一种海关进出口商品税号预测方法与流程
本发明涉及自然语言处理技术领域,具体涉及一种基于混合卷积神经网络和辅助网络的海关进出口商品税号预测方法。
背景技术:
海关税收是很多国家税收的主要来源。目前中国海关主要使用人工进行审核进出口商品的税率,其能覆盖海量的进出口商品的很少一部分。由于海关征税的主要依据是商品的文本信息,使用自然语言处理技术对商品文本进行分类,根据类别确定税收,可以实现税收风险防控的自动化。商品的税收预测可以转化为一个中文文本分类问题。
中文文本分类,指将文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记的过程。它根据一个已经被标注的训练文档集合,找到文档特征和文档类别之间的关系模型,然后利用这种学习得到的关系模型对新的文档进行类别判断。现有的文本分类从基于知识的方法逐渐转变为基于统计和机器学习的方法。很多分类模型在中文文本分类任务上取得了较为理想的效果,海关进出口申报文本相比较于普通中文,单条文本是由多个要素线性组成的,没有连续的上下文语义。目前,利用人工智能进行海关进出口申报文本分类任务还没有人尝试,但是抽象成传统的文本分类问题,麻省理工的yoonkim提出的textcnn卷积模型可以很好的提取文本特征,利用特征组合进行文本分类;谷歌提出的bert模型利用大规模预训练语料以及庞大的模型参数量,提高了文本分类任务的精度。但是对于海关进出口申报文本分类任务,由于海关文本存在的领域性及特殊性,普通模型在海关商品分类任务上效果表现欠佳。
技术实现要素:
本申请的目的在于提供一种海关进出口商品税号预测方法,通过利用海关专有的语料资源,实现了在申报要素长短差异导致短要素特征稀释的前提下对海关进出口商品文本进行税号预测,提高了税号预测的准确率。
为实现上述目的,本申请的技术方案为:一种海关进出口商品税号预测方法,具体包括:
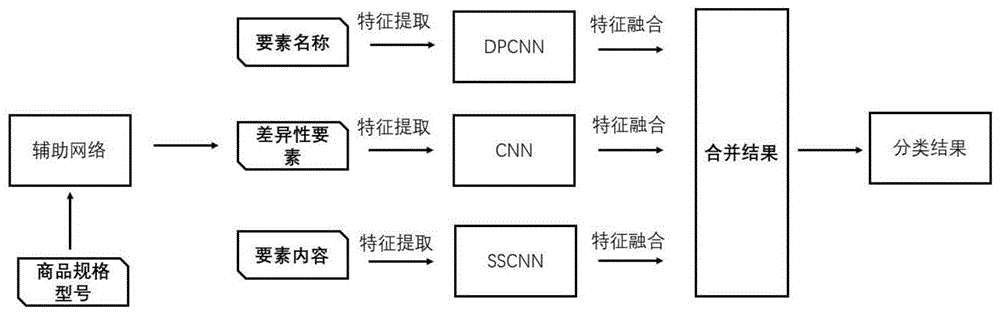
步骤1:对海关进出口商品文本进行预处理,得到要素名称和要素内容;
步骤2:将步骤1中得到的要素内容进行拆分,然后利用辅助网络进行差异性要素选择;
步骤3:把步骤2中得到的差异性要素送入cnn网络中进行特征提取,同时利用dpcnn网络提取要素名称特征、sscnn网络提取要素内容特征。
步骤4:融合步骤3中得到的差异性要素特征、要素名称特征、要素内容特征,然后进行分类操作,进而得到商品税号。
进一步的,所述步骤2具体实现方式为:
步骤21.将得到的要素内容,把商品大类相同的数据聚集在一起形成一个段落;
步骤22.计算每个段落有多少个商品小类,依此把每各个段落送入辅助网络中,针对商品小类进行分类训练;在每个段落训练时,按顺序依次把要素内容变成要素名称,得到每个要素的损失值;
步骤23.利用每个段落得到的各个要素的损失值,按照从大到小的顺序,选择出前2个差异性要素。
进一步的,所述步骤3具体实现方式为:
步骤31.将差异性要素,送入cnn网络中利用卷积层提取特征,最大池化层进行特征稀疏;
步骤32.将要素名称,送入dpcnn网络中利用卷积层提取特征,下采样层压缩序列长度,扩大感受野;
步骤33.将要素内容,送入sscnn网络中利用结构化卷积层提取浅层特征。
进一步的,所述步骤4具体实现方式为:
步骤41.拼接差异性要素特征、要素名称特征、要素内容特征;
步骤42.将拼接后的特征送入两层的全连接层,全连接层是每一个结点都与上一层的所有结点相连的网络,用来把提取到的特征综合起来;第一层输出维度是商品大类号,第二层全连接层输出维度是商品小类号,将大类号和小类号拼接在一起得到商品税号。
本发明由于采用以上技术方案,能够取得如下的技术效果:本发明通过融合多种卷积网络,利用海关专属的语料资源,结合海关文本的特点,解决了同一目录下的商品区分性不明显和由于申报要素长短差异导致短要素特征稀释的问题,增强较短内容要素在整体特征中的独立性以及重要性,提高了海关进出口商品税号预测的准确率。
附图说明
图1为一种海关进出口商品税号预测方法流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细的描述:以此为例对本申请做进一步的描述说明。
实施例1
