一种基于Avro的结构化数据序列化传输方法及装置与流程
本发明涉及计算机容灾备份技术领域,特别是涉及一种基于avro的结构化数据序列化传输方法及装置。
背景技术:
序列化是将数据对象状态转换为可存储或传输的格式的过程,与序列化相反的是饭序列化,它将流转换为数据对象,这两个过程结合起来,可以轻松地存储和传输数据。
目前,数据导出程序将从源端数据库导出的数据按照一定格式序列化,再将序列化结果传递到数据装载程序,装载程序将收到的数据块反序列化,得到原始数据并装载到备端数据库,是数据库备份的主要流程。数据序列化和反序列化是否高效,序列化后的数据体积是否足够小,直接影响着数据库备份的性能。
传统的数据序列化方法主要有json和xml,其中xml因为序列化效率不高,并且有冗长的描述性字段在追求高性能的场合已经被弃用,json采用键值对的方式保存数据,跟xml比较在数据的冗余度、以及序列化的速度上都有了长足的进步,是现在主流的数据序列化方法。
但是,json在处理数据表的数据时有着很多缺点:一、json采用键值对的方式保存数据,这样在数据表的数据有很多行的时候,会保存很多重复的数据列名;二、json不能直接保存二进制数据,如果需要在json中保存二进制数据,通常需要将其先base64编码以后再转成16进制可打印字符,这就需要额外的序列化时间,也使序列化结果数据的体积变得更大;三、json的序列化和反序列化性能也不够出色。
目前,另外一种流行的序列和反序列化方法是google的protobuf。它是一种二进制的消息流,具有跨平台、解析速度快、序列化数据体积小、扩展性高等特点。但是,protobuf的二进制消息流不具有自描述特性,这导致它序列化的数据不能被装载程序很方便的反序列化,使用protobuf序列化、反序列化数据需要提前为数据库的每一张表定制一个proto结构描述文件并部署到源备两端,由于数据库备份的时候通常会备份很多数据表,而每个数据表的结构一般不能提前预知,这导致提前部署proto文件很麻烦,使用protobuf就受到很大限制。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于avro的结构化数据序列化传输方法及装置,以实现序列化速度快、序列化结果体积小、序列化结果自描述的目的。
为达上述目的,本发明提出一种基于avro的结构化数据序列化传输方法,包括:
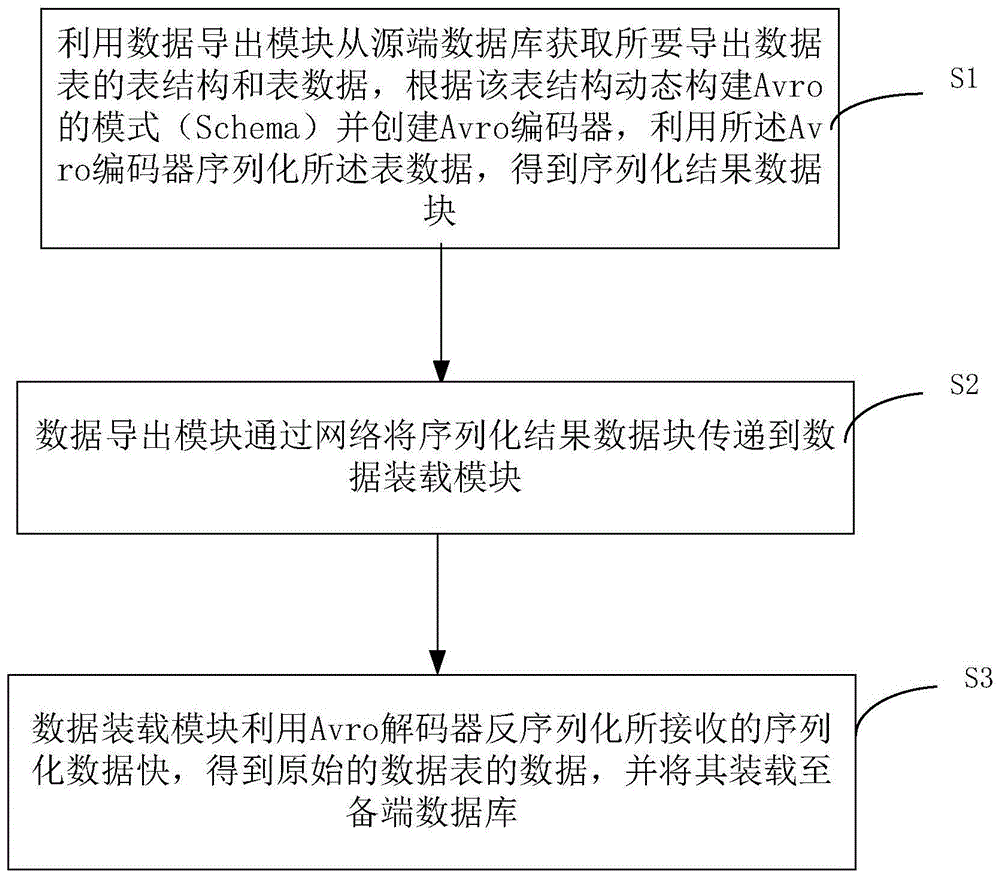
步骤s1,利用数据导出模块从源端数据库获取所要导出数据表的表结构和表数据,根据该表结构动态构建avro的schema并创建avro编码器,利用所述avro编码器序列化所述表数据,得到序列化结果数据块;
步骤s2,所述数据导出模块通过网络将所述序列化结果数据块传递到数据装载模块;
步骤s3,所述数据装载模块利用avro解码器反序列化所接收的序列化数据快,得到原始的数据表数据,并将其装载至备端数据库。
优选地,步骤s1进一步包括:
步骤s100,从源端数据库获取所要导出的数据表的表结构;
步骤s101,根据获得的数据表的表结构动态构建一个avro的schema;
步骤s102,根据动态构建的schema创建avro编码器;
步骤s103,所述数据导出模块从源端数据库读取表数据,利用所述avro编码器将所述数据表数据处理成序列化结果数据块。
优选地,于步骤s2中,于创建avro编码器同时,在字节缓冲区中创建一个带schema的avro数据头。
优选地,于步骤s103中,所述数据导出模块从源端数据库读取表数据,按行插入avro编码器,所述avro编码器以流的方式将序列化的数据写入字节缓冲区,当该数据表的所有行都读取完成或者读取超过了一定行数,关闭所述avro编码器,得到内嵌所述schema的序列化结果数据块。
优选地,于步骤s103中,avro序列化后的数据按行存放。
优选地,于步骤s103中,所述avro编码器对不同avro类型写入数据块的处理如下:
对于boolean、int、long、float、double的avro类型,在所述序列化结果数据块中将直接存放,占用固定的数据类型长度;
对于string、bytes的变长的avro类型,在所述序列化结果数据块中先存放字节流或者二进制流的长度,再放置原始的字节流或者二进制流;
对于avro的逻辑类型,将它们转换成bytes类型处置,以节约存储空间;
对于允许null值的union类型,先存放一个union的index值,再按照实际的类型存储。
优选地,于步骤s1中,获取的表结构包括但不限于表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
优选地,于步骤s101中,以所述数据表的表名作为所述schema的名称,所述数据表的每一列对应所述schema内的一个field,列名为field的名称,并在数据列的类型和schemafield的类型之间建立映射关系。
优选地,所述数据导出模块与所述数据装载模块通过jdbc接口从源端数据库读取、向备端数据库装载数据。
为达到上述目的,本发明还提供一种基于avro的结构化数据序列化传输装置,包括:
数据导出模块,用于从源端数据库获取所要导出数据表的表结构和表数据,根据该表结构动态构建avro的模式schema并创建avro编码器,利用所述avro编码器序列化所述表数据,得到序列化结果数据块,并将得到的序列化结果数据块通过网络传递至数据装载模块;
数据装载模块,用于利用avro解码器反序列化所接收的序列化数据快,得到原始的数据表的数据,并将其装载至备端数据库。
与现有技术相比,本发明具有如下有益效果:
1、本发明中,每一个数据块只在数据头的schema信息里保存了数据列的名称信息,这在数据表有很多行数据的情况下,不需要像json一样保存很多份冗余的数据列名称信息。
2、本发明中,二进制数据是直接保存的,省去了转换的时间开销,也使序列化的结果体积更小。
3、本发明中,每张数据表序列化的schema都是根据表结构动态生成的,具有使用简单的优点。
附图说明
图1为本发明一种基于avro的结构化数据序列化传输方法的步骤流程图;
图2为本发明具体实施例中动态生成的schema示例图;
图3为本发明具体实施例中序列化得到的数据块格式示意图;
图4为本发明一种基于avro的结构化数据序列化传输装置的系统架构图;
图5为本发明实施例中基于avro的结构化数据序列化传输装置的示意图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种基于avro的结构化数据序列化传输方法的步骤流程图。如图1所示,本发明一种基于avro的结构化数据序列化传输方法,包括:
步骤s1,利用数据导出模块从源端数据库获取所要导出数据表的表结构和表数据,根据该表结构动态构建avro的模式(schema)并创建avro编码器,利用所述avro编码器序列化所述表数据,得到序列化结果数据块。
avro是hadoop的一个数据序列化系统,设计用于支持大批量数据交换的应用。avro依赖模式(schema)来实现数据结构定义。可以把模式理解为java的类,它定义每个实例的结构,可以包含哪些属性,avro支持两种序列化编码方式:二进制编码和json编码。由于avro技术为现有技术,在此不予赘述。
具体地,步骤s1进一步包括:
步骤s100,利用数据导出模块从源端数据库获取所要导出的数据表的表结构,包括表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
具体地说,在导出某张数据表的时候,先利用数据导出模块通过jdbc接口从源端数据库获取该数据表的结构,包括表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
