一种基于深度学习的单图像去反射方法与流程
本发明涉及数字图像复原领域,特别涉及了一种基于深度学习的单图像去反射方法。
背景技术:
随着科学技术的不断发展人们对信息的感知、获取和处理变得越来越重要,然而现实世界的拍摄过程光照造成的反射会导致户外视频系统捕获的图像颜色和对比度严重退化不仅会影响人们的观察理解,而且妨碍图像后续处理的基本信息提取。当人们在玻璃前拍摄物体的照片时,反射是很常见的物理现象。因此,如何降低或去除反射对图像的影响成为计算机视觉领域的研究的基础问题。
针对反射问题,shih等人(y.shih,d.krishnan,f.durand,andw.t.freeman,“reflectionremovalusingghostingcues,”inieeeconferenceoncomputervisionandpatternrecognition,2015.)对google上的关于窗户反射的图像进行了物理统计,结果发现大约有一半的图像会伴随有重影现象这是由于玻璃的双重反射在图像上产生的关于反射层场景的二次成像现象导致的。本发明主要针对有重影效应的反射图像,使用了diamant和schechner提出的重影模型(y.diamantandy.y.schechner.overcomingvisualreverberations.inieeeconferenceoncomputervisionandpatternrecognition(cvpr),pages1–8,2008.2,3,5.)。来自被反射物体的光线(与相机在玻璃窗格的同一侧)首先从玻璃窗格反射,以产生一个原始反射层,用r1表示。由于玻璃是半反射的,因此r1仅包含一定比例的入射光。其余的透过玻璃,到达另一侧,其中的一部分会反射回相机,这导致用r2表示的第二反射。r1是r2在空间上移位和衰减的图像。r1和r2的叠加产生了重影反射层图像r,t为背景层图像,i为观测得到的带重影的反射图像。他们量化了传输层和反射层中的重影。将重影建模为反射层r与内核k的卷积。然后可以分别通过r和t将观察到的图像i建模为重影反射层和透射层的加法混合:
其中重影卷积核k的估计由空间移位矢量d和衰减因子c进行参数化:
k=δ(x)+cδ(x-d)(2)
这里x指像素的坐标,δ(·)表示狄拉克函数。
图像去反射已经研究多年,针对反射现象研究人员提出通过使用特定的硬件设备,例如以不同偏振角拍摄的几张图像来估计反射层(n.kong,y.tai,andj.shin.aphysically-basedapproachtoreflectionseparation:fromphysicalmodelingtoconstrainedoptimization.ieeetransactionsonpatternanalysisandmachineintelligence(tpami),36(2):209–221,2014.1,2.y.y.schechner,j.shamir,andn.kiryati.polarizationandstatisticalanalysisofscenescontainingasemireflector.thejournaloftheopticalsocietyofamericaa,17(2):276–284,2000.1,2.),或者依靠具有和不具有闪光灯拍摄的同一场景的两张照片消除闪光图像的反射和高光等基于多图像的去反射方法(y.y.schechner,n.kiryati,andj.shamir.blindrecoveryoftransparentandsemireflectedscenes.inieeeconferenceoncomputervisionandpatternrecognition(cvpr),volume1,pages38–43,2000.1,3.)。这些方法都取得了较好去反射的效果,但是这些算法都是基于多幅图像,需要较长的图像序列,极大地限制了它们的应用范围。考虑到普通用户的技能和资源,这些方法都不可行。对于使用普通相机进行的日常摄影,去除单个图像反射的方法是十分必要的。
