基于时空关系学习的移动社交网络用户关系推断方法与流程
本发明涉及一种基于时空关系学习的移动社交网络用户关系推断方法,利用用户的移动信息。
背景技术:
近些年来,随着facebook、twitter和微博这类移动社交网络应用的普及,用户可以及时地发布其正在访问的感兴趣地点(一家网红餐厅、一个旅游景点等)与好友共享。虽然这类社交方式给人们的交友带来了极大的方便,但存在泄露用户社交关系的风险。移动社交网络的用户也逐渐意识到这一点,例如,一项针对facebook用户的大规模研究表明:facebook用户隐藏好友列表的比例从2010年的17.2%上升到2011年的56.2%。但很少有用户知道利用具有时空关系的签到记录可以推断其朋友,从而准确地揭露用户之间隐藏的社交关系。
现有的基于时空关系的社交关系推断方法主要分为两类:第一类是基于特征选择的启发式方法,通过观察选择碰面次数、共享位置数、共享位置流行程度等有效特征作为衡量用户之间是否具有朋友关系的衡量标准。但这些方法对所需的移动数据提出了很多假设和限制,这在很大程度上缩小了它们的适用范围。例如,几乎所有现有的有效方法都只能在两个个体共享位置的情况下使用。另一类方法是基于特征学习的方法,通过机器学习的方法将用户的移动特征向量化,利用向量之间的相似程度作为推断用户对是否具有朋友关系的标准。但该类方法针对个体建模且丢失移动数据中的时间信息,因此无法直接获得较为准确的关系推断。
技术实现要素:
本发明的目的是提供一种能够利用用户移动信息准确推断用户社交关系的模型。
为了达到上述目的,本发明的技术方案是提供了一种基于时空关系学习的移动社交网络用户关系推断方法,其特征在于,包括以下步骤:
步骤1、提取用户对之间的交互行为特征,利用该特征推断两个用户之间是否具有朋友关系,包括以下步骤:
步骤101、将移动数据所有用户签到涉及的兴趣点pois按照经纬度划分到i×j的网格中,同时将时间划分为m个时间片段,构建一个i×j×m的时空矩阵std,其中,时间维度上将时间分为长度τ的等长时间片,空间维度上将空间均匀地划分为大小相等的网格,递归地将每个网格划分为四个相等的网格,直到兴趣点pois的数量在每个网格小于阈值σ;
步骤102、将每个用户对(ua,ub)的轨迹均投影到时空矩阵std中,用户的每一个签到都可以投影到一个特定的方格中,对于每个方格,计算:该时间段内用户ua访问过的兴趣点数na;用户ub访问过的兴趣点数nb;用户ua和用户ub共同访问过的兴趣点数na,b,由此获得用户对(ua,ub)的时空矩阵
步骤103、将每对用户对(ua,ub)的时空矩阵o(a,b)编码成一个低维向量,并利用该低维向量计算用户ua和用户ub存在朋友关系的概率,获得初始的社交关系图g=(u,e),u是图中的顶点的集合,表示所有具有移动信息的用户;e是边的集合,表示两个用户之间具有朋友关系,其中,时空矩阵o(a,b)的大小通过参数σ和τ来调整;
步骤2、为每个用户提取一个k可达的子图来描述用户之间的网络结构,对于给定的初始的社交关系图g=(u,e),定义提取用户对(ua,ub)的k-可达子图
步骤201、设置路径长度为2,将
步骤202、在初始的社交关系图g中找出(ua,ub)之间所有长度为2条的路径,并将找到的所有路径表示为
步骤203、逐步增加路径长度,重复步骤202,直到路径长度超过k;
