一种基于特征序列挖掘和精简的恶意软件检测方法与流程
本发明属于恶意软件检测
技术领域:
,具体涉及一种基于特征序列挖掘和精简的恶意软件检测方法。
背景技术:
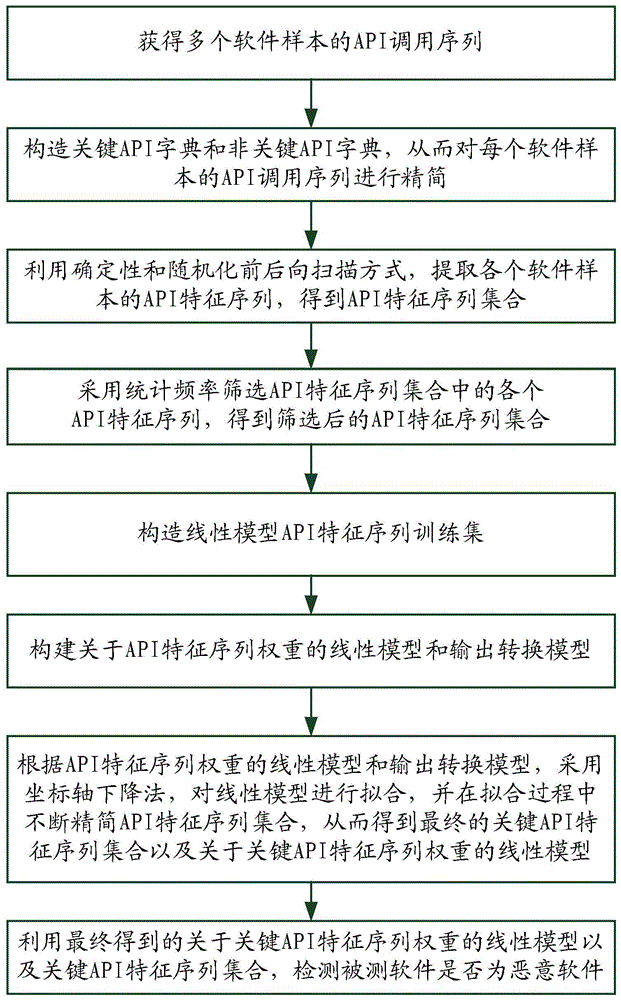
:恶意软件是指各种形式的恶意或者入侵软件,例如计算机病毒、蠕虫、间谍软件、木马、广告软件等。恶意软件通常以可执行程序、脚本等形式存在。在计算机系统安全领域,一个重要问题是进行恶意软件的检测与识别,以便能在恶意软件运行之前将其清除,避免给计算机系统造成破坏或者给用户造成损失。恶意软件的检测与识别,常用方法为恶意软件静态检测方法,即:对恶意软件的静态特征进行识别,其中,静态特征主要包括可执行文件及其反汇编文件的字节码、汇编指令、导入函数和分节信息等特征。然而,实际应用中使用的恶意软件往往存在变形或垃圾代码插入等混淆情况,从而导致静态检测方法无法有效识别混淆后的恶意软件,降低恶意软件的检测分类精度。因此,如何有效提高恶意软件的检测与识别精度,从而及时清除恶意软件,保障计算机系统运行安全,是目前急需解决的问题。技术实现要素:针对现有技术存在的缺陷,本发明提供一种基于特征序列挖掘和精简的恶意软件检测方法,可有效解决上述问题。本发明采用的技术方案如下:本发明提供一种基于特征序列挖掘和精简的恶意软件检测方法,包括以下步骤:步骤1,收集p个软件样本,分别为软件样本s1,s2,...,sp;其中,所述软件样本包括恶意软件样本和正常软件样本;对于收集到的每个软件样本si,i=1,2,...,p,获得其api调用序列apii=<apii1,apii2,...,apiic>;其中,c为软件样本si对应的api调用序列中包括的api的总数量;步骤2,构造关键api字典和非关键api字典,从而对每个软件样本si的api调用序列apii进行精简,得到每个软件样本si对应的精简后的api调用序列api'i,具体方法为:步骤2.1,对p个软件样本的api调用序列包含的api进行统计分析,将重复的api去除,一共得到n种api,n种api形成的api集合表示为as=<api[1],api[2],...,api[n]>;其中,api[1],api[2],...,api[n]分别代表第1种api,第2种api,...,第n种api;步骤2.2,构造线性模型api权重训练集,方法为:步骤2.2.1,对于每个软件样本si,根据其api调用序列apii=<apii1,apii2,...,apiic>以及集合as=<api[1],api[2],...,api[n]>,构造对应的输入向量xi=<xi1,xi2,...,xin>;其中,输入向量xi中元素数量,与集合as中元素数量相等;输入向量xi的各元素取值为:如果集合as中的api[1]出现在api调用序列apii中,则输入向量xi中第1个元素xi1取值为1;否则,输入向量xi中第1个元素xi1取值为0;如果集合as中的api[2]出现在api调用序列apii中,则输入向量xi中第2个元素xi2取值为1;否则,输入向量xi中第2个元素xi2取值为0;依此类推如果集合as中的api[n]出现在api调用序列apii中,则输入向量xi中第n个元素xin取值为1;否则,输入向量xi中第n个元素xin取值为0;步骤2.2.2,对于软件样本si,定义标签真实值yi;标签真实值yi通过以下方式取值:如果软件样本si为恶意软件样本,则标签真实值yi为1;反之,如果软件样本si为正常软件样本,则标签真实值yi为0;步骤2.2.3,将软件样本si的输入向量xi和标签真实值yi组合,形成软件样本si的训练样本tsi=<xi,yi>=<xi1,xi2,...,xin,yi>;步骤2.2.4,因此,对于p个软件样本,可对应得到p个训练样本,从而形成线性模型api权重训练集;步骤2.3,构建关于api权重的线性模型hθi:hθi=θ0+θ1xi1+θ2xi2+...+θnxin(1)其中:θ0为线性模型常数项;θ1,θ2,...,θn分别为线性模型的系数;构建输出转换模型:其中:y'i为与软件样本si对应的基于api权重的线性模型的标签预测值;步骤2.4,根据线性模型hθi和输出转换模型,对线性模型hθi进行拟合,得到最终的θ0,θ1,θ2,...,θn的值,从而得到最终的关于api权重的线性模型;步骤2.5,对于集合as=<api[1],api[2],...,api[n]>,系数θ1同时表示api[1]的权重,系数θ2同时表示api[2]的权重系数,...,系数θn同时表示api[n]的权重;预设置权重阈值ε0;检查每个系数θj的绝对值是否小于权重阈值ε0,其中,j=1,2,...,n,如果是,则系数θj对应的api[j]为非关键api,并将非关键api存入非关键api字典;设置百分比h,对各个系数θj的绝对值从大到小排序,获得排序最前面的h*n个系数;将获得的h*n个系数所对应的集合as中的api[j]称为关键api,并将关键api存入关键api字典;步骤2.6,对于步骤1收集到的每个软件样本si,将其api调用序列apii=<apii1,apii2,...,apiic>中的非关键api剔除,从而得到软件样本si对应的精简后的api调用序列api'i;步骤3,对于每个软件样本si对应的精简后的api调用序列api'i,均对其api调用序列api'i进行挖掘,得到多个api特征序列,将各个api特征序列存入api特征序列集合c(api),具体方法为:步骤3.1,对于每个软件样本si对应的精简后的api调用序列api'i,定位到关键api,对于定位到的每个关键api,均执行步骤3.2-步骤3.3;步骤3.2,利用确定性前后