一种大数据平台及其应用的制作方法
本申请属于数据分析技术领域,特别是涉及一种大数据平台及其应用。
背景技术:
近年来随着人工智能和大数据[技术的快速发展,各行各业都在数据信息技术处理方面出现了快速的技术升级,尤其是在传统行业里面发生了巨大的技术变革。在石油领域中,各大石油企业内部的业务系统的广泛使用对数据处理提出了更高要求,如提高单井运行效率、合理规划油田产能、降低运输成本、提高生产效率、企业油田数据管理、提供高层决策支持,与此同时,伴随着油田数字化和智慧油田建设,各类物联网设备也被应用在石油生产活动当中,这些物联网设备在生产活动中不断产生出大量的数据,并且这些数据呈现爆炸式增长。如在油田多相流测量当中,仅一台多相流量计一天的ect、微波、文丘里等数据就将近1g,这些与多相流相关的油气含量数据直接或者间接体现着某一口油井的产量多少以及油的品质,并且由于这些数据的量非常大,传统的数据分析方法已经不能满足当前的需求,因此对于多相流的油气大数据进行数据挖掘需要更高的要求。同时对于大量的数据如何应用在深度学习方面的应用也面临着巨大的问题,由于这些数据是直接从多相流量计上面采集而来,数据存在缺失、错误、冗余等问题而不能直接用于深度学习模型的训练,因此需要借助大数据平台对数据进行数据预处理,然后将处理好之后的数据应用深度学习模型的训练和进行预测。
油田企业拥有众多的生产数据,而对于大量生产数据的应用确是存在一定的困难,尤其是对于不同的企业数据存在一定的隐私而不可能做到数据交互,因此将数据交于第三方公司并利用第三方的大数据平台进行数据分析,并将融合之后的数据应用于各个模型的训练当中,随后将数据分析的结果和训练的模型返回给不同的企业以提高模型的可靠性。
当前很多石油企业,如壳牌、雪佛龙、沙特阿美、斯伦贝谢等均在自己的企业内部都建立了自己的大数据平台,但是这些大数据平台根据不同的需求建立各个不同的业务模块,利用数据进行数据分析,并给现场人员决策支持,通过自动化的决策降低人工干预的可能,减少数据分析人员工作量,而在石油行业对于多相流的细分方向还没有相对应的数据分析平台,除此之外这些大公司的数据平台的数据并不能交由第三方公司来做数据分析而是企业内部的数据分析平台。
技术实现要素:
1.要解决的技术问题
基于当前很多石油企业,如壳牌、雪佛龙、沙特阿美、斯伦贝谢等均在自己的企业内部都建立了自己的大数据平台,但是这些大数据平台根据不同的需求建立各个不同的业务模块,利用数据进行数据分析,并给现场人员决策支持,通过自动化的决策降低人工干预的可能,减少数据分析人员工作量,而在石油行业对于多相流的细分方向还没有相对应的数据分析平台,除此之外这些大公司的数据平台的数据并不能交由第三方公司来做数据分析而是企业内部的数据分析平台。
的问题,本申请提供了一种大数据平台及其应用。
2.技术方案
为了达到上述的目的,本申请提供了一种大数据平台,所述平台包括界面子平台、业务模式子平台、集群子平台和数据层子平台;
所述界面子平台,用于利用大数据平台显示各个不同的维度数据并进行对比;
所述业务模式子平台,用于将数据层子平台计算结果实时的反馈给外界;
所述集群子平台,用于利用已有的大数据分析平台实时和离线处理来自不同企业的数据,对数据进行不同的机器学习算法,根据需要调用外部训练好的模型来处理数据;
所述数据层子平台,用于对实时数据和历史数据分别存储,并对部分数据进行清洗。
