基于机器学习的中小学数学能力点缺陷极小样本高精度发现方法与流程
本发明涉及数学能力缺陷点检测
技术领域:
,具体涉及基于机器学习的中小学数学能力点缺陷极小样本高精度检测方法。
背景技术:
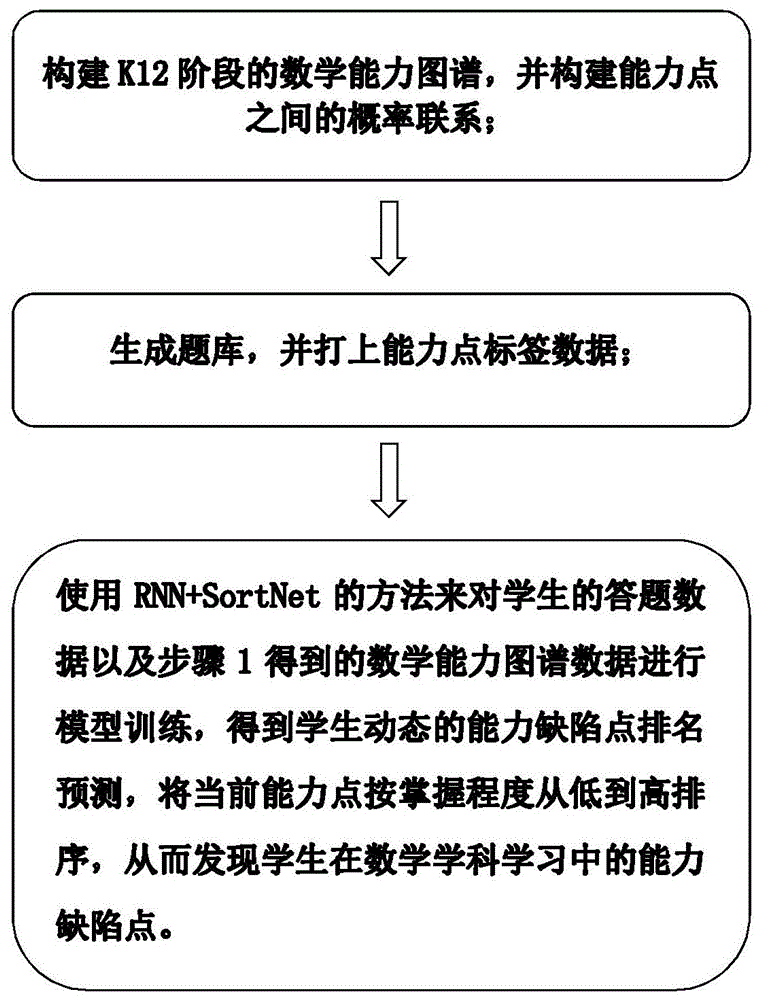
:数学学科在中小学生学习中占有非常重要的基础性地位,甚至可以说直接决定了一名学生的综合学习能力和考试成绩的高低,因而受到学校、老师、家长和学生的广泛重视。另一方面,数学也是学生普遍反映较难的科目,知识点较为抽象和多变,相同知识点有很多种呈现形式和难度值,教师和学生均不易加以变通、总结和归纳。导致虽然从小学一年级到高中三年级(以下简称k12阶段),绝大多数学生在数学学科耗费了大量的时间与精力,反复进行大量练习甚至课外补习,收效却不明显。因为无法抓住真正薄弱的知识点(后文称为缺陷点)进行个性化的重点突破,只能是万人一面做大量重复学习,不仅浪费时间,还挫伤了学习积极性与信心。所以准确捕捉学生在数学学科学习中的知识缺陷点不仅可以有效提升学习效率、成绩,而且是个性化学习和兴趣导向学习的基础。传统学习情境下,有针对性的查漏补缺只能存在于非常有经验的教师组织的小班或1对1(1v1)教学场景,成本高昂,而且由于名师远远供不应求,只能牺牲教育的公平性和普惠性来满足少数城市和富裕家庭的需求,对于数学这一关乎未来国民整体科技素养的基础学科而言,与我国义务教育的宗旨背道而驰。随着近二十年来人工智能特别是其中机器学习算法的爆发式发展,从技术角度首次具备了全民“因材施教”、“千人千面”和兴趣驱动学习的可能性。蓬勃发展的在线教学和电子化学习、考试开始让学习数据线上化和结构化,从而形成可被算法理解和重构的“学习大数据”,让精细化和个性化学习成为可能。并且,由于数学学科的标准化和结构化特点,是特别适合通过大数据和机器学习算法来辅助学习的学科,所以本发明选择数学作为学科突破口,并保留对其他k12学科的延展可能性。在此,本发明须重点解决的问题是:如何仅利用少量学习反馈数据(极少样本量),高精度(高准确率和召回率)地定位学生在数学学科中的能力缺陷点。为了更好介绍本发明对前沿机器学习方法的优化和创新,以及如何更好的应用于本发明的目标问题,首先概要介绍相关技术背景,特别是其中涉及的机器学习算法。a.最细粒度知识图谱构建(knowledgegraph)通常的方法是首先根据专业知识构建离散的知识点集合以及先后顺序关系。再运用自然语言处理(nlp)特别是命名体识别(ner)技术来抽取普通学习文本中的核心概念,从而进一步发掘知识点间的概率联系。能力点间的概率关系可以通过题目和能力节点构成的二分网络图上的随机漫步方法来迭代计算和不断优化。b.排序学习(learningtorank)和时序神经网络(rnn)很多机器学习问题的目标都可以抽象为排序问题,从搜索到推荐再到自动问答系统,本质上都是给定二元组的数据列表,按照某种标准(通常是两者相关性)对这组列表进行排序。排序学习在处理这类问题的优势在于目标函数与目标的一致性,也即我们只关心相对顺序而并不关心具体的数值,换句话说排序学习能够产生相对其他方法更准确的顺序排列。而学生知识薄弱环节的定位正可以看成一个按掌握度从弱到强的排序问题。同时因为学生的学习具有连续性和难以逆转的特征,将对同单个学生的动态模型预测看成一个有机的时序整体会有助于提高模型的准确性和稳定性,同时缓解数据的稀疏性。所以我们融合了深度学习中的时序神经网络(rnn)模型来对连续多次测试数据进行建模,并融合排序学习模型形成一个统一的新模型,实验表明,新模型效果相对传统模型更准确。术语解释项目反应理论(irt),自适应学习,深度学习(deeplearning),知识图谱(knowledgegraph)和能力图谱(abilitygraph),深度能力跟踪(deepknowledgetracing),极小样本学习(few-shotlearning),排序学习(learningtorank),排序网络(sortnet),时序神经网络(rnn),排序效果评估指标ndcg。1现有技术的技术方案“修复理论”主张最好的帮助孩子提高的方法是依靠理解他们犯错误的根源性原因(brown&venlehn,1980)。