多角度引入属性语义的知识表示学习方法和系统与流程
本发明涉及知识表示学习领域,特别涉及融合数字外部信息的知识表示的建模,具体涉及一种多角度引入属性语义的知识表示学习方法和系统。
背景技术:
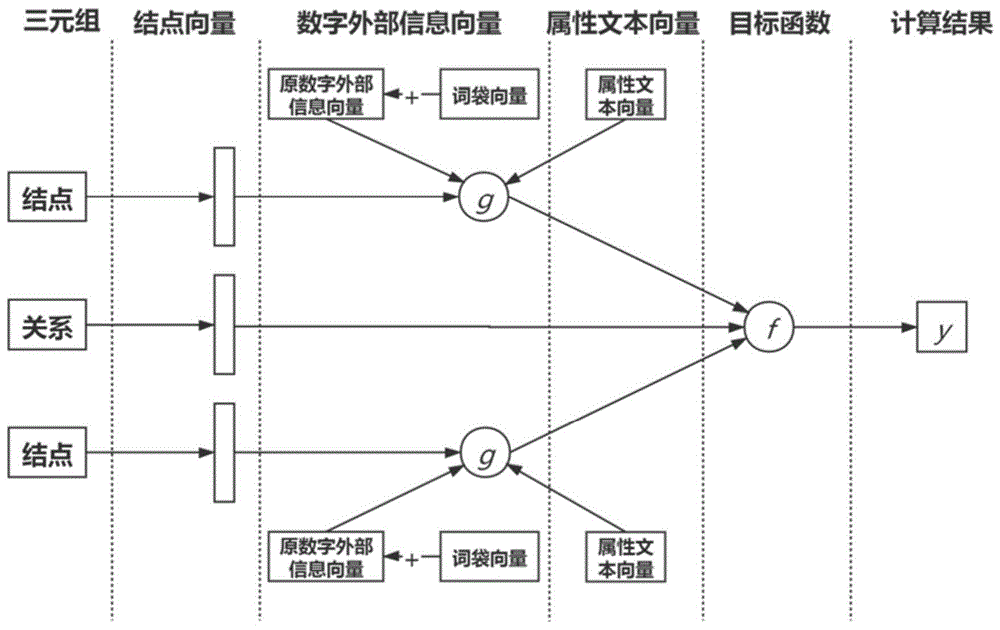
:近些年,知识图谱(knowledgegraph,kg)推动了许多知识驱动的应用,如问答和数据集成。dbpedia、freebase、yago3是知识图谱中应用最广泛,也最为人们熟知的数据集。它们将知识存储在包含两个实体及其关系的三元组中。面向知识图谱的表示学习是知识工程领域中十分重要的一项工作,这项工作促进了一些下游任务的开展,如链路预测和实体分类等。知识表示学习(kgrepresentationlearning)也称为知识嵌入学习(kgembedding),目的是将知识图谱的元素编码为低维的嵌入式表示。这些量化的嵌入式表示可以捕获全局模式(也称为基于结构的信息),并使计算给定三元组的存在性成为可能。目前,基于实体和关系之间连接关系(结构信息)的知识表示学习方法可以分为基于翻译的模型、基于语义匹配的模型和基于神经网络的模型三类。transe及其引申模型等基于翻译的模型把关系看作两个实体之间的翻译操作,并以此作为训练的目标。语义匹配模型,如rescal、distmult、complex,利用三维矩阵来表示图谱,此矩阵中的值代表是否存在该三元组,他们通过矩阵分解来得到实体和关系的表示。conve和convkb等神经网络模型则是引入神经网络作为其核心结构。近年来,越来越多的工作试图在传统的包含结构信息的数据库中添加额外的信息,以更详细地描述实体或关系。这些外部信息往往通过具体的属性与实体或关系进行连接。根据这些外部信息的数据类型,模型可分为四类:基于文本外部信息的模型(dkrl,kdcoe),基于图像外部信息的模型(ikrl),基于数字外部信息的模型(literale,mt-kgnn,kblrn)以及基于多模态外部信息的模型(eakgae,mkbe)。它们对这些外部信息进行编码,并将它们与实体或关系的嵌入式表示相结合,得到了更佳的实体表示。如在融合图像信息的工作中,ikrl为现有知识图谱中的实体添加相应的图片,利用cnn或注意力模型对图片信息进行表征,并将其与实体表征结合,利用transe的思想学习实体和关系的向量表示,该工作将图片中的包含关系或是视觉上的相似关系加入到知识图谱表示当中;在融合文本的工作中,dkrl利用自然语言处理方法对文本数据进行表征并与结点表征进行融合,同样在transe的框架下对三元组的表征进行学习;在融合数字外部信息的工作中,literale对结点的数字描述依据其属性构造表征向量,并同样与结点表征进行融合输入到表示学习框架中(该方法将会在方法原理部分作细致说明)。但是已有的引入数字外部信息的方法仅将属性作为构造表示向量时维度划分的依据,而忽略了属性本身的语义。因此,属性语义信息的编码以及语义信息同数字外部信息的融合是十分必要的工作。这将会使得外部数据信息得到充分利用,并提升表示学习效果,从而为下游任务提供帮助。技术实现要素:本发明的主要目的在于提供两种引入属性语义信息的角度,即通过不同的方法对语义信息进行编码,并利用两种方式将其与结点的嵌入式表示以及数字外部信息的嵌入式表示进行结合。这两个角度都对先前的数字形式的外部数据进行了更充分的利用,并最终提高了表示学习效果。本发明的另一目的在于利用更优的嵌入式表示结果进行基于知识图谱的链接预测。