基于深度学习的开放集辐射源个体识别方法与流程
本发明属于通信辐射源个体识别领域以及深度学习领域,具体涉及基于卷积神经网络及openmax算法的开集个体识别方法。
背景技术:
随着无线网络的飞速发展,以及手机、ipad等射频设备(radiofrequencydevice,rfdevice)的迅速普及,无线通信技术被广泛应用于商业、医疗、军事等领域。但由于无线通信的开放性,使其更容易受到攻击。攻击者可以通过模仿主用户信号,伪装成主用户攻击软件无线电通信网络,即主用户仿冒攻击。通信辐射源个体识别(radiofrequencydeviceidentification)可以通过通信信号所包含的由相位噪声、功放的非线性失真等设备的物理硬件缺陷引起的射频指纹特征(radiofrequencyfingerprinting)[1],识别不同的通信个体,使得无线通信网络有效避免仿冒信号攻击通信网络。同时在军事领域,通信辐射源个体识别技术可以在复杂的无线电环境中,准确检测敌方的通信设备,并对其进行识别定位,因此通信辐射源个体识别技术在军事领域也具有重要意义。
深度学习作为机器学习领域的新兴技术,通过模拟人脑神经元结构,能够发掘大数据中所蕴含的深层次特征,在机器视觉、自然语言处理以及大数据分析等领域均展现了出色性能。通过将深度学习与通信辐射源个体识别技术[2,3]相结合,使得网络能够自主学习不同辐射源个体的差异特征,对于提高通信辐射源个体识别准确率与稳定性,提升通信网络安全性能具有重大意义。
然而,现存基于深度学习的辐射源个体识别技术,大多建立在封闭集条件下,即辐射源个体信息作为先验信息已知,测试集中无未知类辐射源,但这并不符合实际应用中对辐射源个体识别所提出的要求。由于训练集大小有限,无法涵盖无限的辐射源个体类型,在实际应用中,测试集中可能会出现与训练集不同的设备类型,此时,我们将其称为开放集。对于开放集所出现的未知类数据,网络会以高置信度将其误判为某一已知类,造成模型的崩溃。
开放集识别技术大多采用阈值处理与封闭集分类器相结合的方法,例如针对单类开放集的“1-vs-setmachine”方法,将正例数据与两个超平面相关联来替换二元线性分类器的半空间检测法。以及基于紧致减速概率(compactabatingprobability,cap)模型的weibull校准支持向量机算法(weibull-calibratedsupportvectormachine,w-svm)。该算法将用于分数校准的统计极值理论与二元支持向量机相结合,降低了开放空间风险。这类方法的巅峰是极值机模型(theextremevaluemachine),该方法源自统计极值理论(statisticalextremevaluetheory,evt),能够动态调整阈值,提高分类的准确率。但这些方法的计算和存储成本很高,且识别准确率有限。此外有研究证明可以产生“fooling”数据,与已知类的大不相同,但是仍能够获得较高判别概率[4,5]。这说明通过阈值检测的方法不足以完成开集类判断。
本发明拟采用基于卷积神经网络与openmax相结合的方法实现开放集辐射源个体识别。[1]hallj,barbeaum,kranakise.detectionoftransientinradiofrequencyfingerprintingusingsignalphase[j].wirelessandopticalcommunications,2003:13-18.
[2]choehc,poolece,andreamy,etal.novelidentificationofinterceptedsignalsfromunknownradiotransmitters[c].in:spie's1995symposiumonoe/aerospacesensinganddualusephotonics.internationalsocietyforopticsandphotonics,1995:504-517.
[3]neumannc,heeno,onnos.anempiricalstudyofpassive802.11devicefingerprinting[c].in:32ndinternationalconferenceondistributedcomputingsystemsworkshops(icdcsw),2012.ieee,2012:593-602.