本申请提供的另一种实施方式为:所述界面子平台、所述业务模式子平台、所述集群子平台和所述数据层子平台通信连接。
本申请提供的另一种实施方式为:所述界面子平台包括数据显示模块和模型管理模块;
所述数据显示模块,用于对总数据展示,支持二维或者三维可视化图表展示各个关键的指标,对数据挖掘的结果或者中间结果进行显示;
所述模型管理模块,用于对特定模型结果进行对比,并选择最优模型。
本申请提供的另一种实施方式为:所述业务模式子平台包括数据传输模块以及业务处理模块,所述数据传输模块用于对不同的数据来源进行管理,对于不同存储的方式,将部分数据自动地迁移到另一个存储设备,方便各个计算引擎进行计算;
所述业务处理模块用于对各个业务指标进行分析,或者对自动化脚本分析、汇总。
本申请提供的另一种实施方式为:所述集群子平台包括数据处理模块、算法模块和模型协调模块;
所述数据处理模块,用于根据不同的数据来源和数据格式,对数据进行离线处理和实时处理;
所述算法模块,用于对数据进行不同的机器学习算法;
所述模型协调模块,用于根据需要调用外部训练好的模型来处理数据。
本申请提供的另一种实施方式为:所述数据层子平台包括数据生命周期管理模块和数据存储模块;
所述数据生命周期管理模块,用于对数据进行数据挖掘、模型训练,对大量数据下载和筛选符合要求的数据;
所述数据存储模块,用于对数据分类后分别进行存储。
本申请提供的另一种实施方式为:所述界面子平台还包括权限管理模块,所述权限管理模块用于对公司内部各个不同部门的员工以及其他作业方的员工制定相应的权限,对于不同的角色也制定不同的权限。
本申请提供的另一种实施方式为:所述算法模块包括机器学习算法子模块,所述机器学习算法子模块包括回归模型、分类模型、聚类分析模型和时间序列模型。
本申请还提供一种大数据平台的应用,将所述的大数据平台应用于油气大数据的分析。本申请提供的另一种实施方式为:还包括油气井故障监测模块和油井开发方案评价模块;所述油气井故障监测模块,用于对抽油杆断脱、活塞遇阻、油管或泵漏油、结蜡或者出砂、供液不足进行监测;
所述油井开发方案评价模块,用于提供配产、配注方案,评价开发方案的适应程度,提出调整方案;预测分区块、分井的产量、压力、含水率变化趋势和油井水淹规律。
3.有益效果
与现有技术相比,本申请提供的一种大数据平台及其应用的有益效果在于:
本申请提供的大数据平台,基于多传感技术手段的油气静、动态多维度生产大数据,以支撑油气生产的智慧化管理而提出一套解决这些难题的方案,并建立一套第三方用于生产大数据分析的系统并部署于实际的生产环境当中。
本申请提供的大数据平台,利用当前大数据平台收集各大石油公司的油气生产数据,然后对各个石油公司的数据进行数据预处理并对数据进行分析,最后需要可视化的数据进行展示。
本申请提供的大数据平台,利用比较主流的大数据分析技术spark来,相对于传统的hadoop处理方式速度更快,数据处理能力更强。
本申请提供的大数据平台,对于大数据平台的数据分析可以使用机器学习和深度学习模型在平台上面进行预测。
本申请提供的大数据平台,针对于数据存放在阿里云上面的特点而进行特定的传输到大数据平台内部。
本申请提供的大数据平台,针对于数据特点在平台层面设计合理的存储方式。
附图说明
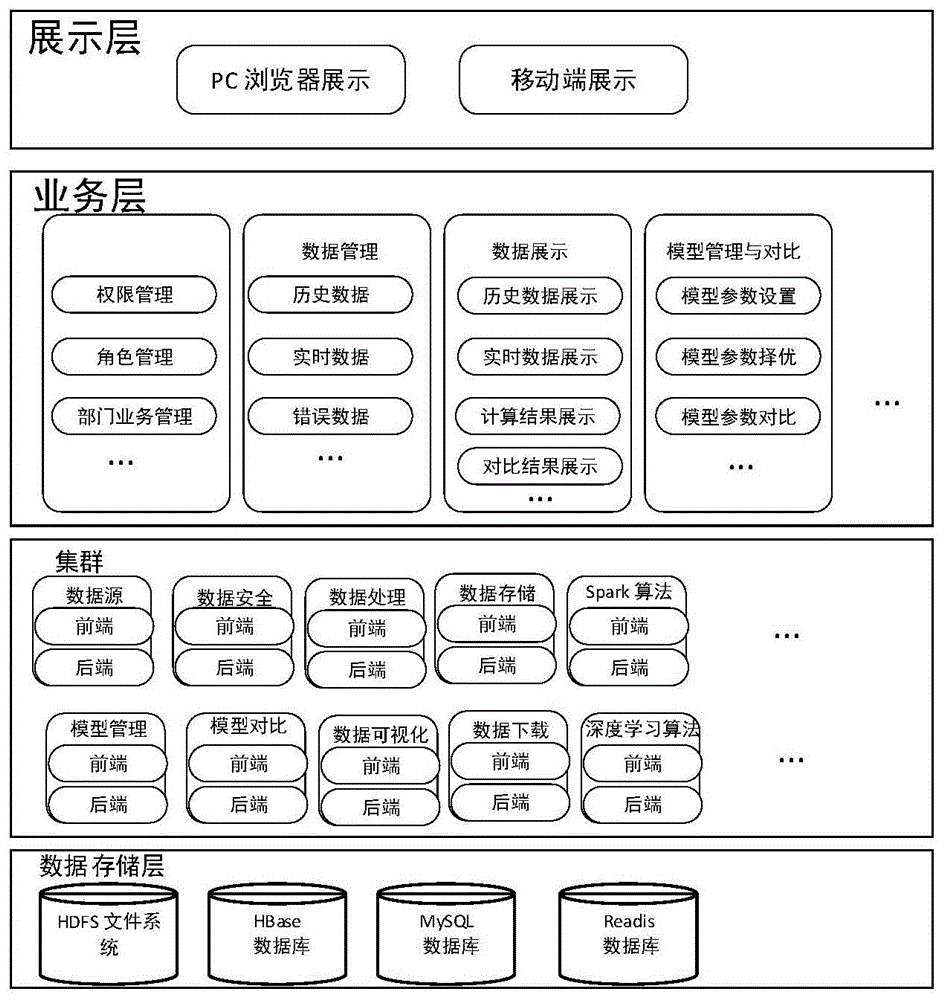
图1是本申请的大数据平台架构示意图;
图2是本申请的数据处理流程示意图;
图3是本申请的ssh架构示意图;
图4是本申请的历史数据查看示意图;
