一种基于深度学习的肺结核DR影像识别方法与流程
本发明涉及肺结核dr影像识别技术领域,尤其涉及的是,一种基于深度学习的肺结核dr影像识别方法。
背景技术:
结核病是由结核分枝杆菌引起的慢性传染病,它可以侵及人体除头发、指甲以外的各个器官,特别是肺部,所占数量最多,约80%左右。尽管这是一个非常古老的疾病,但目前全球疫情仍十分严重,特别是我国结核病数量上仍居全球第二位,防控形势非常严峻。
肺结核病的早期发现除了患者因症状就诊,大规模的查体也是非常重要的手段,这就带来了一个实际问题,这些海量的胸部影像资料如何快速处理,医生的阅片能力与水平如何保证,而cad技术则为这一难题带来解决的可能与希望。通过人工智能深度学习的算法辅助医生的影像学诊断,既达到快速,同时又是高效,更能保证准确。因此建立肺结核早期诊断的人工智能模型,可以应对结核病的早期诊断、治疗,以结核病减少传播、降低发病率。现阶段医疗影像数据快速积累,已具有开发应用规模,我国每天产生的影像数据以pb计算,占到医疗行业数据的90%,影像医生产能负荷重和部分地区医生影像诊断水平偏低,而人工智能大有所为,放射科医师数量存在缺口,医师的疲劳或经验不足可能造成误判。
现阶段国内肺结核医疗影像存在如下问题:1、医生方面,大幅减少读片时间,降低误诊概率,提高诊疗水平;2、患者方面,有效减少诊疗时间,享受大型三甲医院的高水平医疗;3、医院方面,对大规模的数据加以利用,建立整体的数字化平台,提高医院的核心业务能力,推进医院之间的数据共享。传统的医学图像处理方式是由工程师们创造一套规则,算法根据规则对图像进行处理。但由于规则很难穷尽,所以对于现实中多变的情况准确率不高。
技术实现要素:
本发明提供一种基于深度学习的肺结核dr影像识别方法及系统,所要解决的技术问题为传统的医学图像处理方式由工程师们创造一套规则,规则很难穷尽,对于现实中多变的情况准确率不高的问题。
本发明提供一种基于深度学习的肺结核dr影像识别方法,包括以下步骤:
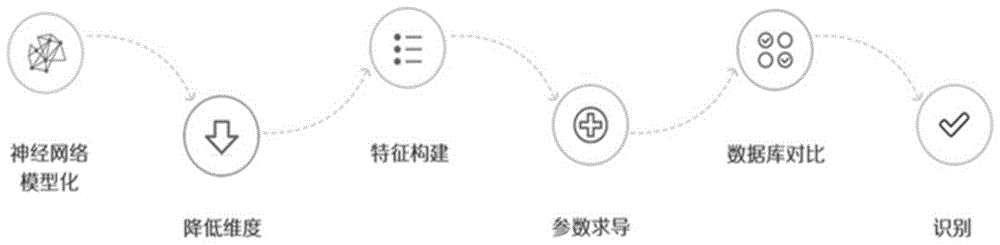
步骤1:10万张数字胸片收集后进行ai阅片及专家标注;专家标注后的胸片,进行ai训练识别功能的实现,结合ai阅片得到数字胸片筛查结果;
步骤2:薄层液基菌涂片染色一体开发,进入自动扫描识别系统,得到痰涂片诊断结果后与步骤1中的数字胸片筛查结果一并送至步骤3;
步骤3:推送到医院his系统,得到结核病诊断结果。
上述中,所述步骤1中进行ai训练识别功能的实现具体包括以下步骤:
步骤101:建立神经网络模型化以及特征构建:神经网络,由一个前置的32通道的卷积层和多个网络组件构成整个神经网络,总共有6个网络组件,每个组件由一个前置的卷积和一组循环的网络结构构成,所述循环的网络结构由卷积层,batchnormalize层,激活函数,残差网络构成;所述6个网络组件分别进行不同数量的重复,首尾相接;重复的数量分别为1,2,8,8,4,4;每个组件中,卷积数量为2个,前面卷积的通道数目2倍于后面一个卷积,每个卷积后面连接batchnormalize层;前5个组件的前置卷积的strde为2,其余的卷积的stride为1,因此整个神经网络的下采样率为32(2**5);在每个组件的两个卷积层之间设计直连残差网络;最后一个卷积层的输出为1024*16*16,网络的训练是的batchsize设置为16,初始学习率为0.01,采用步进学习率递减方式进行学习率的更新;训练时对不同的目标检测维度采用的不同的损失函数,对于检测框的中心点x,y和宽高w,h采用mse损失函数,对于分类采用交叉熵损失函数,对于置信度损失采用bcelosswithlogits损失函数;