步骤3、根据初始的社交关系图g,对于每对用户对(ua,ub)的k-可达子图
步骤4、利用分类器根据用户对的综合特征向量进行0/1分类,其中1是朋友,0为不是朋友,获得最新的预测社交图。
步骤5、利用最新的社交图,更新用户对的结构特征,进而重新进行预测,直到预测结果不再发生变化,即获得最终预测的社交网络图。
优选地,步骤103中,将时空矩阵o(a,b)输入一个具有r个隐藏层的自动编码器,该自动编码器将其编码成d维的向量,获得重构的时空矩阵
式中,
自动编码器采用有监督训练实现编码过程的重构和区别,即为自动编码器添加一个分类网络来监控其编码过程,该过程的损失函数
式中,
为了获取更具有识别力的向量表示,对整合混合网络作出以下约束:
式中,
一旦训练完成,编码器将从自动编码器网络中取出,用于对用户集中的任何一对用户时空关系矩阵进行编码和初步关系推断。
本发明提供了一种新的社交关系推理模型,该模型同时考虑了个体之间的移动性和社交性。考虑社交网结构对社会联系预测的有效性,该模型首先基于用户的移动性构建一个初步的社交图,然后从初步构建的社交图中抽取用户对的社交网络结构特征,最后综合移动性和社交性两个方面的特征进行朋友关系推断。我们的模型一旦训练完成,可以较好地迁移不同的场景对用户之间的朋友关系进行预测。通过对两个真实世界数据集的实验证明我们的方法始终优于现有的方法。此外,我们的模型对于具有少量签到数据和不具备碰面事件的关系也有效。
附图说明
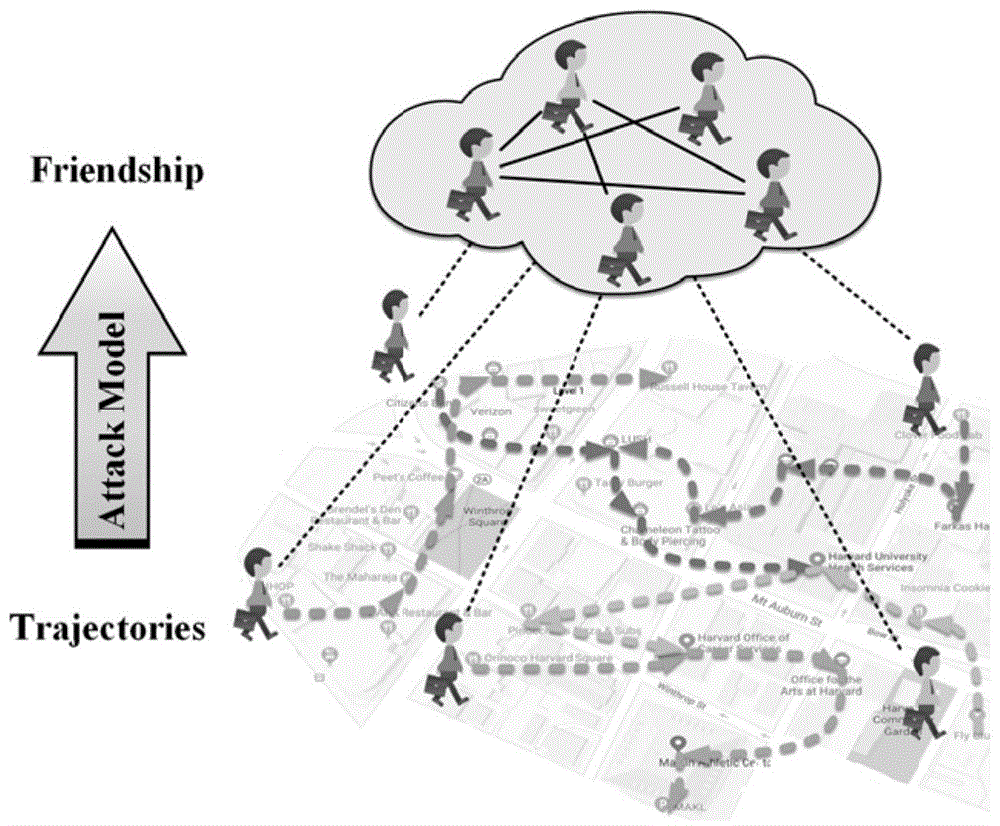
图1为用户移动关系映射朋友关系的示意图;
图2为社交关系推断模型的系统结构图;
图3为交互行为特征抽取过程示意图;
图4为k-可达子图编码过程的示意图;
图5(a)为brightkite数据集中空间粒度大小对朋友关系推断准确性的影响结果图;
图5(b)为gawalla数据集中空间粒度大小对朋友关系推断准确性的影响结果图;
图6(a)为brightkite数据集中时间粒度对朋友关系推断准确性的影响结果图;
图6(b)为gawalla数据集中时间粒度对朋友关系推断准确性的影响结果图;
图7(a)为brightkite数据集中特征向量维度对朋友关系推断准确性的影响结果图;
图7(b)为gawalla数据集中特征向量维度对朋友关系推断准确性的影响结果图;
图8(a)为brightkite数据集中迭代次数对朋友关系推断准确性的影响结果图;
图8(b)为gawalla数据集中迭代次数对朋友关系推断准确性的影响结果图;
图9(a)为brightkite数据集中用户签到数对朋友关系推断准确性的影响结果图;
图9(b)为gawalla数据集中用户签到数对朋友关系推断准确性的影响结果图;
图10(a)为brightkite数据集中用户对共享位置数对朋友关系推断准确影响结果图;
图10(b)为gawalla数据集中用户对共享位置数对朋友关系推断准确影响结果图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明通过利用用户间移动轨迹的相似性和社交网络的传播性,推断用户间是否具有朋友关系,图1为对该现实问题的抽象。该推断模型分为两个阶段:1、构建初始社交网络图:基于朋友间的移动轨迹一般具有更高相似性这一观察,构建初始社交网络图。2、获得隐藏的社交关系:基于朋友间网络拓扑结构更相似的现象,挖掘具有相似喜好但不具备相似移动轨迹的隐藏朋友关系。
