基于多相关日场景生成的充电负荷区间预测方法与流程
本发明属于ev充电负荷预测技术领域,具体涉及基于多相关日场景生成的充电负荷区间预测方法。
背景技术:
随着微网内ev充电负荷渗透率不断增加,具有强随机性的充电负荷严重影响了微网系统运行的可靠性与经济性。因此,ev充电负荷预测是进行微网规划与调度、运行风险评估、ev与微网双向互动等研究的基础。
现有ev充电负荷预测多基于模型驱动,主要有以下研究:一、通过分析ev每天最晚回家时间分布,计及不同类型ev影响,采用蒙特卡洛(montecarol,mc)方法抽取起始充电时间进行充电负荷预测。二、对传统汽车用户的行驶规律进行分析,采用mc方法建立了考虑ev类型、渗透率、充电情景等因素的规模化充电需求模型。三、考虑交通路网约束,分析ev用户行车轨迹特性,模拟1天内的充电负荷时空分布特性。四、以排队论为理论基础,假设ev抵达充电站的时间服从泊松分布,开展充电负荷预测。五、采用停车生成模型预测停车需求,建立ev停车时空分布模型,在基础上开展充电负荷预测。六、针对ev充电负荷时空随机性的问题,考虑了实时温度与路况,提出一种基于随机路径模拟的充电负荷时空分布预测方法。七、基于移动社交网络,考虑了ev向电力系统反向送电的行为,提出一种在分时电价约束下的ev充放电行为预测方法。八、通过建立描述ev并网充电的动态物理过程来计算其充电负荷,其中假设ev并网时的剩余电量服从正态分布。
相较于基于模型驱动的ev充电负荷预测方法,基于数据驱动的预测方法能够综合利用ev历史充电数据,简化ev充电负荷预测模型,不需假设大量模型参数等优点。有的考虑ev的移动特性,建立考虑行驶特性和充电特性的ev模型,得到充电负荷确定性预测结果。还有的基于经验模态分解-模糊熵和集成学习,提出一种ev充电负荷的确定性预测方法。再或者分析公交车充电站的负荷特性,提出了一种基于数据新鲜度和交叉熵的组合预测方法。此外,基于数据驱动的深度学习方法在ev充电负荷预测领域也取得了较好的效果。但是,现有深度学习方法在预测环节较少考虑ev历史日充电行为与待预测日充电行为间的相关性,预测效果有待提升。
从现有研究成果看,确定性预测结果难以反应ev充电负荷的强随机性与不确定性对微网带来的风险;而区间预测结果更能够反映ev充电负荷的强随机性。同时,基于模型驱动的ev充电负荷方法建模时涉及变量较多,且模型中存在较多假设条件,使得ev充电行为的分析偏于主观。
技术实现要素:
本发明的目的是提供基于多相关日场景生成的充电负荷区间预测方法,解决了现有基于模型驱动的预测方法中存在较多假设条件,使得ev充电行为的分析偏于主观的问题。
本发明采用的技术方案是,基于多相关日场景生成的充电负荷区间预测方法,具体按照以下步骤实施:
步骤1、基于sr相关系数理论,分析待预测日与历史各日ev充电行为的日间相关性,构建多相关日场景集;
步骤2、以多相关日场景集为基础,构建基于β-vae的ev充电负荷场景生成模型,生成海量充电场景;
步骤3、在生成海量充电场景中筛选与待预测日的极强相关历史日间充电行为相关性强的场景,组成相似场景集;
步骤4、根据相似场景集最后一日数据得到ev充电负荷区间预测结果。
本发明的特点还在于:
步骤1具体过程为:
步骤1.1、根据sr相关系数公式计算待预测日与历史各日ev充电行为的日间相关性,确定极强相关日;
步骤1.2、按时间顺序选取待预测日的历史十日内极强相关的ev充电负荷,构成多相关日场景集。
步骤1.1中sr相关系数公式如下:
式中:
当
步骤2具体过程为:
取编码器的识别模型为qφ(z|x),编码器的生成模型为pθ(x|z),场景生成的概率分布pθ(x|z),假设数据集d={x,v,w},其中
生成样本由两个隐变量共同生成,利用数据x能得到x和z的联合分布,其中,
利用拉格朗日kkt条件构建网络的损失函数为:
通过损失函数寻求多相关日场景集中特征,进而生成海量充电场景。
步骤3具体过程为:
以待预测日与各相关历史日的相关系数为权系数,规定待预测日d的全部极强相关历史日与生成场景集中第j个样本间对应历史日的加权sr相关系数为sj,表达式如式(4)所示:
式中:
根据式(4),按照加权sr相关系数sj从大到小的顺序,在生成场景集中筛选与待预测日极强相关历史日间相似性高的m个样本,构成相似场景集。
步骤4具体过程为:
以相似场景集最后一日数据[ppre]m×96,由式(5)得到ev充电负荷区间预测结果;
式中:pmax,t、pmin,t分别为t时刻ev充电负荷预测区间上下限;pmean,t为t时刻ev充电负荷确定性预测结果。
本发明的有益效果是:
本发明基于多相关日场景生成的充电负荷区间预测方法,能够获得覆盖率高、宽度窄的预测区间及精确的充电负荷区间预测结果;与gpr概率预测方法相比,本发明的预测指标更优,能够准确覆盖ev充电负荷波动性区间;预测区间越限值更小,有利于微网的安全与经济运行。
附图说明
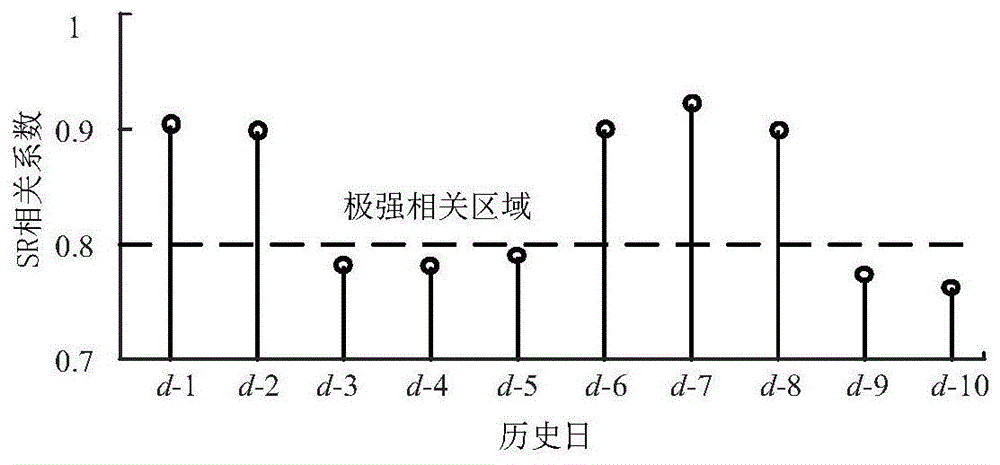
图1是待预测日与历史日ev充电负荷日间相关性图;
图2是多相关日场景与生成场景数据概率分布特性图;
图3是不同场景集规模方案的预测指标箱线图;
图4(a)是各时刻实际值超出预测区间的最大值分布图;
图4(b)是各时刻实际值超出预测区间的均值分布图;
图5(a)是春季的日内ev充电负荷预测结果对比图;
图5(b)是夏季的日内ev充电负荷预测结果对比图;
图5(c)是秋季的日内ev充电负荷预测结果对比图;
图5(d)是冬季的日内ev充电负荷预测结果对比图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于多相关日场景生成的充电负荷区间预测方法,具体按照以下步骤实施:
步骤1、基于sr相关系数理论,分析待预测日与历史各日ev充电行为的日间相关性,构建多相关日场景集;
步骤1具体过程为:
步骤1.1、根据sr相关系数公式计算待预测日与历史各日ev充电行为的日间相关性,确定极强相关日;
步骤1.2、按时间顺序选取待预测日的历史十日内极强相关的ev充电负荷,构成多相关日场景集。
步骤1.1中sr相关系数公式如下:
式中:
当
ev充电负荷数据采用美国中西部地区2009年住宅能耗调查(residentialenergyconsumptionsurvey,recs)数据集中随机选择的348辆汽车的家庭插电式ev充电配置文件,包括每辆车一年365天的充电负荷数据记录。参考现有研究,将采样间隔设为15分钟,即每天96点。考虑待预测日ev充电负荷受历史日充电行为影响,因此基于多日间充电负荷相关性,构建能够反映ev用户充电行为间关联性的多相关日场景。由于实测数据中,ev充电负荷不服从正态分布如图1所示,而sr相关系数可用于分析数据相关性,且数据不须满足正态性假设。故采用sr相关系数理论分析待预测日与历史日ev充电负荷之间相关性。sr相关系数公式如式(1)所示。
基于式(1),分析待预测日d与其历史十天各日的ev充电负荷的相关性。分析结果如图2所示。图2反映历史各日充电行为对待预测日充电行为的影响程度。当
故按时间顺序构建包含待预测日及其5个极强相关历史日的ev充电负荷多相关日场景,随机选取一年中285个充电负荷多相关日场景构成多相关日场景集,用于训练β-vae模型。剩余70个多相关日场景作为测试集评价预测效果优劣。
步骤2、以多相关日场景集为基础,构建基于β-vae的ev充电负荷场景生成模型,生成海量充电场景;
步骤2具体过程为:
取编码器的识别模型为qφ(z|x),编码器的生成模型为pθ(x|z),场景生成的概率分布pθ(x|z),假设数据集d={x,v,w},其中
生成样本由两个隐变量共同生成,利用数据x能得到x和z的联合分布,其中,
利用拉格朗日kkt条件构建网络的损失函数为:
vae能以无监督的形式实现对ev充电负荷多相关日场景集数据分布特性的挖掘。