步骤102:降低维度,进行归一化和图片增强;所述图像增强,将rgb转变为hsv格式,即为色度、饱和度、亮度,然后对饱和度和亮度进行数据增强;具体实现方式为:对饱和度和亮度乘以一个0.5到1.5倍随机数,然后将hsv格式还原为rgb格式;所述归一化为让网络在训练时集中于图像的相对检测区域,图像在进入网络之前都会将尺寸归一化到512*512像素;先将图片按照原图的比例缩放到高为512或宽为512像素,然后将尺寸较小的维度,图像增强部分随后对图像进行旋转、透视、错切变换,旋转的角度为-5和5之间的随机数,透视因子为0.9到1.1的随机数,错切因子为-0.1到0.1的随机数,变换之后,按照0.5的概率对图像进行水平和垂直翻转,最终对图像会进行0到1的归一化;
步骤103:特征构建;神经网络之后是特征提取网络,网络采用多尺度空间检测方式,能自适应不同大小的检测区域;在6个网络组件中,第3个,第4个和第6个三个组件的特征图输出作为检测结果,第3个组件的输出尺寸为256*64*64,第4个组件的输出尺寸为512*32*32,第6个组件的输出尺寸为1024*16*16;首先基于第6个组件提取网络的第一个特征图,通过7个卷积进行提取特征,每个卷积的特征图尺寸相同,不同的是通道数目,前6个卷积的通道数目以1024,512循环的方式,最后一个卷积的通道数目为18,然后基于第4个,第6个组件提取网络的第二个特征图,将第4和第6这两个不同深度的特征图进行融合,具体方法为:在第一个特征图的7个卷积提取中,取第6个卷积的输出,该输出尺寸为512*16*16,对该特征图进行上采样,输出尺寸为512*32*32的特征图,取第4个组件的输出特征图尺寸也为512*32*32,将该两个特征图在通道维度进行拼接,输出一个特征图,尺寸为1024*32*32,命名为特征图b,特征图b作为后面第3个特征图的输入,也作为本层特征图的输入,将其经过7个卷积进行特征提取,每个卷积的特征图尺寸相同,不同的是通道数目,前6个卷积的通道数目以512,256循环的方式,最后一个卷积的通道数目为18;
步骤104:参数求导;具体的包括:肺部结核病ai判定,1为正常,2为异常,当0-1之间,分值越大,病灶位置相似度越大;
步骤105:数据库对比,是dr影像质量ai判定,即判定dr影像为合格片或者是废片;
步骤106:肺结核dr影像识别;肺部结核病ai判定,判定为正常或异常;当判定的异常时结合分值以及病灶位置可以具体判定为:1.活动性结核-胸膜病变;2.活动性结核-肺部病变;3.非活动性结核-肺部钙化;4.非活动性结核-肺部纤维硬结;5.非活动性结核-胸膜钙化;6.非活动性结核-胸膜纤维硬结;7.考虑结核-需排除炎症;8.考虑结核-需排除肿瘤;9.非结核。
本发明还提供一种基于深度学习的肺结核dr影像识别系统,包括:系统服务模块、web浏览模块与系统管理模块;
所述系统服务模块:用于支持web服务,实现浏览器访问系统各功能模块;还用于提供数据存储功能,用户数据与图像数据存储在不同的位置;还用于与第三方系统进行患者信息、阅片报告信息的接收和发送;还用于ai学习和判定平台,具体由一种基于深度学习的肺结核dr影像识别方法实现;
所述web浏览模块:患者信息的采集,包括患者基本信息、影像文件与实验室检测结果采集;患者信息查询;支持专家对采集的患者影像进行阅片并登记阅片结果;支持按时间、地区、人群分布的各类统计信息的图文展示;
系统管理模块:包括后台用户管理单元、角色管理单元、权限管理单元、系统信息管理单元、存储介质管理单元。所述系统服务模块中的提供数据存储功能,具体的:数据中心充分利用各ai节点影像数据训练改进模型,并将新模型分发到各ai节点;同步影像、患者信息与各ai节点统计信息,为数据中心决策提供支持。