[4]i.goodfellow,j.shelns,andc.szegedy.explainingandharnessingadversarialexamples.ininternationalconferenceonlearningrepresentations.computationalandbiologicallearningsociety,2015
[5]a.nguyen,j.yosinski,andj.clune.deepneuralnetworksareeasilyfooled:highconfidencepredictionsforunrecognizableimages.incomputervisionandpatternrecognition
技术实现要素:
为克服现有技术的不足,针对开放集辐射源个体识别要求,本发明旨在利用卷积神经网络的特征提取能力,学习已知辐射源个体传输信号所隐含的设备物理层指纹特征,实现对已知辐射源个体的准确分类,同时自主识别未知辐射源个体数据,扩大深度网络的应用范围。为此,本发明采取的技术方案是,基于深度学习的开放集辐射源个体识别方法,在训练阶段,通过卷积神经网络提取训练集的类间差异特征,生成闭集激活向量cs-av(closedsetactivationvectors)用于已知集合分类,以及类内共同特征用于计算已知类基准向量即平均激活向量mav,和构建威布尔模型,从而建立已知信息的整体量化模型;在测试阶段,通过威布尔累积分布函数cdf(cumulativedistributionfunction)计算开集激活向量os-av(opensetactivationvectors),通过开集激活向量os-av定量表示测试样本不同于已知类的特异性特征,并估计样本的开集概率。
模型包含4个卷积层和2个全连接层,卷积层采用线性整流函数relu(rectifiedlinearunit)作为激活函数,其中第一个卷积层提取基本特征,随后的卷积层提取设备物理层指纹特征,每个卷积层之后是批量归一化层,以加速收敛并避免过拟合现象,第一个全连接层用采用relu作为激活函数,将提取的特征连接成激活向量av(activationvectors),最后一个全连接层采用softmax激活函数,计算闭集的分类概率。
构建威布尔模型具体步骤如下:
(1)数据处理
挑选各类判断正确的训练样本的激活向量rightav(rightactivationvector),取均值计算其基准向量得到各类判别范围的中心,即平均激活向量mav(meanactivationvector),随后计算各训练样本激活向量vi,j,与其对应平均激活向量mavμi之间的距离si,j,i=1,2…α,α为已知类个数,j=1,2,…m,m为判断正确的样本个数,作为每类样本的判别范围;
(2)模型拟合
通过拟合样本激活向量与mav之间的距离si,j分布,建立各已知类的威布尔模型ρi,i=1,2…α,α为已知类个数,威布尔模型ρ:
其中,k为尺度参数,λ为形状参数,x为卷积特征,在得到已知类的威布尔模型后,训练阶段结束,在随后的测试阶段,计算测试集中样本的开集概率。
计算开集概率具体步骤:在训练阶段得到的威布尔模型表征的是已知类样本的先验信息,在测试阶段通过构造开集激活向量,表征样本的未知类特征,从而计算开集概率。
详细步骤如下:
(1)构造开集激活向量
首先利用威布尔模型的累积分布函数cdf计算修正参数ωi:
其中,k、λ为之前所求尺度参数与形状参数,修正参数ωi表征的是样本属于该已知类的概率,而后,通过构造开集激活向量
(2)计算开集概率
得到测试集样本开集激活向量
其中,y为样本预测标签值。
本发明的特点及有益效果是:
辐射源个体的开机识别,引入了openmax算法,并结合卷积神经网络发掘数据隐藏结构,提取深层次特征的能力,在保证已知类准确分类的前提下,实现对开放集中的未知类样本的识别,扩大了卷积神经网络的应用范围。图5展示了6个体,2未知类检测结果图,可以看到不但实现了已知类的准确分类,而且对不同未知类都能够成功识别,总体识别准确率为94.33%。
附图说明:
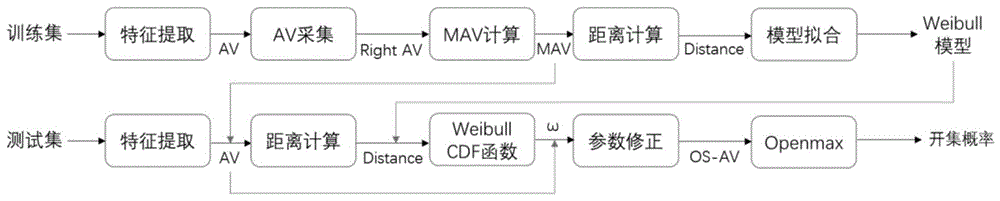
图1开集辐射源个体识别流程图。
图2特征提取网络模型。
图3个体激活向量分布。
图401个体距离概率分布图。
图5个体开集识别性能。
具体实施方式
本发明针对开放集辐射源个体识别要求,利用卷积神经网络的特征提取能力,学习已知辐射源个体传输信号所隐含的设备物理层指纹特征,并通过openmax函数实现对已知辐射源个体的准确分类,同时自主识别未知辐射源个体数据,扩大深度网络的应用范围。