当然,定位错误根源的前提条件是我们对易犯的错误点有清晰而准确的分类(能力图谱),如(feldmanetal.2018)文献中所定义的那样。遗憾的是,在本文之前尚未有关于k12阶段数学能力的精确能力图谱,要求是图谱内的节点具有不可再分性,也就是“原子级别”的知识点,这也是我们要解决的首要问题。下文介绍的其他方法都基于比较粗粒度的能力点。与一般产品缺陷点的检测不同,学生能力缺陷点既不可见也难以准确定量描述,并且处于动态变化的过程中。另一方面,由于知识点的内在关联性,缺陷点之间往往是关联的,这其实给我们相对准确定位提供了极大的便利。这也是我们提出的方法核心创新之处。以下是一些代表性的方法,篇幅关系,我们将重点介绍代表性的irt模型和dkt模型。a.教师人工分析b.问题规则库方法(buggyrules)(selent&heffeman,2014)c.itemresponsetheory(irt,项目反应理论)&multi-dimensionalitemresponsetheroy(mirt)d.beyesianknowldegetracing(bkt)e.deepknowledgetracing(dkt)irt模型的功能是预测一名学生答对某道题目的概率,使用了经典的logistic回归的方法(假定回答正确的概率符合正态分布)。bayesianknowledgetracing(bkt)和deepknowledgetracing(dkt,piech&bassen,etc.,2015)。bkt将学生回答问题的结果看成时间序列,并通过贝叶斯模型(beyesianmodel)去拟合时序关系,dkt则更进一步的,利用循环神经网络(rnn)来更准确捕捉通过连续测试反馈的缺陷点之间的时序关联性,并且取得了更好的精度。然而无论是irt及其变种,还是比较新的beyesianknowledgetracing和deepknowledgetracing,都无法很好利用能力图谱及能力点间的概率信息,从而造成数据稀疏和结果不准确。同时,我们首次将融合了时序网络的排序学习(learningtorank)方法运用于k12缺陷点定位和排序问题,能准确的反应学生在能力点上的缺陷度排序情况,从而让后续的个性化学习更有针对性。2现有技术的缺点目前已知的k12数学知识图谱(含商业化系统),普遍存在的问题有两点:1.知识点划分不够细;2.缺乏构建知识点间的联系的自动化方法。然而要想准确定位学生的知识能力缺陷,首要条件是是构建细粒度、互联互通的、与题库打通的能力图谱。能力结构图谱、标签化的题库和学生的回答构成了三层结构化数据,图谱是这个结构的基础和核心。让我们再次回到数学能力缺陷点检测的目标,能力缺陷发现的本质手段是通过测试题来判断,无论是教师人工判断还是机器学习的方法。由于可用数据的模糊性和稀疏性,造成了传统机器模型预测的偏差。所谓数据的模糊性在于,单个题目回答的错误原因可能有很多,有时仅仅是笔误或粗心,即使该题目仅涉及某一细分知识点,无法准确归因于该知识点上的缺陷。不仅如此,通常有测试价值的测试题,往往不只涉及一个知识点,而是多个知识点的综合考察。数据的稀疏性很好理解,无论是学生能够在某个具体知识点上测试的题目数量或者是答错题目的数量,都是很少的。因此有必要研发更为鲁棒和精确的模型来对评测数据中隐含的缺陷和时序关联性进行建模。我们需要注意到目标问题的两个特点。首先是学生在学习数学的时候是循序渐进的,我们只关心当前需要学习的若干能力点(大约100个左右),并且我们最关心的其实是待学习的能力点的相对排序,所以对当前学习能力点按掌握程度进行更准确的排序是能更好解决该问题的目标函数,也即仅需要考虑能力点和能力点间的相对排序,这属于机器学习中经典的“排序学习(learningtorank)”问题。遗憾的是,目前还没有看到相关的方法运用于k12数学能力缺陷检测。第二个必须关注的特点是,测试题往往不止一道,学生也不会只做一次测试,所以通过多次、每次多道测试题每位学员的反馈形成一个解答序列,类似于其他许多机器学习应用场景,比如用户的搜索序列、商品浏览序列等,只有考虑了每次测试的关联结果,才能更准确定位学生真实的缺陷点以及变化。