采有本发明的方法及系统,通过人工智能深度学习的算法辅助医生的影像学诊断,既达到快速,同时又是高效,更能保证准确。因此建立肺结核早期诊断的人工智能模型,对于结核病的早期诊断、治疗,以减少传播、降低发病率。
附图说明
图1为本发明肺结核dr影像识别方法示意图。
图2为本发明实施例中参数求导示意图。
图3为本发明实施例中降低维度的示意图。
图4为本发明肺结核dr影像识别方法流程图
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。但是,本发明可以用许多不同的形式来实现,并不限于本说明书所描述的实施例。
在过去的五年中,人工智能领域是最为革命性的技术,模仿人脑神经元网络的数学模型,需要海量的数据作为训练素材,曾因为算法复杂、预算要求高尔难以使用,近五年的革命性突破使其更近进人脑结构,在各个领域的表现令人震惊,在默写情景下的智能水平已经超过了人脑的表现,我们通过建立深度学习神经元数学模型,从海量肺结核医疗影像诊断数据中挖掘规律,学习和模仿国内顶尖肺结核一生的诊断技术。
实施例一
本发明的一个实施例是,一种基于深度学习的肺结核dr影像识别方法,通过深度学习则无需人工特征提取,通过大量的影像数据和诊断数据,不断对神经网络进行深度学习训练,促使其掌握诊断能力。基于国内肺结核防治的需求我们通过专家资源以及对ai深度学习的方法创造了一套针对肺结核dr影像识别方法及系统,为国内肺结核防治提供更好的诊断辅助以及医学资源共享。
如图4所示,一种基于深度学习的肺结核dr影像识别方法,具体包括以下步骤:
步骤1:10万张数字胸片收集后进行ai阅片及专家标注;专家标注后的胸片,进行ai训练,识别功能的实现,结合ai阅片得到数字胸片筛查结果;如图1所示,所述步骤1中进行ai训练识别功能的实现具体包括以下步骤:
步骤101:建立神经网络模型化以及特征构建:
神经网络是一个庞大而丰富的深度卷积神经网络模型。由一个前置的32通道的卷积层和多个网络组件构成整个神经网络,总共有6个网络组件,每个组件由一个前置的卷积和一组循环的网络结构构成,该循环的网络结构由卷积层,batchnormalize层,激活函数,残差网络构成。该6个网络组件分别进行不同数量的重复,首尾相接。重复的数量分别为1,2,8,8,4,4。每个组件中,卷积数量为2个,前面卷积的通道数目2倍于后面一个卷积,每个卷积后面连接batchnormalize层。前5个组件的前置卷积的strde为2,其余的卷积的stride为1,所以整个神经网络的下采样率为32(2**5)。因为本发明的图像输入尺寸是512,所以神经网络最后的输出尺寸是16。在每个组件的两个卷积层之间设计直连残差网络。神经网络总共有60个卷积层。除了最后一个卷积层采用linear函数,其他卷积的激活函数都采用leakyrule函数。主干网络负责的是特征提取的工作,网络弃用了普遍采用的池化层,用步长为2的卷积来进行降采样。残差网络能确保网络不会因为深度过深而出现梯度爆炸和消失的现象。神经网络最后一个卷积层的输出为1024*16*16。网络的训练是的batchsize设置为16,初始学习率为0.01,采用步进学习率递减方式进行学习率的更新。训练时对不同的目标检测维度采用的不同的损失函数,对于检测框的中心点x,y和宽高w,h采用mse损失函数,对于分类采用交叉熵损失函数,对于置信度损失采用bcelosswithlogits损失函数。
步骤102:降低维度;也就是如图3所示,进行归一化和图片增强;