向扫描方式,提取与定义的窗口尺度对应的api特征序列,并存入api特征序列集合c(api),方法为:预定义窗口尺度为b;利用确定性前后向扫描方式,提取所有种包含关键api的尺度为b的api特征序列;步骤3.3,利用随机性前后向扫描方式,提取与定义的窗口尺度对应的api特征序列,并存入api特征序列集合c(api),方法为:步骤3.3.1,预定义窗口尺度为b;步骤3.3.2,预定义随机截取阈值v*;步骤3.3.3,对于软件样本si,设精简后的api调用序列api'i为:api'i=<api'i1,api'i2,...,api'id>;其中,d为软件样本si对应的精简后的api调用序列api'i中包括的api的总数量;假设api'ik为api'i中的一个关键api;步骤3.3.4,令计数器b0=0,计数器b1=0;a1)进行前向扫描,方法为:按照距离api'ik由近向远的顺序进行前向扫描,首先考察api'i(k-1),考察方法为:随机生成0到1之间的随机数v1,若v1大于阈值v*,则提取api'i(k-1),同时令b0=b0+1;如果v1不大于阈值v*,则不提取api'i(k+1),继续前向考察其他相邻的api';a2)进行后向扫描,方法为:按照距离api'ik由近向远的顺序进行后向扫描,首先考察api'i(k+1),考察方法为:随机生成0到1之间的随机数v2,若v2大于阈值v*,则提取api'i(k+1),同时令b1=b1+1;如果v2不大于阈值v*,则不提取api'i(k+1),继续后向考察其他相邻的api';a3)当前向扫描提取到b0=0个api',而后向扫描提取到b1=b-1个api',则api'ik和后向扫描提取到的b1个api'按顺序排列,形成一种尺度为b的api特征序列;当前向扫描提取到b0=1个api',而后向扫描提取到b1=b-2个api',则前向扫描提取到的b0个api'、api'ik和后向扫描提取到的b1个api'按顺序排列,形成一种尺度为b的api特征序列;依此类推当前向扫描提取到b0=b-1个api',而后向扫描提取到b1=0个api',则前向扫描提取到的b0个api'和api'ik按顺序排列,形成一种尺度为b的api特征序列;因此,以上各种随机性扫描形成的尺度为b的api特征序列,均存入api特征序列集合c(api);步骤4,利用统计频率筛选api特征序列集合c(api)中的各个api特征序列,得到筛选后的api特征序列集合c'(api),方法为:设正常软件样本的总数量为|ns|,对于api特征序列集合c(api)中的每个api特征序列,统计其在所有正常软件样本的精简后的api调用序列中出现的次数f,计算该api特征序列的正常样本覆盖率f/|ns|;如果f/|ns|低于阈值c,则保留该api特征序列;否则,从api特征序列集合c(api)中剔除该api特征序列,进而得到筛选后的api特征序列集合c'(api);步骤5,构造线性模型api特征序列训练集,方法为:步骤5.1,对于筛选后的api特征序列集合c'(api),假设共有w个api特征序列,分别表示为:q1,q2,...,qw,因此,c'(api)=<q1,q2,...,qw>;步骤5.2,对于每个软件样本si,根据其精简后的api调用序列api'i=<api'i1,api'i2,...,api'id>以及c'(api)=<q1,q2,...,qw>,构造对应的输入向量ei=<ei1,ei2,...,eiw>;其中,输入向量ei中元素数量,与集合c'(api)中元素数量相等;输入向量ei的各元素取值为:如果集合c'(api)中的第1个api特征序列,即q1出现在api调用序列api'i中,则输入向量ei中第1个元素ei1取值为1;否则,输入向量ei中第1个元素ei1取值为0;如果集合c'(api)中的第2个api特征序列,即q2出现在api调用序列api'i中,则输入向量ei中第2个元素ei2取值为1;否则,输入向量ei中第2个元素ei2取值为0;依此类推如果集合c'(api)中的第w个api特征序列,即qw出现在api调用序列api'i中,则输入向量ei中第w个元素eiw取值为1;否则,输入向量ei中第w个元素eiw取值为0;步骤5.3,对于软件样本si,定义标签真实值yi;标签真实值yi通过以下方式取值:如果软件样本si为恶意软件样本,则标签真实值yi为1;反之,如果软件样本si为正常软件样本,则标签真实值yi为0;步骤5.4,将软件样本si的输入向量ei和标签真实值yi组合,形成软件样本si的api特征序列训练样本qsi=<ei,yi>=<ei1,ei2,...,eiw,yi>;因此,对于p个软件样本,可对应得到p个api特征序列训练样本,从而形成线性模型api特征序列权重训练集;步骤6,构建关于api特征序列权重的线性模型hβi;hβi=β0+β1ei1+β2ei2+...