步骤s101,所述数据导出模块根据获得的数据表的表结构动态构建一个avro的模式(schema)。在本发明具体实施例中,以数据表的表名作为schema的名称,表的每一列对应schema内的一个field,列名为field的名称,动态创建schema需要在数据列的类型和schemafield的类型之间建立映射关系,具体映射关系如下:
数据列类型为char、varchar、nchar、nvarchar、clob、longvarchar、nclob、longnvarchar等字符串兼容的类型时,映射为avro的string类型;
数据列类型为blob、binary、varbinary、longvarbinary等二进制类型时,映射为avro的bytes类型;
数据列类型为bit、boolean等类型时,映射为avro的boolaen类型;
数据列类型为tinyint、smallint、integer等类型时,映射为avro的int类型;
数据列类型为bigint时,映射为avro的long类型;
数据列类型为real、float等类型时,映射为avro的float类型;
数据列类型为double时,映射为avro的double类型;
数据列类型为带精度的numeric、decimal类型时,映射为avro逻辑类型的decimal类型;
数据列类型为date时,映射为avro逻辑类型中的date类型;
数据列类型为timestamp时,映射为avro逻辑类型中的timestamp-micros类型;
数据列类型为其它类型时,映射为avro逻辑类型中的string类型。数据导出模块在导出这些类型的列的时候先将列数据转换成字符串格式。
另外,如果数据列允许null值,需要将avro的类型设置为原始类型和null的union。
图2为本发明实施例中动态生成的schema示例图,在图2中,其映射关系如下:
列int_col映射到int类型,不允许出现null值。
列bigint_col映射到long类型,不允许出现null值。
列double_col映射到double类型,允许出现null值。
列boolaen_col映射到boolean类型,不允许出现null值。
列char_col映射到string类型,不允许出现null值。
列varchar_col映射到string类型,允许出现null值。
列clob_col映射到string类型,允许出现null值。
列date_col映射到逻辑类型中的date类型,允许出现null值。
列timestamp_col映射到逻辑类型中的timestamp-micros类型,允许出现null值。
列decimal_col映射到逻辑类型中的decimal类型,精度为11,scale为4,允许出现null值。
列blob_col映射到bytes类型,允许出现null值。
步骤s102,所述数据导出模块根据动态构建的schema创建avro编码器。于步骤s102中,在字节缓冲区中创建一个带schema的avro数据头。
步骤s103,所述数据导出模块从源端数据库读取表数据,按行插入avro编码器,所述avro编码器以流的方式将序列化的数据写入字节缓冲区。最终的序列化结果将包含该schema,这样,avro序列化的消息流就与xml或json消息流一样具有了自描述的特点,可以被数据装载模块解析使用。当该数据表的所有行都读取完成或者读取超过了一定行数,关闭所述avro编码器,则可以得到一个内嵌了schema的数据块。
在本发明具体实施例中,avro序列化后的数据按行存放,最终数据块的格式如图3所示,在本发明具体实施例中,所述avro编码器对不同avro类型写入数据块的处理如下:
对于简单的avro类型如boolean、int、long、float、double,在序列化结果数据块中将直接存放,占用固定的数据类型长度,例如boolean一个字节,int四个字节,long八个字节等;
对于变长的avro类型如string、bytes,在序列化结果数据块中先存放字节流或者二进制流的长度,再放置原始的字节流或者二进制流,如写入数据块的时候先写4字节长度,再写后续的字符或者二进制数据;