图5是本申请的油气产量数据展示示意图;
图6是本申请的大数据框架示意图。
具体实施方式
在下文中,将参考附图对本申请的具体实施例进行详细地描述,依照这些详细的描述,所属领域技术人员能够清楚地理解本申请,并能够实施本申请。在不违背本申请原理的情况下,各个不同的实施例中的特征可以进行组合以获得新的实施方式,或者替代某些实施例中的某些特征,获得其它优选的实施方式。
集群:计算机集群简称集群,是一种计算机系统,它通过一组松散集成的计算机软件或硬件连接起来高度紧密地协作完成计算工作。
分布式:指由多台分散的计算机,经互连网络的联接而形成的系统,系统的处理和控制功能分布在各个计算机上。
数据挖掘:指从大量的数据中通过算法搜索隐藏于其中信息的过程
大数据平台:是指以处理海量数据存储、计算及不间断流数据实时计算等场景为主的一套基础设施。典型的包括hadoop系列、spark、storm、flink以及flume/kafka等集群。
对于采用时间序列来预测未来一段时间产量,存在以下问题:
(1)当前大数据平台均是针对于企业内部的数据平台,而对于具体行业的油气大数据分析还没有完整的数据分析平台。
(2)当前数据分析平台多数没有考虑将多个油田的数据收集起来进行数据分析,由于是企业内部并不能做到数据共享。
(3)当前数据分析平台数据采集方式较为单一,而本平台数据采集方式较多。
(4)多维数据在平台的数据储存模式没有明确得具体化。
(5)当前大多数技术平台多选择比较老的技术框架hadoop,使得其计算你速度较慢。
参见图1~6,本申请提供一种大数据平台,所述平台包括界面子平台、业务模式子平台、集群子平台和数据层子平台;
所述界面子平台,用于利用大数据平台显示各个不同的维度数据并进行对比;
所述业务模式子平台,用于将数据层子平台计算结果实时的反馈给外界;
所述集群子平台,用于利用已有的大数据分析平台实时和离线处理来自不同企业的数据,对数据进行不同的机器学习算法,根据需要调用外部训练好的模型来处理数据;
所述数据层子平台,用于对实时数据和历史数据分别存储,并对部分数据进行清洗。
首先,数据进入数据存储子平台,根据业务的需求从数据存储层获取数据然后再利用集群的硬件进行计算,计算的结果存放在磁盘或者数据库,最后利用网页展示数据。
部分数据可以直接从数据层到界面显示,部分数据可以直接从外部接口传入到界面显示,部分数据可以直接根据集群的计算结果进行显示。
通过界面可以直接设置部分业务层面的参数,然后再进行计算和存储。
部分业务层面可以通过定时启动或者脚本方式进行启动。
友好的交互作用:平台设计可重拖、拉、等方式来对复杂界面进行调整。
进一步地,所述界面子平台、所述业务模式子平台、所述集群子平台和所述数据层子平台通信连接。
进一步地,所述界面子平台包括数据显示模块和模型管理模块;
所述数据显示模块,用于对总数据展示,支持二维或者三维可视化图表展示各个关键的指标,对数据挖掘的结果或者中间结果进行显示;友好的可视化界面:界面可以通过百度echarts插件对可总数据展示,支持二维或者三维可视化图表展示各个关键的指标,如折线图、曲线图、雷达图以及地图来显示各个区域油井产量等。
所述模型管理模块,用于对特定模型结果进行对比,并选择最优模型。通过web界面可以实现对特定模型结果进行对比,并选择最优模型。