+βweiw(3)其中:β0为线性模型常数项;β1,β2,...,βw分别为线性模型的系数;构建输出转换模型:其中:f'i为与软件样本si对应的基于api特征序列权重的线性模型的标签预测值;步骤7,根据线性模型hβi和输出转换模型,对线性模型hβi进行拟合,并在拟合过程中不断精简api特征序列集合c'(api),从而得到最终的关键api特征序列集合以及关于关键api特征序列权重的线性模型,具体方法为:步骤7.1,根据线性模型hβi和输出转换模型,对线性模型hβi进行n轮迭代拟合,得到β0,β1,β2,...,βw的拟合值;步骤7.2,对于每个api特征序列训练样本qsi=<ei,yi>=<ei1,ei2,...,eiw,yi>,将ei1,ei2,...,eiw、β0,β1,β2,...,βw的值代入公式(3),计算得到hβi;步骤7.3,根据公式(4),得到api特征序列训练样本qsi的标签预测值f'i;步骤7.4,比较api特征序列训练样本qsi的标签真实值yi与标签预测值f'i,如果标签真实值yi与标签预测值f'i相等,代表线性模型hβi对api特征序列训练样本qsi预测正确,令统计量di为1;反之,代表线性模型hβi对api特征序列训练样本qsi预测错误,令统计量di为0;步骤7.5,对于步骤5.4得到的训练样本集中的每个训练样本,均执行步骤7.1-步骤7.4,由于共有p个训练样本,可计算得到p个统计量di;计算拟合度如果本轮拟合度ε1低于上一轮拟合度,且两者差值大于阈值η,则停止迭代,执行步骤7.6;否则,假设本轮得到的β0,β1,β2,...,βw表示为:β^0,β^1,β^2,...,β^w;预设置序列权重阈值ε2;检查系数β^1,β^2,...,β^w中每个系数β^z的值是否小于序列权重阈值ε2,其中,z=0,1,2,...,w,如果是,则将系数β^z对应的api特征序列qz从api特征序列集合c'(api)中删除,从而得到精简后的api特征序列集合c"(api);然后,用精简后的api特征序列集合c"(api)替换上一轮得到的api特征序列集合c'(api),返回步骤6,重新执行步骤6、步骤7.1-步骤7.5;步骤7.6,将上一轮得到的api特征序列集合称为关键api特征序列集合,设关键api特征序列集合共包括个关键api特征序列,分别为q*1,q*2,...,因此得到关键api特征序列集合对应的,上一轮得到的q*1,q*2,...,分别对应的权重系数为:β*1,β*2,...,由此得到最终的关于关键api特征序列权重的线性模型步骤8,利用最终得到的关于关键api特征序列权重的线性模型以及关键api特征序列集合检测被测软件是否为恶意软件,方法为:步骤8.1,获得被测软件的api调用序列m1(api);步骤8.2,利用步骤2构造的非关键api字典,将api调用序列m1(api)中的非关键api删除,得到精简后的api调用序列m2(api);步骤8.3,通过前后向扫描,获得步骤7得到的关键api特征序列集合中各关键api特征序列的状态变量值,具体的:如果关键api特征序列q*1出现在精简后的api调用序列m2(api)中,则关键api特征序列q*1的状态变量x1取值为1,否则,状态变量x1取值为0;如果关键api特征序列q*2出现在精简后的api调用序列m2(api)中,则关键api特征序列q*2的状态变量x2取值为1,否则,状态变量x2取值为0;依此类推如果关键api特征序列出现在精简后的api调用序列m2(api)中,则关键api特征序列的状态变量取值为1,否则,状态变量取值为0;由此得到状态变量x1,x2,...,的值;状态变量x1,x2,...,物理含义为:分别为关键api特征序列q*1,关键api特征序列q*2,...,关键api特征序列的权重值;步骤8.4,组合关键api特征序列q*1,q*2,...,的状态变量值,构造得到输入向量步骤8.5,将输入向量输入到步骤7得到的线性模型即公式(5),得到如果则被测软件为恶意软件;如果则被测软件为正常软件。优选的,步骤2.4具体为:步骤2.4.1,预设置θ0,θ1,θ2,...,θn的初始值;步骤2.4.2,对于每个训练样本tsi=<xi,yi>=<xi1,xi2,...,xin,yi>,将xi1,xi2,...,xin、θ0,θ1,θ2,...,θn的值代入公式(1),计算得到hθi;步骤2.4.3,根据公式(2),得到训练样本tsi的标签预测值y'i;步骤2.4.4,比较训练样本tsi的标签真实值yi与标签预测值y'i,如果标签真实值yi与标签预测值y'i相等,代表线性模型hθi对训练样本tsi预测正确,令统计量ai为1;反之,代表线性模型hθi对训练样本tsi预测错误,令统计量ai为0;步骤2.4.5,对于步骤2.2.4得到的训练样本集中的每个训练样本,均执行步骤2.4.2-步骤2.4.4,由于共有p个训练样本,可计算得到p个统计量ai;计算拟合度如果拟合度ε大于拟合度阈值η0,则停止迭代,此时得到的θ0,θ1,θ2,...,θn为最终的θ0,θ1,θ2,...,θn的值;如果拟合度ε不大于拟合度阈值η0,则调节θ0,θ1,θ2,...,θn的值,返回步骤2.4.2,重新进行拟合,直到拟合度ε大于拟合度阈值η0。本发明提供的一种基于特征序列挖掘和精简的恶意软件检测方法具有以下优点:本发明提供的基于特征序列挖掘和精简的恶意软件检测方法,为一种基于软件行为的动态检测方法,本发明同时采用api特征序列精简和关键api扩展扫描这两项技术,提升了api特征序列的挖掘效率,从而能够全面得到更能反映恶意软件行为特征的api特征序列,既提高了恶意软件检测识别精度,又缩短了恶意软件检测识别耗费的时间,提高恶意软件检测识别效率。附图说明图1为本发明提供的一种基于特征序列挖掘和精简的恶意软件检测方法的流程示意图。具体实施方式为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。本发明提供一种基于特征序列挖掘和精简的恶意软件检测方法,一方面,通过恶意软件行为特征,即:关键api调用序列特征对恶意软件进行检测识别,由于为一种动态检测方法,可有效提高恶意软件检测识别准确度;另一方面,本发明对恶意软件api调用序列特征进行有效精简,提高恶意软件检测识别速度,以满足对恶意软件检测速度要求高的需求。