所以我们提出了一种基于rnn(循环神经网络)+sortnet(深度排序网络),能够处理时序、异构的输入特征,获得更精确排序。综上,目标问题面临的主要挑战主要有两点:1.获得更细粒度和相互关联的k12能力点图谱;2.在数据关联模糊和数据及其稀疏的前提下,如何更好的提高缺陷点预测精度。技术实现要素:本发明的目的是:为了解决现有技术中存在的上述问题,本发明提供一种基于机器学习的中小学数学能力点缺陷极小样本高精度发现方法,主要解决两个挑战:构建最细粒度k12阶段的数学能力图谱;基于极小样本量(3题/能力点)反馈的缺陷点高精度检测算法。为了解决上述问题,本发明所采用的技术方案是:基于机器学习的中小学数学能力点缺陷极小样本高精度发现方法,其特征在于,包括如下步骤:步骤1:构建k12阶段的数学能力图谱,并构建能力点之间的概率联系;步骤2:生成题库,并打上能力点标签数据;步骤3:使用rnn+sortnet的方法来对学生的答题数据以及步骤1得到的数学能力图谱数据进行模型训练,得到学生动态的能力缺陷点排名预测,将当前能力点按掌握程度从低到高排序,从而发现学生在数学学科学习中的能力缺陷点。进一步的,所述步骤1中的构建k12阶段的数学能力图谱,具体步骤是:步骤1.1:通过解析k12阶段的最细粒度的数学能力,获得k12阶段的数学能力图谱,包括若干个能力点;步骤1.2:能力点之间的概率联系构建:给定标注好能力点的题库q={q1,q2,...,qn},使用随机游走方法迭代获得最佳网络概率联接参数。进一步的,所述步骤1.2中的能力点之间的概率联系构建,具体步骤包括:标注好的知识点与题目构成了二分图,即知识点构成了一组节点集合,题目构成了另一组节点集合,有且只有知识点节点和题目节点之间有连接的边,借鉴蚁群信息素+随机游走的方法,采用一种计算二分图节点相似性的方法,来计算原本没有联系的知识点间的概率关联;节点ui代表知识点,vj代表题目,如果题目vj被标注为与ui知识点相关,则ui与vj有边相连;为第t轮迭代,知识点ui带有的信息素种类及浓度;为第t轮迭代,题目vj带有的信息素种类及浓度;初始化阶段,和均为长度为|u|的矢量,|u|即知识点数;通过题目与知识点之间关联的多次传播和迭代,可以得到每个知识点节点上携带的所有其他知识点信息素种类和数量,代表了该知识点与其他知识点的联系及强弱,从而构成一幅带有转移概率联接的知识图谱。进一步的,所述步骤2中的生成题库,并打上能力点标签数据,具体步骤包括:步骤2.1:生成题库:根据互联网上公开的各年度的各年级数学考试真题以及部分用作机器学习的k12题库,经过扫描和数字化之后,获得12个学年段的题库;步骤2.2:对题库中的题全部打上能力点标签数据。进一步的,所述步骤3的发现过程,具体步骤如下:步骤3.1:数据准备和预处理,包括能力点激活预处理和训练和测试数据准备;步骤3.2:模型训练,具体包括:训练过程,预测过程其中q为问题相关的特征集合,qi=[t1,t2,...,tm,qscorei,yi]是模型的输入数据,t为知识点相关的特征集合,tj为表征该题是否涉及知识点j,取值0代表不涉及,1代表涉及,qscorei代表题目的难度值,取值范围(0,1),越大代表题目越难,yi是学生回答的结果,正确为1,错误为0.是用户最近测评的结果,其中ui为最近几次评测的按主题缺陷度排序结果;是预测结果,包含m个待排序主题的向量,其中按掌握程度从低到高排序为:r1<r2<…<rm,是用于训练排序,包含m个待排序主题的向量,其中按掌握程度从低到高排序为:s1=s2=…=sk<sk+1=sk+2=…=sm,被标记为缺陷的k个知识点整体低于其余知识点;对于sortnet网络,正向传播公式为:n>(<x,y>)=σ(∑i,i′wi,>hi(<x,y>)+wi′,>hi′(<x,y>)+b>),(6)对于rnn网络,正向传播公式为:ht=tanh(whxxt+whx′x′t+whhht-1+bh),(7)yt=σ(wyhht+by),(8)sortnet网络接收自变量输入数据,产生结果n>和n<,分别代表输入知识点k(x参数)缺陷值大于和小于知识点p(y参数)的概率,进而又作为rnn网络的输入参数,rnn进行3个周期的序列计算,输出o;o接近1代表k知识点的缺陷度大于知识点p,o接近-1代表k知识点的