基于无监督孤立点检测的医保反欺诈监测分析方法和系统与流程
本发明涉及医保反欺诈监测领域,尤其是一种基于无监督孤立点检测的医保反欺诈监测分析方法。
背景技术:
医疗保险欺诈是公民、法人或者其他组织违反医疗保险管理法规和政策,弄虚作假、隐瞒真实情况等,骗取医疗保险待遇或医疗保险基金的行为。医疗保险基金欺诈案频繁发生,对医疗保险制度运行和发展危害巨大。医疗保险损失巨大,在地区都是亟待解决的难题。
医疗保险体系涉及多个利益主体,相对于其他险种而言复杂的多,主要包括医疗供方(医院、药店等)、医疗需方(参保者)、医保管理部门(经办机构和监督机构)。由于涉及的环节多、链条长、风险点多,如果方法基金风险的措施做得不全面,就容易滋生医保欺诈、骗保问题。当前的医保欺诈主体可分为医疗机构的欺诈、参加医疗保险的欺诈(参保人欺诈)和医患合谋欺诈。
医疗数据库中包含可靠、透明标准的医疗信息,大数据时代,将所有医疗相关数据,包括患者的诊断治疗信息、就诊记录、个人基本信息、参保情况和药品器械使用信息等数据。利用海量的医疗数据建立有效的医保欺诈预警模型,为医保中心实施监管的工作提供决策支持,是当前要解决的首要任务。
医保反欺诈稽查不仅需要大量的人力、物力、财力和时间,还需要持续不断的技术支持。我国当前医保反欺诈的技术还停留在依靠黑名单和规则库监控管理医保基金的安全。黑名单是医保监察管理部门已经查出来的欺诈行为,并将其纳入医保欺诈黑名单里的一种反欺诈技术方法。但这种方法有两个致命的缺陷,一个是后置性,必须在监察人员查处后再将其放入黑名单,缺少提前预警机制。另一个是缺少动态管理,即进入黑名单里的案例,将永久在黑名单里,当该案例行为正常时,缺少机动性管理,将其拉出黑名单。
技术实现要素:
本发明的目的在于克服现有技术中存在的不足,提供一种基于无监督孤立点检测的医保反欺诈监测分析方法和系统,能够帮助相关机构更好地识别参保人的医保欺诈行为,采用集成思想,提高系统的泛化能力和准确率。
本发明的第一方面,提供一种基于无监督孤立点检测的医保反欺诈监测分析方法,包括以下步骤:
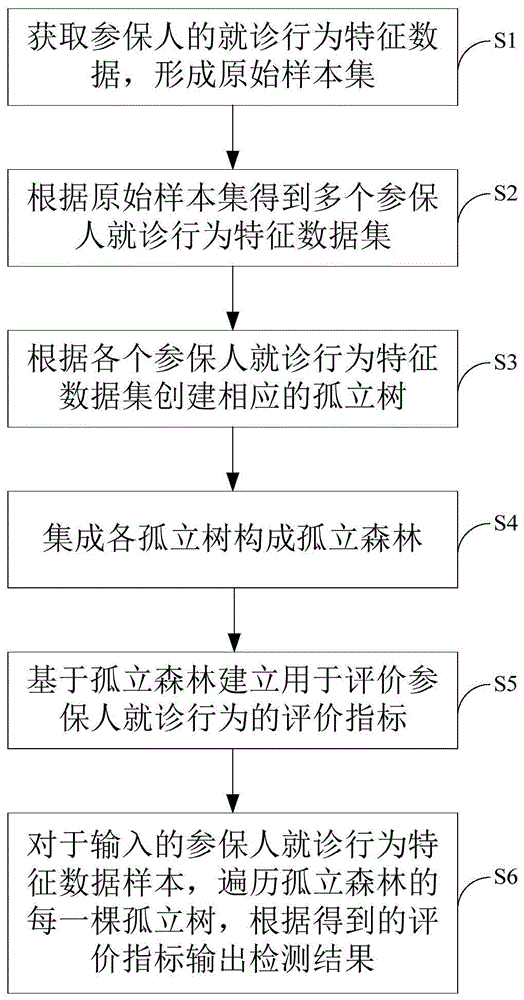
步骤s1,获取参保人的就诊行为特征数据,形成原始样本集;
步骤s2,根据原始样本集得到多个参保人就诊行为特征数据集;
步骤s3,根据各个参保人就诊行为特征数据集创建相应的孤立树;
步骤s4,集成各孤立树构成孤立森林;
步骤s5,基于孤立森林建立用于评价参保人就诊行为的评价指标;
步骤s6,对于输入的参保人就诊行为特征数据样本,遍历孤立森林的每一棵孤立树,根据得到的评价指标输出检测结果。
进一步地,步骤s3具体包括:
样本数据集x={x1,x2……xn}为参保人就诊行为特征数据集;其中
s301,从x中随机抽取
s302,从d个维度中随机指定一个维度q,在当前子集中随机产生一个分割点p,min(xij,j=q,xij∈x’)<p<max(xij,j=q,xij∈x’);
s303,此分割点p生成一个超平面,将当前数据空间划分为两个子空间:指定维度对应的值小于p的样本点归入左子节点,大于或等于p的样本点归入右子节点;
s304,递归s302和s303,直至所有的叶子节点都只有一个样本点或者孤立树已经达到指定的高度。
进一步地,评价指标建立如下:
对每一个样本xi,令其遍历孤立森林的每一棵孤立树,计算其在孤立森林中的平均路径长度
其中,
h(i)为调和数。
进一步地,步骤s6中,具体设置一个评价指标阈值,当得到的评价指标大于该评价指标阈值时,判断为参保人的异常行为;相应的参保人为嫌疑参保人。
进一步地,步骤s2具体包括:
对于原始样本集,当样本数大于样本数阈值时,将原始样本集简单划分为多个参保人就诊行为特征数据集;
当样本数不超过样本数阈值时,采用套袋法从原始样本集多次抽取样本得到k个参保人就诊行为特征数据集;k≥2。
本发明的第二方面,提供一种基于无监督孤立点检测的医保反欺诈监测分析系统,包括:
存储器,存储有计算机程序;
处理器,用于运行所述计算机程序,所述计算机程序运行时执行如上文所述的方法的步骤。
本发明的优点在于:
1)提高了对参保人欺诈行为的检测水平;
医保反欺诈政策和机构完善正在紧锣密鼓筹建中,但医保反欺诈的行为和医保基金的损失仍然居高不下,基于无监督孤立点检测的医保反欺诈监测分析系统采用人工智能算法深度结合参保人欺诈行为数据,实现了反欺诈体系的能力升级;能够将正常参保人行为纳入模型中,扩大参保人检测检查欺诈行为,有效防范参保人医保欺诈发生率,反欺诈效果显著。
2)节省了资源成本;
以往传统的欺诈检测方法需要耗费大量的人力、财力和时间识别和判断出欺诈行为,在庞大的数据量和丰富的欺诈手段面前,显得尤为不足;基于无监督孤立点检测的医保反欺诈监测分析系统,是以智能化的技术为基础降低参保人欺诈率以及医保基金的损失,并且可以实现反欺诈方案的快速规模化应用复制,为更多的机构和地区提供反欺诈安全服务,改善当前单一的反欺诈策略,促进反欺诈策略向智能化、智慧化演进。
3)提高了机构工作效率;
以往传统的欺诈检测方法是通过专家经验,或者反欺诈医疗规则库,这种策略的反欺诈有很强的规则性,并且很容易被欺诈者钻空子,效率也不高;基于无监督孤立点检测的医保反欺诈监测分析系统,不仅可以处理批量的数据,还可以应用到不同场景中,使欺诈行为无处遁形。采用系统模型判断,避免因经验或人力不足带来的缺陷,提高工作效率。
附图说明
图1为本发明实施例中的方法流程图。
图2为本发明实施例中的孤立森林示例图。
图3为本发明实施例中的正常点路径分割与异常点路径分割对比图。
图4为本发明实施例中的平均路径长度示意图。
图5为本发明实施例中的评价指标示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
目前社会保险中的大量医保基金,被很多不法分子钻了空子,利用不正当手段获取医保基金,无形的掠夺病人的救命钱。这些行为不仅恶劣,如果不加整治和管理还会形成恶性循环,不断地侵蚀着医保基金,增加财政负担。相比骗保问题的严重,当前反欺诈的能力显得不足,尤其在一些技术相对落后的一线城市,医保风控体系几乎还是原始的名单类,且名单信息严重缺失。或者利用一些简单的规则拦截,比如一张医保卡一天中不能在5家医院就诊等,拦截精准度和覆盖度都非常有限。基于无监督孤立点检测的医保反欺诈监测分析解决方案的精妙之处是,通过技术手段发现对比出异常数据,给出检测结果,这些异常在模型遍历之下无处遁形。
参保人的异常行为是指在医疗就诊过程中,以参保人就诊过程中产生的就诊行为数据为参保人的就诊特征,参保人就诊特征样本中不同于绝大多数参保人就诊特征的样本,称为参保人行为噪点,找出医疗就诊过程中参保人行为噪点就能够确定嫌疑参保人。
嫌疑参保人的异常行为不同于一般的异常点或噪点的定义,嫌疑参保人的异常行为是以参保人为主体,诊疗过程中产生的就诊行为数据为就诊特征,综合考虑诊疗过程中的行为数据,再采用数据疏密程度的算法找出的异常值;而普通的异常值分析或离群点识别,局限于单个特征或一维数据空间的特征检测,缺少全局性综合考虑多维数据特征的情况。
本发明的实施例首先提出一种基于无监督孤立点检测的医保反欺诈监测分析方法,包括以下步骤:
步骤s1,获取参保人的就诊行为特征数据,形成原始样本集;
