一种基于时空行为数据的跨社交网络虚拟用户身份对齐方法与流程
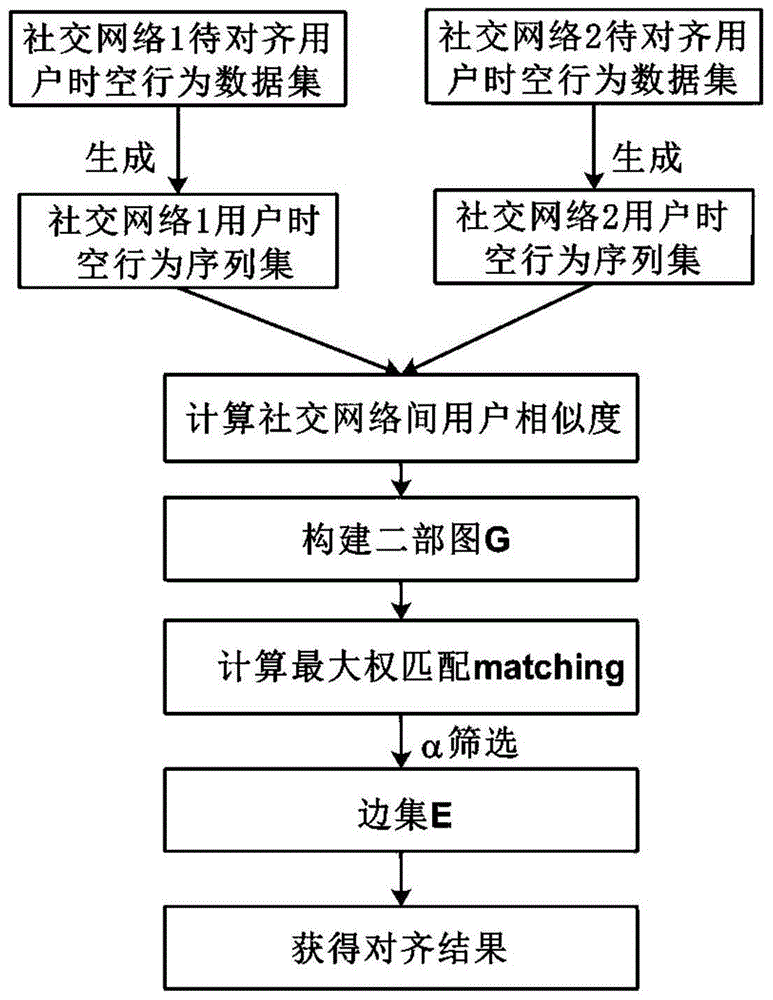
本发明属于社交媒体数据挖掘领域,特别涉及一种基于时空行为数据的跨社交网络虚拟用户身份对齐方法。
背景技术:
:随着在线社交网络等互联网技术的飞速发展与大规模普及,网络空间内的数据越发呈现出多源异构的特性。个体在不同社交网络上的虚拟身份可能具有不同的社交关系,出于保护隐私的目的,个体在社交网络上填写的用户属性可能不具有真实性,基于单一一种社交网络,技术人员很难准确评估用户的真实社交关系与属性,这给精准推荐带来了难度,因此对个体在多个社交网络中的虚拟身份进行综合分析是一个有效的解决办法。其中适合于大规模社交网络的虚拟用户身份对齐技术是关键的技术。当前主流的身份对齐技术主要包括基于虚拟用户在所属社交网络中的拓扑特性和基于用户属性进行对齐,由于社交网络的异构性以及用户填写的属性真实性存疑,上述技术的范围适用较窄,相比于拓扑特性和用户属性,用户的行为特性与时空数据在不同社交网络上具有更大相似性与更高的真实性,当能够有效获取用户在社交网络上的行为数据以及产生行为的时间与位置数据时,基于时空行为数据能够快速准确地实现跨社交网络虚拟用户身份对齐。因此,怎样利用时空数据与行为数据进行虚拟用户身份对齐,成为了一个研究重点。技术实现要素:为了克服上述现有技术的缺点,针对社交网络中用户身份虚拟化、隐蔽性的问题,本发明的目的在于提供一种基于时空行为数据的跨社交网络虚拟用户身份对齐方法,能够在规模较大的社交网络间实现快速、高效的虚拟用户身份对齐。为了实现上述目的,本发明采用的技术方案是:一种基于时空行为数据的跨社交网络虚拟用户身份对齐方法,包括如下步骤:步骤1,针对社交网络中用户时空行为数据,将时空网格化,使得每一个网格对应于一个网格编号grid_index,其中时间上可以一天作为粒度,空间上可以区(县)作为粒度,将用户在社交网络上的多种线上行为(包括3种指定行为:发布、转发、评论)进行离散编码,每一种线上行为对应于一个行为编号activity_index。步骤2,获取用户在社交网络上的线上行为对应的时间与位置数据,进而根据步骤1查找该时间与位置数据对应的时空网格的编号grid_index与该线上行为所对应的的行为编号activity_index,将该线上行为对应的网格编号grid_index和行为编号activity_index的组合作为一个行为元素e,行为元素e即二元组(grid_index、activity_index)。按时间顺序获取用户的在社交网络上所有线上行为的对应行为元素,由这些行为元素构成该用户的时空行为数据序列sequence,计算待对齐两个社交网络中所有待对齐用户的时空行为数据序列。步骤3,根据步骤2中的时空行为数据序列,计算两个社交网络间的任意两个用户的行为序列相似度,方法如下:步骤3.1,获取分属两个社交网络的两个用户的时空行为数据序列sequence1、sequence2,计算行为序列sequence1和行为序列sequence2的最长公共子序列subsequence;步骤3.2,计算作为sequence1与sequence2的相似度,其中|·|表示序列·的长度。步骤4,将两个社交网络中的用户分别划分为对应的两个节点集合,构建完全二部图,具体构建过程包括以下步骤:步骤4.1:获取待对齐的两个社交网络中的所有待对齐用户,为每一个用户定义一个相对应的节点。步骤4.2:对于分属于两个社交网络的两个用户节点,计算用户间的时空行为序列相似度,将序列相似度作为节点间边的权重,同一社交网络中的节点间无边,由此得到二部带权图g。