缺陷度小于知识点p;vxk,i和vyk,i为sortnet层待学习的联接权重,whx和whx′为rnn层待学习的联接权重,分别对应输入的n>和n<,whh为待学习的隐含层联接权重;各网络参数采用标准反向传播方法进行求解;步骤3.3:模型训练流程和模型评价,具体包括:模型训练、预测代码采用python3.0语言实现,其中深度学习模块使用pytorch实现,硬件平台为centos8.0服务器,训练流程如下表所述:模型评价,具体包括:采用通行的衡量排序指标ndcg和recall@5来对比本方法与传统sortnet方法的效果;(1)ndcg指标其中(2)recall@5指标取预测排名靠前的5个知识点,与专家标注的缺陷知识点进行比对,计算如下指标:步骤3.4:实验结果和模型对比,包括:对若干名学生测试数据实验结果分别采用三种方法进行评价,分别为sortnet;本发明方法rnnsortnet1,无激活步骤处理,采用公式1和2;本发明方法rnnsortnet2,有激活步骤处理,采用公式1和3;步骤3.5.将答题数据输入步骤3.4模型对比后的最优模型,得到学生动态的能力缺陷点排序,将能力点按掌握程度从低到高排序,从而发现学生的能力缺陷点;具体包括:完成了模型评测后,再将所有的数据重新进行训练一个完整的模型,得到模型m;对于未出现于训练数据的学生,对其进行若干次测试,每次测试若干道题;将答题数据输入模型,得到学生知识点的薄弱度排序;依据模型排序结果,得出重点需要给该学生推荐的知识点。进一步的,步骤3.1中的能力点激活预处理,具体步骤包括:采用两种不同的知识点权值计算方法:二值权重和概率权重,分别对应于不考虑知识点间联系和考虑知识点间联系;定义第k个能力点分值向量为:定义第i道题目的能力点分值向量为:其中j∈[1,m],m为能力点数量;或公式(2)和(3)的区别是是否考虑了知识图谱的结构信息,公式(2)称为无激活处理,公式(3)称为激活处理,分别对应本方法提出的两种不同的模型rnnsortnet1和rnnsortnet2。进一步的,所述步骤3.2中的训练和测试数据准备,具体步骤包括:采用基于排序对的排序模型,原始训练数据经过排序处理,得到两两对比的排序数据,采用10次交叉验证的方法,将数据的随机1/10留作测试样本,其余作为训练样本,重复训练和测试流程10次并单独记录结果,按照上述处理,得到样本总数。进一步的,步骤3.2中的模型训练,包括:训练样本生成,即:对于每名学生的每次测验,基于测验结果对当前测验进行专家评估,对当前测验试题所涉及的知识点进行缺陷定位,标记薄弱的知识点(0/1取值),标记为薄弱的知识点集合记为ws={t1,t2,...,tw},其余非薄弱知识点集合记为nws={nt1,nt2,...,ntnw},下标s取值为[1,n],n代表总共做的有间隔的测试次数,对于每次测验,生成三元组{tk,ntp,1}或{ntp,tk,-1}(随机选择一种),三元组包含的特征值记为{x1k,x2k,...,x10k,y1p,y2p,...,y10p,oi},其中oi=-1或1(k缺陷度小于或大于p);假设当前计算的是知识点k和p的输入参数,那么第i道题关于知识点k和p的输入值计算公式如下:其中qik和tk的定义参考前文公式(1~3);注:表征学生过去缺陷点的向量通过rnn的隐含层ht捕捉并输入到rt+1的计算中。进一步的,步骤3.2中的模型训练,包括:模型训练细节:h0是rnn模型的超参数,按照常规,将它设定为0;σ是激活函数,使用的是sigmoid函数,定义为:sortnet中的隐藏层节点数设定为10,随着训练数据的增加,需要调高这个值以带来效果的提升。本发明实施例提供的上述技术方案的有益效果至少包括:本方法可以准确、及时发现学生在数学学科学习中的薄弱点(能力缺陷点)对于有效提升学生成绩和展开个性化学习都非常有效:1.能够有效定位k12阶段学生在数学学科的最细粒度缺陷能力点,从而有针对性的进行差缺补漏练习和巩固,迅速提升学习成绩和学习兴趣;2.通过更多用户的实际反馈数据,更加完善能力图谱和缺陷点关联网络,从而可以更精准定位和预测可能的其他缺陷点;3.该方法作为k12阶段个性化学习的基础和前提,提供更精确的缺陷点和兴趣点定位能力,并具备良好的向其他学科横向拓展的能力。