一种基于图信息增强的实体关系抽取方法与流程
本发明涉及一种基于图信息增强的实体关系抽取方法,属于信息抽取和大数据挖掘技术领域。
背景技术:
实体关系抽取是知识图谱构建、信息抽取领域的重要研究课题。实体关系抽取是指从文本数据集中抽取不同实体之间的各种语义关系。知识图谱在智能搜索与问答、个性化建模与推荐、文本分类与聚类等领域得到广泛应用。
实体关系抽取方法主要分为基于机器学习的方法、基于神经网络的方法、基于远程监督的方法、基于半监督的方法等。基于机器学习的实体关系抽取方法通常首先构建文本特征,然后采用支持向量机、随机森林,以及条件随机场等模型进行实体关系识别。基于神经网络的方法是指采用卷积神经网络、循环神经网络等深度学习模型来抽取实体关系。基于远程监督的实体关系抽取方法是指通过远程知识库扩大标注数据集,使模型能够学习到包含实体关系的自然语言上下文特征信息。基于半监督的实体关系抽取方法则同时利用大量标注样本数据和少量未标记样本数据,来构建实体关系的学习器。
图神经网络(graphneuralnetwork,简称gnn)能够将语料集中句子内的实体关系集合转换为图数据,然后学习图节点即实体的向量表示。对于拓扑结构的图数据,图中每个节点通过语义关系或其他关联关系等与其邻居节点相连,节点的邻居节点的数量和类型是动态变化的。这些节点及其关系能够用于获取实体之间的依赖关系信息。通过图神经网络训练学习数据集中实体的图结构信息,生成表示实体的节点的向量表示。
实体关系抽取是知识图谱构建的重要研究内容。目前实体关系抽取方法主要利用语料集的文本信息,来学习刻画实体关系的词法和句法等自然语言方面的特征,难以学习三个或更多个实体之间的隐式关系的结构特征。
技术实现要素:
本发明的目的在于针对现有实体关系抽取方法难以学习多个实体之间隐式关系的结构特征的技术缺陷,提出了一种基于图信息增强的实体关系抽取方法,将训练集中的实体关系三元组集合转换为图数据,基于图神经网络生成实体的向量;再基于预训练模型bert生成句子词语向量,构建句子初始向量,拼接句子初始向量和实体向量为句子向量,再将句子向量输入至全连接网络,进行句子权重训练,实现实体关系抽取。
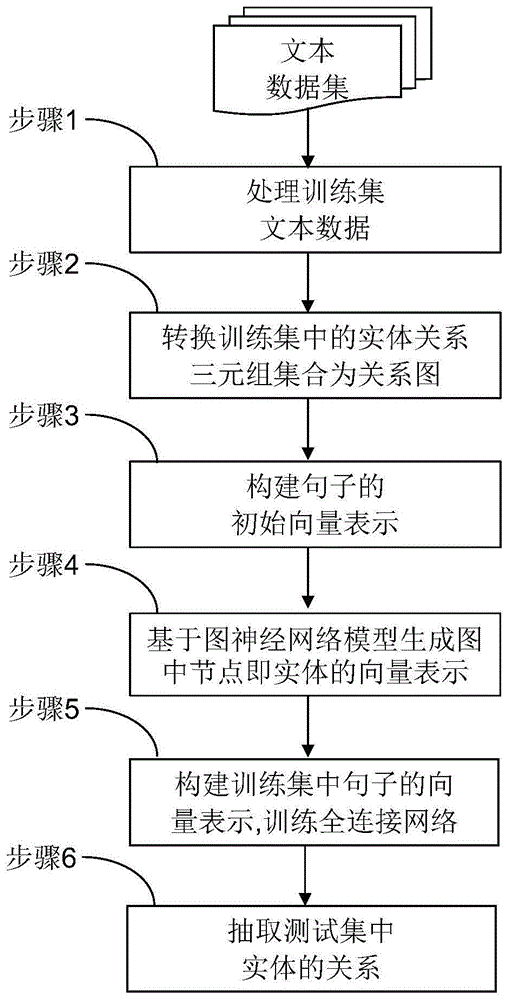
所述基于图信息增强的实体关系抽取方法,包括以下步骤:
步骤1:训练集文本数据处理:将训练集中的句子进行分词、抽取头实体和尾实体及其关系,并将头实体和尾实体保存为字典形式;
步骤1,具体为:利用预训练模型bert中的tokenizer方法对句子进行分词,抽取头实体和尾实体,获取头实体和尾实体的位置标记,标注头实体和尾实体的关系;
步骤2:将训练集中的实体关系三元组集合转换为关系图;
对训练集进行实体对及其关系抽取,获取关系三元组集合,并将其转换为图的表示形式,即构建其对应的关系图;
该关系图,记为g,g中节点表示实体,边表示实体关系三元组中头实体和尾实体之间的关系;
其中,关系三元组包括头实体,关系和尾实体;
步骤3:构建训练集中句子的初始向量表示,利用预训练模型bert生成句子词语的向量,进而构建句子的初始向量;
步骤3.1:对分词后的句子加入句子的开始标记“[cls]”,句子的结尾标记“[sep]”;
步骤3.2:对句子中的token或词语进行标引,将句子中每个词与词汇表对应,生成句子索引向量;
步骤3.3:将句子索引向量输入到预训练模型bert中;
步骤3.4:对于每个单词,采用其最后两层隐藏层的特征向量作为词向量;对于每个句子,将其所有词语的词向量求平均作为句子的初始向量表示;
步骤4:基于图神经网络模型生成关系图中节点即实体的向量表示;
步骤4.1:生成关系图中每个节点v的初始向量;
对于节点v,设其表示实体e,通过预训练模型bert生成实体e的词向量,作为节点v的初始向量;
步骤4.2:采用graphsage训练图神经网络,提取隐藏层向量,生成关系图中节点的向量表示;