本发明提供一种基于特征序列挖掘和精简的恶意软件检测方法,主要思路为:1、获得多个软件样本的api调用序列;2、构造关键api字典和非关键api字典,从而对每个软件样本的api调用序列进行精简;3、利用确定性和随机化前后向扫描方式,提取各个软件样本的api特征序列,得到api特征序列集合c(api);4、采用统计频率筛选api特征序列集合c(api)中的各个api特征序列,得到筛选后的api特征序列集合c'(api);5、构造线性模型api特征序列训练集;6、构建关于api特征序列权重的线性模型和输出转换模型;7、根据api特征序列权重的线性模型和输出转换模型,对线性模型进行拟合,并在拟合过程中不断精简api特征序列集合c'(api),从而得到最终的关键api特征序列集合以及关于关键api特征序列权重的线性模型;8、利用最终得到的关于关键api特征序列权重的线性模型以及关键api特征序列集合检测被测软件是否为恶意软件。参考图1,本发明提供的基于特征序列挖掘和精简的恶意软件检测方法,具体包括以下步骤:步骤1,收集p个软件样本,分别为软件样本s1,s2,...,sp;其中,所述软件样本包括恶意软件样本和正常软件样本;对于收集到的每个软件样本si,i=1,2,...,p,获得其api调用序列apii=<apii1,apii2,...,apiic>;其中,c为软件样本si对应的api调用序列中包括的api的总数量;在具体实现上,可采用以下方式实现:1)针对kvm虚拟技术被云数据中心大规模采用的情况,搭建kvm虚拟化环境并配置linux虚拟机。2)为了更好地模拟云应用环境,在linux虚拟机安装hadoop软件和spark平台。3)在linux虚拟机上基于cuckoo沙箱软件搭建恶意软件动态分析环境。4)将收集到的恶意软件样本集和正常软件样本集中的软件样本,逐个载入cuckoo沙箱环境中运行。5)根据cuckoo沙箱输出的运行报告json文件,提取每个软件样本的api调用序列作为软件样本的动态特征。步骤2,构造关键api字典和非关键api字典,从而对每个软件样本si的api调用序列apii进行精简,得到每个软件样本si对应的精简后的api调用序列api'i,本步骤的目的是:步骤1提取的软件样本的api调用序列规模庞大,如果直接进行api特征序列挖掘,计算量大,无法在大型样本库上进行有效挖掘。由于各种api调用序列中存在较多数量的普通api调用序列,这对于识别软件是否为恶意软件不能起到作用,因此,可以将这些普通api调用序列剔除,从而实现对api调用序列的精简,提升后面步骤中api调用序列挖掘的效率。具体方法为:步骤2.1,对p个软件样本的api调用序列包含的api进行统计分析,将重复的api去除,一共得到n种api,n种api形成的api集合表示为as=<api[1],api[2],...,api[n]>;其中,api[1],api[2],...,api[n]分别代表第1种api,第2种api,...,第n种api;步骤2.2,构造线性模型api权重训练集,方法为:步骤2.2.1,对于每个软件样本si,根据其api调用序列apii=<apii1,apii2,...,apiic>以及集合as=<api[1],api[2],...,api[n]>,构造对应的输入向量xi=<xi1,xi2,...,xin>;其中,输入向量xi中元素数量,与集合as中元素数量相等;输入向量xi的各元素取值为:如果集合as中的api[1]出现在api调用序列apii中,则输入向量xi中第1个元素xi1取值为1;否则,输入向量xi中第1个元素xi1取值为0;如果集合as中的api[2]出现在api调用序列apii中,则输入向量xi中第2个元素xi2取值为1;否则,输入向量xi中第2个元素xi2取值为0;依此类推如果集合as中的api[n]出现在api调用序列apii中,则输入向量xi中第n个元素xin取值为1;否则,输入向量xi中第n个元素xin取值为0;由此可以看出,输入向量xi中各个元素,是刻画集合as中对应api的布尔变量,取值为1或0。步骤2.2.2,对于软件样本si,定义标签真实值yi;标签真实值yi通过以下方式取值:如果软件样本si为恶意软件样本,则标签真实值yi为1;反之,如果软件样本si为正常软件样本,则标签真实值yi为0;步骤2.2.3,将软件样本si的输入向量xi和标签真实值yi组合,形成软件样本si的训练样本tsi=<xi,yi>=<xi1,xi2,...,xin,yi>;例如:假设n=4,则集合as=<api[1],api[2],api[3],api[4]>;对于某个软件样本,通过步骤1获得其api调用序列为<api[2],api[3],api[2],api[3],api[1]>;则该软件样本的输入向量为:x=<x1,x2,x3,x4>=<1,1,1,0>。其标签真实值y与软件样本类型有关,如果软件样本是恶意软件,则标签真实值y为1;如果软件样本是正常软件,则标签真实值y为0。步骤2.2.4,因此,对于p个软件样本,可对应得到p个训练样本,从而形成线性模型api权重训练集;步骤2.3,构建关于api权重的线性模型hθi:hθi=θ0+θ1xi1+θ2xi2+...