图像增强:对于病灶区域的检测主要来源与色度,为了提升网络对色度的敏感,而稍微忽略对于饱和度和亮度的影响。对饱和度和亮度进行数据增强。通常情况下,相对于rgb颜色空间,hsv颜色空间更容易跟踪某种颜色的物体,常用于分割指定颜色的物体。本专利在处理图片流程中,先将rgb转变为hsv格式,即为色度、饱和度、亮度,然后对饱和度和亮度进行数据增强。具体实现方式为:对饱和度和亮度乘以一个0.5到1.5倍随机数。然后将hsv格式还原为rgb格式。
归一化:为了让网络在训练时集中于图像的相对检测区域,图像在进入网络之前都会将尺寸归一化到512*512像素。不同于一般的直接缩放,先将图片按照原图的比例缩放到高为512或宽为512像素。然后将尺寸较小的维度,比如宽进行0值填充。这样能保证图片不会变形,提升检测效果。图像增强部分随后对图像进行旋转、透视、错切变换,旋转的角度为-5和5之间的随机数,透视因子为0.9到1.1的随机数,错切因子为-0.1到0.1的随机数。变换之后,按照0.5的概率对图像进行水平和垂直翻转。最终对图像会进行0到1的归一化。
步骤103:特征构建;
神经网络之后是特征提取网络。网络采用多尺度空间检测方式,能自适应不同大小的检测区域。在6个网络组件中,第3个,第4个和第6个三个组件的特征图输出作为检测结果。第3个组件的输出尺寸为256*64*64,第4个组件的输出尺寸为512*32*32,第6个组件的输出尺寸为1024*16*16。第6个组件输出的感受野更大,对较大目标检测效果较好,而第3,4个组件的感受野更小,对较小的目标的检测效果较好。
首先基于第6个组件提取网络的第一个特征图,通过7个卷积进行提取特征,每个卷积的特征图尺寸相同,不同的是通道数目,前6个卷积的通道数目以1024,512循环的方式,最后一个卷积的通道数目为18。所以该特征图输出尺寸为18*16*16。数目18的解释如下:对于每个特征图的每个点,设置3个检测anchorbox。对于该特征图的输出,anchorbox为:[142,110],[192,243],[459,401],该尺寸是对应的原图的大小,输出到特征图时,需要scale到16*16的尺寸。对于每个特征点的18个通道,1个通道用来进行分类,1个通道用来预测置信度,4个通道用来预测x,y,w,h。本专利的分类数目为1,也就是说检测的目标区域就是病灶区域一个分类。所以通道总数为18,即3*(1+1+4)。
然后基于第4个,第6个组件提取网络的第二个特征图。因为使用某个深度的特征图会使得网络的鲁棒性变差。为此将第4和第6这两个不同深度的特征图进行融合。具体方法为:在第一个特征图的7个卷积提取中,取第6个卷积的输出,该输出尺寸为512*16*16。对该特征图进行上采样,输出尺寸为512*32*32的特征图。取第4个组件的输出特征图尺寸也为512*32*32。将该两个特征图在通道维度进行拼接,输出一个特征图,尺寸为1024*32*32(命名为特征图b),该特征图将作为后面第3个特征图的输入,也作为本层特征图的输入,将其经过7个卷积进行特征提取。每个卷积的特征图尺寸相同,不同的是通道数目,前6个卷积的通道数目以512,256循环的方式,最后一个卷积的通道数目为18。所以该特征图输出尺寸为18*32*32。该特征图的通道定义和第一个特征图定义相同。不同的是特征图的尺寸,还有anchorbox的尺寸和第一个特征图有差异,具体设置为:[36,75],[76,55],[72,146]。最后需要scale到32*32的尺寸。
最后基于第3个,特征图b(1024*32*32)提取第3个特征图。将特征图b进行上采样,得到尺寸为1024*64*64的特征图。第3个特征图的输出为256*64×64。将这个两个特征图在通道维度进行拼接。通过7个卷积进行提取,每个卷积的特征图尺寸相同,不同的是通道数目,前6个卷积的通道数目以1280,512循环的方式,最后一个卷积的通道数目为18。所以该特征图输出尺寸为18*64*64。该特征图的通道定义和第1,2个特征图定义相同。不同的是特征图的尺寸,还有anchorbox的尺寸和第1,2个特征图有差异,具体设置为:[12,16],[19,36],[40,28]。最后需要scale到64*64的尺寸。