1.实现结构
本发明的实现结构如图1所示。
在训练阶段,通过卷积神经网络提取训练集的类间差异特征,生成闭集激活向量(closedsetactivationvectors,cs-av)用于已知集合分类,以及类内共同特征用于计算已知类基准向量即平均激活向量(meanactivationvector,mav),和构建威布尔模型(weibullmodel),从而建立已知信息的整体量化模型。在测试阶段,通过开集激活向量(opensetactivationvectors,os-av)定量表示测试样本不同于已知类的特异性特征,并估计样本的开集概率。
2.数据集产生
本发明采用由6个射频设备发射的话音信号组成话音数据集。利用6个同型号的射频设备发射同一话音片段,并在接收端存储为i/q(in-phase/quadrature)两路数据形式。随后将其切片为2×768的样本片段,随后进行重复实验,每一个体采集7000个样本,随后对其进行短时傅里叶变换(short-timefouriertransform,stft),产生7000个大小为64×89的样本。将其保存为python的字典结构,字典键对应个体标签(01,02等)。将6类个体样本分为已知类和未知类,每个个体已知类的50%作为训练集训练网络,其余的3500个已知类样本以及全部的未知类样本作为测试集。
3.特征提取
本发明的特征提取网络模型如图2所示。
模型包含4个卷积层(convolutionallayer)和2个全连接层(fullyconnectedlayer)。卷积层采用线性整流函数(rectifiedlinearunit,relu)作为激活函数,卷积核分别为160×5×5,160×5×5,64×3×3,64×3×3。其中第一个卷积层提取基本特征,如信号功率和发射频率,随后的卷积层提取相位噪声,放大器功率非线性失真等的设备物理层指纹特征。每个卷积层之后是批量归一化层(batchnormalizationlayer),以加速收敛并避免过拟合现象。第一个全连接层用采用relu作为激活函数,将提取的特征连接成激活向量(activationvector,av)。最后一个全连接层采用softmax激活函数,计算闭集的分类概率。
4.构建威布尔模型(weibullmodel)
(1)数据处理
挑选各类判断正确的训练样本的激活向量(rightavtivationvecotr,rightav),取均值计算其基准向量得到各类判别范围的中心,即平均激活向量(meanavtivationvecotr,mav)。随后计算各训练样本激活向量vi,j,与其对应平均激活向量(mav)μi之间的距离si,j,(i=1,2…α,α为已知类个数,j=1,2,…m,m为判断正确的样本个数),作为每类样本的判别范围。图3展示了话音数据集的6个体的激活向量的分布。
(2)模型拟合
通过拟合样本激活向量与mav之间的距离si,j分布,建立各已知类的威布尔模型ρi,(i=1,2…α,α为已知类个数)。威布尔模型ρ:
其中,k为尺度参数,λ为形状参数,x为卷积特征。01个体的距离概率分布如图4所示。在得到已知类的威布尔模型后,训练阶段结束。在随后的测试阶段,计算测试集中样本的开集概率。
5.计算开集概率
(1)构造开集激活向量
在训练阶段得到的威布尔模型表征的是已知类样本的先验信息,在测试阶段通过构造开集激活向量,表征样本的未知类特征,从而计算开集概率。
首先利用威布尔模型的累积分布函数(cumulativedistributionfunction,cdf)计算修正参数ωi:
其中,k、λ为之前所求尺度参数与形状参数。修正参数ωi表征的是样本属于该已知类的概率。而后,通过构造开集激活向量
(2)计算开集概率
得到测试集样本开集激活向量
下面结合附图和具体实施例进一步详细说明本发明。
(1)将数据信号分成已知类和未知类,由每已知类的50%作为训练集,剩余已知类和未知类作为测试集。
(2)利用训练集训练网络,得到训练样本激活向量vi,j。
(3)由判断正确样本的激活向量(rightav),计算各已知类的平均激活向量μi。
(4)计算各个训练样本激活向量vi,j与各对应类的平均激活向量μi之间的距离分布si,j。
(5)拟合该距离si,j,建立各已知类的weibull模型ρi。
(6)将测试集输入网络,得到测试样本的激活向量。
(7)计算测试样本激活向量与各平均激活向量μi之间的距离,得到各样本的距离分布,将其输入各已知类weibull模型ρi的cdf函数计算修正参数ωi。
(8)利用修正参数ωi计算开集激活向量
(9)将开集激活向量
- 还没有人留言评论。精彩留言会获得点赞!