高维特征的处理方法、装置、设备及计算机可读存储介质与流程
本发明涉及图像处理领域,具体涉及一种高维特征的处理方法、装置、设备及计算机可读存储介质。
背景技术:
深度学习已经在许多领域得到深入的应用,例如在人脸识别相关的应用场景中,监控系统采集实时视频或图像,再经过人脸识别系统提取的人脸高维特征的数量级极大,例如每年多达几十亿。在人脸图像特征库中进行相似度的搜索是最重要的功能需求。目前人脸特征库进行海量图像特征的搜索效果极差,由于海量人脸特征在高维空间中的分布特点难以估计,故无法在完成秒级查询的同时达到很高的召回率。
对于海量的十亿级或者百亿级高维特征(例如512维及以上)的相似度搜索不可能使用暴力方法比对计算每一个特征向量的相似度,暴力比对搜索消耗的时间和空间难以承受。
目前的搜索方法将人脸这种空间分布情况比较复杂的特征向量进行子空间切分以后,各个子空间中特征数目差别很大,相交子空间边缘特征向量的子空间划分往往不合理;另外,从算法逻辑上也不能够保证相似性搜索的应搜尽搜,存在死角的可能性。
技术实现要素:
本发明提供一种高维特征的处理方法,其包括合成超链图构造过程和合成超链图搜索过程。
合成超链图构造过程包括:依次对所有的特征向量点,通过预设赋值方案确定当前特征向量点的插入图层并利用当前特征向量点参与构造m个索引图层;利用所有特征向量点参与构造全量图层;其中,m个索引图层为第m索引图层、第m-1索引图层…第1索引图层;当预设赋值方案进行操作得到结果值为t,则所确定的当前特征向量点的插入图层为第t索引图层、第t-1索引图层…第1索引图层。
合成超链图搜索过程包括:索引图层搜索阶段:依次从第m索引图层至第1索引图层,将目标特征向量点插入当前索引图层并进行索引图层筛选操作,直至该层中目标特征向量点与其最近邻点的距离不再缩小,再在下一索引图层进行索引图层筛选操作;全量图层搜索阶段:将目标特征向量点插入全量图层并进行全量图层筛选操作,直至目标特征向量点与其最近邻点的距离不再缩小;其中,m为预设的大于等于1的整数,t为大于等于1且小于等于m的整数。
在一种改进的方案中,预设赋值方案为公式floor(-ln(uniform(0,1))×m);其中,floor()表示向下取整,ln()表示取对数,uniform(0,1)表示在0到1的均匀分布数值中随机取出一个实数。
在一种改进的方案中,利用当前特征向量点参与构造m个索引图层的过程中,第t索引图层的构造方式为:将当前特征向量点插入第t索引图层,将已插入的特征向量点按照由近至远的顺序与当前特征向量点进行连线,且与当前特征向量点进行连线的点的个数以m为限;其中,t为大于等于1且小于等于t的整数,m为大于等于1的整数。
在一种改进的方案中,利用当前特征向量点参与构造全量图层的过程中,将当前特征向量点插入全量图层,将已插入的特征向量点按照由近至远的顺序与当前特征向量点进行连线,且与当前特征向量点进行连线的点的个数以m为限;从当前特征向量点所连接的点中查找出当前特征向量点的最近邻点,将当前特征向量点到该最近邻点的距离与距离阈值做比较;若判断当前特征向量点到该最近邻点的距离小于等于距离阈值,则将当前特征向量点归入到该最近邻点所在的子图中;若判断当前特征向量点到该最近邻点的距离大于距离阈值,则以当前特征向量点为基准开设一个新的子图;其中,m为大于等于1的整数。
