一种模拟妈妈与婴幼儿交互的方法及智能系统与流程
本发明涉及人工智能领域,尤其涉及一种模拟妈妈与婴幼儿交互的方法及智能系统。
背景技术:
现在社会妈妈一般休完产假就会继续早出晚归上班,婴幼儿由老人或他人代为照顾,妈妈与婴幼儿相处的时间较少,而婴幼儿都非常依赖妈妈,妈妈上班时间只能通过电话或视频做短时间交互。
妈妈在上班时间能与婴幼儿交互的时间非常有限,婴幼儿不能与妈妈进行随时的交互。
技术实现要素:
本发明提供了一种模拟妈妈与婴幼儿交互的方法,包括执行以下步骤:
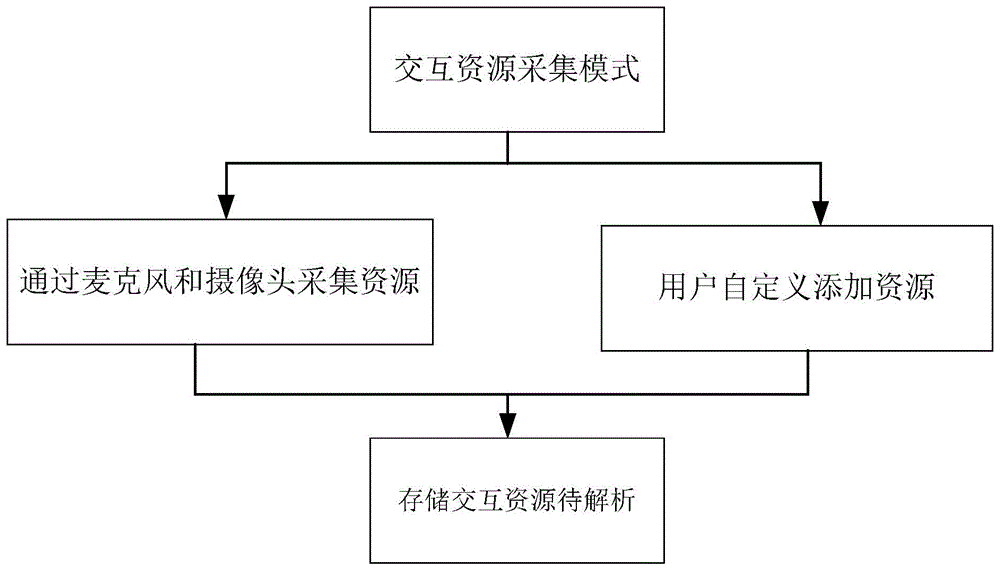
步骤1:交互资源采集;妈妈与婴幼儿相处时,开启设备资源采集模式,包括视频采集和音频采集,拍摄妈妈与婴幼儿相处时的视频和音频,并存储所采集交互资源待解析;
步骤2:交互资源解析;根据步骤1采集的音频资源解析出妈妈与婴幼儿的交互行为,再把声音分组形成各种交互组,最后把所有的交互组存储为资源库;
步骤3:模拟交互模式;妈妈不在婴幼儿身边时,开启设备交互模式,模拟妈妈与婴幼儿进行交互。
作为本发明的进一步改进,在所述步骤1中,所述资源采集模式包括以下两种方式:
a.通过麦克风和摄像头采集资源;
b.用户自定义添加资源。
作为本发明的进一步改进,在所述步骤2中,妈妈与婴幼儿交互行为的数据包括婴幼儿发出的声音,妈妈回应的声音,妈妈主动发出的声音,婴幼儿回应的声音。
作为本发明的进一步改进,在所述步骤2中,还包括执行以下步骤:
s1步骤:将步骤1存储的交互资源按时间解析人声;
s2步骤:将s1步骤解析的人声识别和分类,分为妈妈的声音和婴幼儿的声音;
s3步骤:对声音进行分组,形成交互声音组;
s4步骤:把所有解析的交互组存储为资源库存。
作为本发明的进一步改进,在所述步骤3中,还包括执行以下步骤:回应步骤:婴幼儿发出某种声音,设备采集到后,在已解析的资源库中查询所属交互组,从交互组中得到妈妈回应的声音或者视频,设备使用该声音回应婴幼儿,有视频时能同时播放视频;
主动发声步骤:用户或设备选择妈妈主动发出声音的交互组,从交互组取出妈妈的声音或相关视频,设备用妈妈的声音或相关视频与婴幼儿交互。
本发明还公开了一种模拟妈妈与婴幼儿交互的智能系统,包括以下单元:
交互资源采集单元:用于妈妈与婴幼儿相处时,开启设备资源采集模式,包括视频采集和音频采集,拍摄妈妈与婴幼儿相处时的视频和音频,并存储所采集交互资源待解析;
交互资源解析单元:用于将交互资源采集单元采集的音频资源解析出妈妈与婴幼儿的交互行为,再把声音分组形成各种交互组,最后把所有的交互组存储为资源库;
模拟交互模式单元:用于妈妈不在婴幼儿身边时,开启设备交互模式,模拟妈妈与婴幼儿进行交互。
作为本发明的进一步改进,在所述交互资源采集单元中,所述资源采集模式包括以下两种方式:
a.通过麦克风和摄像头采集资源;
b.用户自定义添加资源。
作为本发明的进一步改进,在所述交互资源采集单元中,妈妈与婴幼儿交互行为的数据包括婴幼儿发出的声音,妈妈回应的声音,妈妈主动发出的声音,婴幼儿回应的声音。
作为本发明的进一步改进,在所述步骤2中,还包括执行以下步骤:
s1步骤:将步骤1存储的交互资源按时间解析人声;
s2步骤:将s1步骤解析的人声识别和分类,分为妈妈的声音和婴幼儿的声音;
s3步骤:对声音进行分组,形成交互声音组;
s4步骤:把所有解析的交互组存储为资源库存。
作为本发明的进一步改进,在所述模拟交互模式单元中,还包括以下模块:
回应模块:用于婴幼儿发出某种声音,设备采集到后,在已解析的资源库中查询所属交互组,从交互组中得到妈妈回应的声音或者视频,设备使用该声音回应婴幼儿,有视频时能同时播放视频;
主动发声模块:用于用户或设备选择妈妈主动发出声音的交互组,从交互组取出妈妈的声音或相关视频,设备用妈妈的声音或相关视频与婴幼儿交互。
本发明的有益效果是:1.本发明的一种模拟妈妈与婴幼儿交互的方法和智能系统,在妈妈不在婴幼儿身边时模拟妈妈与婴幼儿进行交互;2.本发明的一种模拟妈妈与婴幼儿交互的智能系统采集音视频资源并解析成资源库,在交互模式下利用资源库模拟妈妈与婴幼儿进行交互。
附图说明
图1是本发明的交互资源采集流程图;
图2是本发明的交互资源解析流程图;
图3是本发明的模拟妈妈与婴幼儿交互流程图。
具体实施方式
如图1-3所示,本发明公开了一种模拟妈妈与婴幼儿交互的方法,包括执行以下步骤:
步骤1:交互资源采集;妈妈与婴幼儿相处时,开启设备资源采集模式,包括视频采集和音频采集,拍摄妈妈与婴幼儿相处时的视频和音频,并存储所采集交互资源待解析,妈妈也可以自己添加音视频资源;
步骤2:交互资源解析;根据步骤1采集的音频资源解析出妈妈与婴幼儿的交互行为,再把声音分组形成各种交互组,比如婴幼儿发出的声音与妈妈回应的声音形成一个交互组,妈妈主动发出的声音形成一个交互组(婴幼儿有回应则加入这个交互组),最后把所有的交互组存储为资源库;比如婴幼儿发出哭泣的声音,妈妈安抚的声音;妈妈唱摇篮曲哄婴幼儿睡觉的声音;妈妈鼓励婴幼儿做出某种行为的声音,婴幼儿完成该行为的声音,以及妈妈鼓励表扬的声音等。
步骤3:模拟交互模式;妈妈不在婴幼儿身边时,开启设备交互模式,模拟妈妈与婴幼儿进行交互。
在所述步骤1中,所述资源采集模式包括以下两种方式:
a.通过麦克风和摄像头采集资源;
b.用户自定义添加资源。
在所述步骤2中,妈妈与婴幼儿交互行为的数据包括婴幼儿发出的声音,妈妈回应的声音,妈妈主动发出的声音,婴幼儿回应的声音。
在所述步骤2中,还包括执行以下步骤:
s1步骤:将步骤1存储的交互资源按时间解析人声;
