一种改进的KNN案例推理检索算法的制作方法
本发明涉及一种检索算法,具体涉及到一种改进的案例推理检索算法。
背景技术:
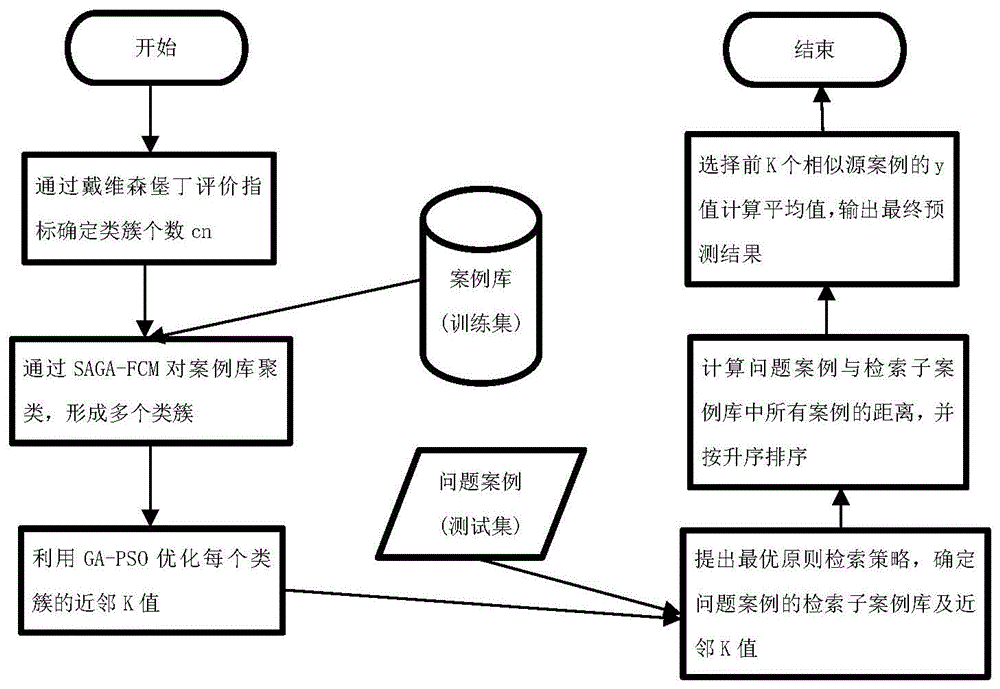
:案例推理(case-basedreasoning,cbr)是人工智能领域一种基于现有知识的问题求解与学习方法,其解决问题的方法是通过重用或修改与问题案例相似性高的历史案例。一般地,最为广泛应用的cbr模型是aamodt和plaza提出的”4r循环“,即以下四个环节:(1)案例检索(retrieve):从案例库中检索与问题案例相似性最高的一个或多个相似源案例。(2)案例重用(reuse):将检索后得到的相似源案例作为建议解;(3)案例修正(revise):对案例重用得到的建议解进行评估。若评估合格,则不需要修正;若评估不合格,则对建议解进行相应的修正;(4)案例保存(retain):将问题案例以及其解决方案作为新案例存储到案例库中。目前,cbr的应用与研究非常广泛。案例检索是案例推理的中心环节。因此,检索算法的性能直接影响案例推理检索结果的精度和执行时间。目前常用的案例推理检索算法有:知识引导法(knowledge-guided)、归纳索引法(induceindexing)、k-最近邻算法(k-nearestneighbor)等。k最近邻算法(k-nearestneighbor,k-nn)是1967年由covert和hartp提出的一种基本分类与回归方法,是最简单的机器学习算法之一。相较于其他常用的检索算法,knn是基于距离的相似性度量方法,不存在检索过程繁杂以及对数据的归纳整理操作。由于k-最近邻算法通过欧氏距离实现相似性计算,所以被广泛的应用于案例推理。目前对于改善传统knn算法性能、提高案例推理检索效率的研究颇多。其中:樊瑞宣等提出一种个性化k近邻的检索算法,其每个样本的近邻k值通过算法自动确定。但是该算法需要对每个样本优化近邻k值,因此时间复杂度相对较高。万碧君等提出一种改进k最近邻回归建模算法。但其采用的k-means以及粒子群算法都存在局部最优解的问题且粒子群算法不易收敛。技术实现要素:本发明的目的是提供一种改进的knn案例推理检索算法,可以显著提高预测结果的精度。本发明的上述技术目的是通过以下技术方案得以实现的:一种改进的knn案例推理检索算法,所述算法包括以下步骤:s1,遗传模拟退火-模糊c均值聚类算法对案例库聚类,形成多个类簇;s2,改进的遗传-粒子群混合算法优化各类簇近邻k值;s3,最优原则检索策略确定检索子案例库及近邻k值。进一步地,所述步骤s1具体包括以下步骤:s1.1假设一个数据集x有n个样本,聚类为cn类,其目标函数为:其中:uk为隶属度函数;dij为欧几里得距离,xi为第i个样本,cj为第j个类簇中心;b为加权参数,取值范围[1inf];隶属度函数:类簇中心cj:s1.2,初始化种群控制参数:种群规模pop_size,最大进化次数max_iterate,交叉概率pc,变异概率pm,退火初始温度tstart,冷却系数j,终止温度tend,类簇个数cn;s1.3,随机初始化cn个类簇中心,并生成初始种群chrom,对每个类簇中心用公式(2)计算各样本的隶属度,以及用公式(1)计算每个个体的适应度值fi,其中i=1,2,…,pop_size;s1.4,设置进化迭代参数iterate=0;s1.5,对种群chrom