一种动态场景下的基于概率传递模型的环境感知方法与流程
本发明涉及虚拟现实技术领域,尤其涉及一种动态场景下的基于概率传递模型的环境感知方法。
背景技术:
同时定位与建图(simultaneouslocalizationandmapping,slam)技术是为了解决机器人的自定位和环境感知问题而提出,并且已经在许多不同领域有着广泛应用,包括自动驾驶、机器人导航和虚拟现实等。然而当前已有的slam框架都是基于静态场景的假设,场景中的动态物体会造成错误的数据关联结果进而影响slam系统中的跟踪和建图过程。近年来,针对动态场景的视觉slam方法研究已经取得了许多进展,但这些方法都有各自的优点和局限性,现有技术中动态场景下的视觉slam方案存在如下问题:
1)动态物体造成slam系统前端出现错误的数据关联,导致定位精度降低,进而影响后端的回环检测过程,无法得到准确的环境地图;
2)基于几何模型ransac算法的slam系统仅能剔除少量的动态物体,在动态物体占据较大比例的场景无法可靠剔除异常点匹配;
3)基于深度学习方法的视觉slam系统针仅能剔除特定种类的动态物体进行分割,并且深度学习网络模型有时无法保证精确的语义分割,导致部分静态物体被剔除进而降低定位精度与建图质量。
技术实现要素:
本发明的目的是提供一种动态场景下的基于概率传递模型的环境感知方法,该方法能够消除动态物体造成slam系统前端出现错误的数据关联,提升视觉slam系统在动态场景下的定位精度和鲁棒性,从而得到完整的静态场景地图。
本发明的目的是通过以下技术方案实现的:
一种动态场景下的基于概率传递模型的环境感知方法,所述方法包括:
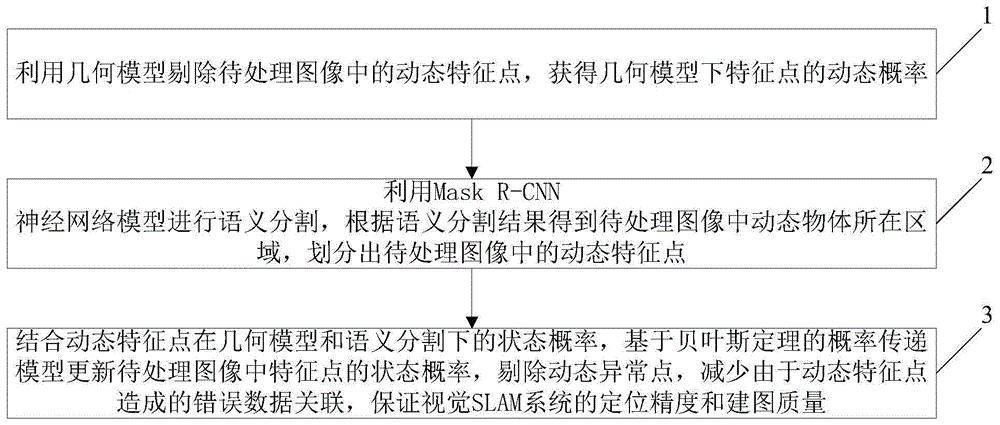
步骤1、利用几何模型剔除待处理图像中的动态特征点,获得几何模型下特征点的动态概率;
步骤2、利用maskr-cnn神经网络模型进行语义分割,根据语义分割结果得到待处理图像中动态物体所在区域,划分出待处理图像中的动态特征点;
步骤3、结合动态特征点在几何模型和语义分割下的状态概率,基于贝叶斯定理的概率传递模型更新待处理图像中特征点的状态概率,剔除动态异常点,从而减少由于动态特征点造成的错误数据关联,保证视觉slam系统的定位精度和建图质量。
由上述本发明提供的技术方案可以看出,上述方法能够消除动态物体造成slam系统前端出现错误的数据关联,提升视觉slam系统在动态场景下的定位精度和鲁棒性,从而得到完整的静态场景地图。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1为本发明实施例提供的动态场景下的基于概率传递模型的环境感知方法示意图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
下面将结合附图对本发明实施例作进一步地详细描述,如图1所示为本发明实施例提供的动态场景下的基于概率传递模型的环境感知方法示意图,所述方法包括:
步骤1、利用几何模型剔除待处理图像中的动态特征点,获得几何模型下特征点的动态概率;
在该步骤中,所述利用几何模型剔除待处理图像中的动态特征点的过程具体为:
利用光流法计算当前帧中匹配的特征点,如果该特征点太靠近图像边缘或匹配对中心的3×3图像块的像素差太大,则删除匹配对的特征点;
再利用ransac算法获得基本矩阵f,计算从匹配的特征点到极线的距离,如果距离大于设定的阈值,则将匹配点定义为动态特征点;
剔除所述动态特征点,以减少因动态物体导致的错误数据关联。
举例来说,若假设p1,p2为相邻两帧图像中的一对匹配点:
p1=[x1,y1,1],p2=[x2,y2,1]
极线l1可表示为:
其中,x1,y1,z1表示极线方向向量的坐标;f表示利用ransac算法获得基本矩阵;p2到其对应极线l1的距离可表示为:
通过判断该距离是否大于设定的阈值,来判断是否将p2定义为动态特征点。
另外,考虑到几何模型的局限性,进一步采取概率模型更新动态特征点的状态,具体过程为:
定义在时刻t由几何模型判定的特征点pi状态标签为
由于动态物体的存在,图像中的动态特征点不会严格位于其对应的极线上,因此可以通过计算特征点pi到对应极线的距离判定该点的状态概率,本实例中利用标准高斯分布的概率密度函数来估计特征点pi的状态概率
其中,pi,p′i为一对匹配特征点;
步骤2、利用maskr-cnn神经网络模型进行语义分割,根据语义分割结果得到待处理图像中动态物体所在区域,划分出待处理图像中的动态特征点;
在该步骤中,maskr-cnn神经网络模型在coco实例分割任务上的性能超越了目前所有单模型方法结果,并且在目标检测任务方面的表现也十分出色,maskr-cnn神经网络模型是fasterr-cnn的扩展,对于fasterr-cnn的每个proposalbox都要使用fcn进行语义分割,分割任务与定位、分类任务是同时进行的,同时该maskr-cnn神经网络模型引入了roialign代替fasterrcnn中的roipooling,使得mask的精度从10%显著提高到50%。
利用maskr-cnn神经网络模型进行语义分割,分割图像中潜在的动态物体,例如行人,车辆,动物等,从而划分出待处理图像中的动态特征点。
另外,考虑到maskr-cnn神经网络模型识别的动态物体有限,并且有时无法保证在边界处的精确分割,因此距离语义分割边界处较近的静态特征点有可能被错分为动态特征点,为了更好地估计语义分割结果下特征点的概率,本实施例进一步利用logistic回归模型估计语义分割结果下特征点的状态概率,具体表示为:
其中,α取0.1;
st表示特征点标签的集合
dist(pi,zt)为特征点pi与语义分割边界的距离,表示为:
其中,边界像素点的集合为
步骤3、结合动态特征点在几何模型和语义分割下的状态概率,基于贝叶斯定理的概率传递模型更新待处理图像中特征点的状态概率,剔除动态异常点,从而减少由于动态特征点造成的错误数据关联,保证视觉slam系统的定位精度和建图质量。
在该步骤中,首先定义特征点pi的真实状态标签为dt(pi),如果特征点pi位于待处理图像中动态物体所在区域,即判定为动态特征点并且有dt(pi)=1;如果特征点pi位于待处理图像中其它区域,即判定为静态特征点并且有dt(pi)=0;
融合几何模型和语义分割两种方法,更新当前帧图像中特征点的状态概率为:
其中,ω为权重参数,表示为:
其中,nc表示当前帧由几何模型剔除的动态特征点个数;ns表示当前帧由语义分割方法剔除的动态特征点个数;
假设概率传递模型满足马尔科夫性,即当前状态和上一个时刻有关,基于贝叶斯定理,利用前一帧的信息与当前帧的观测结果相结合更新特征点pi的状态概率为:
其中,η为归一化参数;
其中,
再依据概率传递模型得到的状态概率
进一步的,将状态概率高于0.5的特征点划分为动态特征点,状态概率低于0.5特征点划分为静态特征点;
然后剔除动态特征点,仅挑选静态特征点用于视觉定位与建图线程,进而提升视觉slam系统的精度和鲁棒性,减少由于动态特征点造成的错误数据关联,保证视觉slam系统的定位精度和建图质量,并且能够得到完整的场景静态地图。
值得注意的是,本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
综上所述,本发明实施例所述方法能够处理动态物体占据大部分场景的情况,并且避免了深度神经网络将部分静态物体因错分为动态物体的情况,提升了视觉slam系统在动态场景下的精度和鲁棒性,并得到完整的静态场景地图;该方案整体成本低,不需要对环境及机器人自身进行改造,可移植性强。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!