在一种改进的方案中,索引图层搜索阶段中,在第n索引图层中,第1次索引图层筛选操作为:将与开始点由近至远相连接的m个点加入排序队列并加入出发队列,计算排序队列中目标特征向量点与其最近邻点的距离;当第n索引图层为第m索引图层时,开始点为第m索引图层中的第一个插入点或某一点;当第n索引图层为非第m索引图层时,开始点为第n+1索引图层中目标特征向量点的最近邻点;第k+1次索引图层筛选操作为:对第k次索引图层筛选操作所形成的出发队列中的每个点,将与这些点由近至远相连接的m个点加入排序队列并加入出发队列,计算排序队列中目标特征向量点与其最近邻点的距离,去除出发队列中已经被查找过的点;n为大于等于1且小于等于m的整数,k为大于等于1的整数。
在一种改进的方案中,全量图层搜索阶段中,第1次全量图层筛选操作为:以第1索引图层中目标特征向量点的最近邻点为开始点,将与开始点由近至远相连接的m个点加入排序队列并加入出发队列,从排序队列中查找出与目标特征向量点的距离小于等于距离阈值的点,并计算排序队列中目标特征向量点与其最近邻点的距离;第k+1次全量图层筛选操作为:对第k次全量图层筛选操作所形成的出发队列中的每个点,将与这些点由近至远相连接的m个点加入排序队列并加入出发队列,从排序队列中查找出与目标特征向量点的距离小于等于距离阈值的点,并计算排序队列中目标特征向量点与其最近邻点的距离,去除出发队列中已经被查找过的点;对各次全量图层筛选操作的排序队列中查找出的与目标特征向量点的距离小于等于距离阈值的点以及这些点所在子图中的点,将这些点按照与目标特征向量点的距离由近至远排序,并作为搜索结果;k为大于等于1的整数。
在一种改进的方案中,合成超链图构造过程中,构造第n索引图层的特征向量点的数量多于构造第n+1索引图层的特征向量点的数量,且第n索引图层中包括第n+1索引图层中的所有特征向量点;合成超链图构造过程中,利用当前特征向量点先后参与构造m个索引图层和参与构造全量图层,或者,利用当前特征向量点先后参与构造全量图层和参与构造m个索引图层,或者,利用当前特征向量点同时参与构造m个索引图层和参与构造全量图层;其中,n为大于等于1且小于等于m的整数;处理方法还包括输出搜索结果过程。
本发明还提供一种高维特征的处理装置,其包括接收单元、合成超链图构造单元、合成超链图搜索单元和输出单元;合成超链图构造单元包括索引图层构造模块、全量图层构造模块和合成超链图插入模块;合成超链图搜索单元包括索引图层搜索模块和全量图层搜索模块。
接收单元分别连接至合成超链图插入模块、全量图层构造模块和索引图层搜索模块;合成超链图插入模块、索引图层构造模块和索引图层搜索模块依次连接;全量图层构造模块连接、全量图层搜索模块和输出单元依次连接。
接收单元用于接收特征向量点;合成超链图插入模块用于通过预设赋值方案确定当前特征向量点的插入图层;索引图层构造模块用于利用当前特征向量点参与构造m个索引图层;全量图层构造模块用于利用所有特征向量点参与构造全量图层;其中,m个索引图层为第m索引图层、第m-1索引图层…第1索引图层;当预设赋值方案进行操作得到结果值为t,则所确定的当前特征向量点的插入图层为第t索引图层、第t-1索引图层…第1索引图层。
接收单元还用于接收目标特征向量点;索引图层搜索模块用于依次从第m索引图层至第1索引图层,将目标特征向量点插入当前索引图层并进行索引图层筛选操作,直至该层中目标特征向量点与其最近邻点的距离不再缩小,再在下一索引图层进行索引图层筛选操作;全量图层搜索模块用于将目标特征向量点插入全量图层并进行全量图层筛选操作,直至目标特征向量点与其最近邻点的距离不再缩小。其中,m为预设的大于等于1的整数,t为大于等于1且小于等于m的整数。
本发明还提供一种高维特征的处理设备,其包括存储器,用于存储程序;还包括处理器,用于通过执行存储器存储的程序以实现上述方法。
本发明还提供一种计算机可读存储介质,其包括程序,程序能够被处理器执行以实现上述方法。