图2展示了本发明提供的一种基于时空关系学习的移动社交网络用户关系推断方法的具体实现内容,主要包括以下两个阶段:
第一阶段:构建初步的社交图
该阶段,我们提取用户对之间的交互行为特征,利用该特征推断两个用户之间是否具有朋友关系。通常,交互行为特征可以通过用户对之间交互的统计属性来刻画,例如碰面次数、共同访问地点数。然而,朋友可能不存在共同访问事件或碰面事件,而且并不是所有的共同访问在推断用户的朋友关系方面都具有相同的重要性。因此,我们提出一种更全面的方法来学习复杂的交互行为特征。我们将两个用户的共同行为和个人行为均嵌入到交互行为特征中。此外,我们认为不同的地点和时段具有不同的预测重要性,并设计了一个混合模型来同时生成压缩的交互行为特征向量和初始分类结果,其中每个位置影响范围和时间间隔的均为模型的参数。该方法可以保证压缩后的交互行为特征尽可能地保留用户原有的动作特征,且该特征在推断朋友关系的任务中具有重要指示作用。第一阶段包括以下步骤:
步骤1、构建时空矩阵
图3展示了构建用户对时空矩阵的示意图。首先将移动数据所有用户签到涉及的兴趣点(pois)按照经纬度划分到i×j的网格中,同时将时间划分为m个时间片段,构建一个i×j×m的时空矩阵(std)。其中,时间维度上分为长度τ的等长时间片;空间维度上将空间均匀地划分为大小相等的网格,考虑到pois的密度在地理区域内存在较大的差异,我们递归地将每个网格划分为四个相等的网格,直到pois的数量在每个网格小于阈值σ。每个用户对(ua,ub),其轨迹均可投影到std中,用户的每一个签到都可以投影到一个特定的方格中,对于每个方格,我们计算三个指示因子,分别为该时间段内用户ua访问过的poi数na,用户ub访问过的poi数nb以及用户ua和用户ub共同访问过的poi数na,b。由此获得用户对(ua,ub)的时空矩阵
步骤2、时空矩阵的编码
该步骤将每对用户对(ua,ub)的时空矩阵o(a,b)编码成一个低维向量,并利用该向量计算用户ua和用户ub存在朋友关系的概率,其中时空矩阵的大小可以通过参数σ和τ来调整。
我们将时空矩阵输入一个自动编码器,具有r个隐藏层的编码器将其编码成d维的向量,即编码器的第r层输出结果。具有r个隐藏层的解码器根据d维向量输出重构的时空矩阵
式中,
自动编码器的训练是无监督的,这意味着它只学习输入结构,而不具备特征选择或倾向的功能,因此最终获得的d维特征向量仅仅保留用户对原始的移动信息,不能保证在朋友关系推断任务中具有效用。为了避免这个问题,我们采用有监督训练实现编码过程的重建和区别,即我们为自动编码器添加一个分类网络(输出
式中,
为了获取更具有识别力的向量表示,我们对整合混合网络作出以下约束:
式中,
一旦训练完成,编码器将从自动编码器网络中取出,用于对用户集中的任何一对用户时空关系矩阵进行编码和初步关系推断。
第二阶段:获得隐藏的社交关系
在第二阶段,我们考虑用户对间的非直接链路特征,即网络结构特征。由于移动数据不具备社交拓扑图,我们根据第一阶段的预测结果(一个半真实的社会图)提取结构特征。考虑到简单的启发式结构特征不具备普遍适用性,我们提出了一种新的描述目标用户间网络结构特征——k可达子图,并对该子图编码得到结构特征向量。最后将编码后的结构向量与相应的交互特征相结合,提高推断的准确性。此外,我们设计了一个迭代过程,可以同时细化结构特征向量和得到的最终的社交关系图。