本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。附图说明附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1为本发明实施例公开的基于机器学习的中小学数学能力点缺陷极小样本高精度检测方法的流程图。图2为本发明实施例公开的基于机器学习的中小学数学能力点缺陷极小样本高精度检测方法的系统架构示意图;图3为本发明实施例公开的通过三道题目获得的能力点掌握程度可视化结果。图4为本发明实施例公开的二分图上的蚁群信息素传播算法原理示意图。图5为本发明实施例公开的构造完毕的数学能力图谱(局部)示意图(相同颜色深浅度代表联接紧密)。图6为本发明实施例公开的模型训练和预测流程。图7为本发明实施例公开的三次批量测试示意图:数据采集流程。图8为本发明实施例公开的rnnsortnet模型示意图:(左)rnn框架;(右)sortnet框架。具体实施例下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。通过建立带有细粒度标签的题库,并对待测试学员进行3轮、每轮10道题的测试,我们试图通过少量的测试,持续跟踪和定位学员在这些细粒度能力点上的缺陷。表1是一个示例:表1.题目与能力点的关系示例通过测试获得的能力点缺陷预测,可视化的结果如图2。本发明创造完整的技术方案是:基于机器学习的中小学数学能力点缺陷极小样本高精度发现方法,其特征在于,包括如下步骤:s1.数学能力图谱构建本发明的能力图谱与传统知识图谱有显著的区别,最大的区别在于“原子性”:能力点是最细粒度的数学能力,比如“9*9=?”,“竖式加法时的进位”,“通过三边相等判定三角形全等”等。目前小学一年级到六年级的能力图谱已经全部构建完毕,包含总计2038个能力点。知识点之间的概率联系构建:给定我们标注好能力点的题库q={q1,q2,...,qn},我们使用随机游走方法迭代获得最佳网络概率联接参数。我们人工标注的题库包含5672道题目,总计标签数为14833个,平均每道题2.6个标签,平均每个能力点5道题。首先我们注意到,标注好的知识点与题目构成了二分图(bipartitegraph),即知识点构成了一组节点集合,题目构成了另一组节点集合,有且只有知识点节点和题目节点之间有连接的边(标签数据)。我们借鉴蚁群信息素+随机游走的方法,提出了一种计算二分图节点相似性的方法,来计算原本没有联系的知识点间的概率关联。图3中节点ui代表知识点,vj代表题目,如果题目vj被标注为与ui知识点相关,则ui与vj有边相连。为第t轮迭代,知识点ui带有的信息素种类及浓度;为第t轮迭代,题目vj带有的信息素种类及浓度;初始化阶段,和均为长度为|u|(知识点数)的矢量。通过题目与知识点之间关联的多次传播和迭代,我们可以得到每个知识点节点上携带的所有其他知识点信息素种类和数量,代表了该知识点与其他知识点的联系及强弱,从而构成一幅带有转移概率联接的知识图谱。如图4所示,为构造完毕的数学能力图谱(局部)示意图(相同颜色深浅度代表联接紧密)。其中,是题目v在t时刻的信息素种类,是知识点u在t时刻的信息素种类;为v题目所携带的第k个知识点信息素的量,为u知识点所携带的第k个知识点信息素的量;λ为控制因子,取值1,γ为传播因子,取值0.6。s2.题库生成和人工标签题库来源:互联网上公开的从2000年到2020年的各年级数学考试真题以及部分用作机器学习的k12题库,比如开源的math23k和ixl.com题库,经过扫描和数字化之后,12个学年段共计137632道题(截止2020/7/28)。兼顾题目的难度和知识点代表性,我们共选择了从小学一年级到三年级的156个能力点的380道题,全部都打上了能力点标签数据,共覆盖837个能力点(有重复)。1~3年级的总计321名学生参与了三次不同的测试(每次间隔2周),在排除掉29名全部答对的学生样本后,其中292名学生有至少一题错误,他们回答了总计7946道题(有重复),其中错误回答456项,占比5.7%。同时,根据这292名学生的回答,专家(小学数学教师)对着292名学生标记能力缺陷进行标记,总共标记缺陷数1448处(三次测试汇总,有重复),人均4.95处。