块,所述候选集生成模块用于根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s',此时,所述时序边界it+1为更新后当前的视频时刻候选片段;
贝叶斯个性化排序鉴别模块,所述贝叶斯个性化排序鉴别模块用于对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
对抗学习模块,所述对抗学习模块用于通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现以下步骤:
输入完整视频v和查询语句q作为强化学习代理的环境信息;
提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it;
所述强化学习代理根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s',此时,所述时序边界it+1为更新后当前的视频时刻候选片段;
通过贝叶斯个性化排序方法对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
所述强化学习代理和所述贝叶斯个性排序方法通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
输入完整视频v和查询语句q作为强化学习代理的环境信息;
提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it;
所述强化学习代理根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s',此时,所述时序边界it+1为更新后当前的视频时刻候选片段;
通过贝叶斯个性化排序方法对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
所述强化学习代理和所述贝叶斯个性排序方法通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
相较于现有技术,本发明提供的基于强化学习的对抗性视频时刻检索方法、装置、计算机设备及存储介质具有以下有益效果:通过结合强化学习定位和贝叶斯个性化排序方法的结合,一方面能使基于排序的方法得到小数量的、合理的候选集,另一方面使强化学习定位方法得到更灵活的奖励函数,更稳定的收敛,再通过在对抗学习的框架下使排序和定位的方法相互增强,返回更精确的视频时刻片段,有效提高用户的查询检索的准确度和速度。
【附图说明】
图1为本发明提供的基于强化学习的对抗性视频时刻检索方法的流程图;
图2为本发明提供的基于强化学习的对抗性视频时刻检索方法的原理示意图;
图3为图1中步骤s4中的子流程图;
图4为图1中步骤s5中的子流程图;
图5为本发明提供的对抗性视频时刻检索装置的功能框图;
图6为本发明提供的计算机设备的内部结构图。
【具体实施方式】
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请结合参阅图1和图2,本发明提供一种基于强化学习的对抗性视频时刻检索方法,所述方法包括如下步骤:
s1:输入完整视频v和查询语句q作为强化学习代理的环境信息。
s2:提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it。
s3:所述强化学习代理根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s',此时,所述时序边界it+1为更新后当前的视频时刻候选片段。
所述强化学习代理的动作空间ae由7个预定义的动作组成,即所述动作at的起点和终点均向前移动、起点和终点均向后移动、起点或终点的其中一个单独向前或向后移动以及所述动作at停止移动。
具体的,所述强化学习代理移动的初始位置设置为i0=[0.25*h,0.75*h],其中h为所述完整视频v中图像帧的总长度,所述动作at每步的移动大小设置为h/2∈,其中∈是一个确定的超参数,其用于定义所述强化学习代理的最大搜索步数,这样可以保证在最大步数遍历所述完整视频v。
在本实施例中,通过深度确定性策略梯度算法更新所述强化学习代理以输出若干个更新的时序边界it+1,所述深度确定性策略梯度算法由评论家网络、演员网络、评论家网络参数滞后网络以及演员网络参数滞后网络构成,所述评论家网络根据所述奖励rt判断所述动作at是否为最优动作,所述演员网络用于执行所述最优动作以获得更新的时序边界it+1,所述评论家网络参数滞后网络以及所述演员网络参数滞后网络通过软更新方法更新各自滞后网络的参数。
需要说明的是,所述深度确定性策略梯度算法使用函数逼近的深层神经网络,有效利用经验回放和双目标滞后网络的实现,所述评论家网络通过最小化损失函数l来学习与最优策略π对应的动作值函数q(s,a):
l(ω)=es,a,r,s'~m[(q(s,a|ω)-r+γmaxq*(s',a'|ω*))2]
其中,q(s,a)是所述评论家网络的动作值函数,ω是所述动作值函数q(s,a)的变化参数,γ是所述动作值函数q(s,a)的折扣因子,用于平衡所述奖励rt和所述动作值函数q(s,a)的预估值之间的重要性,q*是预设的参数滞后网络,ω*是q*的变化参数,[s,a,r,s']均从记忆库m中采样获得,以从过去的经验中获得启示,s是未更新的视频时刻片段的状态,a是未更新的动作,a'是更新后的动作,当所述动作值函数q(s,a)最逼近所述最优策略π时,所述强化学习代理将获得最大奖励。
所述演员网络执行动作a=π(s;θ)更新所述时序边界it,通过损失函数j求所述动作值函数q(s,a)增大方向的导数,以使所述动作值函数q(s,a)取得最大值,求导后的策略梯度为:
其中,μ为确定性策略梯度,θ为所述确定性策略梯度μ的参数,所述演员网络通过直接调整θ以最大限度地实现所述动作值函数q(s,a)取得最大值。
