一种基于数据可执行特征的网页后门检测方法与系统与流程
本发明属于网络安全技术领域,具体涉及一种基于数据可执行特征的网页后门检测方法与系统。
背景技术:
随着互联网的迅猛发展,web应用的快速普及,web服务攻击事件越发频繁,而向目标站点植入网页后门也成为了攻击者们最常用的攻击方法之一,攻击者利用网页后门获取系统的命令执行环境,从而进一步控制网站服务器,达到信息嗅探、数据窃取或篡改等目的。为对抗web服务攻击,因此网页后门检测的研究成为了当前的重要工作之一。
网页后门检测技术目前主要分为动态特征检测和静态特征检测两种方法,其中,动态特征检测主要是基于文件行为、网页后门通信流量等特征进行检测,需要在网页后门动态执行的情况下才能进行检测分析;静态特征检测方法主要是基于网页后门的文本内容或者系统的日志信息进行检测分析,当前静态特征检测方法的主要研究方向是基于网页后门的文件内容,最早得到广泛使用的是利用正则表达式进行网页后门的检测,但是由于正则表达式是从现有的网页后门中提取生成的,需要不断的进行更新,并且没有检测当前未出现过的网页后门的能力,并且由于网页后门代码混淆加密技术不断趋于成熟,导致利用正则表达式的检测方法的能够被网页后门轻松规避,而当前的研究学者指明,将机器学习运用到网页后门检测中,起到了很好的效果。
通过机器学习进行网页后门检测,其决定性作用的在于网页后门的特征选择。
yongfang等人在2018年提出利用随机深林算法结合fasttext的方法构建训练模型进行网页后门检测的方法,提取了最长字符串、信息熵、符合指数这类统计学特征以及签名函数和黑名单关键字特征,同时也首次提出提取phpopcode代码,经过fasttext处理后与上述特征共同输入到随机森林算法中进行模型训练。
handongcui等人在2018年提出利用随机森林结合梯度提升决策树算法构建训练模型进行网页后门检测的方法,涉及到的特征有:信息熵、重合度、压缩比、最长单词的长度、签名函数匹配数量等统计学特征以及phpopcode代码经过tf-idf算法处理后生成的词频特征和哈希特征。
tingtingli等人在2019年提出基于单词注意机制的网页后门检测方法,涉及到的特征有主要为各个单词对于样本语句表达含义的重要性。
现有的基于机器学习检测网页后门的方法主要都是提取网页后门的统计学特征,结合文本中单词重要性或词频特征进行模型构建。由于统计学特征只能从整体的角度进行检测分析,由于当前web服务的快速发展,开发人员为避免源码泄露,常常会对源代码进行混淆加密,这样就导致了基于统计学特征的方法检测网页后门时产生了大量误报,不能够进行有效的检测分析。
技术实现要素:
本发明的目的之一,在于提供一种基于数据可执行特征的网页后门检测方法,该网页后门检测方法能够有效提高网页后门检测的准确率,减少误报。
本发明的目的之二,在于提供一种存储介质。
本发明的目的之三,在于提供一种基于数据可执行特征的网页后门检测系统。
为了达到上述目的之一,本发明采用如下技术方案实现:
一种基于数据可执行特征的网页后门检测方法,所述网页后门检测方法包括如下步骤:
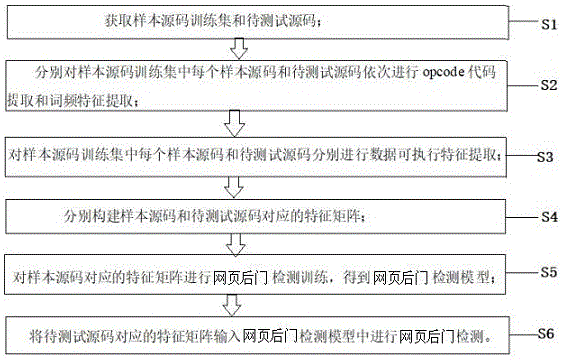
获取样本源码训练集和待测试源码;所述样本源码训练集包括正常样本源码和网页后门样本源码;
分别对样本源码训练集中每个样本源码和待测试源码依次进行opcode代码提取和词频特征提取,生成样本源码和待测试源码的词频矩阵;
对样本源码训练集中每个样本源码和待测试源码分别进行数据可执行特征提取,得到每个样本源码和待测试源码的数据可执行特征;
根据样本源码的词频矩阵和每个样本源码的数据可执行特征、以及待测试源码的词频矩阵和数据可执行特征,分别构建样本源码和待测试源码对应的特征矩阵;
采用监督学习算法,对样本源码对应的特征矩阵进行网页后门检测训练,得到网页后门检测模型;
将待测试源码对应的特征矩阵输入网页后门检测模型中进行网页后门检测。
进一步的,所述分别对样本源码训练集中每个样本源码和待测试源码依次进行opcode代码词频特征提取和词频特征提取的具体实现过程包括:
采用phpdbg和正则匹配方法,对样本源码训练集中每个样本源码和待测试源码分别进行opcode代码提取,得到每个样本源码和待测试源码的opcode代码;
采用n-gram方法,对每个样本源码和待测试源码的opcode代码中分别进行词频特征提取,得到样本源码和待测试源码的词频矩阵。
进一步的,所述分别对样本源码训练集中每个样本源码和待测试源码依次进行opcode代码词频特征提取和词频特征提取的具体实现过程还包括:
采用tf-idf算法,对样本源码和待测试源码的词频矩阵分别进行过滤处理,得到过滤后的样本源码和待测试源码的词频矩阵。
进一步的,所述特征词频矩阵的行数和列数分别为m和n;
其中,m为源码个数,n为每个源码所对应的词频特征数,元素值为每个源码所对应的词频特征;所述源码包括样本源码和待测试源码。
进一步的,所述数据可执行特征提取的具体过程为:
将每个源码转换为对应的抽象语法树;
从对应的抽象语法树中提取调用函数和调用函数内容;
判断调用函数是否为将数据作为php代码或系统命令执行的函数,且调用函数内容是否为变量,如是,则将对应源码的数据可执行特征标注为1,结束;如否,则将对应的样本源码的数据可执行特征标注为0,结束。
进一步的,所述特征矩阵的行数和列数分别为m和n+1;
其中,m为源码数,每行的前n个元素值为每个源码所对应的词频特征;每行的第n+1个元素值为每个源码所对应的数据可执行特征;所述源码包括样本源码和待测试源码。
为了达到上述目的之二,本发明采用如下技术方案实现:
一种存储介质,所述存储介质存储有计算机执行指令;所述计算机执行指令执行时,实现上述所述的网页后门检测方法。
为了达到上述目的之三,本发明采用如下技术方案实现:
一种基于数据可执行特征的网页后门检测系统,所述网页后门检测系统包括上述所述的网页后门检测方法。
本发明的有益效果:
本发明提取的数据可执行特征是从文件代码的语法结构上对文件进行分析描述,可以更清晰的反映样本代码结构,可有效地提高代码分析效率,同时提高对抗源代码的混淆加密,增加了正常文件和网页后门的区分能力,降低了检测误报,有效地提高了网页后门检测的准确性;通过提取opcode代码并经过n-gram算法处理,生成词频矩阵,提高了数据的利用率和运行效率;通过源代码的的数据可执行特征和opcode词频特征,使用多层感知器、支持向量机和决策树等算法对网页后门进行检测的方法,能够实现准确、高效、批量地网页后门检测,能够更好的区分正常文件和网页后门,实现低误报率;本发明能够检测出目前网络上使用的网页后门,还能够检测出未知的网页后门文件。
附图说明
图1为本发明的基于数据可执行特征的网页后门检测方法流程示意图;
图2为本发明的网页后门检测训练流程示意图;
图3为本发明中的opcode代码词频特征提取和词频特征提取的具体实现过程示意图;
图4为本发明中的数据可执行特征提取的具体过程示意图。
具体实施方式
以下结合附图对本发明的具体实施方式作出详细说明。
本实施例给出了一种基于数据可执行特征的网页后门检测方法,参考图1和2,该网页后门检测方法包括如下步骤:
步骤一、获取样本源码训练集和待测试源码。
本实施例中,样本源码训练集包括正常样本源码和网页后门样本源码,正常样本源码为国内外较为知名的php语言cms框架最新版本的源码,网页后门样本源码可以为github中开源的php语言网页后门收集项目通过排重和排错后构成。
步骤二、分别对样本源码训练集中每个样本源码和待测试源码依次进行opcode代码提取和词频特征提取,生成样本源码和待测试源码的词频矩阵。
本实施例的opcode代码可以采用传统的phpvld拓展和正则匹配方法提取,适合于处理代码量少的文件。为了实现对抗网页后门的混淆加密,提高针对混淆加密处理的网页后门检测能力,也可以采用phpdbg和正则匹配方法提取,采用phpdbg处理样本,无论样本的代码量大小或者是否经过加密混淆,均不会产生干扰数据,结合正则匹配方法进行opcode代码提取,不会提取出额外的干扰数据,并且由于phpdbg为php原生调试器,无需调用外部拓展,因此提取样本opcode效率相对更高。本实施例的opcode代码词频特征提取和词频特征提取的具体实现过程如图3所示,包括:
步骤21、采用phpdbg和正则匹配方法,对样本源码训练集中每个样本源码和待测试源码分别进行opcode代码提取,得到每个样本源码和待测试源码的opcode代码;
步骤22、采用n-gram方法,对每个样本源码和待测试源码的opcode代码中分别进行词频特征提取,得到样本源码和待测试源码的词频矩阵。
本实施例利用n-gram方法,提取opcode代码的词频。本实施例中,特征词频矩阵的行数和列数分别为m和n;其中,m为源码个数,n为每个源码所对应的词频特征数,元素值为每个源码所对应的词频特征(即每个词在每个源码中出现的次数),该源码包括样本源码和待测试源码。
为了进一步保证数据的利用率,减少运算量,提高运算效率,需要过滤掉词频矩阵中区分能力较小的词,本实施例还采用tf-idf算法,对样本源码和待测试源码的词频矩阵分别进行过滤处理,得到过滤后的样本源码和待测试源码的词频矩阵。
步骤三、对样本源码训练集中每个样本源码和待测试源码分别进行数据可执行特征提取,得到每个样本源码和待测试源码的数据可执行特征。
在php语言的解析中,并没有数据段和代码段之分,php在接收用户传入的数据时,输入的数据不一定只会作为字符进行处理,也同样有可能作为php的代码进行解析执行。例如php代码为:
这样可以直接确定该代码的功能,即用户输入的数据作为echo函数输出的字符,打印在页面中,而不会因为用户输入的不同而影响到代码的整体的功能,因此该代码的功能是明确的。若将上述代码中的echo替换为eval,则成为一个php语言的一句话木马:
该代码的具体功能我们无法直接确定,若$_get[‘txt’]获取的数据为‘1+1’,这该代码执行计算功能,输出计算结果为2;若$_get[‘txt’]获取的数据为php中的函数phpinfo(),则这段代码将输入的数据作为php函数执行,打印服务器php的相关配置信息;若获取的数据为‘system(whoami)’,则将用户输入转换为system函数执行对应的系统命令,即用户输入的数据在这段代码中实际上是作为了一段php代码进行执行,而输入数据的不同也决定了代码的实际功能的不同。因此,数据可执行特征的定义为:一段php代码中,输入的数据作为php代码或系统命令进行解析执行,从而决定这段代码的实际功能。网页后门往往是通过一段简单的代码,来实现多样的功能,例如获取网站服务器运行环境信息、进行文件上传下载或编辑操作、数据库的连接、获取服务端的命令执行环境等功能,绝大多数的网页后门会将用户输入的不同数据进行执行以实现对应的功能,即绝大多数网页后门都具备数据可执行特征。
提取php代码的数据可执行特征,需要构建php代码的抽象语法树(abstractsyntaxtree,ast),抽象语法树是通过树状形式来表示程序源代码的语法结构,树上的每个节点都表示源代码中的一种结构。php代码的抽象语法树可以使用php-parser进行生成,php-parse是一款使用php语言编写,基于zend引擎的开源php抽象语法树生成工具,例如php代码为:
利用php-parse生成该代码的抽象语法树为:
array(
0:stmt_expression(
expr:expr_eval(
expr:expr_arraydimfetch(
var:expr_variable(
name:_request
)
dim:scalar_string(
value:password
)
)
)
)
)
其中,stmt表示声明节点,expr表示表达式节点,表达式中的变量使用variable表示,scalar_string表示字符串常量,通过抽象语法树,可以很直观的反映代码的整体语法结构,提取php代码的数据可执行特征,便可以通过匹配分析抽象语法树中的expr节点中的eval、funccall、methodcall以及shellexec节点,对这些节点的属性(函数名和参数类型)进行分析判断,即表达式节点中的函数(即调用函数)是否是能够将数据作为php代码或系统命令进行执行的函数,函数的参数(即调用函数内容)是否是variable节点,即变量节点,即表达式节点的函数将变量参数作为php代码或系统命令执行,该段代码的实际功能由变量的值动态决定,若以上条件都满足,则判断该php代码具有数据可执行特征,将其记录为1;反之记录为0。