进行选择、交叉、变异等遗传操作,对新产生的个体用公式(2)、(3)计算各样本的隶属度、以及cn个类簇中心,并用公式(1)计算每一个体的适应度值fi;若fi>fi,则新个体替换旧个体;否则,以概率p=exp((fi-fi)t)接受新个体,抛弃旧个体;s1.6,令iterate=iterate+1,若iterate<max_iterate,则转至步骤s1.5;否则执行下一步;s1.7,令ti=j*ti-1,若ti>tend,则转至步骤s1.4;否则,输出最优解。进一步地,所述步骤s2具体包括以下步骤:s2.1,初始化粒子群并对其编码,采用真实值整数编码;如:02,12,36;s2.2,计算各类簇中每个案例与同类簇其他案例的距离,并将距离值按升序排序;s2.3,通过适应度函数对每个粒子进行适应度值的计算,其中,适应度函数为当前k值的均方误差值mse;即公式(4):其中,n为类簇内案例的个数;yj,real为第j个案例y值的真实值;yj,pre为第j个案例y值的预测值,如公式(5)所示:其中:yi为升序排序后前k个案例y值的真实值;s2.4,根据粒子适应度值更新粒子最优值pbest以及群体最优值gbest;s2.5,将群体最优值gbest十位上的数值对应交叉到粒子值的十位上,若新的粒子的适应度值优于未交叉粒子的适应度值,则更新粒子以及其适应度值;例如:群体最优值gbest=16,当前粒子individual=32,交叉后的粒子new_individual=12;s2.6;对粒子上的个位值、十位值进行变异,若新的粒子的适应度值优于未变异粒子的适应度值,则更新粒子以及其适应度值;s2.7,循环执行步骤s2.3-s2.5,直到满足结束迭代的条件。进一步地,所述步骤s3具体包括以下步骤:s3.1,通过公式(6)计算问题案例与各类簇中心的距离dist;s3.2,将各距离dist按升序排列成(dist1;dist2;…;distcn),并通过公式(7)计算dist;dist=dist2-dist1(7)其中:dist1、dist2为排序后的值;s3.3,ifdist>阈值;s3.4,dist1对应的子类簇为检索子案例库;s3.5,k=k1;s3.6,else;s3.7,dist1与dist2对应的子类簇都作为检索子案例库;s3.8,与现有技术相比,本发明具有以下有益效果:本发明对传统的knn检索算法进行了改进:首先,利用遗传模拟退火-模糊c均值聚类算法对案例库聚类,形成多个类簇;其次,通过改进的遗传-粒子群混合算法优化各类簇近邻k值;最后提出最优原则检索策略,确定检索子案例库及近邻k值,通过mackey-glass混沌时间序列数据进行仿真预测;相较于传统knn检索算法,本发明的检索算法预测结果的精度显著提高。附图说明图1是本发明的算法流程图;图2是本发明的预测结果图;图3是本发明的局部预测结果图(样本为0-60范围内);图4是本发明的局部预测结果图(样本为65-78范围内);图5是本发明的局部预测结果图(样本为105-135范围内);图6是本发明的局部预测结果图(样本为180-210范围内)。具体实施方式以下结合附图及实施例对本发明作进一步详细说明。实施例:如图1-图6所示,一种改进的knn案例推理检索算法,所述算法包括以下步骤:s1,遗传模拟退火-模糊c均值聚类算法对案例库聚类,形成多个类簇;s2,改进的遗传-粒子群混合算法优化各类簇近邻k值;s3,最优原则检索策略确定检索子案例库及近邻k值。