本申请提出了高维特征的处理方法、装置、设备及计算机可读存储介质,该方法是一种海量高维特征存储检索的合成超链图(shg,synthetichyperlinkedgraphs)处理方法,利用特征向量之间的相似性构建索引图层和全量图层,搜索过程从索引图层的上层往下不断切换,直到全量图层完成数据搜索任务,索引图层的数据量有限,故计算速度可以达到极快。根据选取的预设数量的高维特征向量构建多个索引图层,大幅降低了搜索索引图层中近似最近邻点的计算量。在多个索引图层中的搜索到最近邻点后逐层向下深入到全量图层中,从而在各层中往下不断逼近最近邻点。
附图说明
图1为实施例一的方法流程图;
图2为实施例一的合成超链图示意图;
图3为实施例一中已确定当前特征向量点插入图层的合成超链图示意图;
图4为实施例一合成超链图构造过程中的索引图层示意图;
图5为实施例一合成超链图构造过程中的全量图层示意图;
图6为实施例一中已插入目标特征向量点的合成超链图示意图;
图7为实施例一合成超链图搜索过程中的索引图层示意图;
图8为实施例一合成超链图搜索过程中的全量图层示意图;
图9为实施例二的装置结构示意图;
图10为实施例五的方法流程图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。其中不同实施方式中类似元件采用了相关联的类似的元件标号。在以下的实施方式中,很多细节描述是为了使得本发明能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。在某些情况下,本发明相关的一些操作并没有在说明书中显示或者描述,这是为了避免本发明的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
本文中为部件所编序号本身,例如“第一”、“第二”等,仅用于区分所描述的对象,不具有任何顺序或技术含义。而本发明所说“连接”、“联接”,如无特别说明,均包括直接和间接连接(联接)。
本文中,m为大于等于1的整数,t为大于等于1且小于等于m的整数,n为大于等于1且小于等于m的整数,m为大于等于1的整数,t为大于等于1且小于等于t的整数,k为大于等于1的整数。即,1≤m,1≤t≤m,1≤n≤m,1≤m,1≤t≤t,1≤k。
实施例一:
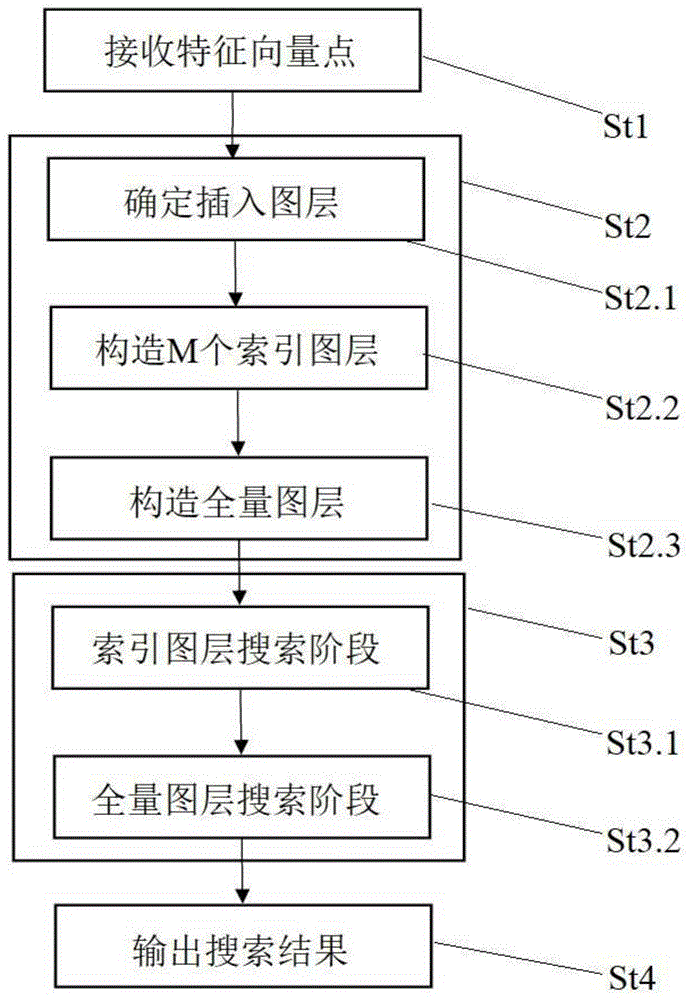
如图1所示为本实施例的高维特征的处理方法,其包括如下过程:
st1、接收特征向量点。
该过程可以是一次接收所有特征向量点,也可以是根据st2的流程对各个特征向量进行依次接收。
st2、合成超链图构造过程。
依次对所有的特征向量点,通过预设赋值方案确定当前特征向量点的插入图层并利用当前特征向量点参与构造m个索引图层;利用所有特征向量点参与构造全量图层。
其中,m个索引图层为第m索引图层、第m-1索引图层…第1索引图层;全量图层为第0索引图层。
当前特征向量点将经过st2.1、st2.2、st2.3三个步骤。本实施例是为便于阐述,故分为三个步骤进行分析,本领域技术人员应当理解,索引图层和全量图层的构造是相互独立的,st2.3可以设置于st2.1、st2.2之前;或者,可以一边执行,同时一边执行st2.3。即,可以利用当前特征向量点先后参与构造m个索引图层和参与构造全量图层,或者,利用当前特征向量点先后参与构造全量图层和参与构造m个索引图层,或者,利用当前特征向量点同时参与构造m个索引图层和参与构造全量图层。
m是预设的值,如图2所示,本实施例期望构造的合成超链图包括由上至下的第m索引图层indexlayerm、第m-1索引图层indexlayerm-1…第2索引图层、第1索引图层、全量图层datalayer0。