本发明采用的技术方案如下:一种多角度引入属性语义的知识表示学习方法,包括以下步骤:对结点的属性语义进行表征,得到属性文本的嵌入式表示;将属性文本的嵌入式表示与结点的嵌入式表示及数字外部信息的嵌入式表示相结合,代入到融合数字外部信息的知识表示学习模型中;通过融合数字外部信息的知识表示学习模型得到实体和关系的嵌入式表示。进一步地,所述对结点的属性语义进行表征,采用以下两种方式中的至少一种:利用词袋模型对属性的语义进行表征;将属性看作结点的描述性文本,利用自然语言处理工具对描述性文本的语义进行表征。进一步地,所述利用词袋模型对属性的语义进行表征,包括:提取属性的描述性词汇,构造属性语义的嵌入式向量,该向量的各个维度为各个描述性词汇;当某个属性包含某个描述性词汇时,则该描述性词汇对应的维度处数值表示为1,不存在的描述性词汇所对应维度处表示为0,即构成属性的词袋特征。进一步地,将属性的词袋特征与数字外部信息的嵌入式表示结合,形成新的数字外部信息的嵌入式表示;将新的数字外部信息的嵌入式表示与结点的嵌入式表示融合,代入到融合数字外部信息的知识表示学习模型中,得到实体和关系的嵌入式表示。进一步地,所述将属性看作结点的描述性文本,利用自然语言处理工具对描述性文本的语义进行表征,包括:将属性预处理为文本形式,并针对结点进行汇总,每个结点都得到一个描述性文段;通过自然语言处理工具对描述性文段进行处理,得到文段的嵌入式表示。进一步地,将文段的嵌入式表示与结点的嵌入式表示及数字外部信息的嵌入式表示进行融合,代入到融合文本外部信息的知识表示学习模型中,得到实体和关系的嵌入式表示。进一步地,所述将属性文本的嵌入式表示与结点的嵌入式表示及数字外部信息的嵌入式表示相结合,代入到融合数字外部信息的知识表示学习模型中,包括:将三部分嵌入式表示通过方程g进行融合,并得到同结点表征维度相同的表征向量;其中方程g为线性映射或非线性映射;在线性映射中,三部分嵌入式表征向量首先通过收尾连接得到一个新的衔接表征向量,该衔接表征向量通过乘以映射乘积矩阵变换到指定空间,而非线性映射则对三部分单独的表征向量和其首尾连接得到的衔接表征向量都予以考虑,各个部分均乘以其各自的映射矩阵,并将最终结果通过sigmoid函数和双曲非线性函数进行变换,从而得到指定空间下的向量;最终三元组各个元素的表征同时输入目标函数进行计算,计算结果为代表该三元组存在性的概率值。进一步地,在训练神经网络的过程中,输入为经过空间映射后的表征向量,输出为表示三元组存在可能性的概率值,训练过程中所计算得到的概率值与真实的标签之间的差距将作为反向迭代的依据,通过训练使得计算得到的概率值逐渐逼近真实的标签;通过反向传播,结点和关系的表征向量和参与运算的矩阵将进行迭代,每轮迭代过程包括根据与真实标签差距的反馈进行反向迭代更新,再利用更新后的向量重新正向计算概率值,在每步的迭代过程都使得结点和关系的表征向量得到调整,从而使其正向计算结果与真实标签接近,训练得到的三元组表征即为最终结点和关系的表征向量。一种多角度引入属性语义的知识表示学习系统,其包括:属性语义表征模块,用于对结点的属性语义进行表征,得到属性文本的嵌入式表示;融合模块,用于将属性文本的嵌入式表示与结点的嵌入式表示及数字外部信息的嵌入式表示相结合,代入到融合数字外部信息的知识表示学习模型中;知识表示学习模块,用于通过融合数字外部信息的知识表示学习模型得到实体和关系的嵌入式表示。一种基于知识图谱的链接预测方法,利用上述方法得到的实体和关系的嵌入式表示构成知识图谱,基于该知识图谱进行链接预测。本发明的有益效果如下:本发明解决了属性语义未被充分利用而造成的实体和关系的嵌入式表示不足够精确的问题,提供了两种引入属性语义信息的角度,这两个角度都对先前的数字形式的外部数据进行了更充分的利用,并最终提高了知识表示学习效果。