β-vae假设数据是基于互相独立的因素生成的,得到ev充电负荷数据的简洁抽象表示,提取多日间具有极强相关性的充电负荷的关键特征并生成具有日间相关性的海量场景。如式(3)所示,β-vae通过可调节超参数β引入解缠性先验,当β=1时为标准vae,以β控制隐变量维度与重建精度间平衡。其网络损失函数为:
式(3)第一项为重构误差,使重构的pθ(x|z)更接近于输入分布pθ(x);第二项旨在减小kl散度,使后验分布qφ(z|x)更接近于pθ(z),限制隐变量信息瓶颈。可从元学习角度提取解缠特征,使其表征能力更强。
通过损失函数寻求多相关日场景集中特征,进而生成海量充电场景。
由于所用ev充电负荷数据分辨率为每天96点,故将包含6天充电负荷数据的多相关日场景(共96×6个点)重塑为24×24的矩阵作为β-vae的输入元组。
步骤3、在生成海量充电场景中筛选与待预测日的极强相关历史日间充电行为相关性强的场景,组成相似场景集;步骤3具体过程为:
以待预测日与各相关历史日的相关系数为权系数,规定待预测日d的全部极强相关历史日与生成场景集中第j个样本间对应历史日的加权sr相关系数为sj,表达式如式(4)所示:
式中:
根据式(4),按照加权sr相关系数sj从大到小的顺序,在生成场景集中筛选与待预测日极强相关历史日间相似性高的m个样本,构成相似场景集。
步骤4、根据相似场景集最后一日数据得到ev充电负荷区间预测结果;
步骤4具体过程为:
以相似场景集最后一日数据[ppre]m×96,由式(5)得到ev充电负荷区间预测结果;
式中:pmax,t、pmin,t分别为t时刻ev充电负荷预测区间上下限;pmean,t为t时刻ev充电负荷确定性预测结果。
为确定ev充电负荷预测所需的生成场景集与相似场景集规模,采用预测区间覆盖率(picp)、预测区间平均宽度(pinaw)分析不同场景集规模下的区间预测效果,采用平均绝对百分比误差(mape)分析不同场景集规模下的确定性预测效果。picp表征预测区间的可靠性,值越大区间越可靠;pinaw表征预测区间精锐程度,值越小,区间上下限与真实值越贴近;mape将误差百分化,比较确定性预测结果精度。
生成场景集规模分别设为1000组、5000组、20000组样本,相似场景集规模分别设为生成场景集规模的1%、2%、3%、4%、5%时。分析测试集中每天预测效果,得到不同场景集规模方案预测指标分布,如图3所示。
由图3可知,不同方案的mape指标差别很小,故主要分析picp指标与pinaw指标来确定最优相似场景集方案。picp最小值反映预测效果下限,为保证预测区间可靠性,将picp下边缘低于75%的筛选方案排除,包括生成1000组样本筛选比例为1%-3%及生成20000组样本筛选比例为1%、2%共五种筛选方案,还剩余10种筛选方案供选择。分析pinaw,生成1000组样本筛选比例为5%、生成5000组样本筛选比例为3%-5%这四种筛选方案的上边缘接近,生成1000组样本筛选比例为5%、生成5000组样本筛选比例为3%、生成20000组样本筛选比例为2%与3%这四种筛选方案的下边缘接近,分析其上下边缘难以评估不同方案的优劣,故分析不同方案的pinaw中位数。求得15种筛选方案picp中位数的均值为27%。将picp中位数大于均值的筛选方案排除,共排除7种筛选方案,还剩余3种筛选方案供选择,包括生成1000组样本筛选比例为4%、生成5000组样本筛选比例为1%、2%三种方案,相关指标分布如图中虚线圈画范围。由图可知,三种方案的picp与pinaw中位数差别很小,故分析两种指标的最恶劣数值以反映预测方法的预测效果下限。三种方案的picp下边缘分别为80%、75%、84%,pinaw指标上边缘分别为29%、29%、31%。前两种方法牺牲较大预测区间可靠性以降低较小的区间宽度,略微提高了决策的参考价值,但更大程度上牺牲了预测的精确度,因此以生成5000组样本时筛选比例为2%(即相似场景集包含样本数m为100)的相似场景集方案作为ev充电负荷的场景区间预测新方法。最终确定,测试集下新方法的picp、pinaw、mape分别为94.5%、26.5%、15%。
