一种基于完全二叉树的容错机制的配置方法与流程
本发明涉及深度学习领域,尤其涉及一种基于完全二叉树容错机制的配置方法。
背景技术:
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。完全二叉树的叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。
深度神经网络中通常包含大量可训练的参数,因此训练出一个性能良好的神经网络需要耗费大量时间。另一方面,为了能从海量的数据中学习到更有价值的特征,深度神经网络的层次正不断加深,进一步增加了训练的耗时。传统的分布式架构模型并行和数据并行的训练方式没有实现模型并行会导致gpu集群的利用率不够高,节点间的松耦合度不够强,并且处理大型数据的能力不强。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于完全二叉树容错机制的配置方法,能实现子节点的松耦合,能实现模型并行和数据并行相结合,累积误差反向传播和标准误差逆向传播相结合,增加了模型处理数据的能力,加快子节点的单个批次快速训练速度,并使用异步io流的方式实现数据的传输,拥有更强的容错机制。
本发明的目的是通过以下技术方案来实现的:
一种基于完全二叉树容错机制的配置方法,方法包括以下步骤:
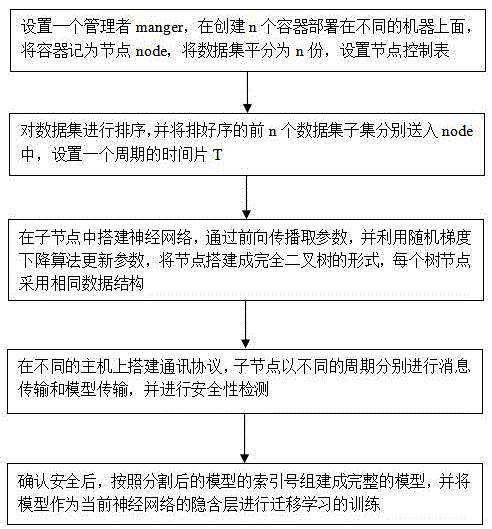
s1,设置一个管理者manger,在创建n个容器部署在不同的机器上面,将容器记为节点node,将数据集平分为n份,设置节点控制表;
s2,对数据集进行排序,并将排好序的前n个数据集子集分别送入node中,设置一个周期的时间片t;
s3,在子节点中搭建神经网络,通过前向传播取参数,并利用随机梯度下降算法更新参数,将节点搭建成完全二叉树的形式,每个树节点采用相同数据结构;
s4,在不同的主机上搭建通讯协议,子节点以不同的周期分别进行消息传输和模型传输,并进行安全性检测;
s5,确认安全后,按照分割后的模型的索引号组建成完整的模型,并将模型作为当前神经网络的隐含层进行迁移学习的训练。
具体的,所述步骤s1中的节点控制表用于记录节点id、节点对应的数据集和当前批次误差。
具体的,所述步骤s4中还包括通过密码机制在完全二叉树的树节点之间设置安全协议,用于防止黑客伪造消息进行攻击。
具体的,所述步骤s4中各个节点之间流通的消息包括公钥签名、消息认证码以及消息摘要。
具体的,所述步骤s4中采用签名聚合和密钥聚合的算法来进行所有节点的验证。
本发明的有益效果:
1、采用基于二叉树形式的模型并行和数据并行相结合的方法,大量缩短了神经网络的训练时间;
2、实现模型的流通,并平均分配数据集到字节点上面,实现数据并行,提升了整个集群处理数据的综合性能,集群整体结构呈二叉树的形式,便于周期性交互时候的遍历和管理工作。
附图说明
图1是本发明的方法流程图。
图2是本发明的完全二叉树的数据结构图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
本实施例中,如图1所示,一种基于完全二叉树容错机制的配置方法,方法包括以下步骤:
步骤1,设置一个管理者manger,在创建n个容器部署在不同的机器上面,将容器记为节点node,将数据集平分为n份,设置节点控制表。其中,节点控制表用于记录节点id、节点对应的数据集和当前批次误差。
步骤2,对数据集进行排序,并将排好序的前n个数据集子集分别送入node中,设置一个周期的时间片t。
步骤3,在子节点中搭建神经网络,通过前向传播取参数,并利用随机梯度下降算法更新参数,将节点搭建成完全二叉树的形式,每个树节点采用相同数据结构。每个树节点的数据结构如图2所示,包括左指针、消息队列、模型队列和右指针。
步骤4,在不同的主机上搭建通讯协议,子节点以不同的周期分别进行消息传输和模型传输,并进行安全性检测。在周期性传输一次过程中,通过密码机制在完全二叉树的树节点之间设置安全协议,用于防止黑客伪造消息进行攻击,各节点之间流通的消息包括公钥签名、消息认证码以及消息摘要,同时对消息摘要进行签名并将其附加到消息文本上。每个节点独立产生自己的私钥片段,然后将可验证的公钥广播出去,以及系统中其他节点需要验证本地节点的可靠性的信息.使用签名聚合和密钥聚合的算法,使所有的节点的验证都没有错误,每个节点达成一致,从而达到节点有可验证性、随机性、唯一性、确定性的效果。
步骤5,确认安全后,按照分割后的模型的索引号组建成完整的模型,并将模型作为当前神经网络的隐含层进行迁移学习的训练。
其中,消息传输在每个周期的时间传输一次,并由主节点负责检查子节点的状态码,状态码有以下几种状态(因网络延迟等不可靠因素而阻塞-1,文件传输的消息等待0,正在运行1),这里将采用自发些的报备的方式告知管理者,从叶子节点开始报备,在每个周期结束后,叶子节点采用异步并行的方式向根节点报备消息,非叶子节点将收到的信息跟自身状态码,公钥,消息密码的信息,依次入队到消息队列中,上传到根节点,根节点通过安全检测后,确认是自己的孩子节点上传的,才接受该消息队列,并取出自身队列的队尾元素跟收到的消息队列组成新的队列上传到根节点,报备后,系统管理员按照后续递归遍历整个集群,找到最后一个节点,以此将消息队列中的元素出队,查看状态码,如状态码为-1,则查询该状态码id,找到主机重启该容器,取出模型队列对尾存储的模型,待该主机重启完后,用取出的模型进行迁移学习继续训练,并清空队列元素,在该主机重启的时候,暂停对其孩子节点的训练,其双亲节点和兄弟节点的训练不受影响。
模型传输每两个周期结束,保存一次模型到模型队列中,队列元素后接一张模型文件情况说明表,标注节点id,loos值等重要信息,在进行模型周期性上传时候,采用并行io流的方式上传模型文件,将模型文件切割成等份,并标注索引,开启一定量的线程,每个线程都会为分配给它的任务保存一个双向链式队列,将分割好的模型文件平均分配到双向链式队列中,每完成一个任务,就会从队列头上取出下一个任务开始执行。基于种种原因,某个线程可能很早就完成了分配给它的任务,而其他的线程还未完成,那么这个线程就会,随机选一个线程,从队列的尾巴上偷走一个任务。这个过程一直继续下去,直到所有的任务都执行完毕,所有的队列都清空。批次上传到根节点,在根节点接受模型前进行消息队列的传输,需先检查安全性,才能接受模型,确认安全后,再按照分割后的模型的索引号组建成完整的模型,将这个模型作为当前神经网络的隐含层进行迁移学习的训练。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护的范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!