一种基于人体骨架时空关系的行为识别方法与流程
本发明涉及计算机视觉技术领域,具体涉及一种基于人体骨架时空关系的行为识别方法。
背景技术:
行为识别是将所给定的视频片段中人的行为类别识别出来,它当前计算机视觉领域中的一个重要研究方向。由于基于视频原始图像的行为识别方法在较多场合易受到光线、遮挡和距离等问题干扰的因素,使用从视频中提取出的骨架信息作为行为识别原始数据的研究越来越多。基于人体骨架的行为识别方法更具有鲁棒性,能在行为识别中获得较高的识别率。
基于人体骨架的行为识别可分为两大类:基于传统方法的行为识别与基于深度学习的行为识别。其中基于传统方法的行为识别使用人工设计的算法提取视频中的行为特征,依赖于先验知识;基于深度学习的方法在构造网络后,网络可自动学习对识别有益的图像特征,但对计算和存储能力要求高。由于当前计算能力与存储能力的高速发展,使用基于深度学习的行为识别方法一般可表现出优于传统行为识别的效果。
基于深度学习的行为识别方法在针对性上也可进行分类,即针对图像特征的方法、针对时序特征的方法与针对结构特征的方法。针对图像特征的方法常使用卷积神经网络及其变形网络,针对时序特征的方法常使用循环神经网络及其变形网络,针对结构特征的方法常使用图神经网络及其变形。但针对单一特征的方法难以充分捕捉人体骨架的时空关系,特别是对于行为来说,由于行为不仅是在空间中人体关节位置的相对关系,也是在不同时间点关节位置的变化。使用多种特征结合来进行行为识别能更充分地利用人体骨架在行为过程中的时空关系信息,从而提高识别的准确性。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于人体骨架时空关系的行为识别方法,解决现有行为识别方法难以充分利用人体在行为动作中时空关系,识别的准确率不高的问题。
本发明解决上述技术问题采用的技术方案是:
一种基于人体骨架时空关系的行为识别方法,包括以下步骤:
s1、对人体骨架序列进行均匀分段处理;
s2、对每段人体骨架信息生成基于距离的图像表达;
s3、采用带权多视角卷积方法对每段人体骨架信息的图像表达进行短时空特征提取;
s4、采用具有时序关系的多个短时空特征作为bi-lstm模型的输入,提取人体骨架序列的整体时空关系并进行行为识别。
作为进一步优化,步骤s1具体包括:
s11、以原始人体骨架序列作为输入,确定均匀分段的段数l以及每段短序列中包含的帧数k,根据原始人体骨架序列包含的帧数x和l×k的大小关系对原始人体骨架序列进行采样或扩充处理,使得处理后的人体骨架序列长度为l×k;
s12、对处理后得到的长度为l×k的人体骨架序列,以长度k为单位进行均匀分段,获得l段短序列。
作为进一步优化,步骤s11中,所述根据原始人体骨架序列包含的帧数x和l×k的大小关系对原始人体骨架序列进行采样或扩充处理,具体包括:
s111、若x>l×k,则对原始人体骨架序列进行顺序随机取帧至l×k帧,然后对所取的l×k帧数据进行合并,进入步骤s12;
s112、若x<l×k,则对原始人体骨架序列进行中的各帧进行复制,使得经过复制处理后的序列长度大于或等于l×k,若等于l×k,则进入步骤s12,若大于l×k,则进行顺序随机取帧至l×k帧,然后对所取的l×k帧数据进行合并,进入步骤s12;
s113、若x=l×k,则进入步骤s12。
作为进一步优化,步骤s2具体包括:
s21、对于划分的短序列中每一帧的骨架数据,分别进行部位划分,将其划分为j个部位;
s22、对于划分的短序列中每一帧骨架数据,计算各个部位中心点的位置:
其中,
s23、对于划分的短序列中每一帧骨架数据,计算各个部位中的关节点与中心点的距离:
其中,d为m通道中,该部位关节点与中心点的距离;
s24、对于划分的短序列中每一帧骨架数据,将其对应表达为包含中心点位置以及关节点与中心点距离的向量:
其中,
s25、对于划分的短序列,将其中每一帧骨架数据所得到的向量表达按时序顺序拼接;
s26、将拼接后的向量表达进行归一化处理;
s27、根据归一化后的向量获得每个短时序骨架数据的图形表达p:
p=[p1,p2,...,pm],
作为进一步优化,步骤s3具体包括:
针对每个短时序骨架的图形表达p,采用针对行为特征提取的带权多视角卷积进行特征提取,得到该短时序骨架的时空特征:
fr-mv=a*s1(x)+b*s2(x)+c*s3(x)+x
其中x代表本层输入,在第一层时,该输入为p,s1、s2、s3分别对应三个视角的卷积操作,a、b、c分别对应三个视角卷积的结果在输出中所占的重要性,s1、s2、s3与a、b、c具体数值均由网络学习得到。
作为进一步优化,步骤s4具体包括:
s41、将多段短时序骨架时空特征作为bi-lstm网络的输入,以得到最终长时序骨架时空特征f;
s42、将长时序骨架时空特征f作为全连接层和softmax层的输入,得到最终各类得分;
s43、通过选取最高分类别的方式得到识别结果。
本发明的有益效果是:
通过将人体骨架数据进行基于图像的生成,可将图像任务中的知识有效地迁移到使用骨架数据进行行为识别的领域,有利于模型的训练及最终效果的提升;使用针对行为特征的带权多视角卷积可从多个角度对行为进行描述,将所得短时序行为特征作为输入,使用双向lstm可将不同时间点的行为联系起来,有效实现对行为时空关系的提取,提升识别准确率。
附图说明
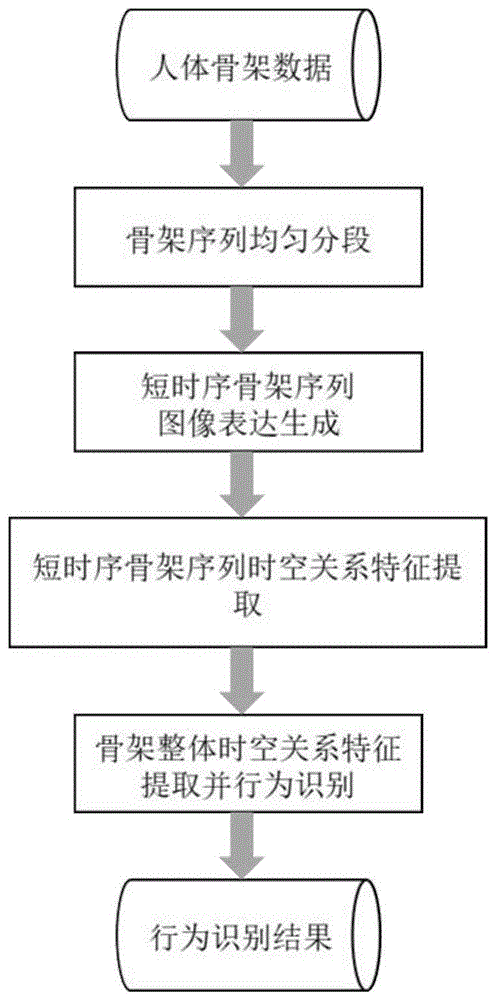
图1为本发明识别方法的流程图;
图2为带权多视角卷积示意图;
图3为带残差思想的带权多卷积示意图;
图4为分层特征提取示意图。
具体实施方式
本发明旨在提出一种基于人体骨架时空关系的行为识别方法,解决现有行为识别方法难以充分利用人体在行为动作中时空关系,识别的准确率不高的问题。其核心思想是:将人体骨架序列进行分段后,进行基于距离的图像表达生成,然后使用带权多视角卷积方法对每个人体骨架信息的图像表达进行短时空特征提取,并使用具有时序关系的多个短时空特征作为bi-lstm模型的输入,提取人体骨架序列的整体时空关系并进行行为识别,本发明正是基于对人体行为时序特性进行的“短时序-长时序”分层特征提取能提高行为识别的准确率。
下面结合附图对本发明的方案作进一步的描述。
如图1所示,本发明中的基于人体骨架时空关系的行为识别方法包括以下步骤:
s1、人体骨架序列均匀分段处理:
本步骤中,以视频中原始人体骨架序列作为此阶段的输入,进行均匀分段,具体包括:
s11:确定均匀分段段数l、每段中包含的帧数k。对于含有x帧数据的骨架数据:
若x>l×k,跳至s12;
若x<l×k,跳至s13;
若x=l×k,跳至s14;
s12:对长度为x的骨架数据进行顺序随机取帧至l×k帧,其中随机取帧方法具体包括::
(1)对于x,从1~x中按顺序随机取l×k个数,如:x=10,l×k=6,随机取数为[1,2,4,7,9,10];
(2)从长度为x的骨架数据中,按(1)中随机所得数取帧,如随机取数为[1,2,4,7,9,10],则取长度为x的骨架数据中的第1帧、第2帧、第4帧、第7帧、第9帧和第10帧。
(3)将所取的骨架数据进行合并,得到长度为l×k帧的骨架数据,进入s14;
s13:对长度为x的骨架数据以复制填充的方式,填充至l×k帧,具体方法包括:
(1)对于x,计算
