基于组合策略的社交网络媒体信息流行度预测方法与流程
本发明涉及网络空间安全
技术领域:
,尤其涉及一种基于组合策略的社交网络媒体信息流行度预测方法。
背景技术:
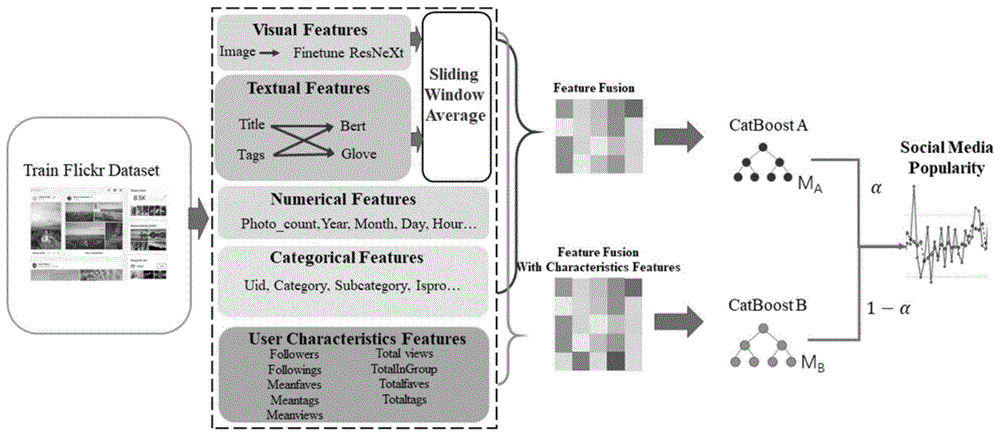
:随着社会的高速发展,越来越多的社交媒体平台出现并且吸引了大量的用户,比如微博,twitter,flickr,facebook等。以微博和flickr为例,每天都有上亿的用户发布分享数量庞大,种类繁多的信息。通过预测社交媒体上信息的受欢迎程度,一方面研究人员可以更好的分析各种问题并开发出广泛的应用来服务社会,比如信息检索系统、推荐系统和事件检测系统。另一方面,对于社交媒体上信息的分析有助于揭示个人偏好和公众关注度,这对于预测社会趋势和做出更好的未来战略决策有很大的帮助。对于社交媒体流行度预测可以分为两个部分:多模态特征的提取和回归模型的建立。在特征提取上,目前所有的方法仅对用户的每个帖子单独处理,虽然达到了比较好的效果,但是这种处理方法忽视了用户可能更倾向于在相近的时间内发布相同主题的帖子,表达自己观点这一现象,单独处理每个帖子没有考虑用户不同帖子间的潜在关联。而在回归模型的选取上,最近基于集成学习的方法在各种任务的回归中都表现出了优越的性能,一些先进的集成学习模型如randomforest、xgboost、lightgbm和catboost在社交媒体流行度预测领域的研究应用中也得到了广泛的应用,并且取得了最好的效果,但是这些方法针对目前规模最大的数据集中1/4缺失的用户粉丝数等数据没有进行有效建模,这些方法可以分为两种:对粉丝数这些缺失数据补零或者不使用缺失数据建模,而对于大量缺失数据补零会改变数据的分布,不使用粉丝数等数据时明显忽视了有大量粉丝数的用户帖子会有更高的流行度这一现象,这些方法都会错误的估计社会焦点。技术实现要素:本发明的目的是提供一种基于组合策略的社交网络媒体信息流行度预测方法,可以针对帖子是否包含用户特征使用不同的模型进行预测,有更好的普遍性与灵活性,也能够获得精确的预测结果本发明的目的是通过以下技术方案实现的:一种基于组合策略的社交网络媒体信息流行度预测方法,包括:对于训练集中每一包含多媒体特征的帖子,从中提取多模态特征,包括:图像特征、文本特征、社交信息中的数字特征以及类别特征,或者还包括用户特征;使用滑动窗口平均化来处理当前帖子的文本特征和图像特征,挖掘相同用户不同帖子间的潜在关联,并将平均化结果作为当前帖子的文本和图像特征,再与当前帖子的其他特征拼接融合;在进行特征拼接融合后,基于catboost根据是否包含用户特征来训练两个独立的模型,catboosta模型与catboostb模型;测试阶段,对于待预测的帖子,根据其是否包含用户特征来对训练后的catboosta模型与catboostb模型设置不同的权重进行社交媒体流行度预测。由上述本发明提供的技术方案可以看出,使用滑动窗口平均,来解决每个用户帖子之间的依赖性,在一定时间内进行特征平均,来挖掘帖子之间的时间相关性,额外利用了一部分时间信息,来获得精确的预测结果。此外,使用组合策略训练组合的catboost模型,可以针对不同的帖子进行预测,有更好的普遍性与灵活性。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。图1为本发明实施例提供的一种基于组合策略的社交网络媒体信息流行度预测方法的示意图。具体实施方式下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。