一种优化数据不平衡状态的移动app用户性别识别方法和系统与流程
本发明属于移动互联网技术领域,尤其涉及一种优化数据不平衡状态的移动app用户性别识别方法和系统。
背景技术:
用户基础属性信息,比如性别、年龄等,通常被认为是用户隐私信息,企业很难获得,但是用户基础属性信息在个性化服务、特定广告投放、用户行为分析和其他方面有着广泛的应用。
在互联网公司的广告业务不断增长的同时,许多的互联网公司也在为用户提供个性化的广告。百度推广会根据用户的搜索历史关键字给用户提供不同的广告业务。很多的公司会根据用户的历史行为分析用户的兴趣模型,以便提供更好的个性化服务。刻画用户模型包括刻画用户的人口统计信息,地理位置信息,搜索访问兴趣爱好等。然而用户的基础属性信息如性别、年龄、收入等在一般情况下是不容易得到的,因为这些信息对用户而言是很敏感的,人们不愿意公开这类个人隐私属性。
尽管一些网络应用在用户注册时要求用户填写性别、出生年月、教育程度等相关信息,但是这些信息对用户比较敏感,因此很多用户根本不会填写这些相关信息或者填写错误的信息,这些不真实的信息对个性化推荐会有负作用。实际情况是大部分用户在注册时都没有填写相关的基础属性信息,对手机应用而言用户的基础属性信息是未知。
目前国内外对于用户基础属性信息的建模研究主要是基于用户在邮件或者社交应用中产生用户数据如邮件内容、搜索内容和空间状态等,主要有三个方面:1、基于邮件内容的用户基础属性预测;2、基于用户搜索内容的基础属性预测;3、、基于用户浏览行为的基础属性预测。研究采用的方法主要是常用的机器学习分类算法,从用户移动终端行为分析用户基础属性的研究则比较少。
中国授权发明专利zl201610486432.7公开一种基于安装包列表的移动用户性别预测方法,包含以下步骤:获取有性别标签的用户设备号;从安装列表库中筛选出有性别标签的用户设备号所对应的用户,获取这些用户的安装包列表;将安装包列表数量小于m或者大于n的用户剔除;将安装包列表信息转换为特征数据集;将特征数据集按设定比例随机划分为训练集和测试集;根据训练集数据,使用gbdt模型训练,然后通过测试集进行验证,得到用户性别预测模型;从安装包列表库中获取没有性别标签的用户及其安装列表,做同样的特征转换利用已训练的性别模型预测。
中国发明专利申请cn201611127122.2提出一种基于手机上网行为的用户性别预测方法,该方法统计用户在一段时间内点击各app的次数;将统计数据整理成矩阵形式;对所述矩阵进行降维处理;将处理后的数据分为训练数据集和测试数据集,用训练数据集来训练预测模型;用测试数据集来验证预测模型,并计算准确度。本发明简单易行,且准确率较高。根据用户使用的app的次数来预测用户的性别,对后续根据不同性别用户的偏好进行相关的个性化服务推荐提供了支持。
然而,虽然现有技术已经存在各种预测用户性别的模型和机器学习算法,但是发明人发现,现有技术大多关注于模型和算法本身,而并未对算法或者模型使用的样本数据进行匹配处理,从而导致实际使用的样本数据本身存在较大的假阳性问题以及不均衡问题;此外,样本数据无法直接输入机器学习模型,必须要对其进行编码化处理,而直接对样本数据进行编码化处理将会带来大量的数据稀疏问题,从而导致建模和预测效果本身的准确性降低。
技术实现要素:
为解决上述技术问题,本发明提出一种优化数据不平衡状态的移动app用户性别识别方法和系统。所述系统包括样本数据输入模块、样本数据分类模块、样本数据编码模块、映射模块、模型训练模块以及预测输出模块。样本数据编码模块用于对连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征。所述样本数据编码模块还包括数据不平衡状态优化子模块,所述数据不平衡状态优化子模块用于对所述连续性特征和离散型特征的不平衡状态进行优化。本发明还提出基于上述系统实现的用户性别识别方法。本发明的技术方案能够解决在使用one-shot编码进行建模过程中产生的数据稀疏以及数据不平衡问题。