+θnxin(1)其中:θ0为线性模型常数项;θ1,θ2,...,θn分别为线性模型的系数;构建输出转换模型:其中:y'i为与软件样本si对应的基于api权重的线性模型的标签预测值;步骤2.4,根据线性模型hθi和输出转换模型,对线性模型hθi进行拟合,得到最终的θ0,θ1,θ2,...,θn的值,从而得到最终的关于api权重的线性模型;步骤2.4具体为:步骤2.4.1,预设置θ0,θ1,θ2,...,θn的初始值;步骤2.4.2,对于每个训练样本tsi=<xi,yi>=<xi1,xi2,...,xin,yi>,将xi1,xi2,...,xin、θ0,θ1,θ2,...,θn的值代入公式(1),计算得到hθi;步骤2.4.3,根据公式(2),得到训练样本tsi的标签预测值y'i;步骤2.4.4,比较训练样本tsi的标签真实值yi与标签预测值y'i,如果标签真实值yi与标签预测值y'i相等,代表线性模型hθi对训练样本tsi预测正确,令统计量ai为1;反之,代表线性模型hθi对训练样本tsi预测错误,令统计量ai为0;步骤2.4.5,对于步骤2.2.4得到的训练样本集中的每个训练样本,均执行步骤2.4.2-步骤2.4.4,由于共有p个训练样本,可计算得到p个统计量ai;计算拟合度如果拟合度ε大于拟合度阈值η0,则停止迭代,此时得到的θ0,θ1,θ2,...,θn为最终的θ0,θ1,θ2,...,θn的值;如果拟合度ε不大于拟合度阈值η0,则调节θ0,θ1,θ2,...,θn的值,返回步骤2.4.2,重新进行拟合,直到拟合度ε大于拟合度阈值η0。步骤2.5,对于集合as=<api[1],api[2],...,api[n]>,系数θ1同时表示api[1]的权重,系数θ2同时表示api[2]的权重系数,...,系数θn同时表示api[n]的权重;例如,以系数θ1为例,系数θ1的绝对值越大,系数θ1对线性模型输出值影响就越大,所以,系数θ1对应集合as中api[1]的权重越大。预设置权重阈值ε0;例如,设置ε0等于0.005。检查每个系数θj的绝对值是否小于权重阈值ε0,其中,j=1,2,...,n,如果是,则系数θj对应的api[j]为非关键api,并将非关键api存入非关键api字典;设置百分比h,对各个系数θj的绝对值从大到小排序,获得排序最前面的h*n个系数;将获得的h*n个系数所对应的集合as中的api[j]称为关键api,并将关键api存入关键api字典;通过以上方法,非关键api字典中存储的各个非关键api,是指对识别软件样本是否为恶意软件影响非常小的普遍api,不能反映恶意软件行为特征;而关键api字典中存储的各个关键api,是指对识别软件样本是否为恶意软件影响非常大的api,能反映恶意软件行为特征。步骤2.6,对于步骤1收集到的每个软件样本si,将其api调用序列apii=<apii1,apii2,...,apiic>中的非关键api剔除,从而得到软件样本si对应的精简后的api调用序列api'i;例如:假设n=4,则集合as=<api[1],api[2],api[3],api[4]>;对于某个软件样本,通过步骤1获得其api调用序列为<api[2],api[3],api[2],api[3],api[1]>;步骤2获得非关键api字典nk=<api[2]>则该软件样本对应的精简后的api调用序列api'i为:<api[3],api[3],api[1]>。通过实验可知,设置ε0等于0.005,通过剔除非关键api,软件样本的api调用序列的大小可以压缩到原来的10%左右,大大减少了大规模数据集的计算量,并且对恶意软件的识别准确度没有产生影响。步骤3,对于每个软件样本si对应的精简后的api调用序列api'i,均对其api调用序列api'i进行挖掘,得到多个api特征序列,将各个api特征序列存入api特征序列集合c(api);本步骤的目的是:步骤1提取的api调用序列的数量非常多,规模庞大,如果直接枚举式扫描进行api特征序列挖掘,计算量大,无法在大型样本库上进行高效挖掘。因此,本发明中,利用步骤2获得的关键api,围绕关键api对每个api调用序列进行前后向扫描,从而只提取包含关键api的api特征序列,此时得到的api特征序列的数量明显降低,从而提高api特征序列的挖掘效率,同时,提取到的api特征序列可充分反应恶意软件样本行为特征,进而不会影响恶意软件样本识别的准确度。例如,常常遇到的恶意软件围绕的关键api是urldownloadtofile,用于payload下载。常常遇到的间谍软件或键盘记录器等恶意软件围绕的关键api是getwindowdc,用于屏幕截取。所以,只需要获得包含关键api的api特征序列,即可充分反应恶意软件样本行为特征。本步骤具体方法为:步骤3.1,对于每个软件样本si对应的精简后的api调用序列api'i,定位到关键api,对于定位到的每个关键api,均执行步骤3.2-步骤3.3;步骤3.2,利用确定性前后向扫描方式,提取与定义的窗口尺度对应的api特征序列,并存入api特征序列集合c(api),方法为:预定义窗口尺度为b;利用确定性前后向扫描方式,提取所有种包含关键api的尺度为b的api特征序列;例如,针对某个软件样本,步骤2获得精简后的api调用序列api'=<api[1],api[3],api[5],api[4],api[7]api[11],api[13],api[2],api[9],api[21]>;步骤2获得关键api字典dk=<api[11]>;如果窗口尺度为1,扫描精简后的api调用序列api',提取到的api特征序列为<api[11]>。如果窗口尺度为2,扫描精简后的api调用序列api',提取到的api特征序列共有两个,分别为:<api[7],api[11]>和<api[11],api[13]>。如果窗口尺度为3,扫描精简后的api调用序列api',提取到的api特征序列共有三个,分别为:<api[7],api[11],api[13]>,<api[4],api[7],api[11]>和<api[11],api[13],api[2]>。窗口尺度最大值为可配置的参数,通常可以设置b等于5。特别的,针对垃圾代码注入式恶意软件,本发明尤其设计以下步骤3.3中的随机化前向和后向多尺度窗口提取方式,从而提取不同尺度的api特征序列。