一种为图像分类器进行对抗样本防御的方法与流程
本发明涉及一种为图像分类器进行对抗样本防御的方法,所述图像分类器为基于神经网络的图像分类器,属于图像分类领域。
背景技术:
近年来,随着数据规模和计算能力的爆炸式增长,深度学习得到飞速发展,其中神经网络以优异的性能广泛服务于诸多应用之中。例如在图像分类中,采用了神经网络技术的图像分类器能够取得极佳的分类效果。然而,神经网络也面临着严峻的安全问题,对抗样本便是其中的一个典型示例。
对抗样本是一类通过人为手段向正常图片中添加微弱扰动而形成的恶意图片,它能够误导基于神经网络的图像分类模型,使其产生错误的输出。因而对抗样本的存在严重威胁着分类模型的鲁棒性,尤其是当模型所涉及到的安全性要求比较高时,威胁则更甚。
对抗训练作为一种有效的防御方法而受到了广泛的使用。其核心思想是在模型训练的每一次迭代中,借助当前模型与某种攻击算法动态地生成对抗样本,并将之作为训练数据,与原图像训练数据共同实现模型当前轮次的训练。经由对抗训练得到的模型能够显著提升自身对于对抗样本的抵御能力。然而对抗训练对图像训练数据的使用并不充分,其忽略了不同图像数据间的相互关系,存在一定的弊端。在经由对抗训练的模型的特征空间上,同类数据特征的距离不够近,不同类数据特征间隔不够远且彼此存在重叠,因而不利于模型的鲁棒性。
技术实现要素:
发明目的:针对现有技术中存在的问题与不足,本发明提供一种为图像分类器进行对抗样本防御的方法,有效弥补传统图像分类器对抗训练算法的不足,进一步提升分类模型在应对对抗样本攻击时的抵御能力。
任意一组对抗样本与正常图像数据间存在三种关系:1)对抗样本是由正常图像数据生成,两者一一对应;2)对抗样本与正常数图像据同属一个类别,但并非一一对应;3)对抗样本与正常图像数据分属不同的类别。本发明将传统对抗训练算法与暹罗架构相互结合,并且设计对抗样本的重排机制,从而充分利用对抗样本与正常图像数据间的上述三种关系,能够在特征空间上,有效降低类内距并扩大类间距,使得训练出的模型对对抗样本具有更强的抵御能力。
技术方案:一种为图像分类器进行对抗样本防御的方法,包括如下步骤:
步骤1,构造模型,准备图像训练数据;
步骤2,将图像训练数据随机划分成多个mini-batch;
步骤3,借助一个mini-batch的图像训练数据实现模型的一次参数更新;
a)选择一个尚未参与计算的mini-batch的图像训练数据,生成对应的对抗样本;
b)将上一步生成的对抗样本与对应的图像训练数据混合,并调整对抗样本中各图像数据的相对位置;
c)借助反向传播算法,更新一次模型参数;
步骤4,重复步骤3,直至步骤2所划分的mini-batch全部参与了计算;
步骤5,重复步骤2-4,直至模型完成训练;
步骤6,输出步骤5完成训练的模型。
将图像训练数据集随机划分成多个mini-batch
假设图像训练集中共包含d条图像训练数据,预设的mini-batch的大小为n。首先将d条图像训练数据随机打乱,之后按照mini-batch的大小依次选取图像训练数据,从而图像训练集共被分成了m个mini-batch。
选择一个尚未参与计算的mini-batch的图像训练数据,生成对应的对抗样本
任取一组尚未使用过的mini-batch的图像训练数据x=(x1,x2,…,xn),在当前的模型下,采用某种对抗攻击算法生成x对应的对抗样本
混合生成的对抗样本与对应图像训练数据,调整对抗样本中各图像数据的相对位置
预设划分比例λ,λ∈[0,1],按照λ将对抗样本
借助反向传播算法,更新一次模型参数
假设模型的参数是w,设定学习率为a。定义损失函数如下所示:
其中α、β、γ为预设的超参数,l(·)为交叉熵损失函数,lcon(·)为对比损失函数。训练时采用暹罗架构,x与
重复步骤2-4,直至模型完成训练
预设训练轮数n,在每一轮中,将图像训练集随机分割成m个mini-batch,实现模型的m次参数更新,完成模型训练。
所述超参数包括:模型学习率、mini-batch的大小、最大迭代次数、损失函数各分量的系数α、β和γ、对抗样本划分比例。
所述模型为基于神经网络的图像分类器。
所述图像训练数据为图片格式的数据。
所述某种对抗攻击算法,包括:有目标攻击或无目标攻击、迭代式攻击或单步式攻击、不同范数攻击,所述不同范数包括:l0、l1、l2和l∞。
有益效果:与现有技术相比,本发明提供的为图像分类器进行对抗样本防御的方法,具有如下优点:本发明首次将对抗训练与暹罗架构相互结合,设计了对抗样本的重排机制,使得图像分类模型在训练过程中能够充分利用图像数据间的相互关系,进一步提升其对对抗样本的防御能力。
附图说明
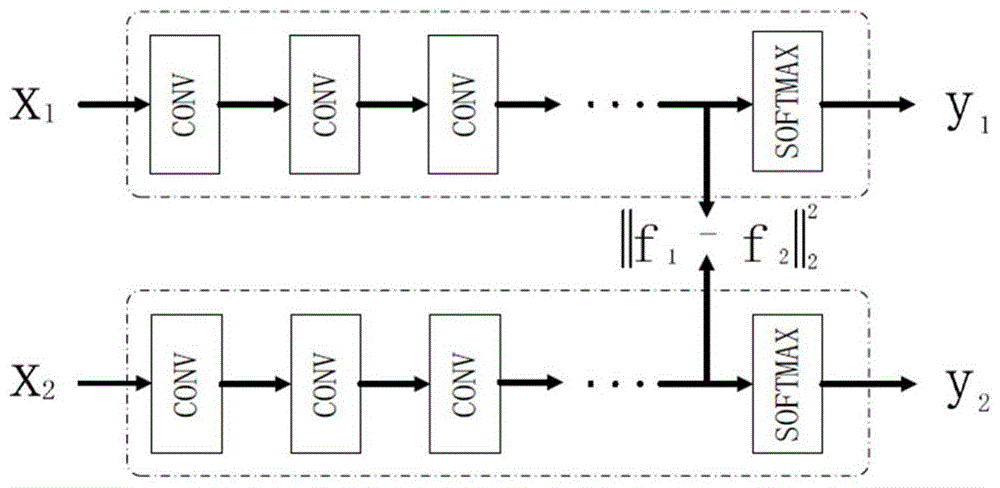