本发明所得到的三元组的嵌入式表示可以应用于一些表示学习的下游工作,如链接预测和实体分类等。本发明将原始的引入外部信息的数据进行了扩充,通过提取数字外部信息数据中属性的描述性词语扩充了属性的语义描述数据;并通过将同一实体的所有描述性词语进行汇合构造针对实体的文本描述数据。附图说明图1是知识表示学习系统框架图。具体实施方式为了使本发明的目的、技术方案及优点更加清晰明了,以下将参照附图及实例,对本发明作进一步详细说明。1.方法原理部分:引入属性语义的知识表示学习方法的核心是对属性语义进行表征及将其与结点的嵌入式表示及数字外部信息的嵌入式表示结合。下面分别介绍本发明提出的两种语义表征方法及所对应的两种融合方式。第一种方法利用词袋模型对属性的语义进行表征(称为literale-an)。在原始的数字外部信息数据中,每个结点都由特定的属性与其对应的数值相连接。如:</m/0n5c9,http://rdf.freebase.com/ns/location.location.area,1245.78>,表示国家/m/0n5c9的面积为1245.78,而location.location.area则是一条具有“面积”的语义含义的属性。在传统的融合数字外部信息的知识表示方法,如literale中,模型将不同的属性作为构造表征向量时维度划分的依据:每个属性对应一个维度,而该维度处所对应的数值则为该属性对应的数字。具体过程如下所示:/m/01dvry属性1:tv.tv_program.number_of_seasons9/m/020trj属性2:people.person.height_meters1.74/m/0n5c9属性3:location.location.area1245.78/m/0n5c9属性4:location.dated_location.date_founded1739/m/0fczy属性5:topic_server.population_number214845所列数据为不同结点针对不同属性的数字外部信息,其中属性部分已删除了网址中相同的部分,保留了能够代表其语义含义的部分。在数字外部信息的表征过程中,依据结点及属性进行了如表1所示的构造(此处假设只包含所列数据的结点和属性)。表1数字外部信息表征向量构造方式结点\属性属性1属性2属性3属性4属性5/m/01dvry90000/m/020trj01.74000/m/0n5c9001245.7817390/m/0fczy0000214845在这个过程中literale并未考虑属性本身具备的语义信息。本发明的第一个方法,考虑属性所具有的语义信息,并利用类似数字外部信息表征的构造方式对其进行表征,即提取所有属性的描述性词汇(在本例中,如location、area),并依据他们构造新的向量,每一维对应一个词汇,该处数值则为0或1,1代表该属性具有该词汇,0代表不具有。这种表征方法被称为词袋模型。而后将每个结点对应的所有属性的词袋特征接入数字外部信息嵌入式表示之后得到新的嵌入式表示。依据上文例子,构造属性语义的表征过程如表2所示(此处只引用部分词汇)。表2属性语义信息表征向量构造方式结点\词汇programnumberpeoplelocationdatedpopulation/m/01dvry110000/m/020trj001000/m/0n5c9000110/m/0fczy010001最后,这些结点关于外部信息的嵌入式表示与传统的结点表征进行融合,并在统一的知识表示学习框架系进行学习,得到训练后的结点和关系的表征。本发明的第二种方法是将属性看作结点的描述性文本(称为literale-at),利用自然语言处理工具doc2vec对文本的语义进行表征。