进一步地,所述步骤s1具体包括以下步骤:s1.1假设一个数据集x有n个样本,聚类为cn类,其目标函数为:其中:uk为隶属度函数;dij为欧几里得距离,xi为第i个样本,cj为第j个类簇中心;b为加权参数,取值范围[1inf];隶属度函数:类簇中心cj:s1.2,初始化种群控制参数:种群规模pop_size,最大进化次数max_iterate,交叉概率pc,变异概率pm,退火初始温度tstart,冷却系数j,终止温度tend,类簇个数cn;s1.3,随机初始化cn个类簇中心,并生成初始种群chrom,对每个类簇中心用公式(2)计算各样本的隶属度,以及用公式(1)计算每个个体的适应度值fi,其中i=1,2,…,pop_size;s1.4,设置进化迭代参数iterate=0;s1.5,对种群chrom进行选择、交叉、变异等遗传操作,对新产生的个体用公式(2)、(3)计算各样本的隶属度、以及cn个类簇中心,并用公式(1)计算每一个体的适应度值fi;若fi>fi,则新个体替换旧个体;否则,以概率p=exp((fi-fi)t)接受新个体,抛弃旧个体;s1.6,令iterate=iterate+1,若iterate<max_iterate,则转至步骤s1.5;否则执行下一步;s1.7,令ti=j*ti-1,若ti>tend,则转至步骤s1.4;否则,输出最优解。进一步地,所述步骤s2具体包括以下步骤:s2.1,初始化粒子群并对其编码,采用真实值整数编码;如:02,12,36;s2.2,计算各类簇中每个案例与同类簇其他案例的距离,并将距离值按升序排序;s2.3,通过适应度函数对每个粒子进行适应度值的计算,其中,适应度函数为当前k值的均方误差值mse;即公式(4):其中,n为类簇内案例的个数;yj,real为第j个案例y值的真实值;yj,pre为第j个案例y值的预测值,如公式(5)所示:其中:yi为升序排序后前k个案例y值的真实值;s2.4,根据粒子适应度值更新粒子最优值pbest以及群体最优值gbest;s2.5,将群体最优值gbest十位上的数值对应交叉到粒子值的十位上,若新的粒子的适应度值优于未交叉粒子的适应度值,则更新粒子以及其适应度值;例如:群体最优值gbest=16,当前粒子individual=32,交叉后的粒子new_individual=12;s2.6;对粒子上的个位值、十位值进行变异,若新的粒子的适应度值优于未变异粒子的适应度值,则更新粒子以及其适应度值;s2.7,循环执行步骤s2.3-s2.5,直到满足结束迭代的条件。进一步地,所述步骤s3具体包括以下步骤:s3.1,通过公式(6)计算问题案例与各类簇中心的距离dist;s3.2,将各距离dist按升序排列成(dist1;dist2;…;distcn),并通过公式(7)计算dist;dist=dist2-dist1(7)其中:dist1、dist2为排序后的值;s3.3,ifdist>阈值;s3.4,dist1对应的子类簇为检索子案例库;s3.5,k=k1;s3.6,else;s3.7,dist1与dist2对应的子类簇都作为检索子案例库;s3.8,实验及结果分析通过训练集完成聚类以及近邻k值的优化后,对测试集进行预测验证,实验比较本发明的检索算法与其它种检索算法对测试集的预测结果,评价预测结果的指标为均方误差值(mse)。