单图像去反射问题是一个极具挑战性的病态问题。通常,在实际场景中,仅依赖一张图像的方法的性能受到限制,而且目标图像和反射层图像之间同时满足自然图像常见的统计特性,这增大了问题的挑战性。现有的单图像去反射研究可以分成两类。第一类使用基于非学习的方法解决这个问题。先前的一些工作采用了不同的先验信息来开发背景层和反射层的特殊属性。广泛使用的先验是自然图像梯度稀疏性(a.levin,a.zomet,andy.weiss.learningtoperceivetransparencyfromthestatisticsofnaturalscenes.innips,2003.2.a.levin,a.zomet,andy.weiss.separatingreflectionsfromasingleimageusinglocalfeatures.incvpr,2004.2.),以找到用于层分解的最小边缘和角。他们的方法依赖于用户标记背景和反射边缘,这非常费力,并且可能在纹理区域中失败。最近的工作利用透射和反射之间的统计不对称性,例如考虑反射场景是消色差的情况(k.kayabol,e.e.kuruoglu,andb.sankur.imagesourceseparationusingcolorchanneldependencies.inindependentcomponentanalysisandsignalseparation,pages499–506.springer,2009.3.),或者相对于透射而言反射模糊(y.liandm.s.brown.singleimagelayerseparationusingrelativesmoothness.inieeeconferenceoncomputervisionandpatternrecognition(cvpr),2014.3,6.),还有一些方法(y.shih,d.krishnan,f.durand,andw.t.freeman,“reflectionremovalusingghostingcues,”inieeeconferenceoncomputervisionandpatternrecognition,2015.)利用了通过双层玻璃拍摄的图像上的重影线索来区分背景层和反射层。
另一类通过使用基于学习的方法。fan等(q.fan,j.yang,g.hua,b.chen,andd.p.wipf,“agenericdeeparchitectureforsingleimagereflectionremovalandimagesmoothing.”inieeeinternationalconferenceoncomputervision,2017.)通过合成数据集训练深度神经网络,利用边缘信息去除反射层。zhang等(zhang,x.,ren,n.,chen,q.:‘singleimagereflectionseparationwithperceptuallosses.ieee/cvfconf.oncomputervisionandpatternrecognition,saltlakecity,ut,2018.)利用低级和高级图像信息的损失,提出了一种基于卷积神经网络的反射分离方法。chi等(chi,z.,wu,x.,shu,x.,etal.:‘singleimagereflectionremovalusingdeepencoder-decodernetwork,2018.)首先估计反射层,然后重建基于估计的反射和传输层以消除反射。chang和jung(chang,y.,jung,c.:‘singleimagereflectionremovalusingconvolutionalneuralnetworks’,ieeetrans.imageprocess.,2019,28,(4),pp.1954–1966.)构建了一个由编码器和解码器组成的端对端网络,以去除单个图像反射。