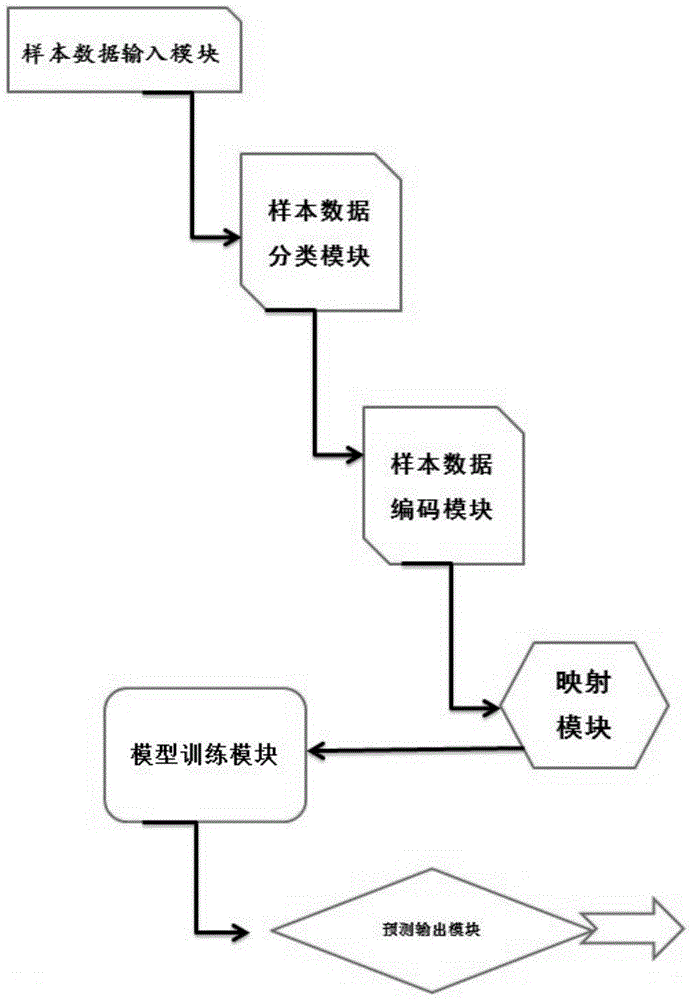
在本发明的第一个方面,提供一种移动app用户性别识别系统,所述系统包括样本数据输入模块、样本数据分类模块、样本数据编码模块、映射模块、模型训练模块以及预测输出模块;
其中,所述样本数据输入模块用于输入移动终端样本数据;
所述样本数据分类模块将所述样本数据进行特征分类,得到连续性特征和离散型特征;
样本数据编码模块用于对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征;
映射模块用于将所有one-hot样本特征进行embedding映射;
所述模型训练模块基于所述embedding映射后的样本特征构建全连接神经网络模型并进行训练;
所述预测输出模块采用训练好的全连接神经网络模型,输入移动终端用户特征,预测用户性别;
作为本发明最突出的优点,所述样本数据编码模块还包括数据不平衡状态优化子模块,所述数据不平衡状态优化子模块用于对所述连续性特征和离散型特征的不平衡状态进行优化。
作为体现上述优点的关键性技术性手段之一,所述数据不平衡状态优化子模块用于对所述连续性特征和离散型特征的不平衡状态进行优化,具体包括:
对于连续性特征进行分段处理,并进行可视化分析,获取连续数据段以及离散数据段,将所述相邻的离散数据段与所述连续数据段之间的第一空值位段、以及相邻的离散数据段之间的第二空值位段识别出来;
如果所述第一空值位段的数量小于第一阈值,则利用所述离散数据段的众数填充所述第一空值位段;
如果所述第二空值位段的数量大于第二阈值,则删除与所述第二空值位段对应的离散数据段。
作为与本发明所要解决的技术问题相关联的具体样本数据处理,所述样本数据输入模块用于输入移动终端样本数据,具体包括:
所述样本数据包括移动终端对应的用户年龄,所述用户年龄包括6个区段。
年龄的处理方式是对其进行分段处理,分别代表不同年龄段,分别为:小于等于18岁,19-23岁,24-34岁,35-44岁,45-54岁,大于等于55岁,这里一共有六段,不同情况下可以有不同划分方式。这样我们就得到了2*6种标签组合,如男生小于等于18岁、女生小于等于18岁等。
所述样本数据输入模块用于输入移动终端样本数据,具体包括:
所述样本数据包括移动终端每个应用类别下安装包的安装数量;
统计该移动终端每个应用类别下安装包的安装总数量,并进行归一化处理。
在本发明中,样本数据编码模块用于对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征,具体包括:
对于离散型特征直接用one-hot表示。
所述模型训练模块基于所述embedding映射后的样本特征构建全连接神经网络模型并进行训练,具体包括:
构建全连接神经网络将所有的one-shot样本特征进行特征映射,映射到最终的类别个数2*6=12个类别上,并使用softmax函数将分类概率归一化,通过交叉熵损失函数来优化模型。
更具体的,所述移动终端为手机,所述样本数据包括手机安装包列表、每个安装包对应的应用类别、手机品牌、手机品牌下的型号、手机屏幕长宽、手机系统、手机系统版本及该手机标注的用户的性别和年龄。
本发明还提出一种用户性别识别方法,所述方法所述的移动app用户性别识别系统实现。
具体而言,所述方法包括如下步骤:
s1:获取移动终端样本数据;
s2:将所述样本数据进行特征分类,得到连续性特征和离散型特征;
s3:对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征;
s4:将所有one-hot样本特征进行embedding映射;