图1为本发明实施例中暹罗架构图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
这里以cifar10数据集的分类问题为例,对本发明进行具体的介绍。cifar10数据集包含60000张32×32的彩色图片,共分10类,每类各有5000张训练图片和1000张测试图片。我们选取神经网络resnet18作为分类模型对cifar10数据集实施分类。需要注意的是cifar10数据集的分类问题仅仅用于说明本发明而不用于限制本发明,本领域技术人员对本发明进行的各种形式的等价修改均属于本发明所附权利要求所限定的范围之内。
针对cifar10数据集的分类问题,具体实施方式对应如下具体步骤:
步骤1,构造神经网络resnet18作为图像分类器,准备cifar10训练数据集共50000张图片,设定超参数:模型的学习率为0.1、mini-batch的大小为256、最大迭代轮数为100、损失函数分类各分类系数α=0.5、β=0.5、γ=1.0、对抗样本分割比例为0.5;
步骤2,根据mini-batch预设的大小,将训练数据随机划分成m个mini-batch,
其中
步骤3,借助一个mini-batch的训练数据实现模型的一次参数更新。在算法实施之前,首先选取pgd算法用于对抗样本的生成,并设定pgd算法迭代次数s=7,步长为α=2/255,扰动上届ε=8/255。之后,依次按下述步骤执行:
a)以当前模型为目标模型,将一组mini-batch的训练数据x=(x1,x2,…,xn)用pgd算法生成对应的对抗样本
其中,
b)调整a)中生成的批量对抗样本中各元素的位置。鉴于预设的分割比例λ=0.5,所以首先将
c)记当前resnet18的模型参数为w和b。将两个参数相同的resnet18组合成暹罗架构的形式,如图1所示,对抗样本和正常训练数据分别作为一支网络的输入。采用如下的损失函数计算参数的梯度:
其中=0.5、β=0.5、γ=1.0。更新模型的参数:
步骤4,重复步骤3,依次使用所划分的mini-batch更新模型参数w和b,直至所有的mini-batch全部参与计算。
步骤5,根据预设的最大迭代轮数,重复步骤2、3和4共100次,每次重复则完成了模型的一轮训练。同时为了模型的训练能够取得更优的效果,对模型的学习率进行衰减。具体而言,每经过40轮,学习率减小至原本的1/10。
步骤6,输出训练好的resnet18模型。由于使用的暹罗架构由两支同参数的resnet18组成,所以任意输出其中一支即可。
我们将按照上述步骤获得的分类模型记为sat。同时为了更好评估模型性能,我们采用传统对抗训练方法,保持网络结构不变、基本超参数一致,获得了cifar10数据集的分类模型,记为at。表一对比了两者在应对不同攻击时的模型准确率。
表一cifar10数据集上的不同攻击下的模型准确率比较
我们采用模型准确率评估算法性能,模型准确率=分类正确的对抗样本数/总测试对抗样本数。选取了5种常见的攻击fgsm、pgd、bim、cw和jsma,其中pgd也被用来模型训练。可以看到本发明提出的对抗训练算法在应对上述攻击时的模型准确率均高于传统的对抗训练算法,增幅在2%~7.3%之间,因而能更好防御对抗样本的攻击。
常见的对抗攻击算法分别见如下论文:
fgsm,goodfellowij,shlensj,szegedyc.explainingandharnessingadversarialexamples[j].arxivpreprintarxiv:1412.6572,2014;
pgd,madrya,makelova,schmidtl,etal.towardsdeeplearningmodelsresistanttoadversarialattacks[j].arxivpreprintarxiv:1706.06083,2017;
bim,kurakina,goodfellowi,bengios.adversarialmachinelearningatscale[j].arxivpreprintarxiv:1611.01236,2016;
cw,carlinin,wagnerd.towardsevaluatingtherobustnessofneuralnetworks[c]//2017ieeesymposiumonsecurityandprivacy(sp).2017:39–57.;
jsma,papernotn,mcdanielp,jhas,etal.thelimitationsofdeeplearninginadversarialsettings[c]//2016ieeeeuropeansymposiumonsecurityandprivacy(euros&p).2016:372–387。
- 还没有人留言评论。精彩留言会获得点赞!