它倾向于学习像素级反射图像而不是传输层。yang等(yang,j.,gong,d.,liu,l.,etal.:‘seeingdeeplyandbidirectionally:adeeplearningapproachforsingleimagereflectionremoval’.proc.oftheeuropeanconf.oncomputervision(eccv),munich,germany,2018,pp.654–669.)提出了一种级联深度神经网络,其使用估计的背景层图像来估计反射,然后使用估计的反射来估计背景层图像。li等人(z.chi,x.wu,x.shu,andj.gu,“singleimagereflectionremovalusingdeepencoder-decodernetwork,”arxivpreprintarxiv:1802.00094,2018.)开发了一种基于深度编码器-解码器,使用混合反射图像和反射边缘作为输入来预测图像反射层。
基于非学习的去反射方法基于图像先验,无法应用于更一般,更复杂的场景。而基于学习的方法,由于深度学习利用其全面的建模能力从而达到更好的反射消除效果。然而现有的基于深度学习的去反射方法没有显示的模型中引入图像先验。因此研究提出基于重影线索的单图像去反射技术,针对反射图像中经常出现的重影现象进行研究,充分利用重影线索,这些提示是由反射场景从玻璃表面移开的两次反射产生的。在双窗格窗口中,每个窗格在与相机相同的玻璃一侧上反射对象的偏移和衰减版本,利用线索可以区分背景层和反射层,从而达到单图像去反射的效果。
技术实现要素:
重影效应是指由于玻璃的双重反射产生的模式重复效应,针对反射图像中经常出现的重影现象,本项目主要研究基于重影线索的单图像去反射技术,针对反射图像中经常出现的重影现象进行研究,充分利用重影线索来区分背景层和反射层。本发明的目的在于克服现有技术的缺点与不足,针对于合成重影反射数据集有别于真实世界的反射图像,而现实世界中的重影反射训练样本难以得到真实背景层、反射层和重影卷积核参数,本发明提供一种利用重影线索,利用双重反射合成建模,首先根据传统方法或者深度学习的方法进行重影卷积核参数估计,利用深度网络估计背景层图像和反射层图像提出自监督的学习方法,从而达到更好的去反射的目的。
本发明的目的至少通过如下技术方案之一实现。
一种基于深度学习的单图像去反射方法,包括以下步骤:
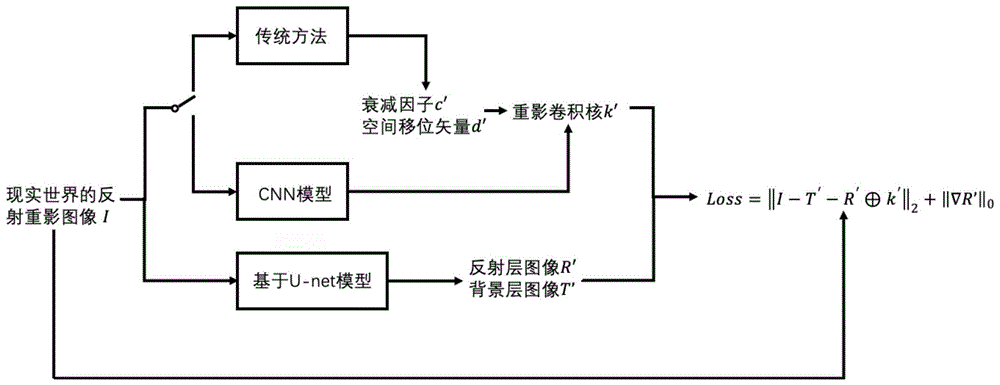
s1、首先合成具有带重影的反射图像以及对应重影参数和背景层反射层图像的合成反射图像数据集,通过合成反射图像数据集中反射重影图像和对应重影参数对于进行重影卷积核k参数估计的cnn模型有监督的进行预训练;
s2、利用具有真实背景层图像t和反射层图像r对应的合成反射图像数据集通过有监督学习对于估计背景层图像t和反射层图像r的基于u-net模型进行预训练;
s3、将具有在真实世界中对于重影卷积核k、真实背景层图像t和反射层图像r未知的带重影的反射图像的数据集作为真实反射图像数据集;输入带重影的真实反射图像i根据重影区域信息利用传统方法或者深度学习的方法及s1中预训练得到的cnn模型进行重影卷积核参数的估计得到k′;
s4、将步骤s3中的带重影的真实反射图像i同时输入基于u-net模型输出对应背景层图像t′和反射层图像r′;
s5、根据步骤s3得到的重影卷积核k′、步骤s4得到的背景层图像t′和反射层图像r′,通过已有带重影的真实反射图像i进行自监督学习,训练网络模型;
s6、将测试数据集中的带重影的反射图像输入训练好的基于u-net模型,输出对应的反射层图像和背景层图像。
进一步地,步骤s1包括以下步骤:
s1.1、为合成带重影的反射图像的数据集,衰减因子c在[0.5,1]随机采样,空间移位矢量d是一个随机向量满足1<||(d)||2≤20,在现有的真实图像数据集中随机选择两张图像作为反射层和背景层,从而生成若干张具有反射重影图像、对应重影参数和背景层反射层图像的合成数据集;在合成数据集中随机选择n1个大小为r×r的反射图像区域块,记为xi;