s4:通过贝叶斯个性化排序方法对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
请参阅图3,在步骤s4中,包括如下步骤:
s41:所述查询语句q包括标记的真实视频时刻τ=(τs、τe),提取所述查询语句q、时序边界it和真实视频时刻τ的特征,分别为fq、fi和fτ,其中,τs为标记的真实视频起始时刻,τe为标记的真实视频结束时刻;
s42:通过预设公共空间以及所述查询语句q的特征、时序边界it的特征和所述真实视频时刻τ的特征获取所述查询语句q的映射函数、时序边界it的映射函数以及所述真实视频时刻τ的映射函数。
具体的,在语义一致性的约束下,将fq、fl和fτ投影倒所述公共空间中,从而使不同模态正则化,有效提高检索性能:
其中,ov和ol是多层感知器近似的投影函数,
s43:通过元素级乘法、元素级加法和全连接获取所述查询语句q的映射函数和所述时序边界it的映射函数结合函数以及所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数:
s44:根据所述查询语句q的映射函数和所述时序边界it的映射函数结合函数以及根据所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数,输出更新的时序边界it中接近所述真实视频时刻τ的匹配分值。
其中,所述真实视频时刻τ与查询语句q的匹配度要比所述时序边界it与所述查询语句q的匹配度要高,优化方式为:
其中,σ是sigmoid激活函数,os是多层感知器近似的分数,δ是控制两者之间差距的超参数,通过以上方式,正例对的匹配分值能够大于负例对的匹配分值,这有效地区分了所述真实视频时刻τ与所述时序边界it的差别,正例对指所述真实视频时刻τ与所述查询语句q,负例对指所述时序边界it与所述查询语句q。
s5:所述强化学习代理和所述贝叶斯个性排序方法通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie)。
请参阅图4,在步骤s5中,包括如下步骤:
s51:获取所述时序边界it和所述真实视频时刻τ的交并比;
s52:根据所述交并比及所述查询语句q和所述时序边界it的映射函数得出联合损失函数,
s53:通过所述贝叶斯个性化排序方法的损失结合所述联合损失函数得出所述最大奖励r:
r=-lbpr-λslsc+λjljoint
s54:通过所述强化学习代理输出所述最大奖励时的时序边界i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
在本实施例中,所述强化学习代理的参数θ所述贝叶斯个性化排序方法的参数
其中,k为所述更新的所述时序边界it的总数量,lsc为所述查询语句q的映射函数和所述真实视频时刻τ的映射函数结合函数。
上述基于强化学习的对抗性视频时刻检索方法,通过结合强化学习定位和贝叶斯个性化排序方法的结合,一方面能使基于排序的方法得到小数量的、合理的候选集,另一方面使强化学习定位方法得到更灵活的奖励函数,更稳定的收敛,再通过在对抗学习的框架下使排序和定位的方法相互增强,返回更精确的视频时刻片段,有效提高用户的查询检索的准确度和速度。
应该理解的是,虽然图1、图3和图4的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1、图3和图4中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
在实施例中,请参阅图5,提供了一种基于强化学习的对抗性视频检索装置,所述装置包括:
输入模块100,所述输入模块100用于输入完整视频v和查询语句q作为强化学习代理的环境信息;
提取特征模块200,所述提取特征模块200用于提取所述环境信息的查询语句特征fq、全局视频特征fg、位置特征it和与所述位置特征it对应的局部视频特征fit构成当前的视频时刻片段的状态st=[fq,fg,it,fit],其中,t为时间步骤,位置特征it为初始的时序边界it;
候选集生成模块300,所述候选集生成模块300用于根据所述状态st作出在所述时序边界it移动的动作at,获取执行所述动作at的奖励rt以及根据所述奖励rt输出若干个更新的时序边界it+1和与所述时序边界it+1对应的局部视频特征fit+1,重新构成当前的视频时刻片段的状态s′,此时,所述时序边界it+1为更新后当前的视频时刻候选片段;
贝叶斯个性化排序鉴别模块400,所述贝叶斯个性化排序鉴别模块400用于对所述时序边界it和所述查询语句q进行匹配,输出匹配分值,并将所述匹配分值作为奖励rt返回所述强化学习代理;
对抗学习模块500,所述对抗学习模块500用于通过对抗学习相互增强,直到收敛,得到对应所述查询语句q的视频时刻片段i=(is,ie),其中,is为视频起始时刻,ie为视频结束时刻。
关于对抗性视频时刻检索装置的具体限定可以参见上文中对于对抗性视频时刻检索方法的限定,在此不再赘述。上述对抗性视频时刻检索装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
在本实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图6所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于强化学习的对抗性视频时刻检索方法。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序指令相关的硬件来完成的,计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
上述实施例和图式并非限定本发明的产品形态和式样,任何所属技术领域的普通技术人员对其所做的适当变化或修饰,皆应视为不脱离本发明的专利范畴。
- 还没有人留言评论。精彩留言会获得点赞!