步骤3.3,利用随机性前后向扫描方式,提取与定义的窗口尺度对应的api特征序列,并存入api特征序列集合c(api),方法为:步骤3.3.1,预定义窗口尺度为b;步骤3.3.2,预定义随机截取阈值v*;步骤3.3.3,对于软件样本si,设精简后的api调用序列api'i为:api'i=<api'i1,api'i2,...,api'id>;其中,d为软件样本si对应的精简后的api调用序列api'i中包括的api的总数量;假设api'ik为api'i中的一个关键api;步骤3.3.4,令计数器b0=0,计数器b1=0;a1)进行前向扫描,方法为:按照距离api'ik由近向远的顺序进行前向扫描,首先考察api'i(k-1),考察方法为:随机生成0到1之间的随机数v1,若v1大于阈值v*,则提取api'i(k-1),同时令b0=b0+1;如果v1不大于阈值v*,则不提取api'i(k+1),继续前向考察其他相邻的api';a2)进行后向扫描,方法为:按照距离api'ik由近向远的顺序进行后向扫描,首先考察api'i(k+1),考察方法为:随机生成0到1之间的随机数v2,若v2大于阈值v*,则提取api'i(k+1),同时令b1=b1+1;如果v2不大于阈值v*,则不提取api'i(k+1),继续后向考察其他相邻的api';a3)当前向扫描提取到b0=0个api',而后向扫描提取到b1=b-1个api',则api'ik和后向扫描提取到的b1个api'按顺序排列,形成一种尺度为b的api特征序列;当前向扫描提取到b0=1个api',而后向扫描提取到b1=b-2个api',则前向扫描提取到的b0个api'、api'ik和后向扫描提取到的b1个api'按顺序排列,形成一种尺度为b的api特征序列;依此类推当前向扫描提取到b0=b-1个api',而后向扫描提取到b1=0个api',则前向扫描提取到的b0个api'和api'ik按顺序排列,形成一种尺度为b的api特征序列;因此,以上各种随机性扫描形成的尺度为b的api特征序列,均存入api特征序列集合c(api);例如,针对某个软件样本,步骤2获得精简后的api调用序列api'=<api[1],api[3],api[5],api[4],api[7],api[11],api[13],api[2],api[9],api[21]>;步骤2获得关键api字典dk=<api[11]>;如果窗口尺度为3,则以下扫描方法如果可以实现,均需要采用:1)前向扫描:11)首先考察api[7],考察方法为:随机生成0到1之间的随机数v1,若v1大于阈值v*,则提取api[7],同时令b0=b0+1;如果v1不大于阈值v*,则不提取api[7],继续向前考察api[4];12)然后考察api[4],考察方法同样为:随机生成0到1之间的随机数v3,若v3大于阈值v*,则提取api[4],同时令b0=b0+1;如果v3不大于阈值v*,则不提取api[4];以此类推,进行前向扫描。2)后向扫描:21)首先考察api[13],考察方法为:随机生成0到1之间的随机数v2,若v2大于阈值v*,则提取api[13],同时令b1=b1+1;如果v2不大于阈值v*,则不提取api[13],继续向后考察api[2];22)然后考察api[2],考察方法同样为:随机生成0到1之间的随机数v4,若v4大于阈值v*,则提取api[2],同时令b0=b0+1;如果v4不大于阈值v*,则不提取api[2];以此类推,进行后向扫描。由于关键api在精简后的api调用序列中的位置不同,所以前向扫描可提取到的api数量以及后向扫描可提取到的api数量,均需要根据实际情况而有所不同。因此,只要满足以下条件,均需要提取对应的一种api特征序列:a1)如果后向扫描可成功提取到2个api,则api[11]和后向扫描提取到的2个api,组成尺度为3的一种api特征序列;a2)如果前向扫描成功提取到1个api,而后向扫描成功提取到1个api,则前向扫描提取到的1个api、api[11]和后向扫描提取到的1个api,组成尺度为3的一种api特征序列;a3)如果前向扫描能够成功提取到2个api,则前向扫描提取到的2个api和api[11],组成尺度为3的一种api特征序列。由此共得到3种api特征序列。需要注意的是,由于随机化阈值v*较小,所以随机化截取的api特征序列,大概率和步骤3.2中确定性截取的api特征序列相同。通过实验可知,设置阈值v*等于0.2时,采用确定性+随机化两种截取策略提取到的api特征序列总数,只比仅采用确定性截取策略提取到的api特征序列总数,增加不超过25%的api特征序列。本发明中,阈值v*是可配置参数,通常可以设置阈值v*等于0.2。当窗口尺度b设置较大时,获得的api特征序列数量庞大,可以进一步利用步骤4的统计频率筛选方式,对api特征序列进一步筛选。步骤4,利用统计频率筛选api特征序列集合c(api)中的各个api特征序列,得到筛选后的api特征序列集合c'(api),方法为:设正常软件样本的总数量为|ns|,对于api特征序列集合c(api)中的每个api特征序列,统计其在所有正常软件样本的精简后的api调用序列中出现的次数f,计算该api特征序列的正常样本覆盖率f/|ns|;如果f/|ns|低于阈值c,则保留该api特征序列;否则,从api特征序列集合c(api)中剔除该api特征序列,进而得到筛选后的api特征序列集合c'(api);如果一个api特征序列在大部分正常软件样本中都出现,则该api特征序列不能作为恶意软件的行为特征序列。