st2.1、预设赋值方案为公式floor(-ln(uniform(0,1))×m);其中,floor()表示向下取整,ln()表示取对数,uniform(0,1)表示在0到1的均匀分布数值中随机取出一个实数,×为乘号。
轮到当前特征向量点时,当利用公式floor(-ln(uniform(0,1))×m)进行计算得到结果值为t,则所确定的当前特征向量点的插入图层为第t索引图层、第t-1索引图层…第1索引图层。当利用公式floor(-ln(uniform(0,1))×m)进行计算得到结果值为0,则确定的当前特征向量点只插入全量图层。
如图3所示,若计算得到结果值为t,则所确定的当前特征向量点的插入图层为第t索引图层indexlayert、第t-1索引图层…第1索引图层。
例如,轮到当前特征向量点时,从0到1的均匀分布数值中随机取出一个实数1/16,则利用公式floor(-ln(uniform(0,1))×m)进行计算所得到的结果为4,则所确定的当前特征向量点的插入图层为第4索引图层、第3索引图层、第2索引图层、第1索引图层。
st2.2、利用当前特征向量点参与构造m个索引图层的过程中,第t索引图层的构造方式为:
将当前特征向量点插入第t索引图层,通过朴素查找法查找到与当前特征向量点最近的m个点,将已插入的这m个特征向量点按照与当前特征向量点由近至远的顺序与当前特征向量点进行连线。本方法中,与当前特征向量点进行连线的点的个数以m为限,m是预设的数值。例如设定m=3,如果图层中只能查找到2个点,则只将这2个点与当前特征向量点进行连线。
本实施例中,为便于理解分析,取m=3。例如,构造第t个索引图层时,如图4所示,构造过程如下:
第1个插入到图层的特征向量点为p1,p1无连线;
第2个插入到图层的特征向量点为p2,则p2连接p1;
第3个插入到图层的特征向量点为p3,则p3连接p1和p2;
第4个插入到图层的特征向量点为p4,则p4连接p1、p2和p3;
第5个插入到图层的特征向量点为p5,已插入的特征向量点与该新特征向量点p5由近至远的顺序为p1、p4、p3、p2,则按照该顺序,p5连接p1、p4和p3;
第6个插入到图层的特征向量点为p6,已插入的特征向量点与该新特征向量点p6由近至远的顺序为p2、p3、p4、p1、p5,则按照该顺序,p6连接p2、p3和p4;
......以此类推;
对当前特征向量点为p’,则按照已插入的特征向量点与该新特征向量点p’由近至远的顺序进行连线。
为便于本文对技术方案进行清楚描述,t个索引图层至全量图层的顺序为:第t索引图层、第t-1索引图层…第2索引图层、第1索引图层、全量图层。t个索引图层的构造顺序优选为:第t索引图层、第t-1索引图层…第2索引图层、第1索引图层。全量图层作为最底层即第0层。
本领域技术人员应当理解,本申请其它的实施方式中,t个索引图层至全量图层的顺序还可以命名为:第1索引图层、第2索引图层…第t-1索引图层、第t索引图层、全量图层。给各个索引图层进行编号或者命名只是技术人员根据需求或习惯而定,无论是以倒序的方式还是以顺序的方式,编号本身并不对技术方案造成限制。
第t索引图层所使用的特征向量点的数量多于第t+1索引图层所使用的特征向量点的数量,且第t索引图层中包含第t+1索引图层中的所有特征向量点。例如,第t+1索引图层中具有p1至p60的特征向量点,则第t索引图层不仅要具有p1至p60的特征向量点,还更多地具有p61至p90的特征向量点;第t索引图层中具有p1至p90的特征向量点,则第t-1索引图层不仅要具有p1至p90的特征向量点,还更多地具有q1至q70的特征向量点。