第二阶段包括以下步骤:
步骤3、抽取局部图结构——k可达子图
katz是常用的用于测量用户之间的网络接近度,它考虑用户对在社交图中的全局视图,即考虑用户对之间的所有可能路径。然而,我们认为这是不合理的,因为较长的路径不仅计算复杂还对关系推断产生负面影响。因此,我们在网络接近度上采用局部视点,即为每个用户提取一个k可达的子图来描述用户之间的网络结构。对于给定的初始的社交关系图g=(u,e),我们定义提取用户对(ua,ub)的k-可达子图
步骤301、设置路径长度为2,将
步骤302、在第一阶段构建的初始的社交关系图g中找出(ua,ub)之间所有长度为2条的路径,并将找到的所有路径表示为
步骤303、逐步增加路径长度,重复步骤302,直到路径长度超过k。
步骤4、迭代更新预测社交图
根据第一阶段构建的初始的社交关系图g,我们对于每对用户对(ua,ub)的k-可达子图
利用分类器根据用户对的综合特征向量(综合第一阶段获得的交互行为特征和第二阶段获得的局部结构特征向量)进行0/1分类(其中1是朋友,0为不是朋友),获得最新的预测社交图。
利用最新的社交图,更新用户对的结构特征,进而重新进行预测,直到预测结果不在发生变化,即获得最终预测的社交网络图。
本发明的验证过程如下:
实验采用brightkite和gowalla两大公开的真实数据,这两个数据集均是基于位置的社交网络,用户可以通过它发布自己的时间-位置信息,分享给自己的好友。这类数据集分为签到数据集和用户的社交关系图两个部分,表1展示了实验数据集的统计信息。
表1.数据集统计
实验与基于移动距离、共享位置数、随机游走和图嵌入四种流行的推断方法进行对比。
·基于共享位置数的关系推断:该方法提取并利用一对用户访问过的共地点的数量作为特征来推断用户对之间是否存在朋友关系。实验采用svm分类器进行有监督学习。
·基于移动距离的关系推断。该方法根据每个用户的全部移动信息计算其活动的中心位置,将每对用户其中心位置的欧式距离作为特征推断他们是否具备朋友关系。实验采用svm分类器进行有监督学习。
·基于随机游走的关系推断。该方法将用户的移动数据映射成一个用户-位置二部图,根据一定的规则为每个用户在二部图中游走出其邻居,并将这些邻居信息压缩成向量,最后通过对比用户对之间特征向量的相似程度进行朋友关系推断。
·基于图嵌入的关系推断。该方法根据用户的移动信息构建碰头图,即两个用户共同出现过(在一定的时间间隔内出现在相同的位置)即有边,在碰头图上为每个用户游走出一定数量的朋友,并将这些朋友节点编码成向量,最后通过对比用户对之间特征向量的相似程度进行朋友关系推断。
实验中,我们使用f1-score作为评价指标,该指标对类的分布不敏感,即使类分布不平衡时,也可以较为准确地刻画推断结果的准确性。其定义为:
f1-score=(2×精确率×召回率)÷(精确率+召回率)
其中精度精确率是真阳性的数量除以预测结果为阳性的数量,而召回率(又称真阳性率)是真阳性的数量除以标签为阳性的数量。f1-score的取值在0到1之间,取值越大,说明推断的准确性越高。