对于avro的逻辑类型,将它们转换成bytes类型处置,以节约存储空间;
对于允许null值的union类型,先存放一个union的index值,再按照实际的类型存储。比如某列的数据为null,只需要存放index值0。如果该列有数据,比如为整数100,会先存放index值1,再存放实际的数据100。
步骤s2,数据导出模块通过网络将序列化结果数据块传递到数据装载模块。
步骤s3,数据装载模块利用avro解码器反序列化所接收的序列化数据快,得到原始的数据表的数据,并将其装载至备端数据库。
具体地,步骤s3进一步包括:
步骤s300,数据装载模块利用avro解码器反序列化接收到的序列化结果数据块,得到原始的数据表数据。因为该序列化结果数据块内嵌了schema,所以数据装载模块不需要额外的信息就可以完成反序列化,得到原始的数据表的数据,即获得的每个数据块都包含头部和数据部两部分,头部内嵌了schema,avro解码器则从头部读取到schema,再根据此schema反序列化数据部得到原始的数据表数据。
步骤s301,数据装载模块通过jdbc接口将得到的原始的数据表数据装载到备端数据库。
在本发明中,每一个数据块只在数据头的schema信息里保存了数据列的名称信息,这在数据表有很多行数据的情况下,不需要像json一样保存很多份冗余的数据列名称信息;本发明中,二进制数据是直接保存的,省去了转换的时间开销,也使序列化的结果体积更小;另外,本发明的每个数据表序列化的schema都是根据表结构动态生成的,具有使用简单的优点。
图4为本发明一种基于avro的结构化数据序列化传输装置的结构示意图。如图4所示,本发明一种基于avro的结构化数据序列化传输装置,包括:
数据导出模块40,用于从源端数据库获取所要导出数据表的表结构和表数据,根据该表结构动态构建avro的模式(schema)并创建avro编码器,利用所述avro编码器序列化所述表数据,得到序列化结果数据块,并将得到的序列化结果数据块通过网络传递至数据装载模块41。
具体地,数据导出模块40进一步包括:
表结构导出单元401,用于从源端数据库获取所要导出的数据表的表结构,包括表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
具体地说,在导出某张数据表的时候,表结构导出单元401先通过jdbc接口从源端数据库获取该数据表的结构,包括表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
模式创建单元402,用于根据获得的数据表的表结构动态构建一个avro的模式(schema)。在本发明具体实施例中,以数据表的表名作为schema的名称,表的每一列对应schema内的一个field,列名为field的名称,动态创建schema需要在数据列的类型和schemafield的类型之间建立映射关系,具体映射关系如下:
数据列类型为char、varchar、nchar、nvarchar、clob、longvarchar、nclob、longnvarchar等字符串兼容的类型时,映射为avro的string类型;
数据列类型为blob、binary、varbinary、longvarbinary等二进制类型时,映射为avro的bytes类型;
数据列类型为bit、boolean等类型时,映射为avro的boolaen类型;
数据列类型为tinyint、smallint、integer等类型时,映射为avro的int类型;
数据列类型为bigint时,映射为avro的long类型;
数据列类型为real、float等类型时,映射为avro的float类型;
数据列类型为double时,映射为avro的double类型;
数据列类型为带精度的numeric、decimal类型时,映射为avro逻辑类型的decimal类型;
数据列类型为date时,映射为avro逻辑类型中的date类型;