基于上述分析,本实施例中数据可执行特征提取的具体过程参考图4,包括:
步骤31、将每个源码转换为对应的抽象语法树;
步骤32、从对应的抽象语法树中提取调用函数和调用函数内容;
步骤33、判断调用函数是否为将数据作为php代码或系统命令执行的函数,且调用函数内容是否为变量,如是,则将对应源码的数据可执行特征标注为1,结束;如否,则将对应的样本源码的数据可执行特征标注为0,结束。
步骤四、根据样本源码的词频矩阵和每个样本源码的数据可执行特征、以及待测试源码的词频矩阵和数据可执行特征,分别构建样本源码和待测试源码对应的特征矩阵。
将提取出的代码数据可执性特征和对应的词频特征,构造特征矩阵,本实施例中,特征矩阵的行数和列数分别为m和n+1;其中,m为源码数,每行的前n个元素值为每个源码所对应的词频特征;每行的第n+1个元素值为每个源码所对应的数据可执行特征;所述源码包括样本源码和待测试源码。
步骤五、采用监督学习算法,对样本源码对应的特征矩阵进行网页后门检测训练,得到网页后门检测模型。
本实施例的监督学习算法包括多层感知器(mlp,multilayerperceptron)算法、支持向量机(supportvectormachine,svm)算法和决策树(decisiontree)算法。
采用多层感知器算法进行检测模型训练时,由于python中的第三方机器学习库sklearn中将该算法封装好了,在模型训练中采用python语言进行实现,调用sklearn库中的mlpclassifier方法,即调用多层感知器算法,设置隐藏层层数,隐藏层单元数,隐藏层激活函数等参数,将上述构造好的特征矩阵输入到算法中进行训练,生成网页后门检测模型。
采用支持向量机算法进行检测模型训练时,调用sklearn库中的svm方法,即调用支持向量机算法,设置惩罚系数、核函数等参数后对样本的特征矩阵进行训练,生成网页后门检测模型。
采用决策树算法进行检测模型训练时,调用sklearn库中的decisiontreeclassifier方法,即调用决策树算法,设置划分度量标准、划分策略,数的最大深度等参数后对样本的特征矩阵进行训练,生成网页后门检测模型。
步骤六、将待测试源码对应的特征矩阵输入网页后门检测模型中进行网页后门检测。
网页后门检测通过将待测试源码对应的特征矩阵输入到训练好的网页后门检测模型中,利用网页后门检测模型判断样本是否为网页后门,数据检测结果。
本实施例通过提取的源代码的数据可执行特征,提高了正常文件和网页后门的区分能力,降低了检测误报,有效地提高了网页后门检测的准确性;通过提取opcode代码并经过n-gram算法处理,生成词频矩阵,提高了数据的利用率和运行效率;通过源代码的的数据可执行特征和opcode词频特征,使用多层感知器、支持向量机和决策树等算法对网页后门进行检测的方法,能够实现准确、高效、批量地网页后门检测,能够更好的区分正常文件和网页后门,实现低误报率;本实施例能够检测出目前网络上使用的网页后门,还能够检测出未知的网页后门文件。
另一实施例给出了一种存储介质,该存储介质存储有计算机执行指令;所述计算机执行指令执行时,实现上述实施例给出的网页后门检测方法。
又一实施例给出了一种基于数据可执行特征的网页后门检测系统,该网页后门检测系统包括上述实施例给出的网页后门检测方法。
以上实施方式仅用以说明本发明实施例的技术方案而非限制,尽管参照以上较佳实施方式对本发明实施例进行了详细说明,本领域的普通技术人员应当理解,可以对本发明实施例的技术方案进行修改或等同替换都不应脱离本发明实施例的技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!