为了得到结点的描述性文本,需要先对该结点的所有属性进行描述性词汇的提取。由于属性为网址形式的文本,在预处理过程中,需将不具有任何含义的重复部分删除,并对具有描述意义的词语,如日期、人口数、地理信息等进行提取。并将这些词语汇总成为文段的形式,如表3所示。最后,利用doc2vec将这种人为构造的描述文本进行表征,得到的嵌入式表示再与结点的嵌入式表示及数字外部信息的嵌入式表示进行融合,并共同输入统一的表示学习框架。此处所提及的表示学习框架将在系统原理中进行详细描述。表3结点的表述性文本此外,由于两种语属性语义的引入角度截然不同,即前者将词袋特种接入数字外部信息的表征后再同结点的表征融合,后者是将文本的语义表征同结点和数字表征共同进行融合,所以可将两种角度进行结合(称为literale-combine),并在同一个训练过程中进行学习。2.系统描述部分:本发明基于知识表示学习对外部信息的引入方式进行研究,提出了两种引入属性语义的方法,并将融合后的结点的嵌入式表示输入到统一的知识表示学习框架中。该框架具有一致的思路和结构,如图1所示。本框架为同时利用两种属性语义引入方法的流程表示。该框架的嵌入式表示有三个部分:三元组的嵌入式表示、数字外部信息的嵌入式表示和属性文本的嵌入式表示。本发明的第一个角度即丰富数字外部信息表示的方法,将属性的词袋特征接入数字外部信息表征后得到新的数字外部信息的表征,并同结点的表征进行融合;第二个角度则为引入属性文本表征的模块,此模块作为单独的部分可同结点和数字外部信息的表征同时进行融合。该三部分嵌入式表示通过方程g进行融合(只考虑单一角度的流程与之类似,即去掉另一角度,此时只有两部分嵌入式表征通过g进行融合),并得到同结点表征维度相同的表征向量。在此映射过程中,方程g具有多种选择,即线性映射和非线性映射。在线性映射中,三部分嵌入式表征向量首先通过收尾连接得到一个新的表征向量,这个衔接表征向量通过乘以映射乘积矩阵变换到指定空间。而非线性映射则对三部分单独的表征向量和其首尾连接得到的衔接表征向量都予以考虑,各个部分均乘以其各自的映射矩阵,并将最终结果通过sigmoid函数和双曲非线性函数进行变换,从而得到指定空间下的向量。该映射的结果为新的实体的表征。最终三元组各个元素的表征同时输入目标函数f进行计算,计算结果为代表该三元组存在性的概率值y。此目标函数可为知识表示学习中的任何一种,如distmult、complex、conve等工作中所构造的目标函数。训练的核心是一个神经网络,训练的输入为经过空间映射后的表征向量,输出为表示三元组存在可能性的概率值。在训练过程中,所计算得到的概率值与真实的标签之间的差距将作为反向迭代的依据。这些标签区别于所得到的概率数值,其代表三元组是否存在的准确信息,它包括两个元素,即0或1,0代表三元组不存在,1代表存在。通过训练使得计算得到的概率值逐渐逼近真实的标签。而通过反向传播,结点和关系的表征向量和参与运算的矩阵将进行迭代,每轮迭代过程包括根据与真实标签差距的反馈进行反向迭代更新,再利用更新后的向量重新正向计算概率值。所以在每步的迭代过程都会使得结点和关系的表征向量得到调整,从而使其正向计算结果与真实标签接近。训练得到的三元组表征即为最终结点和关系的表征向量。最终,所得到的三元组的嵌入式表示将应用于一些表示学习的下游工作,如链接预测和实体分类。这些下游任务也真实地对表征结果的质量进行衡量。链接预测的任务是根据三元组中的两个元素预测另一个元素,如通过一个实体和关系预测另一个实体,或通过两个实体预测他们的关系。在该过程中,沿用上述目标函数计算三元组的存在性,并对得到的针对所有结点或关系的概率值进行排序,样本标签1所对应的结点或关系在排序中的排名将作为链接预测任务及表征结果的评价指标。