数据列类型为timestamp时,映射为avro逻辑类型中的timestamp-micros类型;
数据列类型为其它类型时,映射为avro逻辑类型中的string类型。数据导出模块在导出这些类型的列的时候先将列数据转换成字符串格式。
另外,如果数据列允许null值,需要将avro的类型设置为原始类型和null的union。
avro编码器创建单元403,用于根据动态构建的schema创建avro编码器。avro编码器创建单元403还会在字节缓冲区中创建一个带schema的avro数据头。
序列化单元404,用于从源端数据库读取表数据,按行插入avro编码器,所述avro编码器以流的方式将序列化的数据写入字节缓冲区。序列化单元404最终的序列化结果将包含该schema,这样,avro序列化的消息流就与xml或json消息流一样具有了自描述的特点,可以被数据装载模块解析使用。当该数据表的所有行都读取完成或者读取超过了一定行数,关闭所述avro编码器,则序列化单元404可以得到一个内嵌了schema的数据块,并通过网络将序列化结果数据块传递到数据装载模块41。
数据装载模块41,用于利用avro解码器反序列化所接收的序列化数据快,得到原始的数据表的数据,并将其装载至备端数据库。
具体地,数据装载模块41进一步包括:
反序列化单元410,用于利用avro解码器反序列化接收到的序列化结果数据块,得到原始的数据表数据。因为该序列化结果数据块内嵌了schema,所以数据装载模块不需要额外的信息就可以完成反序列化,得到原始的数据表的数据。
装载单元411,用于通过jdbc接口将得到的原始的数据表数据装载到备端数据库。
实施例
图5为本发明实施例中基于avro的结构化数据序列化传输装置的示意图。如图5所示,本发明基于avro的结构化数据序列化传输过程如下:
步骤1,数据导出模块通过jdbc接口从源数据库获取数据表的结构,包括表名和列名以及每一列的具体数据类型以及是否允许出现null值等信息。
步骤2,数据导出模块根据表结构动态的构建一个schema。以表名作为schema的名称,表的每一列对应schema内的一个field,列名为field的名称。在列的类型和schemafield的类型之间建立映射关系。
步骤3,数据导出模块根据此动态schema创建avro编码器。这个步骤将在字节缓冲区中创建一个带schema的avro数据头。
步骤4,数据导出模块通过jdbc接口从源数据库读取表数据,按行插入avro编码器。avro编码器以流的方式将序列化过的数据写入字节缓冲区。当此数据表的所有行都读取完成或者读取超过了一定行数,关闭编码器,就可以得到一个内嵌了schema的数据块。
步骤5,数据导出模块通过网络将数据块传递到数据装载程序。
步骤6,数据装载模块用avro解码器反序列化收到的数据块。因为数据块内嵌了schema,所以数据装载模块不需要额外的信息就可以完成反序列化,得到原始的数据表的数据。
步骤7,数据装载模块通过jdbc接口将数据装载到备端数据库。
步骤8,如果源数据表的数据还没有完全导出,返回步骤3。
步骤9,如果源数据库还有数据表需要导出,返回步骤1。
根据本发明实施例,序列化的结果通常只有json序列化结果的一半大小,序列化时间和反序列化时间也只有json的一半左右。
综上所述,本发明一种基于avro的结构化数据序列化传输装置通过利用数据导出模块从源端数据库获取所要导出数据表的表结构和表数据,根据该表结构动态构建avro的schema并创建avro编码器,利用所述avro编码器序列化所述表数据,得到序列化结果数据块传递到数据装载模块,由所述数据装载模块利用avro解码器反序列化所接收的序列化数据快,得到原始的数据表数据,并将其装载至备端数据库,本发明具有序列化速度快、序列化结果体积小、序列化结果自描述、使用简单等优点。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!