在获取参保人的就诊行为特征数据时,对有关医疗保险欺诈行为的特征变量进行归类总结,根据数据产生机制主要划分为医院信息、医生信息、患者信息、就诊项目信息、就诊费用信息等;
步骤s2,根据原始样本集得到多个参保人就诊行为特征数据集;
对于原始样本集,可以依照一个样本数阈值,当样本数大于样本数阈值时,可以将原始样本集简单划分为多个参保人就诊行为特征数据集;例如原始样本集中有500个样本,则可以划分5个参保人就诊行为特征数据集,每个参保人就诊行为特征数据集中有100个样本;
当样本数不超过样本数阈值时,可以采用套袋法(即bootstrap)从原始样本集多次抽取样本得到k个参保人就诊行为特征数据集;k≥2;bootstrap称为套袋法或自展法,是一种抽取又放回的方法,目的为了得到统计量的分布以及置信区间;套袋法可以组合多个若分类器期望得到更好更全面的强模型;
步骤s3,根据各个参保人就诊行为特征数据集创建相应的孤立树;
样本点在孤立树中的路径长度为样本点从树的根节点到叶子节点经过的边的数量;
样本数据集x={x1,x2……xn}为参保人就诊行为特征数据集;其中
s301,从x中随机抽取
s302,从d个维度中随机指定一个维度q,在当前子集中随机产生一个分割点p,min(xij,j=q,xij∈x’)<p<max(xij,j=q,xij∈x’);
维度q举例而言,例如是就诊费用,分割点p是就诊费用的一个具体数值,例如200元;
s303,此分割点p生成一个超平面,将当前数据空间划分为两个子空间:指定维度对应的值小于p的样本点归入左子节点,大于或等于p的样本点归入右子节点;
s304,递归s302和s303,直至所有的叶子节点都只有一个样本点或者孤立树已经达到指定的高度;
按上述步骤已经创建一棵孤立树,从创建树的过程可知,孤立树在判断有很大的随机性;首先是随机选择的变量,其次是随机选择的分割点;随机性导致了孤立树很难有较强的鲁棒性,为了解决这一难点,通过集成的方法,创建多棵孤立树,利用共同决策机制,提高模型的泛化能力;
步骤s4,集成各孤立树构成孤立森林;
有了孤立森林之后,对于各个各孤立树所形成的模型就可以采用平均或投票的方式得到总体状况或总体评价;
孤立森林的一个例子如图2所示;
步骤s5,基于孤立森林建立用于评价参保人就诊行为的评价指标;
从图3可以看出,密度很高的簇需要被切分很多次才能被独立,但是那些密度很低的簇很容易就可以被孤立;
异常点的平均路径长度与正常点的平均路径长度对比关系可参考图4;
评价指标建立如下:
对每一个样本xi,令其遍历孤立森林的每一棵孤立树,计算其在孤立森林中的平均路径长度
其中,
h(i)为调和数,该值可以被估计为ln(i)+0.5772156649;
从图5可以看出,
当e(h(x))→c(n)时,s→0.5,不能区分是否异常;n为样本数量;
当e(h(x))→0时,s→1,即样本的评价指标即异常分数接近1时,判定为异常;
当e(h(x))→n-1时,s→0,判定为正常;
步骤s6,对于输入的参保人就诊行为特征数据样本,遍历孤立森林的每一棵孤立树,根据得到的评价指标输出检测结果;
此步骤中,具体设置一个评价指标阈值,当得到的评价指标大于该评价指标阈值时,判断为参保人的异常行为;相应的参保人为嫌疑参保人。
本发明的实施例还提供一种基于无监督孤立点检测的医保反欺诈监测分析系统,包括:
存储器,存储有计算机程序;
处理器,用于运行所述计算机程序,所述计算机程序运行时执行如上文所述的方法的步骤。
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!