s3.当前能力点按掌握程度从低到高排序此步骤我们主要使用rnn+sortnet的方法来对学生的答题数据以及步骤s1得到的知识图谱数据进行模型训练,得到学生动态的缺陷点排名预测。模型训练和预测流程如图5所示。s301.数据准备和预处理(1)能力点激活预处理由于题目和能力点的映射关系是多对多且极为稀疏(平均每道题2.4个能力点),考虑到答错题的概率较低(5%左右),造成了缺陷能力点定位的不准确性。为了测试利用知识点间转移概率对于消除稀疏性的作用,我们尝试了两种不同的知识点权值计算:二值权重(不考虑知识点间联系)和概率权重(考虑知识点间联系)定义第k个能力点分值向量为:定义第i道题目的能力点分值向量为:其中j∈[1,m],m为能力点数量。或公式(2)和(3)的区别是是否考虑了知识图谱的结构信息,公式(2)称为无激活处理,公式(3)称为激活处理,分别对应我们提出的两种不同的模型rnnsortnet1和rnnsortnet2,我们分别进行了实验,结果数据参见下文模型评价部分。(2)训练和测试数据准备由于我们采用的排序模型是基于排序对(pair-wised),原始训练数据需要经过排序处理,得到两两对比的排序数据。我们采用10次交叉验证的方法(crossvalidation),将数据的随机1/10留作测试样本,其余作为训练样本。重复训练和测试流程10次并单独记录结果。按照上述处理,我们总共得到样本总数为67113条。s302.模型训练训练过程,预测过程其中q为问题相关的特征集合,qi=[t1,t2,...,tm,qscorei,yi]是模型的输入数据,t为知识点相关的特征集合,tj为表征该题是否涉及知识点j,取值0代表不涉及,1代表涉及,qscorei代表题目的难度值,取值范围(0,1),越大代表题目越难,yi是学生回答的结果,正确为1,错误为0。是用户最近测评的结果,其中ui为最近几次评测的按主题缺陷度排序结果;是预测结果,包含m个待排序主题的向量,其中按掌握程度从低到高排序为:r1<r2<…<rm。是用于训练排序,包含m个待排序主题的向量,其中按掌握程度从低到高排序为:s1=s2=…=sk<sk+1=sk+2=…=sm。被标记为缺陷的k个知识点整体低于其余知识点。如图6所示为三次批量测试示意图:数据采集流程。图7为rnnsortnet模型示意图:(左)rnn框架;(右)sortnet框架。对于sortnet网络(图7右),正向传播公式为:n>(<x,y>)=σ(∑i,i′wi,>hi(<x,y>)+wi′,>hi′(<x,y>)+b>),(6)对于rnn网络(图7左),正向传播公式为:ht=tanh(whxxt+whx′x′t+whhht-1+bh),(7)yt=σ(wyhht+by),(8)sortnet网络接收自变量输入数据,产生结果n>和n<,分别代表输入知识点k(x参数)缺陷值大于和小于知识点p(y参数)的概率,进而又作为rnn网络的输入参数,rnn进行3个周期的序列计算,输出o。o接近1代表k知识点的缺陷度大于知识点p,o接近-1代表k知识点的缺陷度小于知识点p。vxk,i和vyk,i为sortnet层待学习的联接权重,whx和whx′为rnn层待学习的联接权重,分别对应输入的n>和n<,whh为待学习的隐含层联接权重。各网络参数采用标准反向传播(bp)方法进行求解。(1)训练样本生成:对于每名学生的每次测验,基于测验结果我们对当前测验(10道题)进行专家评估,对当前10道题所涉及的知识点进行缺陷定位,标记薄弱的知识点(0/1取值),标记为薄弱的知识点集合记为ws={t1,t2,...,tw},其余非薄弱知识点集合记为nws={nt1,nt2,...,ntnw}。下标s取值为[1,3],因为总共做了三次有间隔的测试,每次测试10道题。对于每次测验,我们生成三元组{tk,ntp,1}或{ntp,tk,-1}(随机选择一种),三元组包含的特征值记为{x1k,x2k,...,x10k,y1p,y2p,...,y10p,oi},其中oi=-1或1(k缺陷度小于或大于p)。假设当前计算的是知识点k和p的输入参数,那么第i道题关于知识点k和p的输入值计算公式如下:其中qik和tk的定义参考前文公式(1~3)。