s5:基于embedding映射后的样本特征构建全连接神经网络模型并进行训练;
s6:采用训练好的全连接神经网络模型,输入移动终端用户特征,预测用户性别。
在本发明中,所述全连接深度神经网络模型是在基于单层感知机网络模型的基础上,加入多个隐含层的人工神经网络;
所述训练包括根据样本数据特点逐层搭建全连接神经网络模型,训练神经网络模型,并不断反向调整优化模型参数,得到调整后的全连接神经网络模型。
本发明上述方法可以通过计算机程序指令自动化实现,因此,本发明还提出一种计算机可读存储介质,其上存储有计算机程序指令,通过处理器和存储器执行所述程序指令,用于实现所述的方法。
本发明的技术方案着重在于对于建模使用的样本数据进行编码以及优化处理,从而解决在使用one-shot编码进行建模过程中产生的数据稀疏以及数据不平衡问题,使得后续的建模和预测更为准确。
本发明的进一步优点将结合说明书附图在具体实施例部分进一步详细体现。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一个实施例的一种移动app用户性别识别系统的主要模块结构图
图2是图1所述系统的部分具体实现原理图
图3是基于图1所述系统实现的用户性别识别方法的主要流程图
具体实施方式
下面,结合附图以及具体实施方式,对发明做出进一步的描述。
参见图1,本发明一个实施例的一种移动app用户性别识别系统的主要模块结构图。
图1中,所述系统包括样本数据输入模块、样本数据分类模块、样本数据编码模块、映射模块、模型训练模块以及预测输出模块;
其中,所述样本数据输入模块用于输入移动终端样本数据;
所述样本数据分类模块将所述样本数据进行特征分类,得到连续性特征和离散型特征;
样本数据编码模块用于对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征。
onehot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
one-hot向量将类别变量转换为机器学习算法易于利用的一种形式的过程,这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0,特别稀疏。
举个例子:一个特征“性别”,性别有“男性”、“女性”,这个特征有两个特征值,也只有两个特征值,如果这个特征进行one-hot编码,则特征值为“男性”的编码为“10”,“女性”的编码为“01”,如果特征值有m个离散特征值,则one-hot后特征值的表示是一个m维的向量,每个样本的特征只能有一个值,这个值的向量坐标上就是1,其他都是0,如果有多个特征,“性别”有两个特征,“尺码”:m、l、xl三个值,我们用“01”表示男性,m为“100”,l为“010”,xl为“001”,所以一个样本,【“男性”、“l”】one-hot编码为[10010],一个样本也就是5维的向量,这就是one-hot形式。
数据稀疏会带来样本不均衡问题。作为本发明的突出性优点,参见图2,所述样本数据编码模块还包括数据不平衡状态优化子模块,所述数据不平衡状态优化子模块用于对所述连续性特征和离散型特征的不平衡状态进行优化。
更具体的,所述数据不平衡状态优化子模块用于对所述连续性特征和离散型特征的不平衡状态进行优化,具体包括:
对于连续性特征进行分段处理,并进行可视化分析,获取连续数据段以及离散数据段,将所述相邻的离散数据段与所述连续数据段之间的第一空值位段、以及相邻的离散数据段之间的第二空值位段识别出来;
如果所述第一空值位段的数量小于第一阈值,则利用所述离散数据段的众数填充所述第一空值位段;
如果所述第二空值位段的数量大于第二阈值,则删除与所述第二空值位段对应的离散数据段。