进一步地,所述业务模式子平台包括数据传输模块以及业务处理模块,所述数据传输模块用于对于不同的数据来源,可以分为对不同的数据源进行管理,如历史数据、实时数据、阿里云数据、本地磁盘数据;针对于不同存储的方式,部分数据可以自动的对数据进行迁移到另一个存储设备,方便各个计算引擎进行计算;业务处理模块主要借助于web页面来对各个业务指标进行分析,或者借助于后端的自动化脚本分析、汇总等。
进一步地,所述集群子平台包括数据处理模块、算法模块和模型协调模块;
所述数据处理模块,用于根据不同的数据来源和数据格式,对数据进行离线处理和实时处理;根据不同的数据来源和数据格式不同,对于大量数据进行离线处理和对通过传接口过来的油气数据实时处理。
所述算法模块,用于对数据进行不同的机器学习算法;
所述模型协调模块,用于根据需要调用外部训练好的模型来处理数据。
可以通过脚本语言对数据进行相应的预处理,也可以通过平台代码自动处理文件;支持从不同来源的数据处理,如接口数据、阿里云数据、本地数据、实时数据等;支持各种不同的数据形式,如csv、excel、txt文本、json和xml格式数据、数据库数据、hdfs、hive、hbase等数据。
进一步地,所述数据层子平台包括数据生命周期管理模块和数据存储模块;
所述数据生命周期管理模块,用于对数据进行数据挖掘、模型训练,对大量数据下载和筛选符合要求的数据;
所述数据存储模块,用于对数据分类后分别进行存储。
支持对所有油气数据进行数据挖掘、模型训练,其中包括数据清理、数据标准化、数据可视化等。支持通过平台对大量数据的下载和筛选符合要求的数据。
进一步地,所述界面子平台还包括权限管理模块,所述权限管理模块用于对公司内部各个不同部门的员工以及其他作业方的员工制定相应的权限,对于不同的角色也制定不同的权限。
进一步地,所述算法模块包括机器学习算法子模块,所述机器学习算法子模块包括回归模型、分类模型、聚类分析模型和时间序列模型。
还可以用tensorflow来进行训练并将结果呈现在平台并对各种相同模型的参数进行对比或者与不同ai模型进行对比。
本申请还提供一种大数据平台的应用,将所述的大数据平台应用于油气大数据的分析。进一步地,还包括油气井故障监测模块和油井开发方案评价模块;
所述油气井故障监测模块,用于对抽油杆断脱、活塞遇阻、油管或泵漏油、结蜡或者出砂、供液不足进行监测;
所述油井开发方案评价模块,用于提供配产、配注方案,评价开发方案的适应程度,提出调整方案;预测分区块、分井的产量、压力、含水率变化趋势和油井水淹规律。
平台数据处理流程需要分阶段处理,每一个阶段都可以根据实际业务的需求而提供对应的数据处理服务,整体流程如图2所示:
仓库的过程实际上就是数据集成;通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式;数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,归约之后的数据小得多,但仍然接近于保持原数据的完整性,并且结果与归约前结果相同或几乎相同。
数据挖掘算法选择:根据相对应的油田的实际业务需求或者实验室需求选择要使用的算法以及算法结果对比方式,并将结果通过web进行展示。
模型的训练以及数据挖掘:根据不同模型的结果对比选择最优参数和最有参数。利用平台机器学习算法库和深度学习库等完成对应的数据挖掘要求。
数据可视化:借助平台web前端页面可以对数据挖掘的结果或者中间结果进行显示,可以根据数据统计分析可视化结果选择合适的预处理算法。
针对于平台主要功能:
油气生产数据管理,针对于数据来源不同,可以分为历史数据和实时数据进行处理;针对于数据类型可以分为ect、文丘里、微波数据进行处理;针对于数据数据粒度上可分为明细数据、汇总数据处理。
动态生产分析,包括生产分析、措施效果分析、单井变化原因分析、单井油气动态生产分析变化原因、油气动态生产分析-层级(共计五级)、井组动态分析变化原因。
油气井故障监测,包括抽油杆断脱、活塞遇阻、油管或泵漏油、结蜡或者出砂、供液不足。油井开发方案评价,确定区块、小层的合理注采比,合理生产压差,合理注采强度,提供配产、配注方案;分析掌握注水后油井见效、见水以及水淹规律,制定工作制度,保证油井稳定生产;通过油田发开实际情况和动态分析结果,验证油田静态情况(油层连同情况,断层位置、性质和遮挡作用)的认知请层度,评价开发方案的适应程度,提出调整方案;预测分区块、分井的产量、压力、含水率变化趋势和油井水淹规律。
利用平台机器学习库可以进行预测,可以将深度学习模型部署到本平台然后在进行预测。
平台技术实现和平台部署:
在整个web部分后台部分采用的是struts、spring、hibernate进行后台的数据处理和权限控制。其中struts是一个很好的mvc框架,主要技术是servlet和jsp,struts的mvc设计式可以使我们的逻辑变得很清晰,让我们写的程序层次分明,在整个mvc里面起着核心的控制作用;spring提供了管理业务对象的一致方法,并鼓励注入对接口编程而不是对类编程的良好习惯,使我们的产品在最大程度上解耦;hibernate是用来持久化数据,提供了完全面向对象的数据库操作,hibernate对jdbc进行了非常轻量级的封装,它使得与关系型数据库交互变得非常轻松。整个ssh架构见图3。
web的前端采用html、css、javascript等作为页面主要框架,在整个前端当中html决定网页的结构和内容;css设定网页的表现样式;javascript控制网页的行为。除此之外需要用到百度echarts、jquery等第三方插件来实现页面特殊功能和美化页面。搭建完成后的前端可以用来展示部分数据,数据通过后端实现,部分页面实现如下图4、图5所示。
在整个大数据平台层面,选择以apachespark作为计算核心,spark可以处理历史数据和实时数据。整个平台数据可以分为动态数据和静态数据两大类,动态数据和静态数据需要不同的处理方式,在平台里面对于大量的历史数据可以存放在hbase里面,每一天的历史数据经过阿里云临时存储,然后在利用脚本语言将数据下载并存放在hbase里面,实时数据经过接口可以传送过来并利用spark计算框架计算,将中间结果存放在redis内存数据库,计算结果存放在mysql数据库再通过web展现在页面,利用hive可以分析大数据,由于整个平台有多个job因此需要azkaban进行作业调度,整个数据平台提供接口供外部进行调用。整个大数据平台系统架构图如图6所示。
针对于部分数据的传输可以使使用其他框架替换来达到传输效果。
针对于平台内部使用的部分预测算法,可以使用其他算法进行代替。
尽管在上文中参考特定的实施例对本申请进行了描述,但是所属领域技术人员应当理解,在本申请公开的原理和范围内,可以针对本申请公开的配置和细节做出许多修改。本申请的保护范围由所附的权利要求来确定,并且权利要求意在涵盖权利要求中技术特征的等同物文字意义或范围所包含的全部修改。
- 还没有人留言评论。精彩留言会获得点赞!