步骤5,计算二部图的最大权匹配matching,可基于kuhn-munkres算法计算二部图最大权匹配。步骤6,根据二部图最大权匹配,从该匹配中删除权重小于给定阈值的边,将剩余每条边连接的两个节点作为对齐的两个用户,从而计算得到对齐用户,生成跨社交网络虚拟用户对齐结果,具体包括以下步骤:步骤6.1,定义阈值α,从二部图的最大权匹配matching中删除权重小于α的边,α的取值可为0.75;步骤6.2,对于matching中的任意一条边edge,获取edge的两个端点node1与node2,获取node1在社交网络1中对应的虚拟用户user1,获取node2在社交网络2中对应的虚拟用户user2,将user1与user2作为一对被对齐的虚拟用户。与现有技术相比,本发明的有益效果是:(1)、本发明仅通过用户的时空数据与社交网络基础行为数据进行身份对齐,不需要额外的用户拓扑数据以及真实性难以确定的属性等数据,大多数社交网络中用户时空数据与行为数据数据量丰富,因此本发明适用于大多数社交网络间虚拟用户身份对齐。(2)、本发明通过计算用户相似度进而基于二部图最大权匹配算法实现虚拟用户身份对齐,其中用户时空行为序列生成与时空行为序列相似度易于通过分布式框架进行计算,因此本发明适合于在大规模社交网络间进行虚拟用户身份对齐。附图说明图1为基于时空行为数据的跨社交网络身份对齐流程示意图。图2为用户时空行为序列相似度计算示意图。图3为由二部带权图最大权匹配生成对齐结果示意图。具体实施方式下面结合实施例对本发明做进一步详细描述,本发明整体流程如图1所示。一种基于时空行为数据的跨社交网络虚拟用户身份对齐方法,包括如下步骤:步骤s1:社交网络中用户时空行为数据预处理:本实施例中的数据集收集自微博和tweeter,数据集中包括1000个志愿者的微博账号在2019年12月的全部行为与该1000个志愿者twitter账号在2019年12月的全部行为。步骤s101:将时空网格化,时间上将一天作为粒度,空间上将区(县)作为粒度,每一个网格对应于一个编号grid_index,网格编号总数量等于区(县)总数乘以31(2019年12月有31天);将用户在社交网络上的3种线上行为(发布、转发、评论)进行离散编码,每一种行为对应于一个编号activity_index,发布、转发、评论三种行为的activity_index分别为0,1,2。步骤s102:获取用户在社交网络上进行上述线上行为的时间与位置数据,进而确定该时间点与位置所属的时空网格,查找得到时空网格编号grid_index,同时查找该行为所对应的行为编号activity_index,将(grid_index、activity_index)二元组作为一个元素e。按时间顺序获取用户在社交网络上所有上述线上行为的对应元素,由这些元素构成用户在该社交网络上的时空行为数据序列sequence。步骤s103:计算待对齐社交网络中所有待对齐用户在各自社交网络中的时空行为数据序列得到序列集sequence_set。步骤s2:基于时空行为数据序列计算社交网络间用户相似度,用户相似度的计算具体过程包括以下步骤,时空行为序列相似度计算过程如图2所示。步骤s201:从sequence_set中获取分属微博和tweeter的两个用户的时空行为数据序列sequence1、sequence2步骤s202:计算sequence1和sequence2的最长公共子序列subsequence步骤s203:计算作为sequence1与sequence2的相似度。