(2)将长度为x的骨架数据中的每一帧,复制d-1次,如原始帧为[1,2,3,4],d=2,则原始帧经过复制后变为[1,1,2,2,3,3,4,4];
(3)若l×k%x=0,%表示取余,则跳至s14;
(4)若l×k%x≠0,如7%4=3≠0,此时复制后的帧长度为8≠l×k。此时,从复制后的帧长度xˊ中,随机取l×k个数,如随机取数为[1,2,3,4,6,7,8];
(5)取长度为xˊ的骨架数据中的第1帧、第2帧、第4帧、第6帧、第7帧和第8帧数据;
(6)将所取的骨架数据进行合并,得到长度为l×k帧的骨架数据,进入s14;
s14:对长度为l×k的骨架数据,以长度为k进行均匀分段,得到l段短时序骨架数据。
s2、对每段人体骨架信息生成基于距离的图像表达:
本步骤中,使用基于人体关节距离的图像表达生成方法,对切分后的短时序骨架序,进行图像表达生成,具体步骤包括:
s21:对于短时序骨架序列中每一帧的骨架数据,分别进行部位划分,将其划分为j个部位,如可划分为左手、右手、头部、躯干、左腿和右腿六个区域,对于每个部位,分别包括的关节点个数为n1,n2,…,nj;
s22:对于每一帧骨架数据,计算每个部位中心点在每个维度的位置,中心点位置计算方法如下式所示;
其中短时序整体骨架表示为s,
s23:对于每一帧骨架数据,计算各个部位关节点与中心点的距离,如下式所示;
其中
s24:对于每一帧骨架数据,将其对应表达为包含中心点位置与关节与中心点距离的向量,矩阵中的
s25:对于每一段短时序骨架序列,将其中每一帧骨架数据所得到的向量表达按时序顺序拼接,当单个骨架关节点个数为n时,得到v×(n+j)×k大小的表达,v为维度数;
s26:对于得到的v×(n+j)×k向量表达,将其归一化至[0,255]区间,使其能表达为图像形式,归一化方法如下式:
其中a为被归一化的值,min为0,max为255。
s27:最后对每个短时序骨架数据得到一个大小为v×(n+j)×k的表达p。
p=[p1,p2,…,pm],m={1,2,…,v}
s3、获取每段短时序骨架的时空关系特征:
本步骤中,使用针对行为特征提取的带权多视角卷积,对短时序骨架的图像表达p进行特征提取,得到短时序骨架序列的行为时空关系特征fr-mv,具体步骤包括:
s31:将得到的短时序骨架数据图像表达作为输入,对每个图像表达p,使用针对行为特征提取的带权多视角卷积进行特征提取,带权多视角卷积如图2所示,其输出表示为:
fmv=a*s1(x)+b*s2(x)+c*s3(x)
其中,x为该带权多视角卷积的输入,在第一层时,该输入为p。fmv是卷积的输出,s1、s2、s3分别对应三个视角的卷积操作,a、b、c分别对应三个视角卷积的结果在输出中所占的重要性,其中s1、s2、s3与a、b、c具体数值均由网络学习得到。
s32:在使用多视角卷积的卷积层中加入残差的恒等映射,如图3所示,使用带权多视角卷积的残差块的输出为:
fr-mv=a*s1(x)+b*s2(x)+c*s3(x)+x
其中x代表本层输入,f在x已经是足够表达行为特征时不做改变,依旧为x本身。fr-mv为经过使用带权多视角卷积块的输出。
s4、在得到短时序骨架时空特征的基础上,获取行为识别结果:
本步骤中,将多段短时序骨架时空特征作为输入,使用bi-lstm对具有时序关系的短时序骨架的时空关系特征进行整体特征提取,并进行行为识别,最后得到行为识别结果,如图4所示,具体步骤包括:
s41:将多段短时序骨架时空特征作为bi-lstm网络的输入,得到最终长时序骨架时空特征f;
s42:将长时序骨架时空特征f作为全连接层和softmax层的输入,得到最终各类得分;
s43:通过选取最高分类别的方式得到识别结果。
- 还没有人留言评论。精彩留言会获得点赞!