本领域技术人员应当理解,该过程中,t个索引图层可以是依次独立被构造;也可以是在构造好第t+1索引图层后,保留该第t+1索引图层,再以第t+1索引图层为基础继续插入特征向量点从而构造出第t索引图层;也可以是在构造好第t索引图层后,保留该第t索引图层,再选取第t索引图层中的部分特征向量点来构造出第t+1索引图层。
st2.3、本过程利用所有特征向量点构造全量图层,具体包括如下步骤:
st2.31、利用当前特征向量点参与构造全量图层的过程中,将当前特征向量点插入全量图层,通过朴素查找法查找到与当前特征向量点最近的m个点,将已插入的这m个点按照与前特征向量点由近至远的顺序与当前特征向量点进行连线。本方法中,与当前特征向量点进行连线的点的个数以m为限,m是预设的数值。例如设定m=3,如果图层中只能查找到2个点,则只将这2个点与当前特征向量点进行连线。
st2.32、从当前特征向量点所连接的m个点中查找出当前特征向量点的最近邻点,将当前特征向量点到该最近邻点的距离与距离阈值f做比较。
其中,距离阈值f是预设的值。通过对高维特征所表达的相似度进行预研训练,可以获得特征向量之间可靠的相似度阈值。
st2.33、若判断当前特征向量点到该最近邻点的距离小于等于距离阈值f,则将当前特征向量点归入到该最近邻点所在的子图中,即把当前特征向量点的子图编号设置为与最近邻点一致。
st2.34、若判断当前特征向量点到该最近邻点的距离大于距离阈值f,则以当前特征向量点为基准开设一个新的子图,即赋予当前特征向量点一个递增的子图编号。
首个插入点的子图编号设置为1,通过该过程即可将相似点聚合到一个子图里。
其中,当前特征向量点的最近邻点即为与当前特征向量点距离最近的点。
例如,如图5所示,第1个插入到图层的特征向量点为p1,p1无连线且无比较;以p1为基准开设一个新的子图subgraph1;
第2个插入到图层的特征向量点为p2,则p2连接p1;p2为p1的最近邻点,将p1到p2的距离与f作比较,判断结果为p1到p2的距离大于f,则以p2为基准开设一个新的子图subgraph2;
第3个插入到图层的特征向量点为p3,则p3连接p1和p2;p1为p3的最近邻点,将p3到p1的距离与f作比较,判断结果为p3到p1的距离大于f,则以p3为基准开设一个新的子图subgraph3;
第4个插入到图层的特征向量点为p4,则p4连接p1、p2和p3;p2为p4的最近邻点,将p4到p2的距离与f作比较,判断结果为p4到p2的距离大于f,则以p4为基准开设一个新的子图subgraph4;
第5个插入到图层的特征向量点为p5,已插入的特征向量点与p5由近至远的顺序为p1、p4、p3、p2,则按照该顺序,p5连接p1、p4和p3;p1为p5的最近邻点,将p5到p1的距离与f作比较,判断结果为p5到p1的距离大于f,则以p5为基准开设一个新的子图subgraph5;
第6个插入到图层的特征向量点为p6,已插入的特征向量点与p6由近至远的顺序为p2、p3、p4、p1、p5,则按照该顺序,p6连接p2、p3和p4;p2为p6的最近邻点,将p6到p2的距离与f作比较,判断结果为p6到p2的距离小于f,则将p6归入到p2所在的子图subgraph2中;
第7个插入到图层的特征向量点为p7,已插入的特征向量点与p7由近至远的顺序为p1、p3、p5、p4、p2、p6,则按照该顺序,p7连接p1、p3和p5;p1为p7的最近邻点,将p7到p1的距离与f作比较,判断结果为p7到p1的距离小于f,则将p7归入到p1所在的子图subgraph1中;
第8个插入到图层的特征向量点为p8,已插入的特征向量点与p8由近至远的顺序为p6、p2、p3、p4、p1、p7、p5,则按照该顺序,p8连接p6、p2和p3;p6为p8的最近邻点,将p8到p6的距离与f作比较,判断结果为p8到p6的距离小于f,则将p8归入到p6所在的子图subgraph2中;