作为一个示意性而非限制的例子,举例而言,对于连续性特征,例如移动终端系统版本,可以是安卓4.1.2、安卓4.1.3这一类的特征;移动终端屏幕尺寸,可以是4.4寸、4.5寸、4.7寸等;对于这一类特征,在本发明中视为连续性特征,可以将其进行预处理的编码处理,例如移动终端系统版本可以定义为412/413/414……等;
继续以上述移动终端系统版本数据为例,对于连续性特征进行分段处理,并进行可视化分析,获取连续数据段以及离散数据段,举例如下:
假设样本数据中包含的移动终端系统版本数据如下:
412:5个;
413:0个;
414:4个;
415:5个;
416:0个;
417:0个;
418:1个;
419:0个。
则连续数据段为414和415,离散数据段为412-413-414以及416-418以及418-419;
其中,413为相邻的离散数据段与所述连续数据段之间的第一空值位段;而416-417为相邻的离散数据段之间的第二空值位段。
样本数据编码模块用于对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征,具体包括:
对于离散型特征直接用one-hot表示。
所述模型训练模块基于所述embedding映射后的样本特征构建全连接神经网络模型并进行训练,具体包括:
构建全连接神经网络将所有的one-shot样本特征进行特征映射,映射到最终的类别个数2*6=12个类别上,并使用softmax函数将分类概率归一化,通过交叉熵损失函数来优化模型。
在本实施例中,所述移动终端为手机,所述样本数据包括手机安装包列表、每个安装包对应的应用类别、手机品牌、手机品牌下的型号、手机屏幕长宽、手机系统、手机系统版本及该手机标注的用户的性别和年龄。
作为一个类别实例,所述连续性特征包括移动终端屏幕尺寸、移动终端系统版本;所述离散型特征包括移动终端安装包列表、每个安装包对应的应用类别、移动终端品牌、移动终端品牌下的型号、移动终端操作系统及该移动终端标注的用户的性别和年龄段信息。
在上述实施例中,embedding是一个将离散变量转为连续向量表示的一个方式。embedding字面理解是“嵌入”,实质是一种映射,从语义空间到向量空间的映射,同时尽可能在向量空间保持原样本在语义空间的关系,如语义接近的两个词汇在向量空间中的位置也比较接近。
在神经网络中,embedding是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
one-hot编码的最大问题在于其转换不依赖于任何的内在关系,而通过一个监督性学习任务的网络,我们可以通过优化网络的参数和权重来减少loss以改善我们的embedding表示,loss越小,则表示最终的向量表示中,越相关的类别,它们的表示越相近。
基于相关联的技术手段,本发明整体上解决了样本数据进行编码化处理将会带来大量的数据稀疏问题。
图3是基于图1所述方法实现的用户性别识别方法的主要流程图。
图3所述方法包括步骤s1-s6,各个步骤具体实现如下:
s1:获取移动终端样本数据;
s2:将所述样本数据进行特征分类,得到连续性特征和离散型特征;
s3:对所述连续性特征和离散型特征分别进行不同的处理后,采用one-shot编码表示,得到one-shot样本特征;
s4:将所有one-hot样本特征进行embedding映射;
s5:基于embedding映射后的样本特征构建全连接神经网络模型并进行训练;
s6:采用训练好的全连接神经网络模型,输入移动终端用户特征,预测用户性别。
其中所述全连接深度神经网络模型是在基于单层感知机网络模型的基础上,加入多个隐含层的人工神经网络;
所述训练包括根据样本数据特点逐层搭建全连接神经网络模型,训练神经网络模型,并不断反向调整优化模型参数,得到调整后的全连接神经网络模型。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!