步骤s3:构建以用户为节点的二部图,二部图具体构建过程包括以下步骤:步骤s301:为每一个待对齐用户定义一个相对应的节点。步骤s302:对于分属于两个社交网络的两个用户节点,计算用户间的时空行为序列相似度,将相似度作为节点间边的权重,同一社交网络中的节点间无边,由此得到二部带权图g,设社交网络1中拥有m个待对齐用户,社交网络2中拥有n个待对齐用户,则图g中共有m+n个节点,m×n条边。步骤s4:计算二部图的最大权匹配,具体为:步骤s401:基于kuhn-munkres算法计算二部带权图g的最大权匹配,得到matching。步骤s5:根据最大权匹配生成跨社交网络虚拟用户对齐结果,具体包括以下步骤:步骤s501:从matching删除权重小于α的边,α取0.75。步骤s502:任取edge∈matching,获得edge的两个端点node1与node2,获取node1在社交网络1中对应的虚拟用户user1,获取node2在社交网络2中对应的虚拟用户user2,将user1与user2作为一对被对齐的虚拟用户。图3为由图g的最大权匹配matching生成最终对齐结果的过程示意图。1_usera、1_userb、1_userc为社交网络1待匹配用户,2_usera、2_userb、2_userc为社交网络2待匹配用户,在此二部图中,最大权匹配为{(1_usera,2_userc,权重0.7),(1_userb,2_usera,权重1),(1_userc,2_userb,权重1)},由于边(1_usera,2_userc)的权重小于α,因此从最大权匹配中删除此边得到边集{(1_userb,2_usera),(1_userc,2_userb)}。最终的身份对齐结果为社交网络1中的用户1_userb与社交网络2中的用户2_usera对齐,1_userc与2_userb对齐。为了检验在本实施例中本发明所提出的基于时空行为数据的跨社交网络间虚拟用户对齐方法的效果,在数据集上进行了测试,数据集中包括对应于1000个真实用户的1000个微博账号和1000个tweeter账号,对于每个账号,数据集中包含账号在2019年12月的全部指定行为的记录,每一条记录由账号名、行为类型(发布、转发、评论)、时间戳、位置四个字段组成。在数据集的1000个tweeter账号与1000个微博账号间进行对齐,以1000个志愿的真实身份作为标记,使用查准率precision和召回率recall两个指标来评价身份对齐的效果。precision等于正确对齐的账号对的数目与算法输出的对齐节账号对数目的比值,recall等于正确对齐的账号对数目与全部真实账号对的数(1000)的比值。测试集的precision值为95.5%,recall为79.3%,对齐算法在测试数据集上的具体实验结果如表1所示。表1为算法在测试数据集上的实验结果。真实用户对数量1000对算法输出对齐用户对数量830对正确对齐的用户对数量793对precision793/830=95.5%recall793/1000=79.3%该实验结果表明本发明所提出的基于时空行为数据的与二部图最大权匹配的跨社交网络间虚拟用户对齐算法,能够为全方位分析用户在社交网络中扮演的角色、准确估计用户真实属性提供重要理论基础与技术支撑,进而满足提升推荐系统推荐精度、增加企业利润的商业需求,所需要数据在现实社交网络中易于获取,计算过程易于通过分布式框架进行,可以在大规模复杂网络中快速做到虚拟用户身份精准对齐。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1