......以此类推;对新插入到图层的特征向量点为p’也进行上述操作。
这样,各个点不但具有唯一id编号,也具有子图编号。
st3、合成超链图搜索过程。该过程包括索引图层搜索阶段和全量图层搜索阶段。如图6所示,目标特征向量点p0所经历的图层为第m索引图层indexlayerm、第m-1索引图层indexlayerm-1…第1索引图层、全量图层datalayer0。
st3.1、索引图层搜索阶段为:依次从第m索引图层至第1索引图层,将目标特征向量点插入当前索引图层并进行索引图层筛选操作,直至该层中目标特征向量点与其最近邻点的距离不再缩小,再在下一索引图层进行索引图层筛选操作。
具体地,选取第m索引图层至第1索引图层中的第n索引图层为例,在第n索引图层中进行如下多次索引图层筛选操作。
第1次索引图层筛选操作为:将与开始点由近至远相连接的m个点加入排序队列并加入出发队列,计算排序队列中目标特征向量点与其最近邻点的距离;当第n索引图层为第m索引图层时,开始点为第m索引图层中的第一个插入点或某一任意点;当第n索引图层为非第m索引图层时,开始点为第n+1索引图层中目标特征向量点的最近邻点;
第k+1次索引图层筛选操作为:对第k次筛选操作所形成的出发队列中的每个点(点的总数为mk个点减去重复点),将与这些点由近至远相连接的m个点加入排序队列并加入出发队列,计算排序队列中目标特征向量点与其最近邻点的距离,去除出发队列中已经被查找过的点(重复点),则出发队列中点的总数为mk+1个点减去重复点。重复此操作,直至该第n索引图层中目标特征向量点与其最近邻点的距离不再缩小,即完成第n索引图层中的第1次索引图层筛选操作到最后一次索引图层筛选操作,再在下一索引图层即第n-1索引图层进行索引图层筛选操作。
本阶段中,第n索引图层中已经被查找过的点则不再被继续使用,即出发列表里的点需要去重,已经搜索过的点不再加入,保证不再重复搜索,减小计算量。其中,第k次筛选操作所形成的出发队列中的点为mk个点减去重复点,第k+1次筛选操作所形成的出发队列中的点为mk+1个点减去重复点。
另外,作为示例说明,如图7所示,p1到p6是顺序插入的点,所有点都连接到了早先插入点中最近的3个近邻点上。折线是近邻点的连线,因为p2插入较早,虽然距离p1较远也具有近邻连接线,但p1和p2的连线为最重要的“高速公路机制”。索引图层搜索目标点p0近邻点的时候,从p1点进入查找,通过p1和p2的连线即“高速公路机制”绕过p3和p5,快速查找到结果点p2。一个点越早插入就越容易形成与之相关的“高速公路”连接,越晚插入就越难形成与之相关的“高速公路”连接。
在第m索引图层中,通过多次索引图层筛选操作,可以贪婪地遍历第m索引图层的向量点,直到找出第m索引图层中距离目标特征向量距离最短的点。
通过本阶段,先以第m索引图层中的第一个插入点为开始点,找到第m索引图层中目标特征向量点的最近邻点;再切换到第m-1索引图层,以第m索引图层中目标特征向量点的最近邻点为开始点,找到第m-1索引图层中目标特征向量点的最近邻点;...以此类推,再切换到第2索引图层,以第3索引图层中目标特征向量点的最近邻点为开始点,找到第2索引图层中目标特征向量点的最近邻点;再切换到第1索引图层,以第2索引图层中目标特征向量点的最近邻点为开始点,找到第1索引图层中目标特征向量点的最近邻点。
第1索引图层中目标特征向量点的最近邻点将作为全量图层搜索阶段中的开始点。
st3.2、全量图层搜索阶段为:将目标特征向量点插入全量图层并进行全量图层筛选操作,直至目标特征向量点与其最近邻点的距离不再缩小。