s1.2、将害合成反射图像区域块xi的对应重影参数及衰减因子c、空间移位矢量d根据公式计算区域块真实的重影卷积核k,具体如下:
k=δ(x)+cδ(x-d)
其中x指像素的坐标,δ(·)表示狄拉克函数;以xi作为输入,重影卷积核k作为标签训练cnn模型。
进一步地,所述cnn模型包括卷积层conv、批归一化层bn、激活函数relu和激活函数softmax;
第一层包括64个大小为3×3×c的滤波器的卷积层,其中c表示通道数,彩色图像c=3;第二层至第八层均包括64个大小为3×3×64的滤波器的卷积层和批归一化层,且第二层至第八层均添加激活函数relu输出至下一层;第九层包括c个大小为3×3×64的滤波器用于重构输出,且第九层添加激活函数softmax作为输出;
所述训练cnn模型为将估计的重影卷积核k′与真实的重影卷积核k之间的均方误差作为损失函数
进一步地,步骤s2中,采用步骤s1中的合成反射图像数据集作为训练样本,通过有监督学习方法训练生产背景层图像t和反射层图像r的基于u-net模型,具体如下:
对于s1.1中随机选择的合成反射图像区域块xi,以xi对应的真实背景层图像t和反射层图像r作为标签训练基于u-net模型;
所述基于u-net模型包括卷积层conv、批归一化层bn、最大池化层maxpool、反卷积层deconv、激活函数relu以及跳跃链接skipconn;其中,最大池化层用于进行下采样,反卷积层用于进行上采样;首先输入大小为w×h×c图像利用三层包括64个大小为3×3×c的滤波器的卷积层和激活函数relu进行特征提取,特征输入三层下采样层,下采样层由卷积层和激活函数relu和2×2池化核的最大池层构成;将下采样层输出的图像编码输入到三层上采样层,上采样层由卷积层和激活层relu和反卷积层构成,并且为保证扩展路径与收缩路径相同大小的特征图更好的进行跳层连接,反卷积操作之后引入2×2卷积核;跳过连接从第1/2个下采样层添加到第3/2个上采样层;将下采样层输出的大小为w×h×64特征传递给两个多层感知器;
两个多层感知器结构相同均为四层,第一层包括64个大小为3×3×64的滤波器的卷积层,批归一化层,激活函数relu;第二层为16个大小为3×3×64的滤波器的卷积层,批归一化层,激活函数relu;第三层为16个大小为3×3×16的滤波器的卷积层,批归一化层,激活函数relu;第四层为c个大小为3×3×16的滤波器的卷积层激活函数relu;两个多层感知器输出分别为背景层图像t′和反射层图像r′;
所述基于u-net模型将估计的背景层图像和反射层图像与真实背景层图像和反射层图像的均方误差和作为损失函数
进一步地,步骤s3中,首先将真实反射数据集随机裁剪n2个大小为w×h的真实的带重影的反射图像;对于真实带重影的反射图像i,通过传统方法对重影卷积核k进行参数估计,重影卷积核k由空间移位矢量d和衰减因子c进行参数化,包括以下步骤:
s3.1、首先根据输入真实带重影的反射图像i的拉普拉斯算子的2-d估计空间移位矢量得到d′;
s3.2、根据空间移位矢量d′估计衰减因子得到c′;
s3.3、根据衰减因子c′、空间移位矢量d′,通过公式k=δ(x)+cδ(x-d)求出重影卷积核参数估计k′。
进一步地,步骤s3.1包括以下步骤:
s3.1.1、通过计算反射图像i的拉普拉斯算子,得到i的2-d的空间偏移上的自相关图
s3.1.2、在自相关图
s3.1.4、在剩余的局部最大值中,选择最大的值作为估计的空间移位矢量d′;对于d′的正负号,根据第二反射的能量低于第一反射的能量的原理,空间移位矢量d′保证下一步估计的衰减因子c’<1。
进一步地,步骤s3.2包括以下步骤:
s3.2.1、使用哈里斯角点检测器从输入合成反射图像中检测出一组角点特征;
s3.2.2、在每个角点特征周围,提取大小为5×5的区域块,并且对区域块进行对比度标准化;估计每一对匹配的区域块pi、pj之间的衰减为比率:
其中,var[pi]是区域块pi的像素方差,选择的匹配区域块(pi,pj)使得aij<1;