其中,graphsage,即graphsampleandaggregate;
步骤5:构建训练集中句子的向量表示,即拼接句子初始向量、头实体向量和尾实体向量,构建为句子向量,再将句子向量输入全连接网络中,根据句子的分类损失计算模型损失并反向传播回全连接层,进行全连接网络参数的学习和更新;
其中,构建句子向量具体为:
对于句子s,设s包含头实体h和尾实体t,通过步骤4的图神经网络模型生成头实体h的向量vh,以及尾实体t的向量vt;设由步骤3生成句子s的句子初始向量vs,将vs,vh,vt拼接,构建为句子s的向量表示;
模型损失如公式(1)所示:
其中,n为句子数量,li为句子si的分类损失,αi为权重;
步骤6:抽取测试集中实体的关系,具体为:
基于测试集依次进行步骤1的文本数据处理,步骤2的关系图构建,步骤3的句子初始向量表示构建,步骤4的实体节点的向量表示构建,步骤5的句子向量表示构建,将句子向量输入全连接网络中,然后利用softmax函数对句子中的实体关系分类。
有益效果
本发明基于图信息增强的实体关系抽取方法,与现有实体关系抽取方法相比,具有如下有益效果:
1.本发明的实体关系抽取方法具有移植性和鲁棒性,对于语料集的来源和领域不受限制;基于图神经网络对实体关系三元组集合建模,对实体关系三元组中关系类型不受限制;
2.所述方法通过引入基于图神经网络生成的实体向量表示,挖掘了多个实体之间的隐含关系结构特征,增强了句子初始向量的实体特征信息,提高了实体关系抽取的准确性;
3.所述方法引入句子动态权重分类损失的训练方法,由于自然语言的复杂性和灵活性,同一种关系在文本中存在多种表达形式,不同表达形式在同一种关系抽取中具有不同的重要性,即区分了同一种关系的不同句子表达形式的重要程度,提高了实体关系抽取的准确性;
4.所述方法能够抽取不同领域的实体关系,在信息检索、文本分类、问答系统等领域具有广阔的应用前景。
附图说明
图1为本发明一种基于图信息增强的实体关系抽取方法及实施例1的流程示意图。
具体实施方式
下面结合实施例对本发明一种基于图信息增强的实体关系抽取方法的优选实施方式进行详细说明。
实施例1
本实施例叙述了采用本发明所述的一种图信息增强的实体关系抽取方法的流程,如图1所示。本发明基于图信息增强的实体关系抽取方法依托的实体关系抽取系统以pycharm为开发工具,python为开发语言,pytorch为开发框架。
从图1可以看出,具体包括如下步骤:
步骤1:训练集文本数据处理:将训练集中句子进行分词、抽取头实体和尾实体及其关系,并将头实体和尾实体保存为字典形式;
步骤1,具体为:利用预训练模型bert中的tokenizer方法对句子进行分词,抽取头实体和尾实体,获取头实体和尾实体的位置标记,标注头实体和尾实体的关系;
对于句子“liming'sfatherislipeng.”,分词后的结果为“[‘li’,‘ming’,‘'’,‘s’,‘father’,‘is’,‘li’,‘peng’,‘.’]”,抽取头实体和尾实体为“liming,lipeng”,获取头实体和尾实体的位置标记为“[0,1],[6,7]”,标注头实体和尾实体的关系为“is_father”。
步骤2:将训练集中的实体关系三元组集合转换为关系图;
对训练集进行实体对及其关系抽取,获取关系三元组集合,并将其转换为图的表示形式,即构建其对应的关系图g;
图g中节点表示实体,边表示实体关系三元组中头实体和尾实体之间的关系;
其中,关系三元组包括头实体,关系和尾实体;
步骤3:构建句子的向量表示。利用预训练模型bert生成句子词语的向量,进而构建句子的初始向量;
步骤3.1:对分词后的句子加入句子的开始标记“[cls]”,句子的结尾标记“[sep]”。