针对现有技术存在的技术问题,本发明实施例提供一种基于组合策略的社交网络媒体信息流行度预测方法,如图1所示,该方法主要包括:对于训练集中每一包含多媒体特征的帖子(post),从中提取多模态特征,包括:图像特征、文本特征、社交信息中的数字特征以及类别特征,或者还包括用户特征;使用滑动窗口平均化来处理当前帖子的文本和图像特征,挖掘相同用户不同帖子间的潜在关联,并将平均化结果作为当前帖子的文本特征和图像特征,再与当前帖子的其他特征拼接融合;在进行特征融合后,基于catboost根据是否包含用户特征来训练两个独立的模型,catboosta模型与catboostb模型;测试阶段,对于待预测的帖子,根据其是否包含用户特征来对相应的训练后的catboosta模型与catboostb模型设置不同的权重进行社交媒体流行度预测。本领域技术人员可以理解,catboost是一种基于gbdt算法框架的改进优化实现。本发明实施例中,catboosta模型使用全部的训练集来训练,特征中不使用用户特征信息。catboostb模型使用训练集中含有用户特征信息的帖子集合作为训练集,使用全部的特征类型。两个模型训练阶段的目标函数是最小化的均方根误差rmse。本发明实施例上述方案,可以应用于社交网络平台的信息流行度预测,将社交媒体帖子中的图像、文本等异构数据作为本发明的输入数据,可以自动得出帖子将来的关注度,即流行度。在实际应用中,可以以后台进程的方式运行在社交媒体网络平台(如微博),实时预测用户待发布信息的流行度,预测目前社会趋势,更方便研究人员对未来做出更优的战略决策。此外本发明也可以应用在社交媒体上的广告推荐系统与事件检测系统,具有较强的实用性。下面针对以上各个部分做详细的介绍。一、多模态特征提取。1、图像特征提取。本发明实施例中,本发明采用预训练模型resnext-101的框架。resnext利用分组卷积再结合残差网络,在图像领域的多个任务上表现出了优越的性能。本发明实施例中,使用图像的类别标签来微调resnext模型,提取图像的通用特征表示,去掉resnext网络顶部的全连接层,获取最后一个池化层之后的2048维特征向量,作为图像特征。2、文本特征提取。对于文本的挖掘,本发明实施例中,使用两个最先进的预训练的深度学习模型bert和glove来提取文本的特征表示。bert采用多层transformer结构,通过attention机制将任意两个单词的距离转化成1,有效地解决了nlp中的棘手的长期依赖问题。而glove是基于全局词频统计的词表征工具,它可以把单词表示成捕捉到单词之间语义特性的向量。社交媒体信息中的标签和标题能清晰地显示出帖子地类别与主题思想,因此本发明实施例中使用bert和glove提取文本的特征表示。文本需要通过预处理去除无规则的单词;对于预处理后的每一个句子,各自通过预训练的深度学习模型bert和glove提取向量,再进行平均化作为整个句子的文本特征。3、数字特征。数字特征包括:非数值形式的特征,即帖子的时间戳;以及数值形式的特征,即发布位置、转发数目、评论数目和点赞数目;对于时间戳,转化成数值形式的年月日小时格式;对于数值形式的特征可以直接作为catboost的输入。4、类别特征。对于社交媒体上的类别特征,它们的值不能相互比较,用户id信息、图片类别、用户类型和发布平台等类别信息在本发明中直接使用catboost的有序目标统计方法进行转化,计算其统计值作为类别特征。5、用户特征。用户特征包括:用户在社交媒体上的粉丝数、关注数以及平均浏览量。等这些信息对于流行度的预测至关重要。明显可以认为粉丝数,浏览量多的用户和帖子有更大的影响力。因此对于这些数据,我们将其对应的数值作为用户特征。二、基于滑动窗口的特征平均处理。在社交媒体平台中,用户可能更倾向于在相近的时间内发布相同主题的帖子,表达自己的观点等。而滑动窗口平均化可以利用短期时间信息,挖掘相同用户临近帖子间的潜在关联,本发明实施例中,对临近时间的用户帖子特征进行平均处理作为当前帖子特征,对第i个用户,第j个帖子的滑动窗口平均处理后的特征通过以下公式计算:其中,xi,j为经过特征提取后的第i个用户,第j个帖子的原始特征(即,未进行滑动窗口平均之前的文本特征或者图像特征),s为窗口大小。