s3.2.3、计算所有区域块对的衰减为比率总和,得出c的估计值:
其中,
进一步地,步骤s3中,所述深度学习的方法即对于s3中真实带重影的反射图像i通过输入cnn模型对重影卷积核k进行参数估计,包括以下步骤:
将真实反射数据集按照步骤进行处理得到输入的反射图像区域块xireal,真实带重影的反射图像i输入步骤s1中预训练好的cnn模型,输出对应估计重影卷积核k′。
进一步地,步骤s4中,将真实带重影的反射图像i输入步骤s2中预训练好的基于u-net模型,得到估计的背景层图像t′和反射层图像r′;
同样由于没有真实的背景t和反射层r,因此无法对重影t和r进行监督。
进一步地,步骤s5中,采用
通过反向传播算法训练cnn模型和u-net模型,并训练各网络层参数,得到训练好的cnn模型和基于u-net模型。
本发明相对于现有技术具有如下的优点及效果:
(1)本发明针对于合成重影反射数据集有别于真实世界的反射图像,而现实世界中的重影反射训练样本难以得到真实背景层图像、反射层图像和重影卷积核参数的缺点,提出自监督的方法对于深度神经网络进行训练。
(2)本发明使用传统方法或者深度学习的方法对于重影卷积核k估计,更好的利用反射图像中重影线索,从而分离重影反射图像的背景层图像和反射层图像。
(3)本发明对于估计重影卷积核k和估计背景层图像t、反射层图像r的模型进行预训练,从而加快模型收敛速度,提高模型表现。
(4)本发明能够对大部分的自然场景重影反射图像产生较好的复原效果。
附图说明
图1是本发明一种基于深度学习的单图像去反射方法的流程图。
具体实施方式
下面结合实施例及附图,对本发明的具体实施作进一步地详细说明,但本发明的实施方式不限于此。
实施例:
一种基于深度学习的单图像去反射方法,如图1所示,包括以下步骤:
s1、首先合成具有带重影的反射图像以及对应重影参数和背景层反射层图像的合成反射图像数据集,通过合成反射图像数据集中反射重影图像和对应重影参数对于进行重影卷积核k参数估计的cnn模型有监督的进行预训练,包括以下步骤:
s1.1、为合成带重影的反射图像的数据集,衰减因子c在[0.5,1]随机采样,空间移位矢量d是一个随机向量满足1<||(d)||2≤20,本实施例中,在imagenetdataset和bsds-500dataset随机选择两张图像作为反射层和背景层,从而生成643张具有反射重影图像、对应重影参数和背景层反射层图像的合成数据集;在合成数据集中随机选择n1个大小为r×r的反射图像区域块,记为xi,本实施例中,r=32;
s1.2、将合成反射图像区域块xi的对应重影参数及衰减因子c、空间移位矢量d根据公式计算区域块真实的重影卷积核k,具体如下:
k=δ(x)+cδ(x-d)
其中x指像素的坐标,δ(·)表示狄拉克函数;以xi作为输入,重影卷积核k作为标签训练cnn模型。
所述cnn模型包括卷积层conv、批归一化层bn、激活函数relu和激活函数softmax;
第一层包括64个大小为3×3×c的滤波器的卷积层,其中c表示通道数,彩色图像c=3;第二层至第八层均包括64个大小为3×3×64的滤波器的卷积层和批归一化层,且第二层至第八层均添加激活函数relu输出至下一层;第九层包括c个大小为3×3×64的滤波器用于重构输出,且第九层添加激活函数softmax作为输出;
所述训练cnn模型为将估计的重影卷积核k′与真实的重影卷积核k之间的均方误差作为损失函数
s2、利用具有真实背景层图像t和反射层图像r对应的合成反射图像数据集通过有监督学习对于估计背景层图像t和反射层图像r的基于u-net模型进行预训练,具体如下:
对于s1.1中随机选择的合成反射图像区域块xi,以xi对应的真实背景层图像t和反射层图像r作为标签训练基于u-net模型;