在海关进出口商品税号预测过程中,应该利用好各个要素拥有先天分界这一特点,既需要降低各个要素之间语义融合度,又需要提取出足够突出的特征来获取商品的正确税号。基于海关文本的特点以及海关进出口商品税号预测任务中的问题,参见图1,本申请提供一种海关进出口商品税号预测方法:首先对海关进出口商品申报文本进行数据预处理,然后对文本数据进行分词,通过查阅“申报要素目录”,找到商品申报文本要素内容对应的要素名称。然后利用辅助卷积网络,找到同一个大类下商品的决定性差异要素,使用混合卷积神经网络对商品文本预测税号。混合卷积神经网络使用了三种卷积对不同的商品文本内容进行处理,使用普通卷积神经网络(convolutionneuralnetwork,cnn)对差异性要素进行特征抽取,使用浅层结构化卷积(shallowstructuredconvolutionneuralnetwork,sscnn)对要素内容进行特征提取,使用深度金字塔卷积(deeppyramidconvolutionneuralnetwork,dpcnn)对要素名称进行特征抽取,三种特征抽取之后拼接在一起使用全连接网络进行分类,进而得到商品税号。有效解决了海关进出口商品税号预测问题中,同一大类下的商品很难区分,以及由于申报要素长短差别太大导致短要素特征稀释的问题,其准确率比目前其他主流的深度学习方法有显著的提高。
以下结合实施例和附图对本发明做详细的说明,以使本领域普通技术人员参照本说明书后能够据以实施。
本实施例以pycharm为开发平台,python为开发语言。在海关真实数据共1400000句语料上进行。以下为具体过程:
步骤1:对海关进出口商品文本进行预处理操作,得到要素名称和要素内容。
步骤2:对步骤1中得到的要素内容进行拆分,然后利用辅助网络进行差异性要素选择,具体为:
步骤21:将步骤1得到的要素内容,把商品大类相同的数据聚集在一起形成一个段落;例如数据:
数据a:“8412390000|气动执行器|43|将气压动力转换为机械动力|气动阀门用|ingersollrand|94695194”以及
数据b:“8412310090|冲压空气作动器|4|3|提供气压直线作用力|飞机动力系统用|honeywell|676000141”
这两条商品申报记录,大类都是“84123”,固定申报要素都是“商品类别|品牌类型|出口享惠情况|原理|用途|品牌|型号”,所以将其聚集在一个段落中。
步骤22:计算每个段落有多少个商品小类,依此把各个段落送入辅助网络中,针对商品小类进行分类训练。在每个段落训练时,按顺序依次把要素内容变成要素名称,得到每个要素的损失值;
步骤23:利用每个段落得到的各个要素的损失值,按照从大到小的顺序,选择出前2个差异性要素。
上述两条数据经过辅助网络的计算,得到的差异性要素分别是“商品名称”和“原理”。
步骤3:利用步骤2中得到的差异性要素,送入cnn网络中提取特征,同时利用dpcnn和sspcnn网络分别提取要素名称和要素内容特征,具体为:
步骤31:将差异性要素,送入cnn网络中利用卷积层提取特征,最大池化层进行特征稀疏;
步骤32:将要素名称,送入dpcnn网络中利用卷积层提取特征,下采样层压缩序列长度,扩大感受野;
步骤33:将要素内容,送入sspcnn网络中利用结构化卷积层提取浅层特征。
例如上述数据,要素名称和要素内容保持不变送到各自的卷积神经网络模型中提取特征,数据a将“气动执行器|将气压动力转换为机械动力”,数据b将“冲压空气作动器|提供气压直线作用力”送入textcnn模型中提取特征。
步骤4:融合步骤3中得到的差异性要素特征、要素名称特征、要素内容特征,然后进行分类操作。
步骤41:拼接差异性要素特征、要素名称特征、要素内容特征;
步骤42:将拼接后的特征送入两层的全连接层进行分类,其中第一层输出维度是商品大类号,第二层全连接层输出维度是商品小类号,将大类号和小类号拼接在一起得到商品税号。
例如上述数据,最后得到的数据针对所有分类的概率,选择其中概率最大的目标类别做为模型最终预测类别。
根据以上步骤,本发明将分词效果与dpcnn模型,transform模型以及bert模型和roberta模型方法做了对比。从表1中可以看出,本发明提出的方法在分类的准确率、精确率以及f1值方面明显优于其他方法。
表1不同模型针对海关进出口商品分类效果对比
同时,本发明也对不同的辅助网络对最后商品分类的影响进行了验证。如表2所示,本发明中辅助网络选用textcnn模型能够大幅度提高海关进出口商品分类的准确性。
表2不同的辅助网络对海关进出口商品分类效果的影响
以上所述,仅为本发明创造较佳的具体实施方式,但本发明创造的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明创造披露的技术范围内,根据本发明创造的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明创造的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!