所以,只有当某个api特征序列的正常软件样本覆盖率低于阈值时,才能作为有效api特征序列,所以才保留该api特征序列。通过实验可知,设置阈值c=10%,经过该步骤,api特征序列的数量可以压缩12.5%,能够有效减少大规模数据集的计算负荷。步骤5,构造线性模型api特征序列训练集,方法为:步骤5.1,对于筛选后的api特征序列集合c'(api),假设共有w个api特征序列,分别表示为:q1,q2,...,qw,因此,c'(api)=<q1,q2,...,qw>;步骤5.2,对于每个软件样本si,根据其精简后的api调用序列api'i=<api'i1,api'i2,...,api'id>以及c'(api)=<q1,q2,...,qw>,构造对应的输入向量ei=<ei1,ei2,...,eiw>;其中,输入向量ei中元素数量,与集合c'(api)中元素数量相等;输入向量ei的各元素取值为:如果集合c'(api)中的第1个api特征序列,即q1出现在api调用序列api'i中,则输入向量ei中第1个元素ei1取值为1;否则,输入向量ei中第1个元素ei1取值为0;如果集合c'(api)中的第2个api特征序列,即q2出现在api调用序列api'i中,则输入向量ei中第2个元素ei2取值为1;否则,输入向量ei中第2个元素ei2取值为0;依此类推如果集合c'(api)中的第w个api特征序列,即qw出现在api调用序列api'i中,则输入向量ei中第w个元素eiw取值为1;否则,输入向量ei中第w个元素eiw取值为0;步骤5.3,对于软件样本si,定义标签真实值yi;标签真实值yi通过以下方式取值:如果软件样本si为恶意软件样本,则标签真实值yi为1;反之,如果软件样本si为正常软件样本,则标签真实值yi为0;例如,筛选后的api特征序列集合c'(api)中,假设共有4个api特征序列,因此,c'(api)=<q1,q2,q3,q4>;其中,q1=<api[2],api[3]>;q2=<api[1]>;q3=<api[4]>;q1=<api[2],api[3],api[2]>对于某个软件样本,步骤2获得的api调用序列api'i为<api[2],api[3],api[2],api[3],api[1]>;则该软件样本的输入向量e=<e1,e2,e3,e4>=<1,1,0,1>;其标签真实值y与软件样本类型有关,如果软件样本是恶意软件,则标签真实值y为1;如果软件样本是正常软件,则标签真实值y为0。步骤5.4,将软件样本si的输入向量ei和标签真实值yi组合,形成软件样本si的api特征序列训练样本qsi=<ei,yi>=<ei1,ei2,...,eiw,yi>;因此,对于p个软件样本,可对应得到p个api特征序列训练样本,从而形成线性模型api特征序列权重训练集;步骤6,构建关于api特征序列权重的线性模型hβi;hβi=β0+β1ei1+β2ei2+...+βweiw(3)其中:β0为线性模型常数项;β1,β2,...,βw分别为线性模型的系数;构建输出转换模型:其中:f'i为与软件样本si对应的基于api特征序列权重的线性模型的标签预测值;步骤7,根据线性模型hβi和输出转换模型,对线性模型hβi进行拟合,并在拟合过程中不断精简api特征序列集合c'(api),从而得到最终的关键api特征序列集合以及关于关键api特征序列权重的线性模型,具体方法为:步骤7.1,根据线性模型hβi和输出转换模型,采用步骤2.4的方法,对线性模型hβi进行n轮迭代拟合,得到β0,β1,β2,...,βw的拟合值;步骤7.2,对于每个api特征序列训练样本qsi=<ei,yi>=<ei1,ei2,...,eiw,yi>,将ei1,ei2,...,eiw、β0,β1,β2,...,βw的值代入公式(3),计算得到hβi;步骤7.3,根据公式(4),得到api特征序列训练样本qsi的标签预测值f'i;步骤7.4,比较api特征序列训练样本qsi的标签真实值yi与标签预测值f'i,如果标签真实值yi与标签预测值f'i相等,代表线性模型hβi对api特征序列训练样本qsi预测正确,令统计量di为1;反之,代表线性模型hβi对api特征序列训练样本qsi预测错误,令统计量di为0;步骤7.5,对于步骤5.4得到的训练样本集中的每个训练样本,均执行步骤7.1-步骤7.4,由于共有p个训练样本,可计算得到p个统计量di;计算拟合度如果本轮拟合度ε1低于上一轮拟合度,且两者差值大于阈值η,则停止迭代,执行步骤7.6;否则,假设本轮得到的β0,β1,β2,...,βw表示为:β^0,β^1,β^2,...,β^w;预设置序列权重阈值ε2;检查系数β^1,β^2,...,β^w中每个系数β^z的值是否小于序列权重阈值ε2,其中,z=0,1,2,...,w,如果是,则将系数β^z对应的api特征序列qz从api特征序列集合c'(api)中删除,从而得到精简后的api特征序列集合c"(api);然后,用精简后的api特征序列集合c"(api)替换上一轮得到的api特征序列集合c'(api),返回步骤6,重新执行步骤6、步骤7.1-步骤7.5;步骤7.6,将上一轮得到的api特征序列集合称为关键api特征序列集合,设关键api特征序列集合共包括个关键api特征序列,分别为q*1,q*2,...,因此得到关键api特征序列集合对应的,上一轮得到的q*1,q*2,...,分别对应的权重系数为:β*1,β*2,...,由此得到最终的关于关键api特征序列权重的线性模型步骤8,利用最终得到的关于关键api特征序列权重的线性模型以及关键api特征序列集合检测被测软件是否为恶意软件,方法为:步骤8.1,获得被测软件的api调用序列m1(api);步骤8.2