s2步骤:将s1步骤解析的人声识别和分类,分为妈妈的声音和婴幼儿的声音;
s3步骤:对声音进行分组,形成交互声音组;比如婴幼儿发出的声音与妈妈回应的声音形成一个交互组(婴幼儿有回应则加入这个交互组)。
s4步骤:把所有解析的交互组存储为资源库存。
在所述步骤3中,还包括执行以下步骤:
回应步骤:婴幼儿发出某种声音,设备采集到后,在已解析的资源库中查询所属交互组,从交互组中得到妈妈回应的声音或者视频,设备使用该声音回应婴幼儿,有视频时可同时播放视频;
主动发声步骤:用户或设备选择妈妈主动发出声音的交互组,从交互组取出妈妈的声音或相关视频,设备用妈妈的声音或相关视频与婴幼儿交互;即设备也可模拟妈妈主动发出声音,可选择预设的声音,也可随机播放资源库妈妈主动发出的声音,寻求婴幼儿的回应。
本发明还公开了一种模拟妈妈与婴幼儿交互的智能系统,包括以下单元:
交互资源采集单元:用于妈妈与婴幼儿相处时,开启设备资源采集模式,包括视频采集和音频采集,拍摄妈妈与婴幼儿相处时的视频和音频,并存储所采集交互资源待解析;
交互资源解析单元:用于将交互资源采集单元采集的音频资源解析出妈妈与婴幼儿的交互行为,再把声音分组形成各种交互组,最后把所有的交互组存储为资源库;
模拟交互模式单元:用于妈妈不在婴幼儿身边时,开启设备交互模式,模拟妈妈与婴幼儿进行交互。
在所述交互资源采集单元中,所述资源采集模式包括以下两种方式:
a.通过麦克风和摄像头采集资源;
b.用户自定义添加资源。
在所述交互资源采集单元中,妈妈与婴幼儿交互行为的数据包括婴幼儿发出的声音,妈妈回应的声音,妈妈主动发出的声音,婴幼儿回应的声音。
在所述步骤2中,还包括执行以下步骤:
s1步骤:将步骤1存储的交互资源按时间解析人声;
s2步骤:将s1步骤解析的人声识别和分类,分为妈妈的声音和婴幼儿的声音;
s3步骤:对声音进行分组,形成交互声音组;
s4步骤:把所有解析的交互组存储为资源库存。
在所述模拟交互模式单元中,还包括以下模块:
回应模块:用于婴幼儿发出某种声音,设备采集到后,在已解析的资源库中查询所属交互组,从交互组中得到妈妈回应的声音或者视频,设备使用该声音回应婴幼儿,有视频时可同时播放视频;
主动发声模块:用于用户或设备选择妈妈主动发出声音的交互组,从交互组取出妈妈的声音或相关视频,设备用妈妈的声音或相关视频与婴幼儿交互。
本发明的有益效果是:1.本发明的一种模拟妈妈与婴幼儿交互的方法和智能系统,在妈妈不在婴幼儿身边时模拟妈妈与婴幼儿进行交互;2.本发明的一种模拟妈妈与婴幼儿交互的智能系统采集音视频资源并解析成资源库,在交互模式下利用资源库模拟妈妈与婴幼儿进行交互。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!