注意:表征学生过去缺陷点的向量通过rnn的隐含层ht捕捉并输入到rt+1的计算中。(2)模型训练细节h0是rnn模型的超参数(hyper-parameter),按照常规,我们将它设定为0。不过有研究表明(参见https://r2rt.com/non-zero-initial-states-for-recurrent-neural-networks.html),通过前置训练这个超参数可能会获得更好的效果。σ是激活函数,有多种选择,我们使用的是sigmoid函数,定义为:sortnet中的隐藏层节点数我们设定为10,因为目前训练数据样本量并不算大,随着未来训练数据的增加,调高这个值会带来更进一步效果方面的提升。s303.系统实现和模型评价我们采用通行的衡量排序指标ndcg和recall@5来对比本系统与传统方法的效果。(1)ndcg指标其中(2)recall@5指标取预测排名靠前的5个知识点,与专家标注的缺陷知识点进行比对,计算如下指标:模型训练、预测代码采用python3.0语言实现,其中深度学习模块使用pytorch实现,硬件平台为centos8.0服务器。训练流程如表2所述。表2.模型训练流程s304.实验结果和模型对比292名学生测试数据实验结果如下表所示(每次保留1/10数据作为测试样本,10次随机)。三种方法分别为sortnet,我们的方法rnnsortnet1(无激活步骤处理,公式1和2),我们的方法rnnsortnet2(有激活步骤处理,公式1和3)ndcgrecall@5sortnet0.81278.9%rnnsortnet10.89283.3%rnnsortnet20.92387.6%s305.效果举例:完成了模型评测后,我们再将所有的数据重新进行训练一个完整的模型(理论上效果应好于评测阶段的模型,因为数据更充分)。完成对292名学生完成的总计7946道回答的训练,我们得到了模型m。对于未出现于我们训练数据的学生,我们同样对其进行三次测试,每次测试10道题。题目共涉及12个原子级别知识点,如下表所示(知识点有重叠),知识点取自三年级数学难度。实际错误题数为3题,涉及5个知识点。将答题数据输入模型,得到12个知识点的薄弱度排序为:两位数乘以两位数>长度单位换算>3的倍数特征>竖式两位数乘法>一位数乘以两位数(整十)>长度单位>两位数乘以两位数>一位数乘以两位数>一位数乘以一位数>质量单位>质量单位换算>2的倍数特征依据模型排序结果,重点需要给该学生推荐“两位数乘以两位数”、“长度单位换算”、“3的倍数特征”、“竖式两位数乘法”和“一位数乘以两位数(整十)”这五个知识点。下表简单对比了本发明方法与
背景技术:
中所提到的各种方法的优劣。本发明的方法具备明显优势。表1.各种能力追踪方法优劣势对比方法成本普适性精确度持续更新人工高低取决于老师水平难irt低高低难deepknowledgetracing低中较低易本发明方法低高高易应该明白,公开的过程中的步骤的特定顺序或层次是示例性方法的实例。基于设计偏好,应该理解,过程中的步骤的特定顺序或层次可以在不脱离本公开的保护范围的情况下得到重新安排。所附的方法权利要求以示例性的顺序给出了各种步骤的要素,并且不是要限于所述的特定顺序或层次。在上述的详细描述中,各种特征一起组合在单个的实施方案中,以简化本公开。不应该将这种公开方法解释为反映了这样的意图,即,所要求保护的主题的实施方案需要清楚地在每个权利要求中所陈述的特征更多的特征。相反,如所附的权利要求书所反映的那样,本发明处于比所公开的单个实施方案的全部特征少的状态。因此,所附的权利要求书特此清楚地被并入详细描述中,其中每项权利要求独自作为本发明单独的优选实施方案。本领域技术人员还应当理解,结合本文的实施例描述的各种说明性的逻辑框、模块、电路和算法步骤均可以实现成电子硬件、计算机软件或其组合。为了清楚地说明硬件和软件之间的可交换性,上面对各种说明性的部件、框、模块、电路和步骤均围绕其功能进行了一般地描述。至于这种功能是实现成硬件还是实现成软件,取决于特定的应用和对整个系统所施加的设计约束条件。熟练的技术人员可以针对每个特定应用,以变通的方式实现所描述的功能,但是,这种实现决策不应解释为背离本公开的保护范围。