所述基于u-net模型包括卷积层conv、批归一化层bn、最大池化层maxpool、反卷积层deconv、激活函数relu以及跳跃链接skipconn;其中,最大池化层用于进行下采样,反卷积层用于进行上采样;首先输入大小为w×h×c图像利用三层包括64个大小为3×3×c的滤波器的卷积层和激活函数relu进行特征提取,特征输入三层下采样层,下采样层由卷积层和激活函数relu和2×2池化核的最大池层构成;将下采样层输出的图像编码输入到三层上采样层,上采样层由卷积层和激活层relu和反卷积层构成,并且为保证扩展路径与收缩路径相同大小的特征图更好的进行跳层连接,反卷积操作之后引入2×2卷积核;跳过连接从第1/2个下采样层添加到第3/2个上采样层;将下采样层输出的大小为w×h×64特征传递给两个多层感知器;
两个多层感知器结构相同均为四层,第一层包括64个大小为3×3×64的滤波器的卷积层,批归一化层,激活函数relu;第二层为16个大小为3×3×64的滤波器的卷积层,批归一化层,激活函数relu;第三层为16个大小为3×3×16的滤波器的卷积层,批归一化层,激活函数relu;第四层为c个大小为3×3×16的滤波器的卷积层激活函数relu;两个多层感知器输出分别为背景层图像t′和反射层图像r′;
所述基于u-net模型将估计的背景层图像和反射层图像与真实背景层图像和反射层图像的均方误差和作为损失函数
s3、本实施例中,将具有在真实世界中对于重影卷积核k、真实背景层图像t和反射层图像r未知的带重影的反射图像的数据集realimagesfromdataset和sir2-postcarddataset作为真实反射图像数据集;输入带重影的真实反射图像i根据重影区域信息利用传统方法或者深度学习的方法及s1中预训练得到的cnn模型进行重影卷积核参数的估计得到k′;
首先将真实反射数据集随机裁剪n2个大小为w×h的真实的带重影的反射图像,本实施例中,w,h=128;对于真实带重影的反射图像i,通过传统方法对重影卷积核k进行参数估计,重影卷积核k由空间移位矢量d和衰减因子c进行参数化,包括以下步骤:
s3.1、首先根据输入真实带重影的反射图像i的拉普拉斯算子的2-d估计空间移位矢量得到d′,包括以下步骤:
s3.1.1、通过计算反射图像i的拉普拉斯算子,得到i的2-d的空间偏移上的自相关图
s3.1.2、在自相关图
s3.1.4、在剩余的局部最大值中,选择最大的值作为估计的空间移位矢量d′;对于d′的正负号,根据第二反射的能量低于第一反射的能量的原理,空间移位矢量d′保证下一步估计的衰减因子c’<1。
s3.2、根据空间移位矢量d′估计衰减因子得到c′,包括以下步骤:
s3.2.1、使用哈里斯角点检测器从输入合成反射图像中检测出一组角点特征;
s3.2.2、在每个角点特征周围,提取大小为5×5的区域块,并且对区域块进行对比度标准化;估计每一对匹配的区域块pi、pj之间的衰减为比率:
其中,var[pi]是区域块pi的像素方差,选择的匹配区域块(pi,pj)使得aij<1;
s3.2.3、计算所有区域块对的衰减为比率总和,得出c的估计值:
其中,
s3.3、根据衰减因子c′、空间移位矢量d′,通过公式k=δ(x)+cδ(x-d)求出重影卷积核参数估计k′。
所述深度学习的方法即对于s3中真实带重影的反射图像i通过输入cnn模型对重影卷积核k进行参数估计,包括以下步骤:
将真实反射数据集按照步骤进行处理得到输入的反射图像区域块xireal,真实带重影的反射图像i输入步骤s1中预训练好的cnn模型,输出对应估计重影卷积核k′。
s4、将步骤s3中的带重影的真实反射图像i同时输入基于u-net模型输出对应背景层图像t′和反射层图像r′;
同样由于没有真实的背景t和反射层r,因此无法对重影t和r进行监督。
s5、根据步骤s3得到的重影卷积核k′、步骤s4得到的背景层图像t′和反射层图像r′,通过已有带重影的真实反射图像i进行自监督学习,训练网络模型;
采用
通过反向传播算法训练cnn模型和u-net模型,并训练各网络层参数,得到训练好的cnn模型和基于u-net模型。
s6、将测试数据集中的带重影的反射图像输入训练好的基于u-net模型,输出对应的反射层图像和背景层图像。
- 还没有人留言评论。精彩留言会获得点赞!