由以上数据可知,本发明的充电负荷区间预测方法的picp数值高,能够有效跟踪ev充电负荷的波动;pinaw数值低,预测区间平均宽度窄,区间上下限与真实值接近,有利于决策的经济性;mape数值低,反映了ev充电负荷确定性预测结果与真实值之间的误差小。上述指标分析验证了本文新方法取得了较好的预测效果。
采用区间预测效果较好的高斯过程回归(gaussianprocessregression,gpr)开展对比实验。使用相同recs数据集,对于待预测日d的t时刻ev充电负荷,构建包含d-8、d-7、d-6、d-2历史日全部充电负荷与d-1日t时刻充电负荷共385维特征作为输入特征集。训练集与测试集合设置与本发明方法相同。置信度设置为95%,核函数为ardexponential。
1、预测指标分析
基于相同测试集,两种预测方法的预测指标见表1。
表1预测指标
分析表1,新方法各预测指标均优于gpr,其中,picp与pinaw指标明显优于gpr,反映了新方法区间预测效果良好。
2、预测区间越限值分析
若ev充电负荷实际值超出预测区间的数值过大,将严重影响微网系统运行可靠性。故比较不同方法超出预测区间的功率值。定义pbub,t、pblb,t分别为t时刻实际充电负荷超出预测区间上、下限功率值,计算方法如下:
式中:pact,t为t时刻实际充电负荷值,pmax,t、pmin,t分别为t时刻充电负荷预测区间上下限。
图4(a)展示了测试集中待预测日不同时刻真实数据超出预测区间上下限的功率最大值。新方法与gpr方法的pbub,t最大值分别为102kw、118kw,新方法与gpr方法的pblb,t最大值分别为71w、142kw,从预测区间越限值的最恶劣情况验证了新方法优于gpr方法。图4(b)展示了测试集中待预测日不同时刻真实充电数据超出预测区间上下限的功率均值。观察可知,新方法与gpr方法相比,预测区间越限值与零轴的包络面积更小,从潜在的预测区间越限值电量角度验证了新方法优于gpr方法。
3、不同季节日内区间预测效果分析
在春夏秋冬四季各随机选取一天,对比分析两种方法不同季节预测效果,如图5(a)-图5(d)所示,其中图5(a)为3月24日预测效果,图5(b)为7月4日预测效果图,图5(c)为10月17日预测效果图,图5(d)为12月14日预测效果图。
实验数据中,3月24日与12月14日为工作日,10月17日为非工作日,7月4日为节假日(独立日)。7月4日的ev充电负荷值与其他3日相比更小。主要因为节假日微网内ev车主外出,微网内ev充电需求降低。从不同季节工作日角度分析ev充电负荷,季节差异对ev充电行为影响较小,如3月24日与12月14日的ev充电负荷的变化趋势与充电负荷的波动情况较为相似,主要因为微网内ev车主用车习惯一般不受季节影响。由图5(a)-图5(d)可知,ev充电负荷发生剧烈变化的时刻,gpr无法有效跟踪充电负荷变化,导致充电负荷实际值超出其预测区间范围,如图中各虚线框内区域所示。分析这四天的区间预测指标可知,新方法的picp更高,反映真实ev充电负荷变化的能力更强;新方法pinaw更小,有助于提高微网运行经济性。分析图5(a)-图5(d)各日mape,两种方法在不同预测日mape存在差异。但从四天mape均值分析,新方法为14.9%,gpr方法为17.1%,新方法确定性预测结果精确度更高。
通过上述方式,本发明基于多相关日场景生成的充电负荷区间预测方法,能够获得覆盖率高、宽度窄的预测区间及精确的充电负荷区间预测结果;与gpr概率预测方法相比,本发明的预测指标更优,能够准确覆盖ev充电负荷波动性区间;预测区间越限值更小,有利于微网的安全与经济运行。
- 还没有人留言评论。精彩留言会获得点赞!