一种基于大数据分析的机顶盒收视方法及系统与流程
本发明涉及流媒体采集设备技术领域,特别涉及一种利用u盘进行系统强制更新的方法。
背景技术:
人们在生活中产生的数据的速度越来越快,要存储这些数据,需要大量的磁盘容量。存储之后,进行数据分析,也需要大量的运行性能,传统的技术,对于海量的数据,单单依靠mysql来处理和分析,已然无法满足和实现我们的需求,在传统的收集方式中,面对客户端每天生成的上亿的数据,mysql接收和处理都有瓶颈。大数据量的存储和统计,mysql无法支撑,甚至导致来不及处理,而造成了堵塞卡顿或者宕机,无法继续进行统计相关的工作。同时,也因为数据过多,mysql查询时间长,达不到秒级实时响应的效果,需要更多的服务器支撑,特别是在机顶盒的收视方面,在需要大访问量的情况下,如果还用传统的方式,会大大的提高了服务器的成本,也加大了运营维护的难度。
技术实现要素:
为了克服以上问题,本发明在提出了一种基于大数据分析的机顶盒收视统计方法的同时,还提出了一种基于大数据分析的机顶盒收视统计系统,该方法及方法用于使机顶盒大大的提高数据的处理速度和能力,能支撑更多的访问量。
本发明的技术方案为:
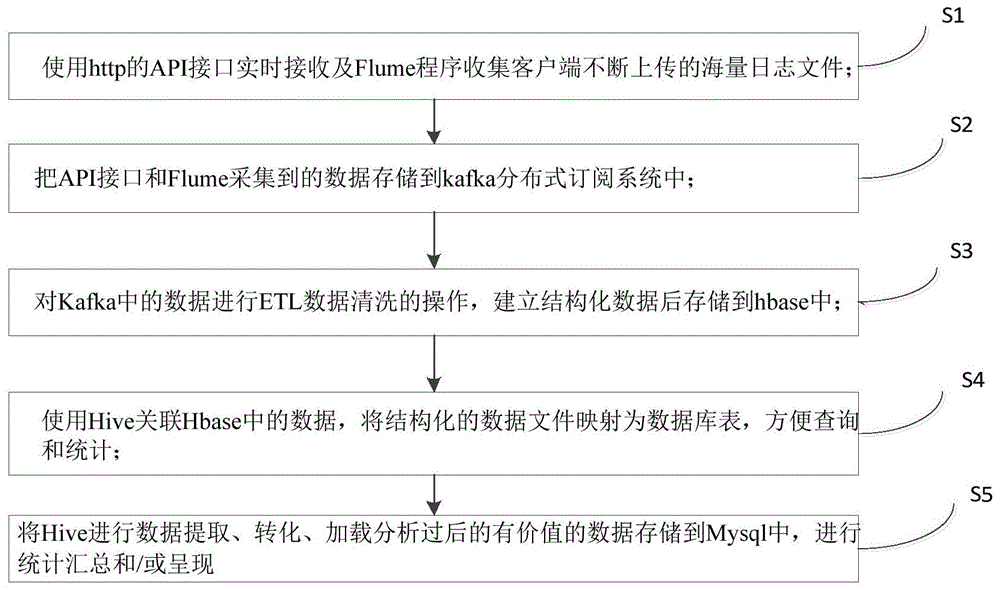
一种基于大数据分析的机顶盒收视统计方法,其特征在于,包括步骤:
s1,使用http的api接口实时接收及flume程序收集客户端不断上传的海量日志文件;
s2,把api接口和flume采集到的数据存储到kafka分布式订阅系统中;
s3,对kafka中的数据进行etl数据清洗的操作,建立结构化数据后存储到hbase中;
s4,使用hive关联hbase中的数据,将结构化的数据文件映射为数据库表,方便查询和统计;
s5,将hive进行数据提取、转化、加载分析过后的有价值的数据存储到mysql中,进行统计汇总和/或呈现。
进一步地,s5中队存储到mysql中的数据进行统计汇总和/或呈现的方法包括直接查询hbase中的结构化数据,对该结构化数据进行离线统计分析,转换生成机器学习需要的数据格式,进行模型训练或汇总分析其使用情况存储到mysql的数据,进web可视化管理。
进一步地,web可视化管理的方法包括使用前端的echarts插件将数据进行可视化并呈现在web页面中。
进一步地,s3中对kafka中的数据进行etl数据清洗的操作的方法包括对数据进行抽取,转换,加载,去除脏数据,最后建立结构化数据存储到hbase中。
一种基于大数据分析的机顶盒收视统计系统,其特征在于包括:
数据采集单元,用于收集客户端不断上传的海量日志文件;
数据的预处理单元,用于将数据采集单元采集到的数据存储到kafka分布式订阅系统中;
数据清洗单元,用于对kafka中的数据进行etl数据清洗的操作,建立结构化数据;
数据分析处理单元,用于对结构化的数据文件映射为数据库表,方便查询和统计;
数据存储单元,用于将提取、转化、加载分析过后的有价值的数据进行存储方便汇总统计;
数据统计汇总和呈现单元,用于对数据进行统计汇总和/或通过可视化单元进行呈现;
可视化单元,用于将数据可视化显示。
进一步地,所述数据采集单元采用http的api接口实时接收及采用flume程序模块收集客户端不断上传的海量日志文件。
进一步地,所述数据清洗单元通过抽取,转换,加载,去除脏数据,建立结构化数据并存储到hbase模块中。
进一步地,所述数据分析处理单元使用hive关联hbase中的数据,通过hive数据仓库工具将结构化的数据文件映射为数据库表。
进一步地,所述数据存储单元包括mysql模块,通过将hive进行数据提取、转化、加载分析过后的有价值的数据存储到mysql中,进行汇总统计。
进一步地,所述可视化单元包括使用前端的echarts插件将数据进行可视化,呈现在web页面中。
本发明的有益效果为:本方法及系统通过使用hadoop来搭建集群,使用flume可以把客户端中的不同的数据源的信息收集起来,存储到kafka的分布式系统中,通过对kafka中数据的进行etl清洗操作,把数据存到hbase中去,利用hbase的rowkey,可以快速便捷的查询hbase中的数据,高效的解决了接收和处理海量数据的瓶颈,也解决了实时查询响应慢的情况,使用hive基于spark的计算引擎,可以完成各种各样的运算,支持分布式计算,大大的提高了统计运算的速度,本申请使用大数据分析机顶盒收视的统计方式及系统,从而大大的提高了机顶盒收集统计数据的处理速度和能力,能支持多元化的信息收集,不仅降低了服务器的成本,也给制定相关销售策略赢得更多的时间。
附图说明
图1为本发明的方法流程图。