(1)传统knn检索算法,记为knn;(2)基于模糊c均值聚类算法结合遗传-粒子群混合算法改进的knn检索算法,记为fcm-gapso-knn;(3)基于遗传模拟退火-模糊c均值聚类算法结合遗传-粒子群混合算法改进的knn检索算法,记为saga-fcm-gapso-knn;(4)本发明的检索算法。实验内容使用mackey-glass混沌时间序列数据进行仿真验证,数据集由时滞微分方程生成当时,上述微分方程呈现混沌特性。仿真取通过runge-kutta方法生成20000个数据。去掉前5000个暂态点,从剩下的点中选取1000个数据点。其中,前800个数据点为训练集,后200个数据点为测试集。对选取的数据点进行异构重组,得出时延为1,嵌入维为4。即:一个案例由5个数据点组成,前4个数据点决定后1个数据点。实验结果及分析通过davies-bouldin评价指标确定最佳类簇个数为4。4种检索算法对训练集聚类,其结果基本为:158*5;170*5;200*5;266*5。相应的近邻k值基本为:11;14;10;19。传统knn的近邻k值为训练集数目的平方根,即26。4种检索算法预测结果的均方误差值如表1所示。表1:序号检索算法均方误差(mse)1传统knn检索算法3.3075e-42fcm-gapso-knn1.5312e-43saga-fcm-gapso-knn1.5185e-44本发明的检索算法1.2316e-4由表1可知:四种检索算法中,传统knn检索算法预测结果的均方误差值最大,即预测效果最差。fcm-gapso-knn、saga-fcm-gapso-knn相较于传统knn检索算法,预测结果的精度均显著的提高。而本发明的改进的knn检索算法的均方误差值最低,预测效果最好。从图2可以看出:除去预测结果存在明显偏差的个别案例外,4种检索算法的总体预测结果仍表现良好。其中,本发明的改进的knn检索算法对所有样本的预测结果最接近。从图3、图4、图5及图6可以看出,传统knn检索算法的预测结果偏差最大。fcm-gapso-knn仍然存在、saga-fcm-gapso-knn较于传统knn检索算法,其预测结果已经明显改善,但个别案例的预测结果仍存在明显偏差。而本发明的改进的knn检索算法在fcm-gapso-knn、saga-fcm-gapso-knn算法已改善的基础上,解决了两者存在的误差,进一步提高了预测结果的精度。本发明所提出的一种改进的knn案例推理检索算法,可以有效的解决传统knn检索算法存在的两个问题:(1)计算量大,效率低。传统knn算法需要对案例库中所有的案例进行相似度计算,以此选择相似性最高的k个相似源案例。因此,对于海量案例库而言,计算量巨大,会降低效率。(2)近邻k值作为决定最终输出结果质量的因素之一。当k值较小时,容易发生过拟合;当k值较大时,会将噪声点划分到相似源案例,导致输出结果的误差增大,质量下降。同时,较于已有改进的knn检索算法,精度进一步提高。本发明对优化各类簇近邻k值的算法、以及确定检索子案例库的算法都进行了改进研究,进而改善了案例推理检索算法的预测结果质量。最后使用mackey-glass混沌时间序列数据进行仿真预测。实验证明,相较于传统knn检索算法,本发明的检索算法对问题案例聚类后,预测结果的精度显著提高。以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1