具体地,第1次全量图层筛选操作为:以第1索引图层中目标特征向量点的最近邻点为开始点,将与开始点由近至远相连接的m个点加入排序队列并加入出发队列,从排序队列中查找出与目标特征向量点的距离小于等于距离阈值的点,并计算排序队列中目标特征向量点与其最近邻点的距离。
第k+1次全量图层筛选操作为:对第k次筛选操作所形成的出发队列中的每个点,将与这些点由近至远相连接的m个点加入排序队列并加入出发队列,从排序队列中查找出与目标特征向量点的距离小于等于距离阈值的点,并计算排序队列中目标特征向量点与其最近邻点的距离,去除出发队列中已经被查找过的点(重复点)。
本阶段中,全量图层中已经被查找过的点则不再被继续使用,即出发列表里的点需要去重,已经搜索过的点不再加入,保证不再重复搜索,减小计算量。其中,第k次筛选操作所形成的出发队列中的点为mk个点减去重复点,第k次筛选操作所形成的出发队列中的点为mk+1个点减去重复点。
至此,已经得到各次筛选操作的排序队列中查找出的与目标特征向量点的距离小于等于距离阈值的点以及这些点所在子图中的点,将这些点按照与目标特征向量点的距离由近至远排序,并作为搜索结果。
例如,查找出的与目标特征向量点的距离小于等于距离阈值的点为p2、p9、p30,p2所在子图中包含了p2、p6、p8,p9所在子图中包含了p9、p23、p57,p30所在子图中包含了p30、p19、p40、p47、p61,这些点与目标特征向量点的距离由近至远排序为p9、p40、p19、p2、p8、p6、p30、p47、p61、p57、p23,则搜索结果为p9、p40、p19、p2、p8、p6、p30、p47、p61、p57、p23。
本领域技术人员应当理解,既可以是将各次筛选操作全部进行完之后,再将选出的点按照与目标特征向量点的距离由近至远排序;也可以是每进行完一次筛选操作就更新一回排序。
例如,既可以是将各次筛选操作全部进行完之后得到p2、p6、p8、p9、p23、p57、p30、p19、p40、p47、p61,再将这些点排序从而得到搜索结果p9、p40、p19、p2、p8、p6、p30、p47、p61、p57、p23。
也可以是,进行完一次筛选操作后得到p2、p6、p8,更新一回排序从而得到p2、p8、p6;再进行完一次筛选操作后得到p9、p23、p57,更新一回排序从而得到p9、p2、p8、p6、p57、p23;再进行完一次筛选操作后得到p30、p19、p40、p47、p61,更新一回排序从而得到p9、p40、p19、p2、p8、p6、p30、p47、p61、p57、p23。
另外,作为示例说明,如图8所示,p1到p8是顺序插入的点,所有点都连接到了早先插入点中最近的3个近邻点上。折线是近邻点的连线,因为p2插入较早,虽然距离p1较远也具有近邻连接线,但p1和p2的连线为最重要的“高速公路机制”。索引图层搜索目标点p0近邻点的时候,从p1点进入查找,通过p1和p2的连线即“高速公路机制”绕过p3和p5,快速查找到结果点p2,然后从p2点找到p2、p6、p8所在子图,将p6、p8加入排序列表,重新排序后根据输出阈值截断排序列表并输出,完成搜索过程。一个点越早插入就越容易形成与之相关的“高速公路”连接,越晚插入就越难形成与之相关的“高速公路”连接。
st4、输出搜索结果过程。
实施例二:
如图9所示为本实施例的高维特征的处理装置,其包括接收单元10、合成超链图构造单元20、合成超链图搜索单元30和输出单元40。
合成超链图构造单元20包括索引图层构造模块21、全量图层构造模块22和合成超链图插入模块23。合成超链图搜索单元30包括索引图层搜索模块31和全量图层搜索模块32。