步骤104:参数求导;具体的包括:肺部结核病ai判定,1为正常,2为异常,当0-1之间,分值越大,病灶位置相似度越大,如图2所示,图2为同一位置的2张图,对同一病灶位置进行了分值的标注,分别标注了1及0.85,这就说明肺部结核病ai判定中对于同一病灶位置的具体判定。
步骤105:数据库对比;也就是说是dr影像质量ai判定,即判定dr影像为合格片或者是废片。
步骤106:肺结核dr影像识别;肺部结核病ai判定,判定为正常或异常;当判定的异常时结合分值以及病灶位置可以具体判定为:1.活动性结核-胸膜病变;2.活动性结核-肺部病变;3.非活动性结核-肺部钙化;4.非活动性结核-肺部纤维硬结;5.非活动性结核-胸膜钙化;6.非活动性结核-胸膜纤维硬结;7.考虑结核-需排除炎症;8.考虑结核-需排除肿瘤;9.非结核。
步骤2:薄层液基菌涂片染色一体开发,进入自动扫描识别系统,得到痰涂片诊断结果后与步骤1中的数字胸片筛查结果一并送至步骤3;
步骤3:推送到医院his系统,得到结核病诊断结果。
实施例二
在实施例一的基础上,还提供一种基于深度学习的肺结核dr影像识别系统,包括:“系统服务模块、web浏览模块与系统管理模块”。
系统服务模块:1、支持web服务,实现浏览器访问系统各功能模块。2、提供数据存储功能,用户数据与图像数据可以存储在不同的位置。3、可与第三方系统进行“患者信息、阅片报告”等信息的接收和发送。4、还包括ai学习和判定平台,具体由上述中的一种基于深度学习的肺结核dr影像识别方法实现。
系统服务模块中的提供数据存储功能,具体的:数据中心(例如中心医院)充分利用各ai节点(例如各地方医院)影像数据训练改进模型,并将新模型分发到各ai节点。同步影像、患者信息与各ai节点统计信息,为数据中心决策提供支持。确诊患者推送到病人管理系统,健全确诊病例的后续治疗管理。开放安全的第三方接口,多系统对接。ai节点支持各节点(例如各地方医院)独立运作,弹性支撑各省业务。影像诊断和实验室诊断提供人工智能ai判定,ai判定采用是实施例一中的一种基于深度学习的肺结核dr影像识别方法。,加速确诊时间,提升准确率。提供针对病人的信息采集、影像诊断、实验室诊断记录的统一记录,提高管理精度。各个维度的统计信息和可视化展示,为疾病防控提供决策支持。数据上报数据中心。
web浏览模块:1、患者信息的采集,包括患者基本信息、影像文件与实验室检测结果采集。2、患者信息查询。3、支持专家对采集的患者影像进行阅片并登记阅片结果。4、支持按时间、地区、人群分布的各类统计信息的图文展示。5、只有授权用户可以访问系统。
系统管理模块:包括后台用户管理单元、角色管理单元、权限管理单元、系统信息管理单元、存储介质管理单元。后台用户管理单元用于管理后台用户,角色管理单元用于管理角色,权限管理单元用于管理权限,系统信息管理单元用于管理系统信息,存储介质管理单元,用于存储介质管理。
采有本发明的方法及系统,通过人工智能深度学习的算法辅助医生的影像学诊断,既达到快速,同时又是高效,更能保证准确。因此建立肺结核早期诊断的人工智能模型,对于结核病的早期诊断、治疗,以减少传播、降低发病率。
需要说明的是,上述各技术特征继续相互组合,形成未在上面列举的各种实施例,均视为本发明说明书记载的范围;并且,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!