实体分类任务是依据实体的嵌入式表示对实体进行聚类,并依据其真实的类别划分对其进行评价。表4、表5总结了在链接预测实验中的结果。链接预测是指根据给定的一个实体和关系来预测另一个实体。计算得到的各个实体的概率会根据大小进行排名,其真实标签所在的位置会作为实验的评价指标。在本实验中,指标包含两部分,一个是平均排名(meanrank),即所有样本排名的平均值;另一个是排名在所有样本中前n个的比例(hits@n),这里n为1或10。由表格可以得到本发明在两个数据集中均取得了最好成绩。整体上,literale-combine提高了基础模型(distmult-literale,complex-literale和conve-literale)的效果。比如hits@10(avg)在fb15k和fb15k-237数据集上分别提高了03%和10.9%。从表4中可以看出,基于complex的模型取得了更好的结果。其中本发明中的模型complex-combine是最优的,基础模型complex-literale是次优的。但是在fb15k-237数据集上,以distmult为基础的模型表现地更好。conve-combine在两个数据集上在mr这个指标上取得了最好的结果。mr指标比对比模型中最好的结果相比,在两个数据集上分别提高了20.3%和6.7%。为了评价组合体各部分的性能及其对最终结果的贡献,我们在三种基础模型上进行了烧蚀实验。表6总结了这一部分的结果。这里的评估指标是hits@10分数。从表6可以看出,literale-an,literale-at和literale-combine都要比literale好。除了一个数据,即在fb15k数据集上基于complex的模型。本发明的最好结果相较于literale分别提高3.1%、0.9%、1.0%、0.6%、0.5%、10.9%。通过对三个模型进行比较。可以看到,除了基于distmult的模型外,大多数组合模型都比其单一模型好。在这两个模型中,literalean的得分最高。在大多数情况下,an和at的贡献是差不多的,但是an更好一些。表4在fb15k数据集上的链接预测结果(最优结果用粗体表示)表5在fb15k-237数据集上的链接预测结果(最优结果用粗体表示)表6烧灼实验结果数据集/基础模型literaleliterale-anliterale-atliterale-combinefb15k/distmult0.7370.7680.7520.741fb15k/complex0.8490.8520.7590.858fb15k/conve0.8160.8220.8250.826fb15k-237/distmult0.4810.4870.4840.484fb15k-237/complex0.4270.430.430.432fb15k-237/conve0.3780.4640.4630.467本发明在对于文本外部信息编码时,不是必须采用dov2vec,任何能够将文本表示为向量形式的工具均可使用,如lstm,n-gram等。其他变形方式如将模型中的两个角度进行简单的组合方式的变换均包含在本发明思想中,如将用词袋方法表示的属性语义信息放在外部,即文本的编码向量处,与结点和数字外部信息的向量通过函数相融合;或将文本编码向量接在数字外部信息后等。以上公开的本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例和附图所公开的内容,本发明的保护范围以权利要求书界定的范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1