接收单元10分别连接至合成超链图插入模块23、全量图层构造模块22和索引图层搜索模块31。合成超链图插入模块23、索引图层构造模块21和索引图层搜索模块31依次连接。全量图层构造模块22连接、全量图层搜索模块32和输出单元40依次连接。
接收单元10用于接收特征向量点,具体完成实施例一的st1过程。
合成超链图插入模块23用于通过预设赋值方案确定当前特征向量点的插入图层,具体完成实施例一的st2.1过程。
索引图层构造模块21用于利用当前特征向量点参与构造m个索引图层,具体完成实施例一的st2.2过程。
全量图层构造模块22用于利用当前特征向量点参与构造全量图层,具体完成实施例一的st2.3过程。
其中,m个索引图层为第m索引图层、第m-1索引图层…第1索引图层;全量图层为第0索引图层。
索引图层搜索模块31用于依次从第m索引图层至第1索引图层,将目标特征向量点插入当前索引图层并进行索引图层筛选操作,直至该层中目标特征向量点与其最近邻点的距离不再缩小,再在下一索引图层进行索引图层筛选操作,具体完成实施例一的st3.1过程。
全量图层搜索模块32用于将目标特征向量点插入全量图层并进行全量图层筛选操作,直至目标特征向量点与其最近邻点的距离不再缩小,具体完成实施例一的st3.2过程。
输出单元40用于输出搜索结果,具体完成实施例一的st4过程。
本实施例的装置中各单元及模块按照实施例一的方法进行操作,技术方案与实施例一一致,故不再赘述。
实施例三:
本实施例提供一种高维特征的处理设备,其存储器,用于存储程序;还包括处理器,用于通过执行存储器存储的程序以实现实施例一的方法。
实施例四:
本实施例提供一种计算机可读存储介质,其包括程序,程序能够被处理器执行以实现实施例一的方法。
实施例五:
如图10所示,本实施例的处理方法包括包括如下过程:
st1、接收特征向量点;
st2、合成超链图构造过程;
st3、合成超链图搜索过程(具体包括st3.1索引图层搜索阶段和st3.2全量图层搜索阶段);
st4、输出搜索结果。
本实施例与实施例一的区别在于,st2过程中,先后执行的步骤为s2.1构造全量图层、s2.2确定插入图层、s2.3构造m个索引图层。本实施例其它技术特征与实施例一一致,故不再赘述。
本申请提出了一种高维特征的处理方法、装置、设备及计算机可读存储介质,该方法是一种海量高维特征存储检索的合成超链图处理方法,利用特征向量之间的相似性构建索引图层和全量图层,搜索过程从索引图层的上层往下不断切换,直到全量图层完成数据搜索任务,索引图层的数据量有限(可以很少),故计算速度可以达到极快。根据选取的预设数量的高维特征向量构建多个索引图层,大幅降低了搜索索引图层中近似最近邻点的计算量。在多个索引图层中的搜索到最近邻点后逐层向下深入到全量图层中,从而在各层中往下不断逼近最近邻点。
在搜索的时候先通过索引图层中向量的比对,在全量图层可以快速定位到目标点附近的位置,从而可以快速到达目标点在全量图层的近邻向量点,然后从这个近邻向量点出发在全量图层的多个子图数据中进行搜索,整体搜索时间大大缩小。在全量图层中根据相似度阈值过滤条件,把相似度很高的多个近邻点预先建立可靠的相似聚合子图,搜索的时候可以一次性进入排序列表,降低了计算量并且提高了查全率。
通过本申请的技术方案,能够合理地对海量人脸高维特征向量进行子空间(即全量图层中的子图)划分,把搜索目标(即目标特征向量点)快速定位到子空间的算法,然后在子空间中搜索,并且能大幅提高搜索的查全率、查准率以及搜索速度。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 还没有人留言评论。精彩留言会获得点赞!