例如,对于句子“[‘li’,‘ming’,‘'’,‘s’,‘father’,‘is’,‘li’,‘peng’,‘.’]”,加入句子的开始标记、结尾标记为“[‘[cls]’,‘li’,‘ming’,‘”,‘s’,‘father’,‘is’,‘li’,‘peng’,‘.’,‘[sep]’]”。
步骤3.2:对句子中的token或词语进行标引,将句子中每个词与词汇表对应,生成句子索引向量。
例如,上面例句生成的索引向量为:“[([cls],101),(li,5622),(ming,11861),(',1005),(s,1055),(father,2289),(is,2003),(li,5622),(peng,26473),(.,1012),([sep],102)]”。
步骤3.3:将句子索引向量输入到预训练模型bert中。例如,预训练模型bert模型为一个12层的深度神经网络模型,每个隐藏层包含768个节点。因此对于输入的每个单词,在对单词进行token转换后,经过模型会生成12个768维度的隐藏层特征。
步骤3.4:对于每个单词,采用其最后两层隐藏层的特征向量作为词向量。对于每个句子,将其所有词语的词向量求平均作为句子的初始向量表示。
步骤4:基于图神经网络模型生成关系图中节点即实体的向量表示;
步骤4.1:生成关系图中每个节点v的初始向量;
对于节点v,设其表示实体e,通过预训练模型bert模型生成实体e的词向量,作为节点v的初始向量;
步骤4.2:采用graphsage方法训练图神经网络,提取隐藏层向量,生成关系图中节点的向量表示;
其中,graphsage,即graphsampleandaggregate;
步骤5:构建句子的向量表示,即拼接句子初始向量、头实体向量和尾实体向量,构建为句子向量,再将句子向量输入全连接网络中,根据句子的分类损失计算模型损失并反向传播回全连接层,进行全连接网络参数的学习和更新;
其中,构建句子向量具体为:
对于句子s,设s包含头实体h和尾实体t,通过步骤4的图神经网络模型生成头实体h的向量vh,以及尾实体t的向量vt。设由步骤3生成句子s的句子初始向量vs,将vs,vh,vt拼接,构建为句子s的向量;
模型损失如公式(1)所示:
其中n为句子数量,li为句子si的分类损失,αi为权重;
步骤6:抽取测试集中实体的关系;
对于测试集,依次进行步骤1的文本数据处理,步骤2的关系图构建,步骤3的句子初始向量表示构建,步骤4的实体节点的向量表示构建,步骤5的句子向量表示构建,将句子向量输入全连接网络中,然后利用softmax函数对句子中的实体关系分类。
为说明本发明的实体关系抽取效果,本实验是在同等条件下,以相同的训练集和测试集分别采用两种方法进行比较。第一种方法是基于注意力机制的双向长短时记忆网络的实体关系抽取方法,第二种是本发明的实体关系抽取方法。
实体关系抽取是多分类任务,采用的评测指标为:宏平均f1值(macroaveragef1值),该值为所有关系种类识别的f1值的平均值,计算方法如公式2所示:
其中,y为所有识别的关系种类集合,py和ry为关系种类y识别的查准率(precision)和召回率(recall),py=tpy/(tpy+fpy),ry=tpy/(tpy+fny)。对于关系种类y,tpy表示模型预测为正例且样本用例真值为真的样本数,即正确接受;fny表示模型预测为假但样本用例真值为真的样本数,即错误拒绝;fpy表示模型预测为真但样本用例真值为假的样本数,即错误接受。
实体关系抽取的结果为:已有技术的基于注意力机制的双向长短时记忆网络的宏平均f1值约为83.2%。采用本发明方法的宏平均f1值约为85.98%。通过实验表明了本发明提出的一种基于图信息增强的实体关系抽取方法的有效性。
以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都落入本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!