具体实施方式
如图1所示,一种基于大数据分析的机顶盒收视统计方法,包括步骤:
s1,使用http的api接口实时接收及flume程序收集客户端不断上传的海量日志文件,flume的管道是基于事务的,保证了数据在传送和接收时的一致性。
s2,把api接口和flume采集到的数据存储到kafka分布式订阅系统中;
s3,编写代码程序,消费kafka中的数据,并进行etl数据清洗的操作,通过抽取,转换,加载,去除脏数据,建立结构化数据存储到hbase中;
s4,使用hive关联hbase中的数据,hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供sql查询功能,能将sql语句转变成mapreduce任务来执行,底层计算可以使用spark、tez等,sql语句实现快速mapreduce统计,使mapreduce变得更加简单;
s5,将hive进行数据提取、转化、加载分析过后的有价值的数据存储到mysql中,进行统计汇总和/或呈现。
s5中队存储到mysql中的数据进行统计汇总和/或呈现的方法包括对于需要实时查询的日志或者其他信息,可以直接查询hbase中的结构化数据,可以进行离线统计分析,转换生成机器学习需要的数据格式,进行模型训练,可以汇总分析月使用情况存储到mysql的数据,进web可视化管理。
其中,web可视化管理的方法包括使用前端的echarts插件将数据进行可视化,比如折线图,柱状图,扇形,更加的直观清楚呈现在web页面中。机顶盒分布的区域,可以通过世界地图的方式展现出来,以及机顶盒的每天的访问量,用户喜爱的节目,用户观看时长,在线观看所占的百分比等其它收视相关的都可以一一呈现出来。通过web可视化管理,使数据发挥了更大的作用,也变得更加有参考的价值性。
一种基于大数据分析的机顶盒收视统计系统,包括:
数据采集单元,用于使用http的api接口实时接收和flume程序收集客户端不断上传的海量日志文件,flume的管道是基于事务的,保证了数据在传送和接收时的一致性;
数据的预处理单元,用于将api接口和flume采集到的数据存储到kafka分布式订阅系统中;
数据清洗单元,用于编写代码程序,消费kafka中的数据,并进行etl数据清洗的操作,通过抽取,转换,加载,去除脏数据,建立结构化数据存储到hbase中;
数据分析处理单元,用于使用hive关联hbase中的数据,hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供sql查询功能,能将sql语句转变成mapreduce任务来执行,底层计算可以使用spark、tez等。sql语句实现快速mapreduce统计,使mapreduce变得更加简单。
数据存储单元,将hive进行数据提取、转化、加载分析过后的有价值的数据存储到mysql中,进行汇总统计。数据统计汇总和呈现单元,用于对数据进行统计汇总和/或呈现;
数据统计汇总和呈现单元,用于对需要实时查询的日志或者其他信息,直接查询hbase中的结构化数据,进行离线统计分析,转换生成机器学习需要的数据格式,进行模型训练,还可以汇总分析月使用情况存储到mysql的数据,通过可视化单元进行web可视化管理;
可视化单元,用于使用前端的echarts插件将数据进行可视化,比如折线图,柱状图,扇形,更加的直观清楚呈现在web页面中。机顶盒分布的区域,可以通过世界地图的方式展现出来,以及机顶盒的每天的访问量,用户喜爱的节目,用户观看时长,在线观看所占的百分比等其它收视相关的都可以一一呈现出来。通过web可视化管理,使数据发挥了更大的作用,也变得更加有参考的价值性。
本实施例的方法及系统都通过使用hadoop,可以更加的方便可靠高效的处理和分析这些数据,而且对于实时查询的数据,也能达到秒级的响应。同时因为它的高效性,能够在节点之间动态的移动数据,还可以方便地扩展到数以千计的节点中。支持可伸缩部署,搭建起来比较容易管理和维护。hadoop有高容错性的特点,并且设计用来部署在低廉的硬件上,也大大的降低了项目硬件的成本。flume的采集,可以定制很多的数据源,减少开发量。spark是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序,可以独立在集群中,也可以运行在hadoop中,提高了统计数据的速度。
以上所属实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制,应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!