,利用步骤2构造的非关键api字典,将api调用序列m1(api)中的非关键api删除,得到精简后的api调用序列m2(api);步骤8.3,通过前后向扫描,获得步骤7得到的关键api特征序列集合中各关键api特征序列的状态变量值,具体的:如果关键api特征序列q*1出现在精简后的api调用序列m2(api)中,则关键api特征序列q*1的状态变量x1取值为1,否则,状态变量x1取值为0;如果关键api特征序列q*2出现在精简后的api调用序列m2(api)中,则关键api特征序列q*2的状态变量x2取值为1,否则,状态变量x2取值为0;依此类推如果关键api特征序列出现在精简后的api调用序列m2(api)中,则关键api特征序列的状态变量取值为1,否则,状态变量取值为0;由此得到状态变量x1,x2,...,的值;状态变量x1,x2,...,物理含义为:分别为关键api特征序列q*1,关键api特征序列q*2,...,关键api特征序列的权重值;步骤8.4,组合关键api特征序列q*1,q*2,...,的状态变量值,构造得到输入向量步骤8.5,将输入向量输入到步骤7得到的线性模型即公式(5),得到如果则被测软件为恶意软件;如果则被测软件为正常软件。本发明提供的一种基于特征序列挖掘和精简的恶意软件检测方法,具有以下特点:(1)本发明提供的基于特征序列挖掘和精简的恶意软件检测方法,为一种基于软件行为的动态检测方法,本发明同时采用api特征序列精简和关键api扩展扫描这两项技术,提升了api特征序列的挖掘效率,从而能够全面得到更能反映恶意软件行为特征的api特征序列,既提高了恶意软件检测识别精度,又缩短了恶意软件检测识别耗费的时间,提高恶意软件检测识别效率。(2)在api特征序列挖掘过程中,采用多尺度挖掘方法会导致api特征序列规模庞大,同时多尺度挖掘中的api特征序列嵌入重叠现象,也使得svm和神经网络等分类模型容易产生过拟合。而本发明采用基于线性模型通过多次迭代进行api特征序列筛选,提升了模型的泛化能力。实施例:实验样本来源于某安全算法大赛使用的数据集,包括7类典型类别的恶意软件样本和正常软件样本。其中,7类恶意软件样本分别是:勒索病毒软件(98个)、挖矿软件(107个)、ddos木马软件(185个)、蠕虫病毒软件(95个)、感染性病毒软件(221个)、后门和特洛伊木马软件(164个)。实验采用的正常软件样本是从操作系统linux,windows和虚拟机软件vmware等软件包中提取的软件文件(2000个)。(1)实施步骤1,利用沙箱技术获得各个软件样本的api调用序列。获得的各个软件样本的api调用序列的统计数据如表1所示。表1api调用序列平均长度勒索病毒软件136765挖矿软件2785781ddos木马软件786875蠕虫病毒软件9877875感染性病毒软件635471后门和特洛伊木马软件6768390正常软件7663785(2)实施步骤2,设置实验参数ε0=0.005,百分比h=10%,获得关键api字典和非关键api字典,字典大小如表2所示。表2继续实施步骤2,利用获得的非关键api字典,对各个软件样本的api调用序列进行精简。精简后的api调用序列的统计数据如表3所示。表3精简之后api调用序列平均长度压缩效果勒索病毒软件1671612.22%挖矿软件1851786.65%ddos木马软件468175.95%蠕虫病毒软件2771872.81%感染性病毒软件351495.53%后门和特洛伊木马软件1681302.48%正常软件126137716.46%根据以上实验数据可知,设置ε0=0.005情况下,通过剔除非关键api,软件样本的api调用序列的大小可以压缩到原来的10%左右,大大减少了大规模数据集的计算负荷。(3)实施步骤3,针对步骤2获得软件样本的api调用序列,围绕关键api,采用确定性和随机性前向和后向多尺度窗口截取方式,提取不同尺度的api特征序列。设置确定性扫描窗口尺度最大值b=5,随机性扫描阈值v*=0.2情况下,获得的api特征序列数量如表4所示。表4从表中数据可知,设置阈值v*=0.2时,采用确定性+随机化的两种截取策略获得的api特征序列总数,只比仅采用确定性截取策略获得的api特征序列总数,增加不超过25%的特征序列。(4)继续实施步骤4,设置阈值c=10%,利用统计频率进行api特征序列筛选。筛选之后的api特征序列统计数据如表5所示。表5根据实验数据可知,筛选之后的api特征序列数量为筛选之前的80%左右,能够缓解大规模数据集的计算负荷。(5)实施步骤5-步骤7,利用线性模型迭代构造最优化检测分类模型和关键api特征序列集合。实验过程中,设置η=0.5%,一共实施5轮优化,每一轮优化结果如表6所示。表6从实验数据可知,每一轮迭代中,由于api特征序列的剔除,api特征序列集合中包含的api特征序列数量会减少。在前三轮迭代过程中,线性模型的拟合度不断提升,其原因是:这三轮剔除的都是非关键的api特征序列,通过排除非关键api特征序列的干扰,检测分类模型能够更好的利用关键api特征序列进行预测分类,所以拟合度不断提升。第4轮中,被剔除的api特征序列中有少量关键api特征序列,所以模型的拟合度下降,但是由于仅仅降低0.3%,小于阈值0.5%,所以允许进行第5轮迭代。显然第5轮中,被剔除的api特征序列中有大量关键api特征序列,所以拟合度急剧下降,下降值超过阈值0.5%。此时迭代停止。并且将前一轮,即第4轮获得线性模型作为最优的检测分类模型,获得的api特征序列集合作为关键api特征序列集合。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1