本发明中采用滑动窗口平均化来对图像和文本的特征进行平均,特别地,图像和文本的滑动窗口设置为3。三、基于catboost的组合策略训练与预测。catboost是在gbdt框架下的一种基于对称决策树的算法改进实现。catboost模型在处理类别特征时采用有序的目标统计策略转化为数值,高效合理地处理了类别数据,并且将不同类别特征进行组合作为新的特征获得高阶依赖。此外它还提出了orderedboosting算法克服了预测偏移问题。它在多方面的预测任务中表现出了巨大的潜力。因此本发明采用catboost作为基础模型,面对数据集中1/4的缺失用户特征如粉丝数等等,本发明提出组合策略来对含有缺失值的用户帖子独立分析独立建模。首先,根据帖子是否含有额外的用户特征来分别训练两个模型,随后根据策略分析待预测的帖子是否含有粉丝数等缺失值进行分模型独立预测再综合两个模型的预测结果,得到最终预测结果。图1中,ma和mb是两个模型的简写,α代表不同的模型权重。对于测试集中的帖子根据是否含有用户特征划分为两个数据集h1和h2,其中h1是包含用户特征的帖子集合,h2是不包含用户特征的帖子集合。对于h2内的帖子用户特征,我们进行补零处理。对于h1和h2内的所有测试集,我们均使用catboosta和catboostb模型来预测所有的帖子,获得对应的流行度。对于h1内的帖子预测值为y=α1*ya+(1-α1)*yb对于h2内的帖子预测值为y=α2*ya+(1-α2)*yb其中,ya和yb分别是catboosta和catboostb模型的输出预测值,通过设置两个不同的超参数α1和α2来更好的解决大量缺失的粉丝数和关注数等数据,并且能更好的提升模型的性能。试验中,设置α1=0.05,α2=0.85。充分利用粉丝数,关注数等关键特征,并且有效解决大量缺失值的数据引起的泛化问题。本发明实施例中,数据集可以使用最新的smpd2020。该数据集来自于flickr平台,包含从70k用户中采集的486k包含多媒体特征的帖子,帖子内容包含图片,用户肖像,文本,时间,位置,类别等多模态信息。数据集中训练集包含305613个帖子,测试集包含180581个帖子,数据集中的用户信息有1/4的缺失,数据集分布如下表1所示。数量缺失比例训练集3056134.37%测试集18058166.12%训练集+测试集48619727.31%表1数据集分布与现有方法相比,本发明上述方案,使用深度学习模型来提取多模态特征,具有更强的特征提取能力,可以获得更好的文本特征向量与图像特征;此外,使用滑动窗口平均,来解决每个用户帖子之间的依赖性,在一定时间内进行特征平均,来挖掘帖子之间的时间相关性,额外利用了一部分时间信息,来获得精确的预测结果。最后,该方法使用组合策略训练组合的catboost模型,可以针对不同的帖子进行预测,有更好的普遍性与灵活性。为了说明本发明实施例上述方案的效果,还进行了相关实验。经过实验,本发明在smpd2020数据集上可以实现当前最佳的预测效果。实验结果如表2所示,斯皮尔曼等级相关系数(src)最高可以达到0.6725,src反应了预测值与真实值的相关程度,当两个统计变量完全正相关时src为+1。平均绝对误差(mae)最低可以达到1.4678,mae反映了预测值与真实值的误差。此外,还实施了单模型预测实验来验证组合策略的有效性,单独使用catboosta来预测,src为0.6549,mae为1.5126;单独使用catboostb来预测,src为0.6432,mae为1.5767。该结果证明本发明具有较好的预测结果。模型catboostacatboostb组合模型src0.65490.64320.6725mae1.51261.57671.4678表2测试实验结果通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1