在我们的实验中,我们采用全连通的自编码器网络,网络结构中每一层的节点数是前一层节点数的一半,其中最后一层为用户自主设置。另一方面,在解码器的结构中,我们使用与编码器相同的反向网络结构。实验根据输入编码器的时空矩阵的大小,调整其层数。我们分别使用一个简单的knn和svm作为阶段1中的分类器和阶段2中的二元分类器,使用rbf作为支持向量机的核函数。所有网络的学习速率设置为0.005,迭代终止的条件为两轮预测的社交网络图边的变化小于1%。
1)空间粒度σ的影响
我们实验了σ为500、750、1000、1250和1500五种情况下,推断结果的准确性。如图5(a)、(b)所示,在brightkite数据集(图5(a))中,当σ增加从500到1000时,其f1-score增加了4.56%,然后随着σ的增加准确性逐渐下降。类似的趋势为gawalla数据集(图5(b)),当σ=750时,f1-score取得最大值,这是由于gawalla数据集中的pois比brightkite数据集中的pois更分散,这意味着gawalla中一个网格所覆盖的地理区域比brightkite要大,所以gawalla数据集的最佳σ值小于brightkite数据。
2)时间粒度τ的影响
我们实验了τ为1天、7天、14天、30天和60天五种情况下,推断结果的准确性。如图6(a)、(b)所示,brightkite数据集(图6(a)),当τ=7天时,f1-score为最大值。类似的实验结果在gawalla数据集(图6(b))也得到了印证。这是由于人类的活动往往表现出周期性,一般以每周为基础。
3)编码维度d的影响
我们实验了d为16、32、64、128和256五种情况下,推断结果的准确性。如图7(a)、(b)所示,brightkite数据集(图7(a))和gawalla数据集(图7(b))的准确性变化具有相同的趋势,这是由于时空关系向量的维数越高,所包含的信息就越多,从而使得攻击性能越好;但高维时空关系向量也会产生过多的噪声,降低了攻击的准确性。
4)迭代次数的影响
根据以上对参数的探究,我们使用每个参数的最佳值对两个数据集进行实验。
图8(a)、(b)描述了brightkite数据集(图8(a))和gawalla数据集(图8(b)),迭代的次数对我们推断准确性的影响。可以看出随着迭代次数的提高,推断准确性保持着提高,在gowalla和brightkite中,满足终止条件所需的迭代次数分别为4和5。
5)用户签到数的影响
图9(a)、(b)绘制了用户对共享位置数对推断结果准确性的影响结果。可以看出,随着用户对共享位置数的增加,推断结果的准确性也不断提升。实验结果同时表明我们的推断模型在brightkite数据集(图9(a))和gawalla数据集(图9(b))都比基于特征抽取的方法(基于移动距离的关系推断)在f1-score这一指标上高出了10%左右。
6)用户对共享位置数的影响
图10(a)、(b)绘制了用户签到数对推断结果准准确性的影响结果。brightkite数据集(图10(a))和gawalla数据集(图10(b))的实验结果表明,我们的方法对于不同签到数的用户都具有一定的鲁棒性。显然,用户签到数越多,用户行为模式的建模就越精确,用户关系推断就越准确。
- 还没有人留言评论。精彩留言会获得点赞!