结合本文的实施例所描述的方法或者算法的步骤可直接体现为硬件、由处理器执行的软件模块或其组合。软件模块可以位于ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、移动磁盘、cd-rom或者本领域熟知的任何其它形式的存储介质中。一种示例性的存储介质连接至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。当然,存储介质也可以是处理器的组成部分。处理器和存储介质可以位于asic中。该asic可以位于用户终端中。当然,处理器和存储介质也可以作为分立组件存在于用户终端中。对于软件实现,本申请中描述的技术可用执行本申请所述功能的模块(例如,过程、函数等)来实现。这些软件代码可以存储在存储器单元并由处理器执行。存储器单元可以实现在处理器内,也可以实现在处理器外,在后一种情况下,它经由各种手段以通信方式耦合到处理器,这些都是本领域中所公知的。上文的描述包括一个或多个实施例的举例。当然,为了描述上述实施例而描述部件或方法的所有可能的结合是不可能的,但是本领域普通技术人员应该认识到,各个实施例可以做进一步的组合和排列。因此,本文中描述的实施例旨在涵盖落入所附权利要求书的保护范围内的所有这样的改变、修改和变型。此外,就说明书或权利要求书中使用的术语“包含”,该词的涵盖方式类似于术语“包括”,就如同“包括,”在权利要求中用作衔接词所解释的那样。此外,使用在权利要求书的说明书中的任何一个术语“或者”是要表示“非排它性的或者”。参考文献[brown&vanlehn,1980]brown,j.s.,andvanlehn,k.1980.repairtheory:agenerativetheoryofbugsinproceduralskills.cognitivescience4(4):379-426.[feldmanetal.2018]feldman,m.q.;cho,j.y.;ong,m.;gulwani,s.;popovic,z.;andandersen.e.2018.automaticdiagnosisofstudents’misconceptionsink-8mathematics.inproceedingsofthe2018chiconferenceonhumanfactorsincomputingsystems,264.acm.[piech&bassen,etc.,2015]chrispiech,jonathanbassen,jonathanhuang,suryaganguli,mehransahami,leonidasj.guibas,jaschasohl-dickstein:deepknowledgetracing.nips2015:505-513.[selent&heffernan,2014]d.selentandn.heffernan.reducingstudenthintusebycreatingbuggymessagesfrommachinelearnedincorrectprocesses.inintl.conf.onintelligenttutoringsystems,pages674-675.springer,2014.[chen&yu,etc.,2018]penghechen,yulu,vincentw.zheng,xiyangchen,bodayang:knowedu:asystemtoconstructknowledgegraphforeducation.ieeeaccess6:31553-31563(2018).[rigutini&papini,etc.,2011]l.rigutini,t.papini,m.maggini,f.scarselli,sortnet:learningtorankbyaneuralpreferencefunction,ieeetransactionsonneuralnetworks,22(9)(2011)1368-1380.当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1